Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Kenta Oku
4,897 views
データベース14 - データベース構造とインデックス
立命館大学 情報理工学部 「データベース」講義スライド 第14回:データベース構造とインデックス
Education
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Downloaded 32 times
1
/ 57
2
/ 57
3
/ 57
4
/ 57
5
/ 57
6
/ 57
7
/ 57
8
/ 57
9
/ 57
10
/ 57
11
/ 57
12
/ 57
13
/ 57
14
/ 57
15
/ 57
16
/ 57
17
/ 57
18
/ 57
19
/ 57
20
/ 57
21
/ 57
22
/ 57
23
/ 57
24
/ 57
25
/ 57
26
/ 57
27
/ 57
28
/ 57
29
/ 57
30
/ 57
31
/ 57
32
/ 57
33
/ 57
34
/ 57
35
/ 57
36
/ 57
37
/ 57
38
/ 57
39
/ 57
40
/ 57
41
/ 57
42
/ 57
43
/ 57
44
/ 57
45
/ 57
46
/ 57
47
/ 57
48
/ 57
49
/ 57
50
/ 57
51
/ 57
52
/ 57
53
/ 57
54
/ 57
55
/ 57
56
/ 57
57
/ 57
More Related Content
PDF
データベース03 - SQL(CREATE, INSERT, DELETE, UPDATEなど)
by
Kenta Oku
PDF
データベース12 - トランザクションと同時実行制御
by
Kenta Oku
PDF
なぜ、いま リレーショナルモデルなのか(理論から学ぶデータベース実践入門読書会スペシャル)
by
Mikiya Okuno
PDF
データベース10 - 正規化
by
Kenta Oku
PDF
データベース09 - データベース設計
by
Kenta Oku
PDF
なかったらINSERTしたいし、あるならロック取りたいやん?
by
ichirin2501
PPTX
世界一わかりやすいClean Architecture
by
Atsushi Nakamura
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
データベース03 - SQL(CREATE, INSERT, DELETE, UPDATEなど)
by
Kenta Oku
データベース12 - トランザクションと同時実行制御
by
Kenta Oku
なぜ、いま リレーショナルモデルなのか(理論から学ぶデータベース実践入門読書会スペシャル)
by
Mikiya Okuno
データベース10 - 正規化
by
Kenta Oku
データベース09 - データベース設計
by
Kenta Oku
なかったらINSERTしたいし、あるならロック取りたいやん?
by
ichirin2501
世界一わかりやすいClean Architecture
by
Atsushi Nakamura
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
What's hot
PDF
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
by
Recruit Technologies
PPTX
WayOfNoTrouble.pptx
by
Daisuke Yamazaki
PPTX
がっつりMongoDB事例紹介
by
Tetsutaro Watanabe
PPTX
Redisの特徴と活用方法について
by
Yuji Otani
PPTX
監査要件を有するシステムに対する PostgreSQL 導入の課題と可能性
by
Ohyama Masanori
PDF
Google Cloud Dataflow を理解する - #bq_sushi
by
Google Cloud Platform - Japan
PPTX
ちゃんとした C# プログラムを書けるようになる実践的な方法~ Visual Studio を使った 高品質・低コスト・保守性の高い開発
by
慎一 古賀
PDF
データベース01 - データベースとは
by
Kenta Oku
PDF
ドメイン駆動で開発する ラフスケッチから実装まで
by
増田 亨
PDF
2025年現在のNewSQL (最強DB講義 #36 発表資料)
by
NTT DATA Technology & Innovation
PPTX
トランザクションの設計と進化
by
Kumazaki Hiroki
PDF
MySQLアーキテクチャ図解講座
by
Mikiya Okuno
PDF
ソーシャルゲームのためのデータベース設計
by
Yoshinori Matsunobu
PDF
SQLアンチパターン - ジェイウォーク
by
ke-m kamekoopa
PDF
ドメイン駆動設計という仕事の流儀
by
増田 亨
PDF
MongoDB〜その性質と利用場面〜
by
Naruhiko Ogasawara
PDF
速習!論理レプリケーション ~基礎から最新動向まで~(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
PPTX
基本情報技術者試験 勉強会
by
Yusuke Furuta
PDF
AWSとオンプレミスを繋ぐときに知っておきたいルーティングの基礎知識(CCSI監修!)
by
Trainocate Japan, Ltd.
