Download as PDF, PPTX










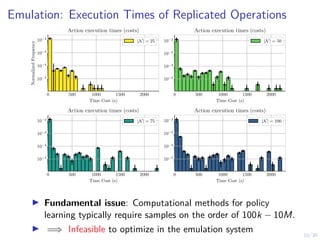



![13/30
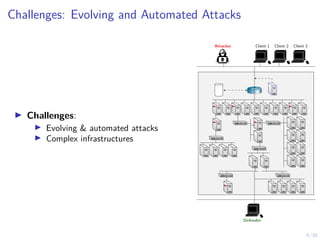
System Identification: Estimated Dynamics Model
−5 0 5 10 15 20
# New TCP/UDP Connections
0.0
0.2
0.4
0.6
0.8
1.0
P[·|(b
i
,
a
i
)]
New TCP/UDP Connections
0 10 20 30 40 50
# New Failed Login Attempts
0.0
0.2
0.4
0.6
0.8
1.0
P[·|(b
i
,
a
i
)]
New Failed Login Attempts
−30 −20 −10 0 10 20 30
# Created User Accounts
0.0
0.2
0.4
0.6
0.8
1.0
P[·|(b
i
,
a
i
)]
Created User Accounts
−0.04 −0.02 0.00 0.02 0.04
# New Logged in Users
0.0
0.2
0.4
0.6
0.8
1.0
P[·|(b
i
,
a
i
)]
New Logged in Users
−0.04 −0.02 0.00 0.02 0.04
# Login Events
0.0
0.2
0.4
0.6
0.8
1.0
P[·|(b
i
,
a
i
)]
New Login Events
0 20 40 60 80 100 120 140
# Created Processes
0.0
0.2
0.4
0.6
0.8
1.0
P[·|(b
i
,
a
i
)]
Created Processes
Node IP: 172.18.4.2
(b0, a0) (b1, a0) ...](https://image.slidesharecdn.com/nseseminar9april21kimhammar-210409131735/85/Self-learning-systems-for-cyber-security-28-320.jpg)
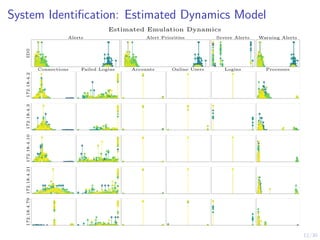
![14/30
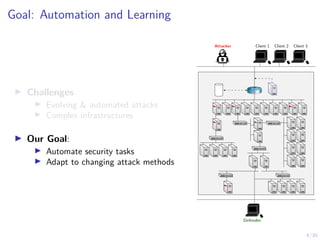
System Identification: Estimated Dynamics Model
0 20 40 60 80 100 120
# IDS Alerts
0.0
0.2
0.4
0.6
0.8
1.0
P[·|(b
i
,
a
i
)]
IDS Alerts
0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0
# Severe IDS Alerts
0.0
0.2
0.4
0.6
0.8
1.0
P[·|(b
i
,
a
i
)]
Severe IDS Alerts
0 20 40 60 80 100
# Warning IDS Alerts
0.0
0.2
0.4
0.6
0.8
1.0
P[·|(b
i
,
a
i
)]
Warning IDS Alerts
0 50 100 150 200 250
# IDS Alert Priorities
0.0
0.2
0.4
0.6
0.8
1.0
P[·|(b
i
,
a
i
)]
IDS Alert Priorities
IDS Dynamics
(b0, a0) (b1, a0) ...](https://image.slidesharecdn.com/nseseminar9april21kimhammar-210409131735/85/Self-learning-systems-for-cyber-security-29-320.jpg)
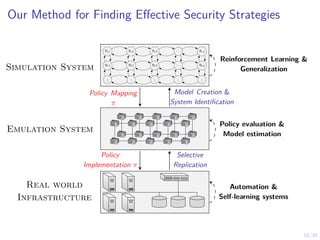
![15/30
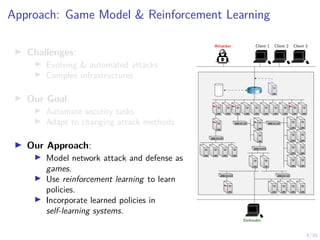
Policy Optimization in the Simulation System
using Reinforcement Learning
I Goal:
I Approximate π∗
= arg maxπ E
hPT
t=0 γt
rt+1
i
I Learning Algorithm:
I Represent π by πθ
I Define objective J(θ) = Eo∼ρπθ ,a∼πθ
[R]
I Maximize J(θ) by stochastic gradient ascent with
gradient
∇θJ(θ) = Eo∼ρπθ ,a∼πθ
[∇θ log πθ(a|o)Aπθ
(o, a)]
I Domain-Specific Challenges:
I Partial observability
I Large state space |S| = (w + 1)|N|·m·(m+1)
I Large action space |A| = |N| · (m + 1)
I Non-stationary Environment due to presence of
adversary
I Generalization
Agent
Environment
at
st+1
