






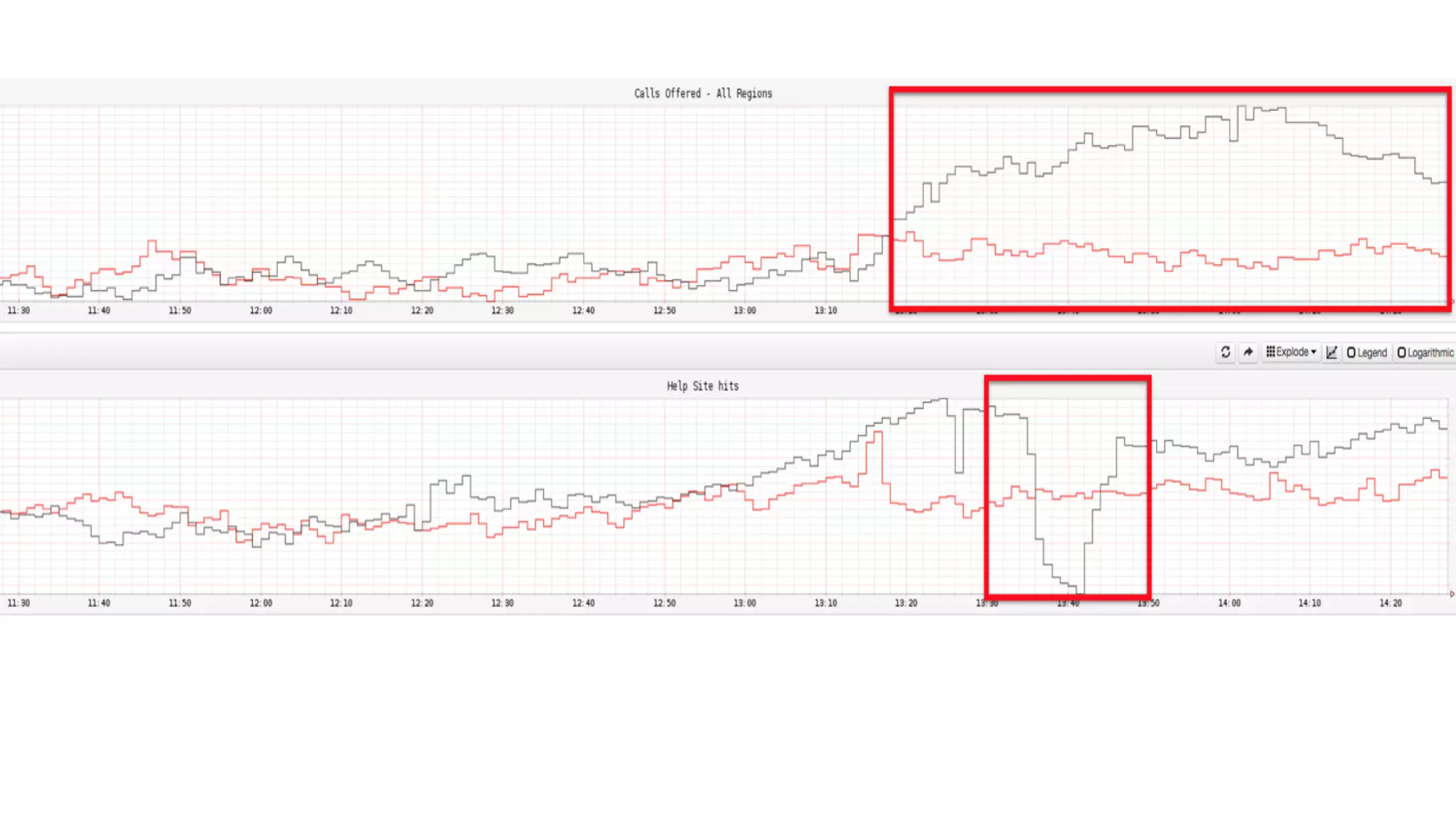