PDF
データベース設計徹底指南
by
Mikiya Okuno
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
by
Recruit Technologies
WayOfNoTrouble.pptx
by
Daisuke Yamazaki
がっつりMongoDB事例紹介
by
Tetsutaro Watanabe
Redisの特徴と活用方法について
by
Yuji Otani
監査要件を有するシステムに対する PostgreSQL 導入の課題と可能性
by
Ohyama Masanori
Google Cloud Dataflow を理解する - #bq_sushi
by
Google Cloud Platform - Japan
ちゃんとした C# プログラムを書けるようになる実践的な方法~ Visual Studio を使った 高品質・低コスト・保守性の高い開発
by
慎一 古賀
データベース01 - データベースとは
by
Kenta Oku
ドメイン駆動で開発する ラフスケッチから実装まで
by
増田 亨
2025年現在のNewSQL (最強DB講義 #36 発表資料)
by
NTT DATA Technology & Innovation
トランザクションの設計と進化
by
Kumazaki Hiroki
MySQLアーキテクチャ図解講座
by
Mikiya Okuno
ソーシャルゲームのためのデータベース設計
by
Yoshinori Matsunobu
SQLアンチパターン - ジェイウォーク
by
ke-m kamekoopa
ドメイン駆動設計という仕事の流儀
by
増田 亨
MongoDB〜その性質と利用場面〜
by
Naruhiko Ogasawara
速習!論理レプリケーション ~基礎から最新動向まで~(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
基本情報技術者試験 勉強会
by
Yusuke Furuta
AWSとオンプレミスを繋ぐときに知っておきたいルーティングの基礎知識(CCSI監修!)
by
Trainocate Japan, Ltd.
データベース設計徹底指南
by
Mikiya Okuno
Viewers also liked
PDF
データベース13 - トランザクションと障害回復
by
Kenta Oku
PDF
情報推薦システム入門:講義スライド
by
Kenta Oku
PDF
データベース02 - SQL概要
by
Kenta Oku
PDF
ICDE2014 Session 22 Similarity Joins
by
Masumi Shirakawa
PDF
ICDE 2014参加報告資料
by
Masumi Shirakawa
PDF
WWW2014 Session 16: Content Analysis 2 - Topics
by
Masumi Shirakawa
PDF
データベース08 - 関係データモデルと関係代数
by
Kenta Oku
PDF
VLDB2015 会議報告
by
Yuto Hayamizu
PDF
N-gram IDF: A Global Term Weighting Scheme Based on Information Distance (WWW...
by
Masumi Shirakawa
PDF
MySQL INDEX+EXPLAIN入門
by
infinite_loop
データベース13 - トランザクションと障害回復
by
Kenta Oku
情報推薦システム入門:講義スライド
by
Kenta Oku
データベース02 - SQL概要
by
Kenta Oku
ICDE2014 Session 22 Similarity Joins
by
Masumi Shirakawa
ICDE 2014参加報告資料
by
Masumi Shirakawa
WWW2014 Session 16: Content Analysis 2 - Topics
by
Masumi Shirakawa
データベース08 - 関係データモデルと関係代数
by
Kenta Oku
VLDB2015 会議報告
by
Yuto Hayamizu
N-gram IDF: A Global Term Weighting Scheme Based on Information Distance (WWW...
by
Masumi Shirakawa
MySQL INDEX+EXPLAIN入門
by
infinite_loop
Similar to データベース14 - データベース構造とインデックス
PDF
データベース05 - SQL(SELECT:結合,副問合せ)
by
Kenta Oku
PDF
2018年度 若手技術者向け講座 インデックス
by
keki3
PDF
2019年度若手技術者向け講座 インデックス
by
keki3
PDF
pg_trgmと全文検索
by
NTT DATA OSS Professional Services
PDF
データベース技術 3(Database_3)
by
Yuka Obu
PDF
データベースシステム論12 - 問い合わせ処理と最適化
by
Shohei Yokoyama
PDF
PostgreSQL18新機能紹介(db tech showcase 2025 発表資料)
by
NTT DATA Technology & Innovation
PDF
ISUCONで学ぶ Webアプリケーションのパフォーマンス向上のコツ 実践編 完全版
by
Masahiro Nagano
PDF
MySQL 5.5 Update #denatech
by
Mikiya Okuno
PDF
SQL Server チューニング基礎
by
Microsoft
PPTX
押さえておきたい、PostgreSQL 13 の新機能!! (PostgreSQL Conference Japan 2020講演資料)
by
NTT DATA Technology & Innovation
PPTX
押さえておきたい、PostgreSQL 13 の新機能!!(Open Source Conference 2021 Online/Hokkaido 発表資料)
by
NTT DATA Technology & Innovation
PDF
データベースシステム論06 - SQL基礎演習1 データの定義と操作
by
Shohei Yokoyama
PDF
Wtm
by
Soudai Sone
PDF
SQLアンチパターン - 開発者を待ち受ける25の落とし穴 (拡大版)
by
Takuto Wada
PDF
JPUGしくみ+アプリケーション勉強会(第20回)
by
Yoshinori Nakanishi
PDF
MySQL Index勉強会外部公開用
by
CROOZ, inc.
