Download as PDF, PPTX



![4/6
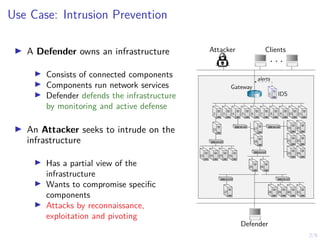
Threshold Properties of the Optimal Defender Policy
b(1)
0 1
belief space B = [0, 1]
S 1
S 2
.
.
.
S L
α∗
1
α∗
2
α∗
L
. . .](https://image.slidesharecdn.com/machinelearningdaydigitalfutures17jan2022hammarstadler-220117101007/85/Intrusion-Prevention-through-Optimal-Stopping-5-320.jpg)
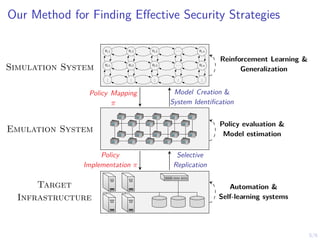


1) The document discusses formulating intrusion prevention as an optimal stopping problem where a defender must monitor an infrastructure over discrete time steps to detect an intrusion by an attacker. 2) If an intrusion is detected, the defender can take defensive actions to stop the intrusion at various time steps, with the goal of stopping intrusions optimally based on observations. 3) The document proposes modeling this problem as a partially observable Markov decision process (POMDP) and using reinforcement learning techniques like simulation and policy evaluation to develop automated security prevention policies that can optimally stop intrusions.





















































