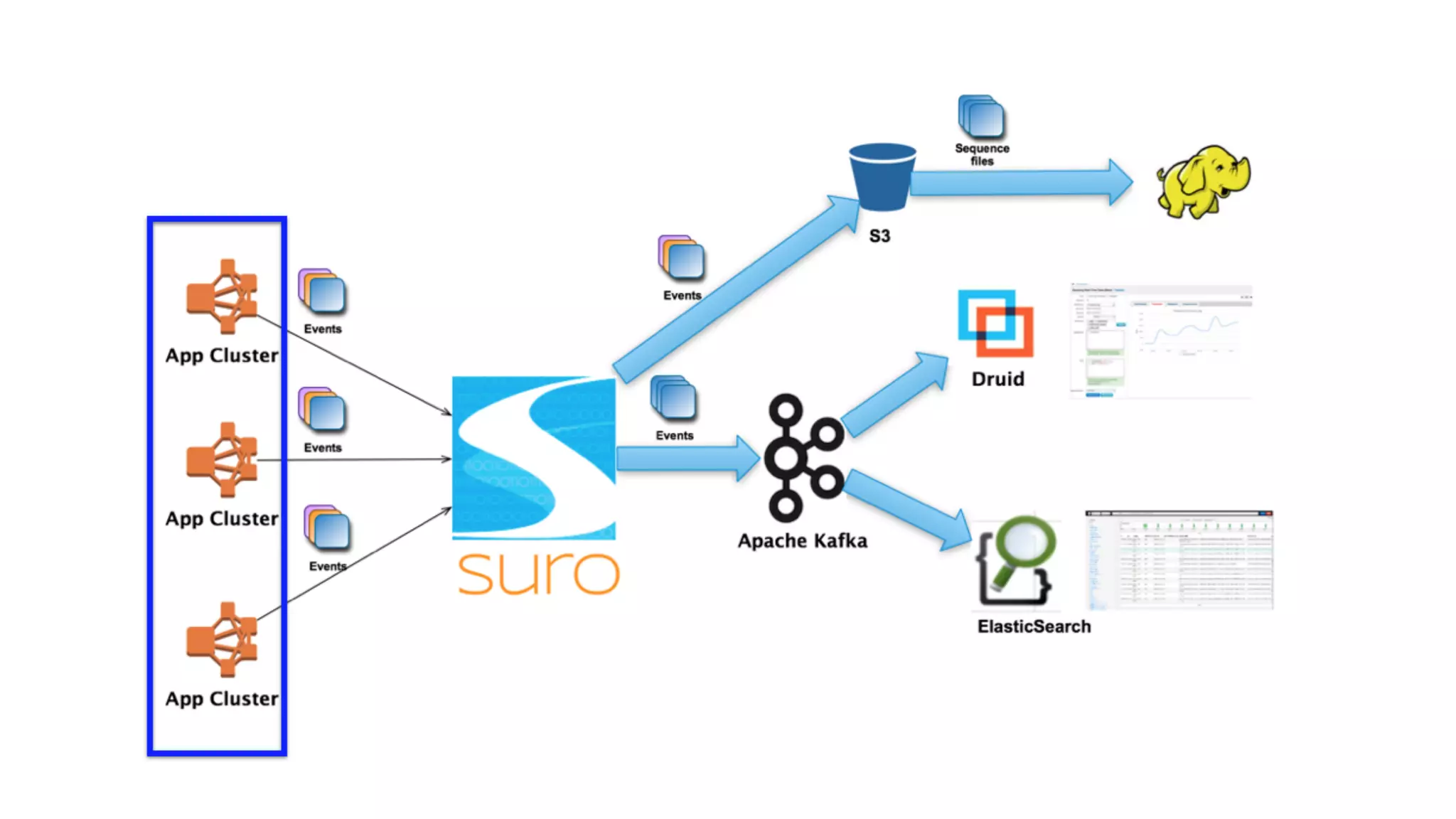
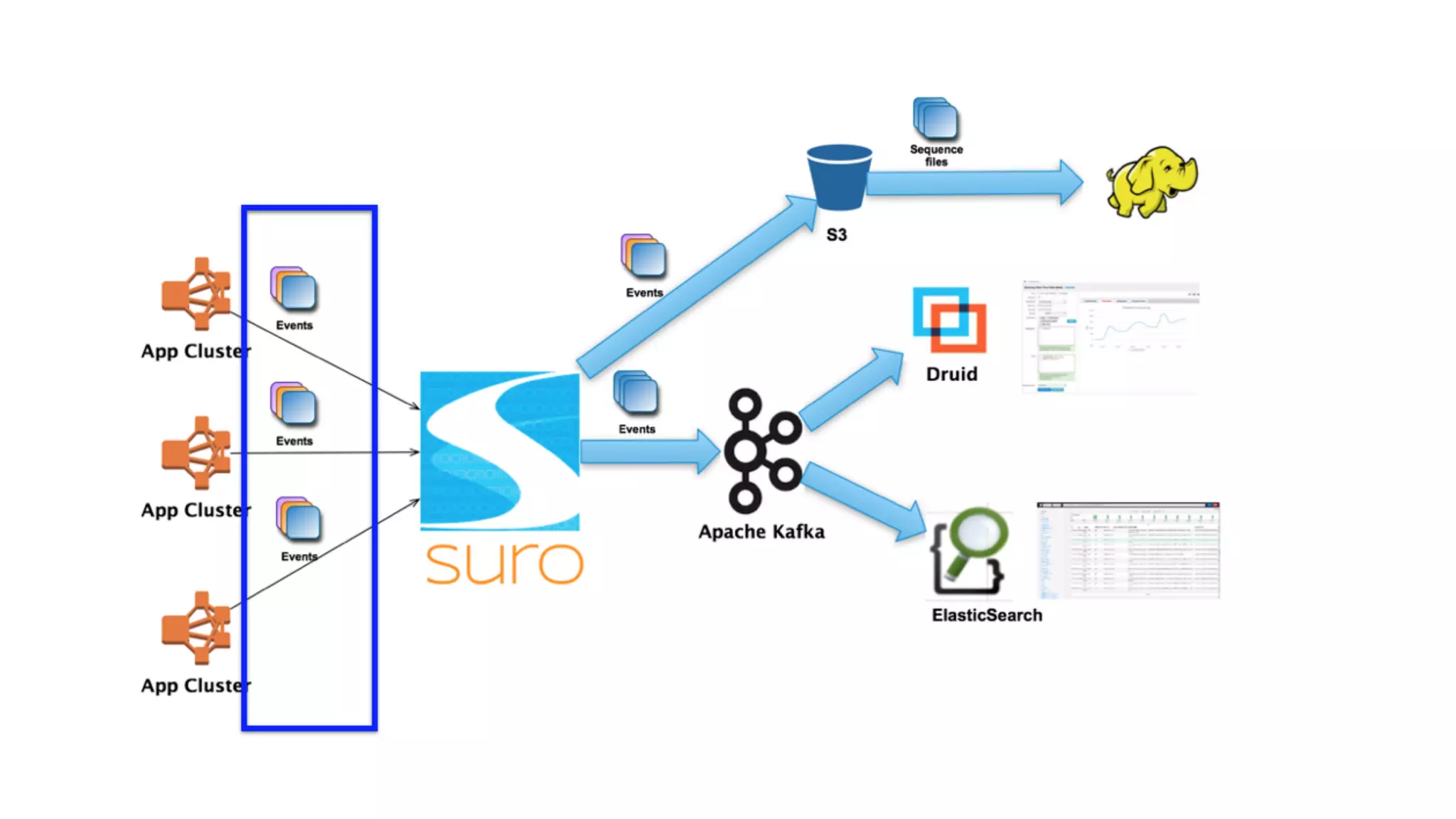