rt+1](https://image.slidesharecdn.com/nseseminar9april21kimhammar-210409131735/85/Self-learning-systems-for-cyber-security-30-320.jpg)
![15/30
Policy Optimization in the Simulation System
using Reinforcement Learning
I Goal:
I Approximate π∗
= arg maxπ E
hPT
t=0 γt
rt+1
i
I Learning Algorithm:
I Represent π by πθ
I Define objective J(θ) = Eo∼ρπθ ,a∼πθ
[R]
I Maximize J(θ) by stochastic gradient ascent with
gradient
∇θJ(θ) = Eo∼ρπθ ,a∼πθ
[∇θ log πθ(a|o)Aπθ
(o, a)]
I Domain-Specific Challenges:
I Partial observability
I Large state space |S| = (w + 1)|N|·m·(m+1)
I Large action space |A| = |N| · (m + 1)
I Non-stationary Environment due to presence of
adversary
I Generalization
Agent
Environment
at
st+1
rt+1](https://image.slidesharecdn.com/nseseminar9april21kimhammar-210409131735/85/Self-learning-systems-for-cyber-security-31-320.jpg)
![15/30
Policy Optimization in the Simulation System
using Reinforcement Learning
I Goal:
I Approximate π∗
= arg maxπ E
hPT
t=0 γt
rt+1
i
I Learning Algorithm:
I Represent π by πθ
I Define objective J(θ) = Eo∼ρπθ ,a∼πθ
[R]
I Maximize J(θ) by stochastic gradient ascent with
gradient
∇θJ(θ) = Eo∼ρπθ ,a∼πθ
[∇θ log πθ(a|o)Aπθ
(o, a)]
I Domain-Specific Challenges:
I Partial observability
I Large state space |S| = (w + 1)|N|·m·(m+1)
I Large action space |A| = |N| · (m + 1)
I Non-stationary Environment due to presence of
adversary
I Generalization
Agent
Environment
at
st+1
rt+1](https://image.slidesharecdn.com/nseseminar9april21kimhammar-210409131735/85/Self-learning-systems-for-cyber-security-32-320.jpg)
![15/30
Policy Optimization in the Simulation System
using Reinforcement Learning
I Goal:
I Approximate π∗
= arg maxπ E
PT
t=0
γt
rt+1
I Learning Algorithm:
I Represent π by πθ
I Define objective J(θ) = Eo∼ρπθ ,a∼πθ
[R]
I Maximize J(θ) by stochastic gradient ascent with gradient
∇θJ(θ) = Eo∼ρπθ ,a∼πθ
[∇θ log πθ(a|o)Aπθ (o, a)]
I Domain-Specific Challenges:
I Partial observability
I Large state space |S| = (w + 1)|N |·m·(m+1)
I Large action space |A| = |N | · (m + 1)
I Non-stationary Environment due to presence of adversary
I Generalization
I Finding Effective Security Strategies through
Reinforcement Learning and Self-Playa
a
Kim Hammar and Rolf Stadler. “Finding Effective Security Strategies through Reinforcement Learning and
Self-Play”. In: International Conference on Network and Service Management (CNSM 2020) (CNSM 2020). Izmir,
Turkey, Nov. 2020.