PPTX
Tuning on my_sql
by
Edward D. Kim
PDF
2018年度 若手技術者向け講座 実行計画
by
keki3
PPT
SQLチューニング勉強会資料
by
Shinnosuke Akita
データベース05 - SQL(SELECT:結合,副問合せ)
by
Kenta Oku
2018年度 若手技術者向け講座 インデックス
by
keki3
2019年度若手技術者向け講座 インデックス
by
keki3
pg_trgmと全文検索
by
NTT DATA OSS Professional Services
データベース技術 3(Database_3)
by
Yuka Obu
データベースシステム論12 - 問い合わせ処理と最適化
by
Shohei Yokoyama
PostgreSQL18新機能紹介(db tech showcase 2025 発表資料)
by
NTT DATA Technology & Innovation
ISUCONで学ぶ Webアプリケーションのパフォーマンス向上のコツ 実践編 完全版
by
Masahiro Nagano
MySQL 5.5 Update #denatech
by
Mikiya Okuno
SQL Server チューニング基礎
by
Microsoft
押さえておきたい、PostgreSQL 13 の新機能!! (PostgreSQL Conference Japan 2020講演資料)
by
NTT DATA Technology & Innovation
押さえておきたい、PostgreSQL 13 の新機能!!(Open Source Conference 2021 Online/Hokkaido 発表資料)
by
NTT DATA Technology & Innovation
データベースシステム論06 - SQL基礎演習1 データの定義と操作
by
Shohei Yokoyama
Wtm
by
Soudai Sone
SQLアンチパターン - 開発者を待ち受ける25の落とし穴 (拡大版)
by
Takuto Wada
JPUGしくみ+アプリケーション勉強会(第20回)
by
Yoshinori Nakanishi
MySQL Index勉強会外部公開用
by
CROOZ, inc.
Tuning on my_sql
by
Edward D. Kim
2018年度 若手技術者向け講座 実行計画
by
keki3
SQLチューニング勉強会資料
by
Shinnosuke Akita
データベース14 - データベース構造とインデックス
1.
データベース 第14回 データベース構造とインデックス 1 2015年7⽉9⽇(⽊) 7・8時限 担当:奥 健太
2.
トランザクションと データベース構造編 回 ⽇付 テーマ 12
6/25 トランザクションと同時実⾏制御 13 7/2 トランザクションと障害回復 14 7/9 データベース構造とインデックス 2
3.
トランザクションと データベース構造編での学習⽬標 3 トランザクションを理解する データベースの同時実⾏制御の仕組みを理解する
データベースの障害回復⽅法を理解する 効率的なデータアクセスのためのデータ ベース構造およびインデックスを理解する
4.
効率的なデータアクセス機構 4 vs. 復習
5.
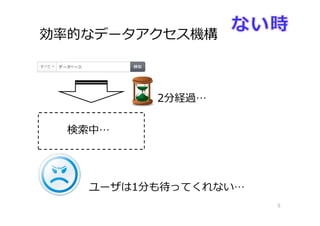
効率的なデータアクセス機構 5 2分経過… ユーザは1分も待ってくれない… 検索中…
6.
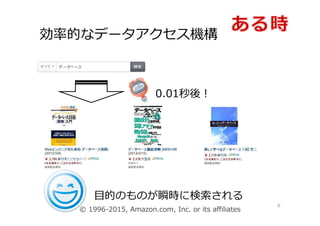
効率的なデータアクセス機構 6 0.01秒後! ⽬的のものが瞬時に検索される © 1996-2015, Amazon.com,
Inc. or its affiliates
7.
効率的なデータアクセス機構 回 ⽇付 テーマ 12
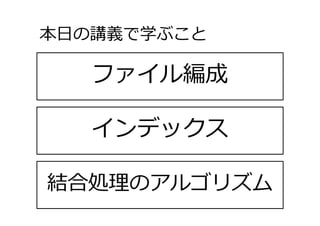
6/25 トランザクションと同時実⾏制御 13 7/2 トランザクションと障害回復 14 7/9 データベース構造とインデックス 7 データベース構造,ファイル編成,イン デックスについて学ぶ
8.
ファイル編成 本⽇の講義で学ぶこと 8 インデックス 結合処理のアルゴリズム
9.
⼤量のデータの管理 9 記憶領域の格納効率 検索効率
10.
⼤量のデータを 効率良く管理せよ 10
11.