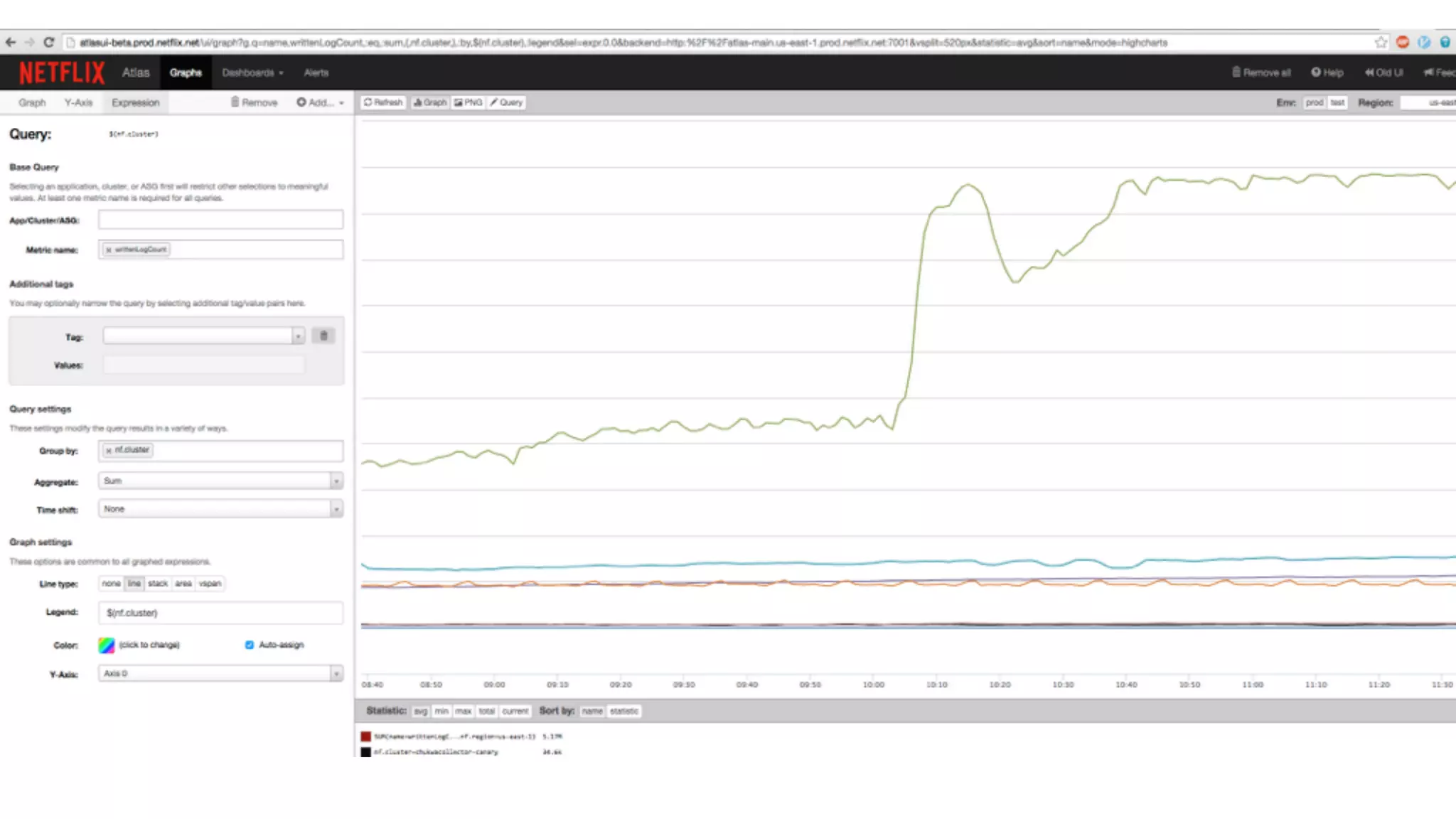