Agent
Environment
at
st+1
rt+1](https://image.slidesharecdn.com/nseseminar9april21kimhammar-210409131735/85/Self-learning-systems-for-cyber-security-33-320.jpg)
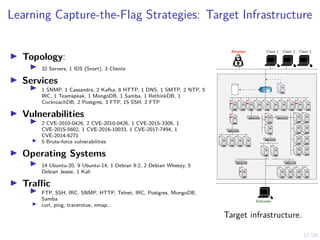
![20/30
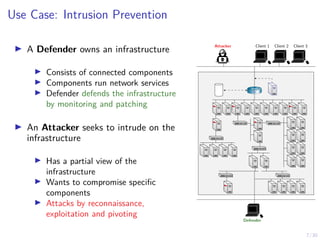
Learning Capture-the-Flag Strategies: System Model 3/3
I Contextual Stochastic CTF with Partial
Information
I Model infrastructure as a graph G = hN, Ei
I There are k flags at nodes C ⊆ N
I Ni ∈ N has a node state si of m attributes
I Network state
s = {sA, si | i ∈ N} ∈ R|N|×m+|N|
I Hacker observes oA
⊂ s
I Action space: A = {aA
1 , . . . , aA
k }, aA
i
(commands)
I ∀(b, a) ∈ A × S, there is a probability ~
w
A,(x)
i,j of
failure a probability of detection
ϕ(det(si ) · n
A,(x)
i,j )
I State transitions s → s0
are decided by a
discrete dynamical system s0
= F(s, a)
I Exact dynamics (F, cA
, nA
, wA
, det(·), ϕ(·)),
are unknown to us!
N0, ~
S0
N1, ~
S1
N2, ~
S2
N3, ~
S3
N4, ~
S4
N5, ~
S5 N6, ~
S6
N7, ~
S7
~
cA
2,3, ~
nA
2,3, ~
wA
2,3
~
cA
3,2, ~
nA
3,2, ~
wA
3,2
~
cA
2,1, ~
nA
2,1, ~
wA
2,1
~
cA
1,2, ~
nA
1,2, ~
wA
1,2
~
c
A
0,1
,
~
n
A
0,1
,
~
w
A
0,1
~
cA
0,2, ~
nA
0,2, ~
wA
0,2
~
cA
3,6, ~
nA
3,6, ~
wA
3,6
~
cA
6,7, ~
nA
6,7, ~
wA
6,7
~
cA
7,4, ~
nA
7,4, ~
wA
7,4
~
c
A
4
,6
,
~
n
A
4
,6
,
~
w
A
4
,6
~
c
A
4
,5
,
~
n
A
4
,5
,
~
w
A
4
,5
~
c
A
5
,4
,
~
n
A
5
,4
,
~
w
A
5
,4
~
cA
1,5, ~
nA
1,5, ~
wA
1,5
~
c
A
5,2
,
~
n
A
5,2
,
~
w
A
5,2
~
c
A
2,
4
,
~
n
A
2,
4
,
~
w
A
2,
4
~
c A
1,4 , ~
n A
1,4 , ~
w A
1,4
Si ∈ Rm, ~
cA
i,j ∈ Rk
+
~
nA
i,j ∈ Rk
+, ~
wA
i,j ∈ [0, 1]k
~
cD ∈ Rl
+, ~
wD ∈ [0, 1]l
Graphical Model.](https://image.slidesharecdn.com/nseseminar9april21kimhammar-210409131735/85/Self-learning-systems-for-cyber-security-39-320.jpg)
![20/30
Learning Capture-the-Flag Strategies: System Model 3/3
I Contextual Stochastic CTF with Partial
Information
I Model infrastructure as a graph G = hN, Ei
I There are k flags at nodes C ⊆ N
I Ni ∈ N has a node state si of m attributes
I Network state
s = {sA, si | i ∈ N} ∈ R|N|×m+|N|
I Hacker observes oA
⊂ s
I Action space: A = {aA
1 , . . . , aA
k }, aA
i
(commands)
I ∀(b, a) ∈ A × S, there is a probability ~
w
A,(x)
i,j of
failure a probability of detection
ϕ(det(si ) · n
A,(x)
i,j )
I State transitions s → s0
are decided by a
discrete dynamical system s0
= F(s, a)
I Exact dynamics (F, cA
, nA
, wA
, det(·), ϕ(·)),
are unknown to us!