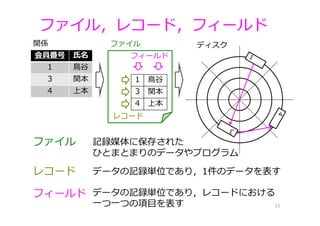
フィールド レコード ファイル ファイル,レコード,フィールド 11 会員番号 ⽒名 1 ⿃⾕ 3
関本 4 上本 1 ⿃⾕ 3 関本 4 上本 ディスク関係 ファイル 記録媒体に保存された ひとまとまりのデータやプログラム レコード データの記録単位であり,1件のデータを表す フィールド データの記録単位であり,レコードにおける ⼀つ⼀つの項⽬を表す
12.
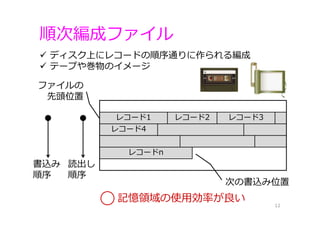
順次編成ファイル 12 ディスク上にレコードの順序通りに作られる編成 テープや巻物のイメージ レコード1
レコード2 レコード3 レコード4 レコードn 書込み 順序 読出し 順序 ファイルの 先頭位置 次の書込み位置 記憶領域の使⽤効率が良い
13.
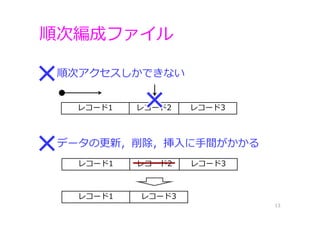
順次編成ファイル 13 順次アクセスしかできない データの更新,削除,挿⼊に⼿間がかかる レコード1 レコード2 レコード3 レコード1
レコード2 レコード3 レコード1 レコード3
14.
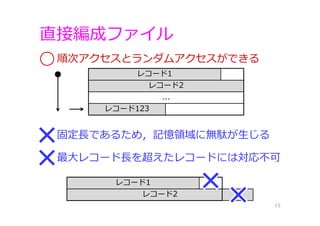
直接編成ファイル 14 レコードをある単位ごとにディスクの場所におき,その 番地を直接指定することで読書きができる編成 レコード1 レコード2 ... レコード123 ... レコードn ... レコード 先頭位置 1バイト⽬ 101バイト⽬ 12,201バイト⽬ 100バイト固定⻑ レコード123はどこにある? 100 ×
(123 - 1) + 1 = 12,201バイト⽬
15.
直接編成ファイル 15 固定⻑であるため,記憶領域に無駄が⽣じる 順次アクセスとランダムアクセスができる レコード1 レコード2 ... レコード123 レコード1 レコード2 最⼤レコード⻑を超えたレコードには対応不可
16.
可変⻑でデータを ⾼速に検索する⽅法は? 16
17.
本の索引 17
18.
索引編成ファイル レコードのキー値から作成した索引(インデックス)を もつ編成 レコードのキー値 格納先の位置 1
1バイト⽬ 2 83バイト⽬ 3 183バイト⽬ ... 123 9,629バイト⽬ インデックスファイル レコード1 レコード2 レコード3 レコード123 レコードn 順次編成ファイル レコード123は どこにある? 検索効率が⽐較的良い レコードの挿⼊や 削除が⽐較的容易
19.
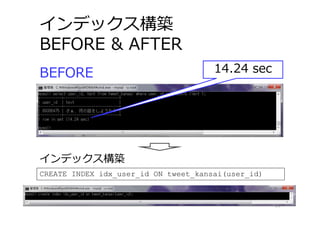
インデックス構築 BEFORE & AFTER 19 BEFORE CREATE
INDEX idx_user_id ON tweet_kansai(user_id) インデックス構築 14.24 sec
20.
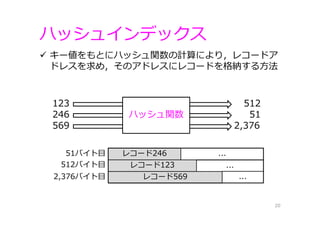
ハッシュインデックス 20 キー値をもとにハッシュ関数の計算により,レコードア ドレスを求め,そのアドレスにレコードを格納する⽅法 51バイト⽬ 512バイト⽬ 2,376バイト⽬ レコード246 レコード123 ... ... ...レコード569 123 512 246
51 569 2,376 ハッシュ関数
21.
ハッシュ関数の種類 21 ⾃乗・中央法 キー値を⾃乗して中央の数字をアドレスとする 246 × 246
= 60516 除算法 キー値をある値で割った余りをアドレスとする 246 ÷ 61 = 4 あまり 2 基数変換法 キー値の基数を変換して下の桁をアドレスとする (246)16=2 × 162 + 4 × 161 + 6 × 160 = 582
22.