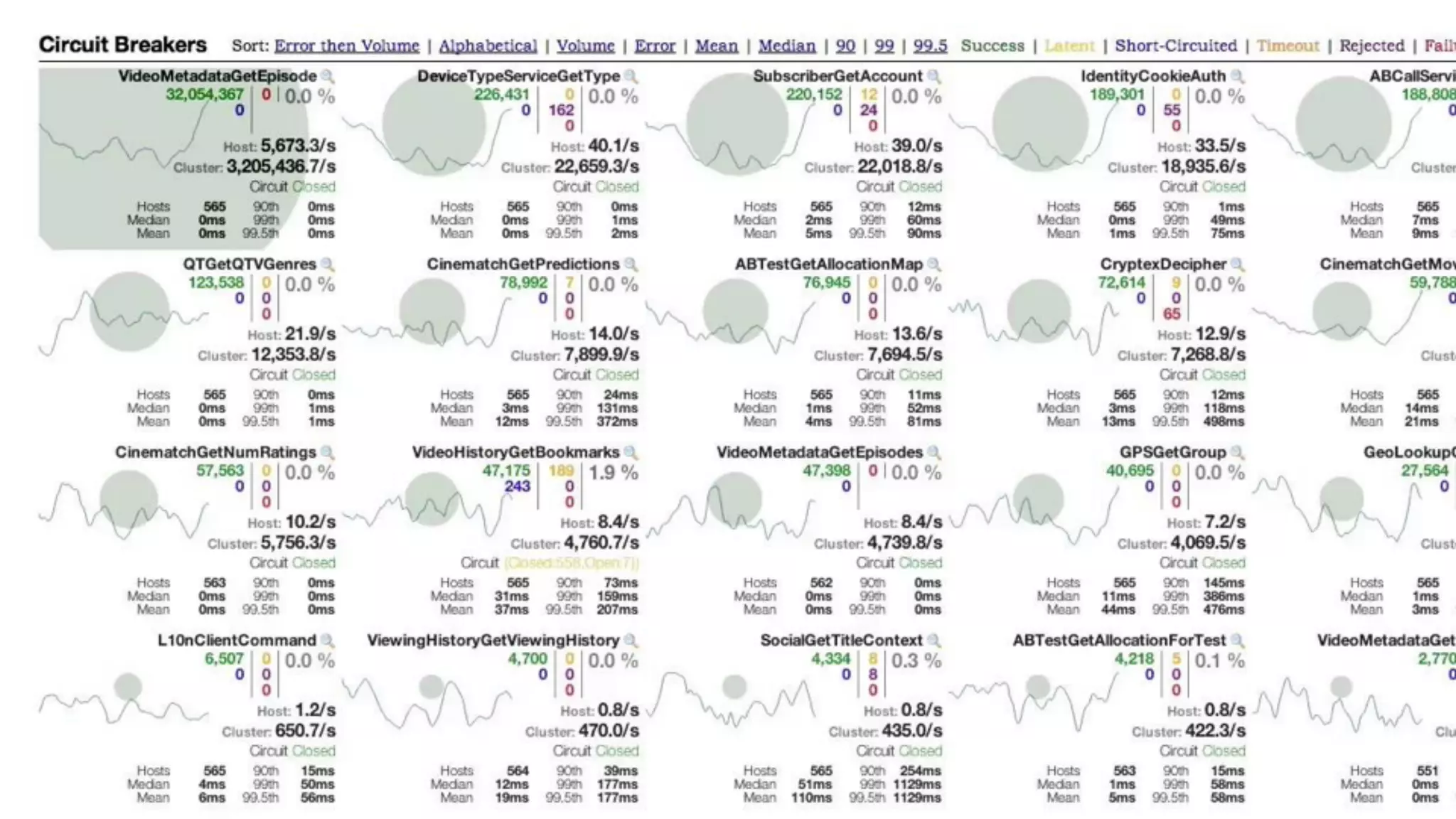
