Downloaded 96 times






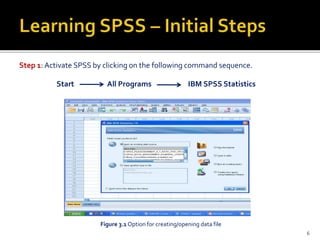


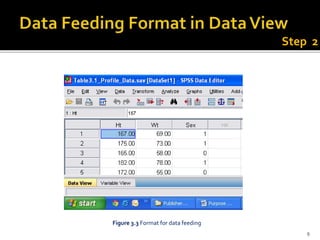


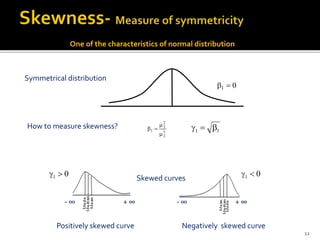


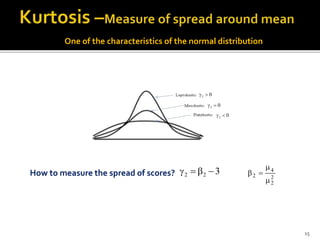

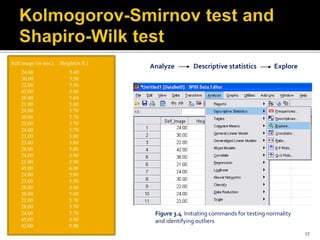
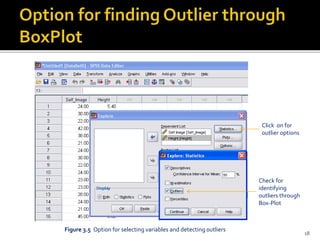
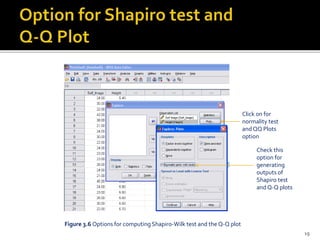


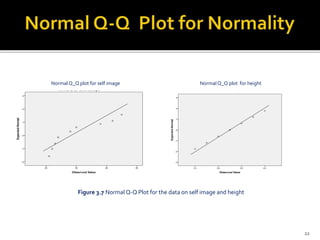



The document is a presentation by Dr. J.P. Verma on assumptions and data preparation for statistical analysis using SPSS, focusing on repeated measures design. It outlines important statistical concepts such as normality, skewness, and kurtosis, as well as step-by-step instructions for using SPSS software. Additionally, it discusses the implications of violating assumptions and offers guidelines for testing and analyzing data sets.























































