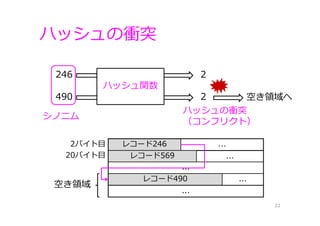
ハッシュの衝突 22 246 2 490 2 ハッシュ関数 ハッシュの衝突 (コンフリクト) 2バイト⽬ 20バイト⽬ レコード246 レコード569 ... ... ... レコード490
... ... 空き領域 空き領域へ シノニム
23.
ハッシュインデックス 23 検索効率がデータ量に依存しない シノニムの発⽣が増えると, アクセス効率が低下する 範囲検索には利⽤できない ソートには利⽤できない
24.
B⽊インデックス 24
25.
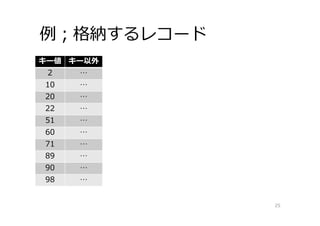
例;格納するレコード 25 キー値 キー以外 2 … 10
… 20 … 22 … 51 … 60 … 71 … 89 … 90 … 98 …
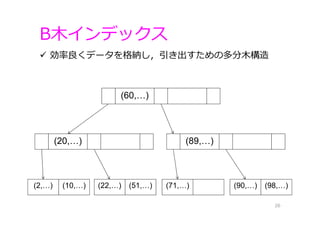
26.
B⽊インデックス 26 効率良くデータを格納し,引き出すための多分⽊構造 (60,…) (20,…) (2,…) (10,…)
(22,…) (51,…) (71,…) (90,…) (98,…) (89,…)
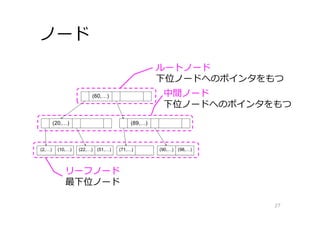
27.
ノード 27 ルートノード 下位ノードへのポインタをもつ 中間ノード 下位ノードへのポインタをもつ リーフノード 最下位ノード
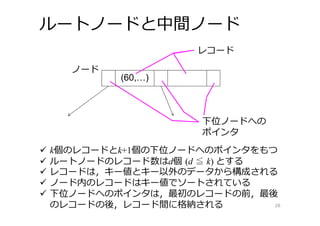
28.
ルートノードと中間ノード (60,…) k個のレコードとk+1個の下位ノードへのポインタをもつ ルートノードのレコード数はd個
(d ≦ k) とする レコードは,キー値とキー以外のデータから構成される ノード内のレコードはキー値でソートされている 下位ノードへのポインタは,最初のレコードの前,最後 のレコードの後,レコード間に格納される レコードレコード レコードレコード下位ノードへの ポインタ ノード 28
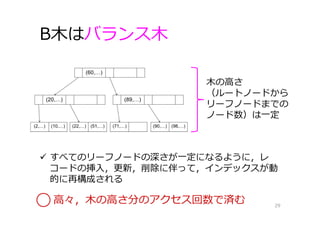
29.
B⽊はバランス⽊ 29 ⽊の⾼さ (ルートノードから リーフノードまでの ノード数)は⼀定 すべてのリーフノードの深さが⼀定になるように,レ コードの挿⼊,更新,削除に伴って,インデックスが動 的に再構成される ⾼々,⽊の⾼さ分のアクセス回数で済む
30.
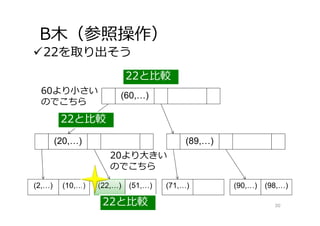
B⽊(参照操作) 22を取り出そう 30 (60,…) (20,…) (2,…) (10,…) (22,…)
(51,…) (71,…) (90,…) (98,…) (89,…) 22と⽐較 22と⽐較 60より⼩さい のでこちら 20より⼤きい のでこちら 22と⽐較
31.
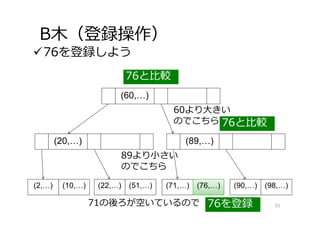
B⽊(登録操作) 76を登録しよう 31 (60,…) (20,…) (2,…) (10,…) (22,…)
(51,…) (71,…) (90,…) (98,…) (89,…) 76と⽐較 76と⽐較 60より⼤きい のでこちら 89より⼩さい のでこちら 76を登録 (76,…) 71の後ろが空いているので
32.