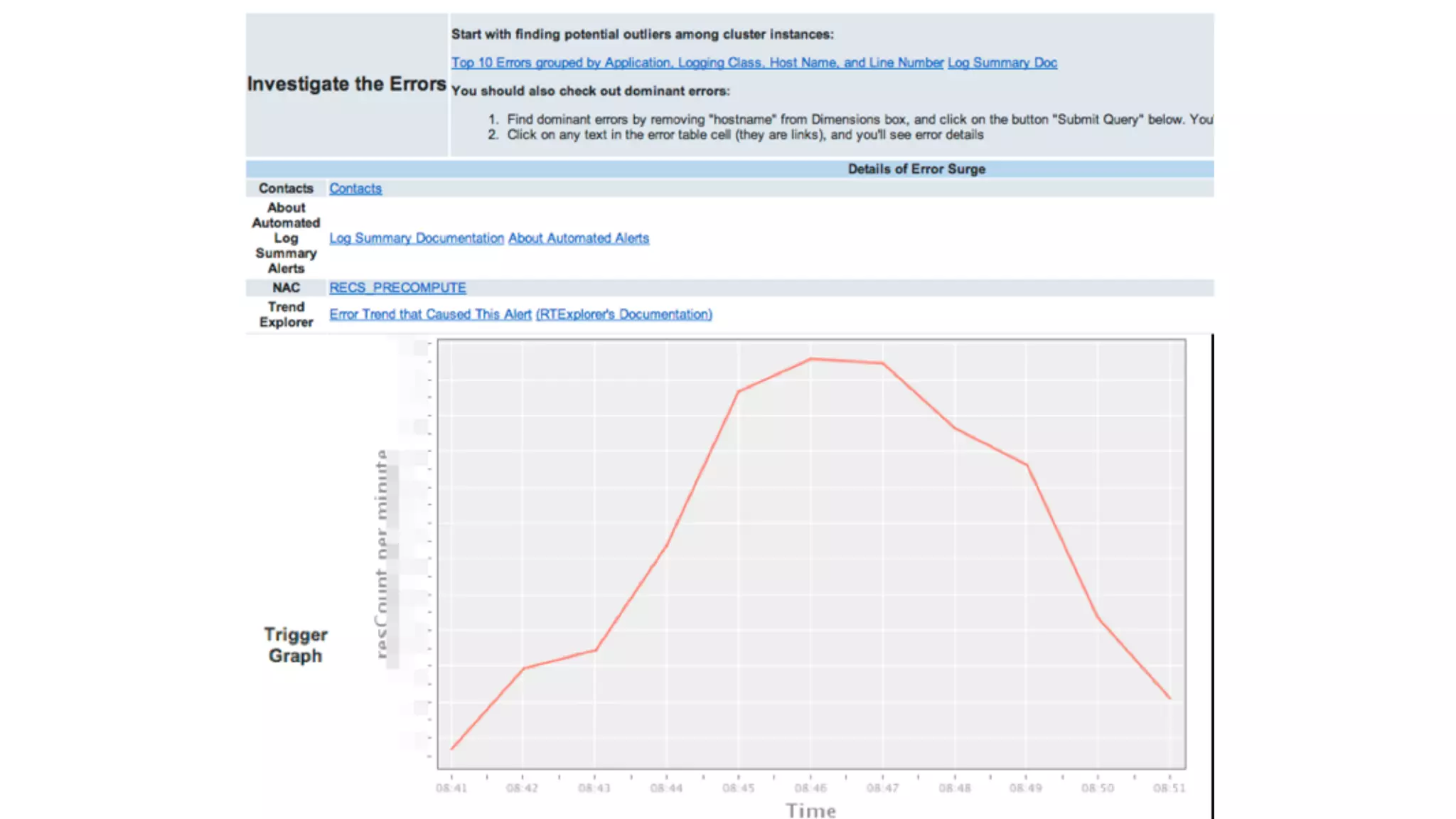
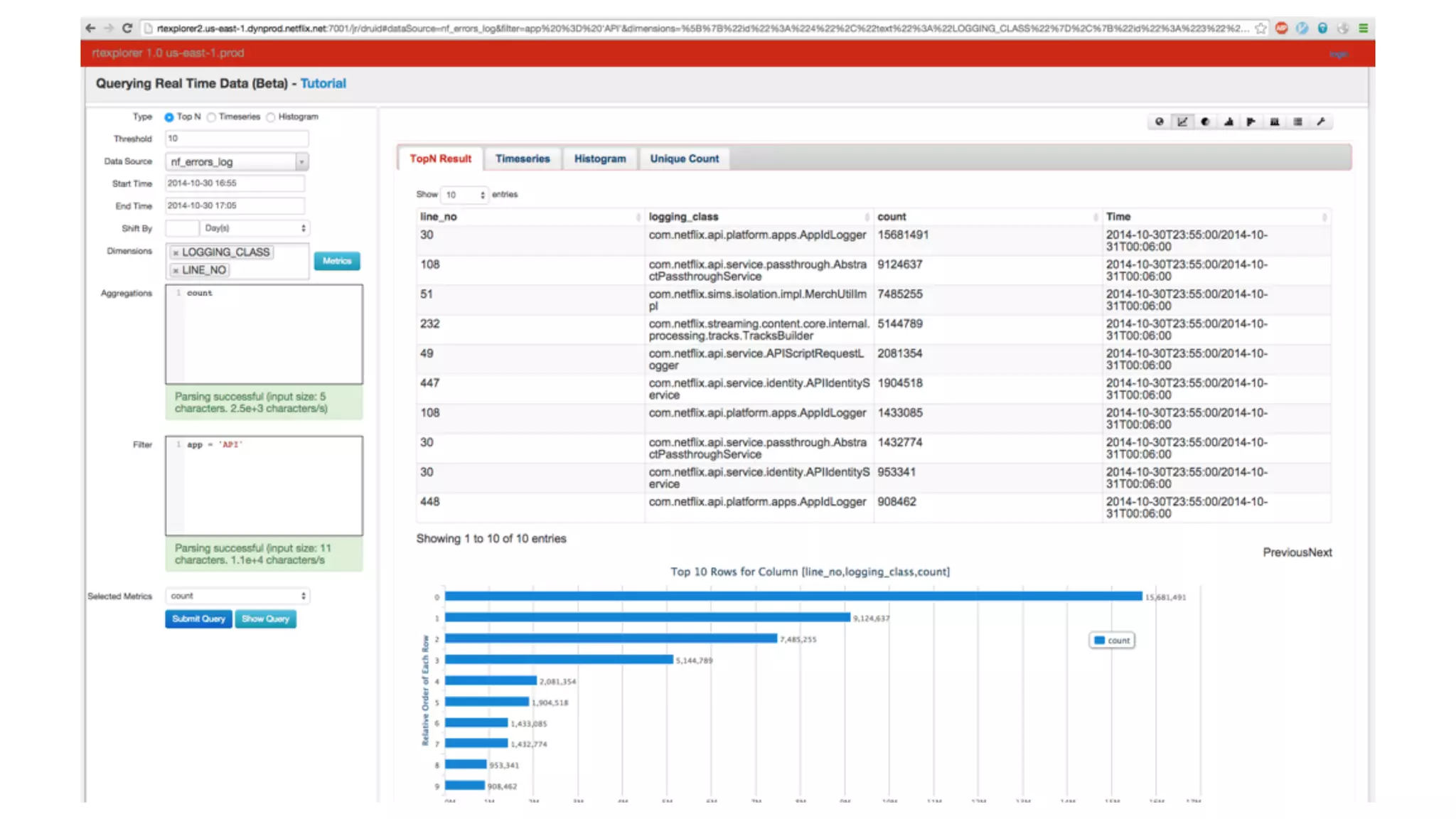