N0, ~
S0
N1, ~
S1
N2, ~
S2
N3, ~
S3
N4, ~
S4
N5, ~
S5 N6, ~
S6
N7, ~
S7
~
cA
2,3, ~
nA
2,3, ~
wA
2,3
~
cA
3,2, ~
nA
3,2, ~
wA
3,2
~
cA
2,1, ~
nA
2,1, ~
wA
2,1
~
cA
1,2, ~
nA
1,2, ~
wA
1,2
~
c
A
0,1
,
~
n
A
0,1
,
~
w
A
0,1
~
cA
0,2, ~
nA
0,2, ~
wA
0,2
~
cA
3,6, ~
nA
3,6, ~
wA
3,6
~
cA
6,7, ~
nA
6,7, ~
wA
6,7
~
cA
7,4, ~
nA
7,4, ~
wA
7,4
~
c
A
4
,6
,
~
n
A
4
,6
,
~
w
A
4
,6
~
c
A
4
,5
,
~
n
A
4
,5
,
~
w
A
4
,5
~
c
A
5
,4
,
~
n
A
5
,4
,
~
w
A
5
,4
~
cA
1,5, ~
nA
1,5, ~
wA
1,5
~
c
A
5,2
,
~
n
A
5,2
,
~
w
A
5,2
~
c
A
2,
4
,
~
n
A
2,
4
,
~
w
A
2,
4
~
c A
1,4 , ~
n A
1,4 , ~
w A
1,4
Si ∈ Rm, ~
cA
i,j ∈ Rk
+
~
nA
i,j ∈ Rk
+, ~
wA
i,j ∈ [0, 1]k
~
cD ∈ Rl
+, ~
wD ∈ [0, 1]l
Graphical Model.](https://image.slidesharecdn.com/nseseminar9april21kimhammar-210409131735/85/Self-learning-systems-for-cyber-security-40-320.jpg)
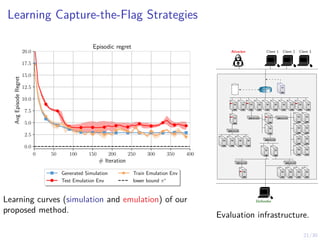






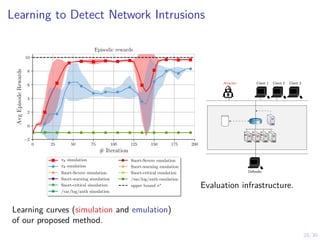
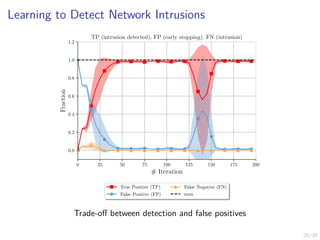


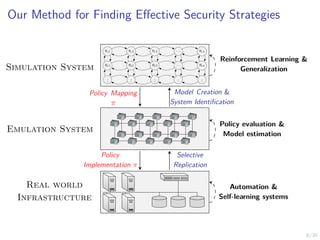
The document discusses using reinforcement learning and game theory to develop self-learning systems for cybersecurity. It describes challenges like evolving attacks and complex infrastructure. The approach models network attacks and defense as games and uses reinforcement learning to learn effective security policies. The work focuses on intrusion prevention, using emulation to create models of real systems and identify dynamics models for simulations. This allows training policies through reinforcement learning to automate security tasks and adapt to changing threats.

















































