B⽊(登録操作) 93を登録しよう 32 (60,…) (20,…) (2,…) (10,…) (22,…)
(51,…) (71,…) (90,…) (98,…) (89,…) 93と⽐較 93と⽐較 60より⼤きい のでこちら 89より⼤きい のでこちら 93と⽐較90と98の間が空いていない
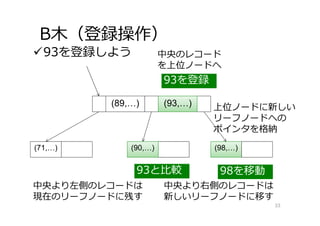
33.
B⽊(登録操作) 93を登録しよう 33 (71,…) (90,…) (98,…) (89,…) 93と⽐較 中央のレコード を上位ノードへ (93,…) 93を登録 中央より左側のレコードは 現在のリーフノードに残す (98,…) 中央より右側のレコードは 新しいリーフノードに移す 98を移動 (90,…) 上位ノードに新しい リーフノードへの ポインタを格納
34.
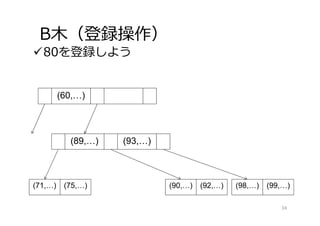
B⽊(登録操作) 80を登録しよう (60,…) (71,…) (75,…) (90,…)
(92,…) (89,…) (93,…) (98,…) (99,…) 34
35.
B⽊(登録操作) 80を登録しよう (60,…) (71,…) (75,…) (90,…)
(92,…) (89,…) (93,…) (98,…) (99,…) 80と⽐較 75と⽐較 89を登録 (75,…) (89,…) 35
36.
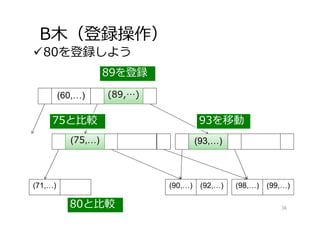
B⽊(登録操作) 80を登録しよう (60,…) (71,…) (75,…) (90,…)
(92,…) (89,…) (93,…) (98,…) (99,…) 80と⽐較 75と⽐較 89を登録 (75,…) (89,…) (93,…) 36 93を移動
37.
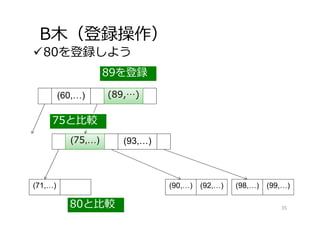
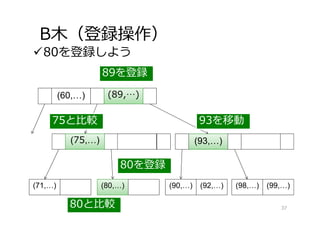
B⽊(登録操作) 80を登録しよう (60,…) (71,…) (75,…) (90,…)
(92,…) (89,…) (93,…) (98,…) (99,…) 80と⽐較 75と⽐較 89を登録 (75,…) (89,…) (93,…) 37 (80,…) 80を登録 93を移動
38.
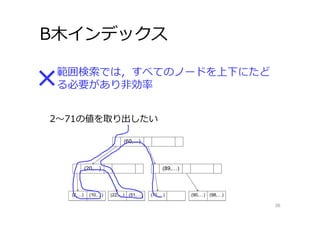
B⽊インデックス 38 範囲検索では,すべてのノードを上下にたど る必要があり⾮効率 2〜71の値を取り出したい
39.
B+⽊インデックス 39 B⽊インデックスを改良
40.
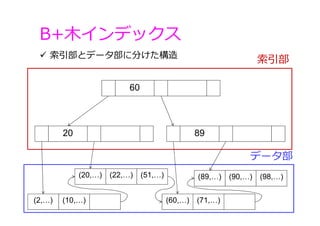
B+⽊インデックス 索引部 データ部 索引部とデータ部に分けた構造 60 20 (2,…) (10,…) (20,…)
(22,…) (60,…) (71,…) (89,…) (90,…) 89 (51,…) (98,…)
41.
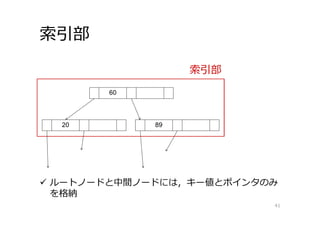
索引部 41 索引部 ルートノードと中間ノードには,キー値とポインタのみ を格納
42.
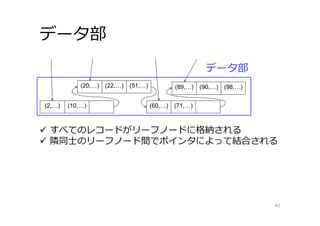
データ部 42 データ部 すべてのレコードがリーフノードに格納される 隣同⼠のリーフノード間でポインタによって結合される
43.