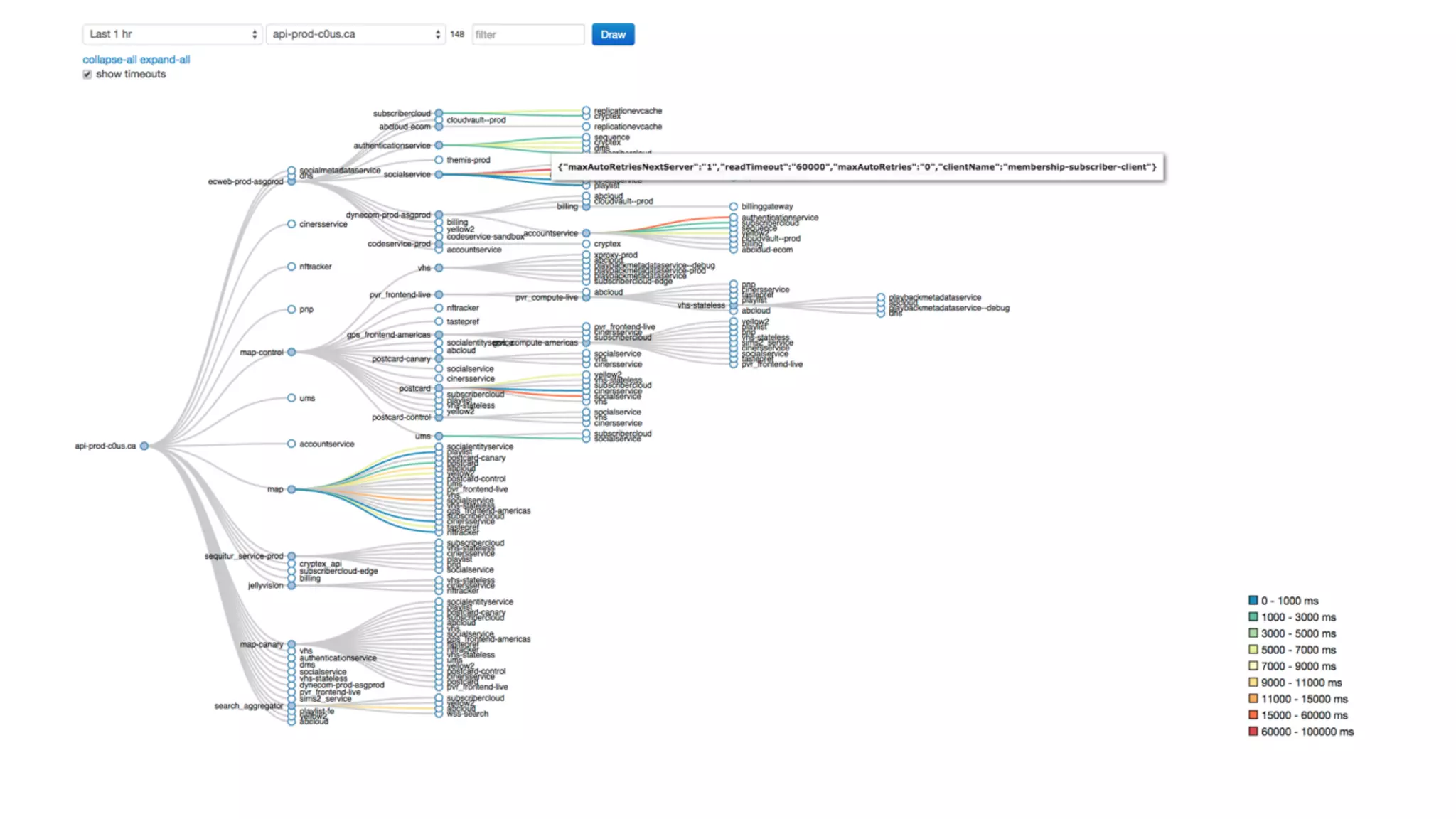