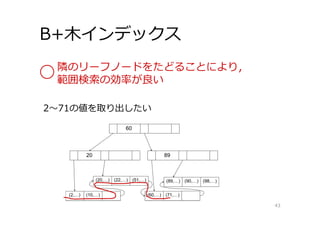
B+⽊インデックス 43 2〜71の値を取り出したい 隣のリーフノードをたどることにより, 範囲検索の効率が良い
44.
インデックス構築 BEFORE & AFTER 44 BEFORE AFTER 14.24
sec 0.01 sec
45.
SHOW INDEX FROM
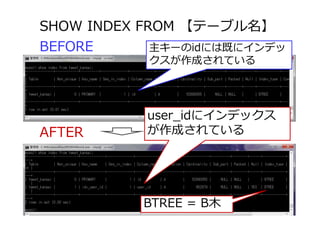
【テーブル名】 45 BEFORE AFTER user_idにインデックス が作成されている BTREE = B⽊ 主キーのidには既にインデッ クスが作成されている
46.
EXPLAIN 【SELECT⽂】 46 BEFORE AFTER ALL: フルテーブルスキャン (インデックス未使⽤) ref:
UNIQUEでないインデッ クスを使った等価検索 インデックスidx_user_idを使⽤
47.
結合処理の アルゴリズム 47
48.
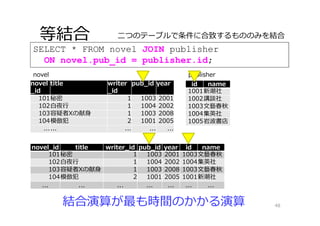
SELECT * FROM
novel JOIN publisher ON novel.pub_id = publisher.id; 等結合 48 novel_id title writer_id pub_id year id name 101秘密 1 1003 2001 1003⽂藝春秋 102⽩夜⾏ 1 1004 2002 1004集英社 103容疑者Xの献⾝ 1 1003 2008 1003⽂藝春秋 104模倣犯 2 1001 2005 1001新潮社 ... ... ... ... ... ... ... novel _id title writer _id pub_id year 101秘密 1 1003 2001 102⽩夜⾏ 1 1004 2002 103容疑者Xの献⾝ 1 1003 2008 104模倣犯 2 1001 2005 ...... ... ... ... novel id name 1001新潮社 1002講談社 1003⽂藝春秋 1004集英社 1005岩波書店 publisher ⼆つのテーブルで条件に合致するもののみを結合 結合演算が最も時間のかかる演算
49.
⼊れ⼦結合 49 . . (1) 駆動表の各⾏について,内部表を1⾏ずつスキャンし, 結合条件に合致するかチェック (2) 条件に合致していれば,結合した⾏を出⼒ 駆動表または外部表 内部表 novel _id title
writer _id pub _id year 101秘密 1 1003 2001 102⽩夜⾏ 1 1004 2002 103容疑者Xの献⾝ 1 1003 2008 104模倣犯 2 1001 2005 105⽕⾞ 2 1001 1998 1061Q84 3 1001 2009 107⾵の歌を聴け 3 1002 2004 108海辺のカフカ 3 1001 2002 109ノルウェイの森 3 1002 1987 110使命と魂のリミット 1 1006 2010 novel id name 1001新潮社 1002講談社 1003⽂藝春秋 1004集英社 1005岩波書店 publisher
50.
id name 1001新潮社 1002講談社 1003⽂藝春秋 1004集英社 1005岩波書店 novel _id title writer _id pub _id year 101秘密
1 1003 2001 102⽩夜⾏ 1 1004 2002 103容疑者Xの献⾝ 1 1003 2008 104模倣犯 2 1001 2005 105⽕⾞ 2 1001 1998 1061Q84 3 1001 2009 107⾵の歌を聴け 3 1002 2004 108海辺のカフカ 3 1001 2002 109ノルウェイの森 3 1002 1987 110使命と魂のリミット 1 1006 2010 インデックスによる結合 50 novel (1) 駆動表の各⾏について,内部表からインデックスをた どって,結合キーが合致する⾏を検索 (2) 検索された⾏を結合した⾏を出⼒ 駆動表または外部表 内部表 publisher 内部表のid に対するイ ンデックス
51.