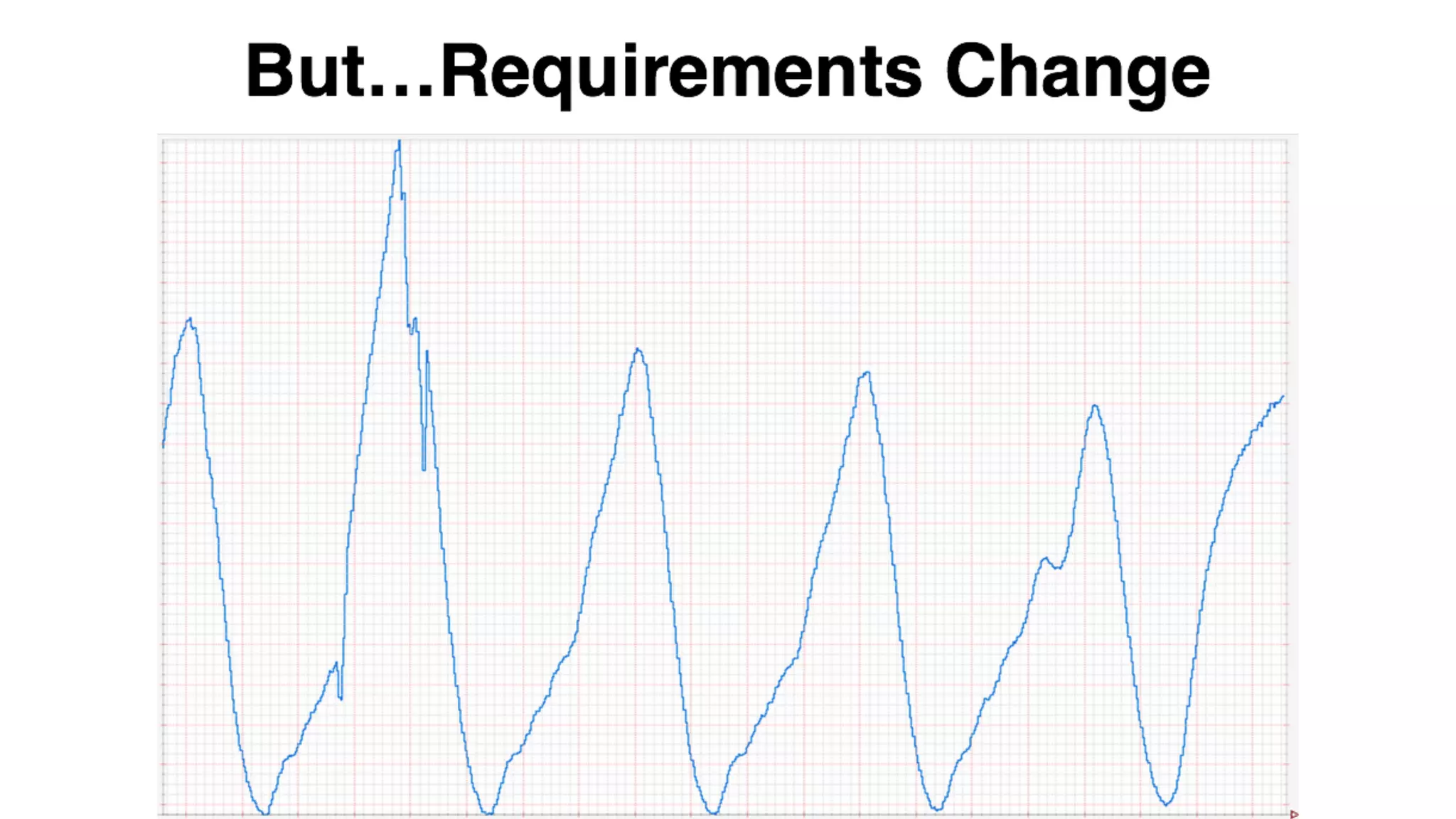


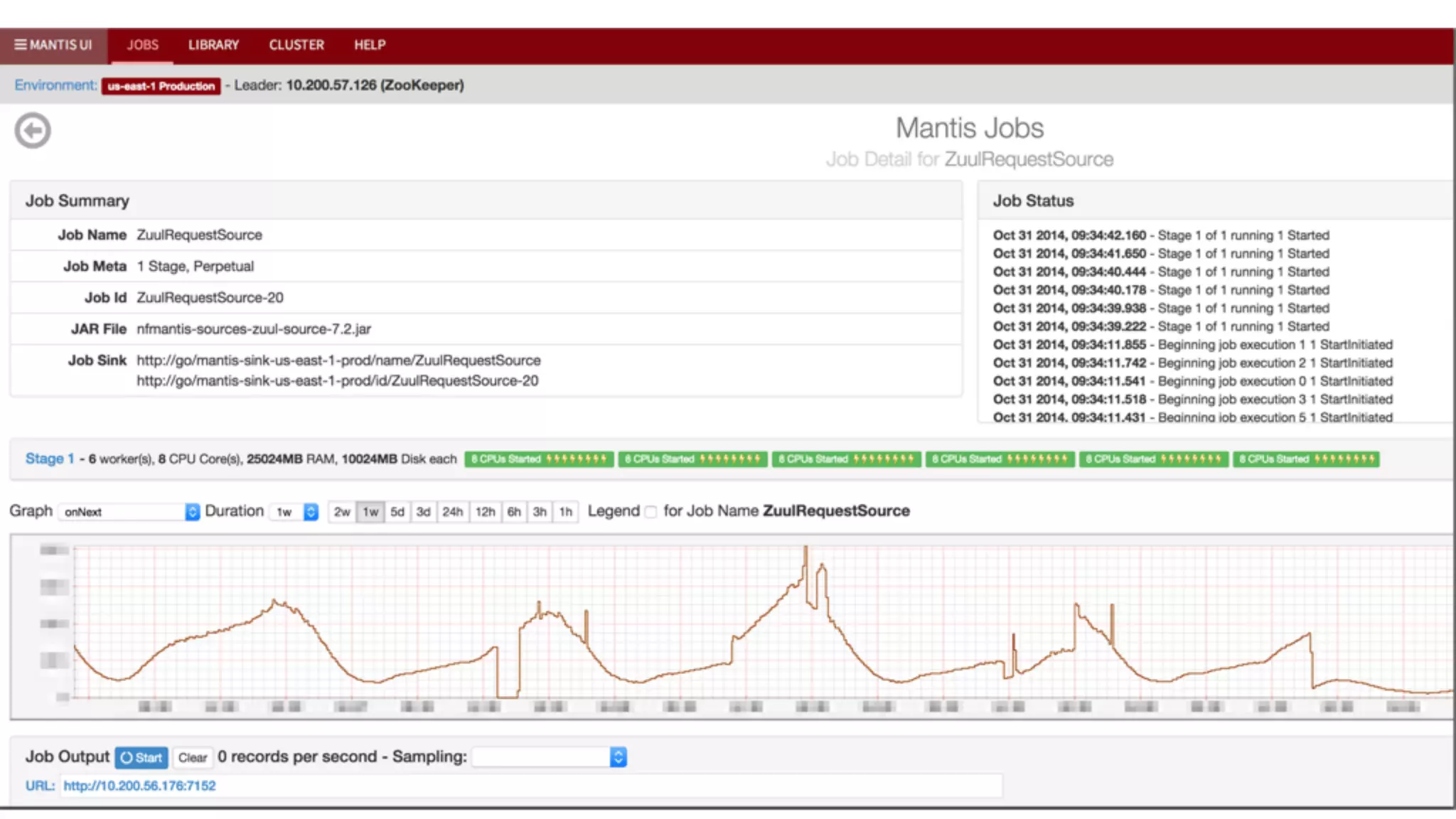