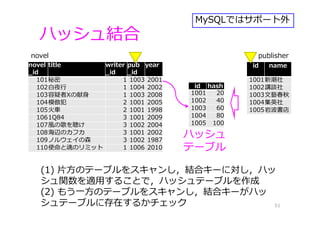
id name 1001新潮社 1002講談社 1003⽂藝春秋 1004集英社 1005岩波書店 novel _id title writer _id pub _id year 101秘密
1 1003 2001 102⽩夜⾏ 1 1004 2002 103容疑者Xの献⾝ 1 1003 2008 104模倣犯 2 1001 2005 105⽕⾞ 2 1001 1998 1061Q84 3 1001 2009 107⾵の歌を聴け 3 1002 2004 108海辺のカフカ 3 1001 2002 109ノルウェイの森 3 1002 1987 110使命と魂のリミット 1 1006 2010 ハッシュ結合 51 novel (1) ⽚⽅のテーブルをスキャンし,結合キーに対し,ハッ シュ関数を適⽤することで,ハッシュテーブルを作成 (2) もう⼀⽅のテーブルをスキャンし,結合キーがハッ シュテーブルに存在するかチェック id hash 1001 20 1002 40 1003 60 1004 80 1005 100 ハッシュ テーブル publisher MySQLではサポート外
52.
マージ結合 52 id name 1001新潮社 1002講談社 1003⽂藝春秋 1004集英社 1005岩波書店 novel _id title writer _id pub _id year 104模倣犯
2 1001 2005 105⽕⾞ 2 1001 1998 1061Q84 3 1001 2009 108海辺のカフカ 3 1001 2002 107⾵の歌を聴け 3 1002 2004 109ノルウェイの森 3 1002 1987 101秘密 1 1003 2001 103容疑者Xの献⾝ 1 1003 2008 102⽩夜⾏ 1 1004 2002 110使命と魂のリミット 1 1006 2010 novel pub_idでソート済み idで ソート済み . . . . . . . (1) あらかじめ両⽅のテーブルを結合キーでソート (2) ソートされたテーブルの各値を⽐較しながら,結合条 件をチェック publisher MySQLではサポート外
53.
EXPLAIN 【SELECT⽂】 53 Block Nested
Loop: ⼊れ⼦結合の改良版
54.
ファイル編成 まとめ 54 インデックス 結合処理のアルゴリズム
55.
まとめ 55 ⼊れ⼦結合 インデックスによる結合 ハッシュ結合 マージ結合 ハッシュインデックス B⽊インデックス B+⽊インデックス 順次編成ファイル 直接編成ファイル 索引編成ファイル
56.
本⽇学習したキーワード 〜トランザクションとデータベース構造編〜 56 2相ロッキング 縮退相 ハッシュ関数 ACID特性
順次編成ファイル ハッシュ結合 Atomicity(原⼦性) 障害回復 ハッシュの衝突 B+⽊インデックス 除算法 バランス⽊ B⽊インデックス ⼈的障害 ビフォアイメージ Consistency(整合性) 成⻑相 ファイル Durability(耐久性) ダーティリード ファントムリード Isolation(隔離性) ダンプファイル フィールド WALプロトコル チェックポイント マージ結合 アフタイメージ 中間ノード 待合せグラフ ⼊れ⼦結合 直接編成ファイル リーフノード インデックス 直列化可能性 両⽴性⾏列 インデックスによる結合 データ部 ルートノード インデックスファイル データベースダンプ レコード 基数変換法 データベースバックアップ ロールバック 共有ロック デッドロック ロールフォワード 更新の喪失 同時実⾏制御 ロギング コミット トランザクション ログ(ジャーナル) 索引部 トランザクション障害 ログファイル 索引編成ファイル ノンリピータブルリード ロッキング ⾃乗・中央法 媒体障害 ロック システム障害 排他ロック シノニム ハッシュインデックス
57.
これまでに学習したキーワード 〜トランザクションとデータベース構造編〜 57 2相ロッキング 縮退相 ハッシュ関数 ACID特性
順次編成ファイル ハッシュ結合 Atomicity(原⼦性) 障害回復 ハッシュの衝突 B+⽊インデックス 除算法 バランス⽊ B⽊インデックス ⼈的障害 ビフォアイメージ Consistency(整合性) 成⻑相 ファイル Durability(耐久性) ダーティリード ファントムリード Isolation(隔離性) ダンプファイル フィールド WALプロトコル チェックポイント マージ結合 アフタイメージ 中間ノード 待合せグラフ ⼊れ⼦結合 直接編成ファイル リーフノード インデックス 直列化可能性 両⽴性⾏列 インデックスによる結合 データ部 ルートノード インデックスファイル データベースダンプ レコード 基数変換法 データベースバックアップ ロールバック 共有ロック デッドロック ロールフォワード 更新の喪失 同時実⾏制御 ロギング コミット トランザクション ログ(ジャーナル) 索引部 トランザクション障害 ログファイル 索引編成ファイル ノンリピータブルリード ロッキング ⾃乗・中央法 媒体障害 ロック システム障害 排他ロック シノニム ハッシュインデックス
Download