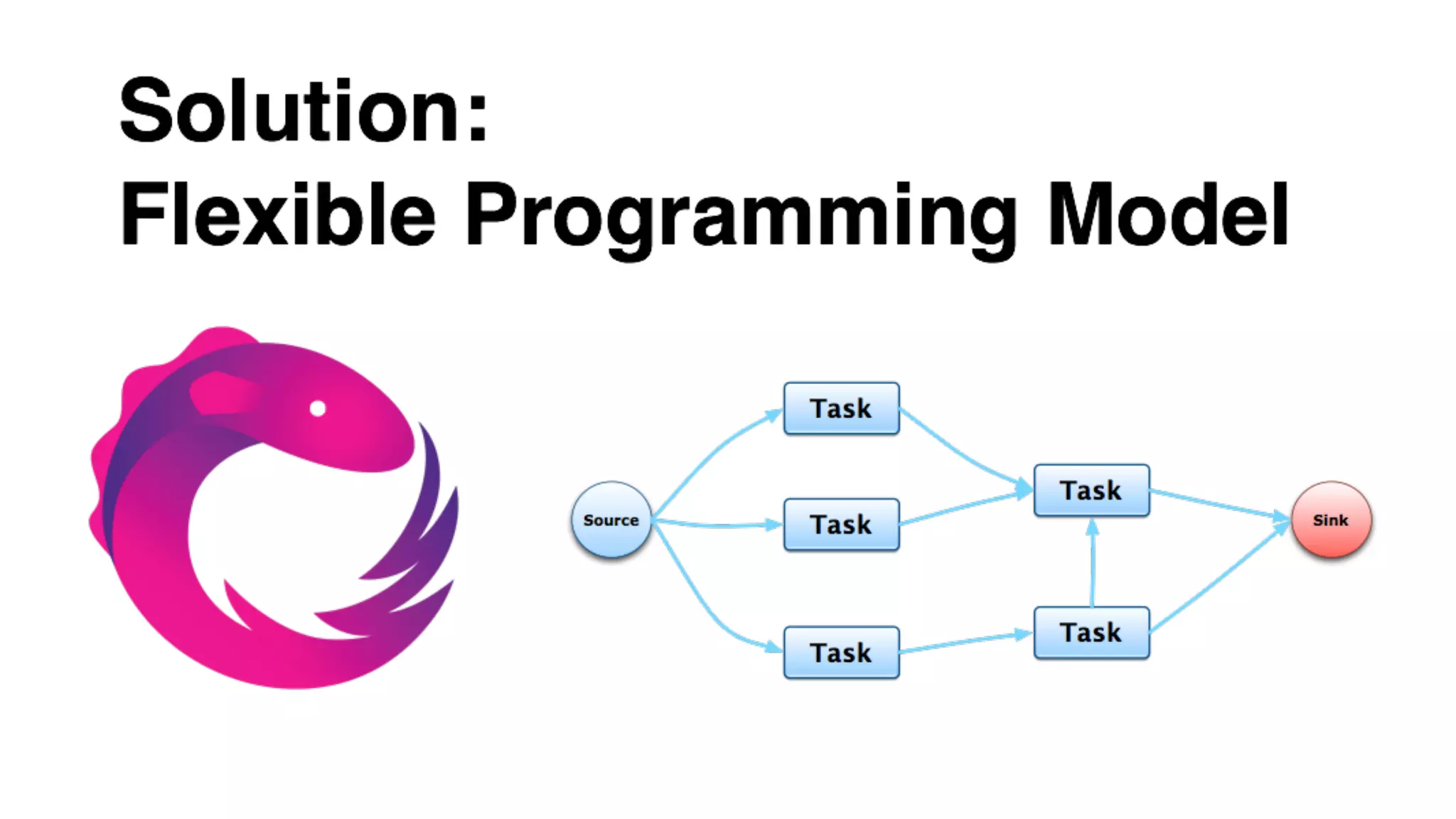
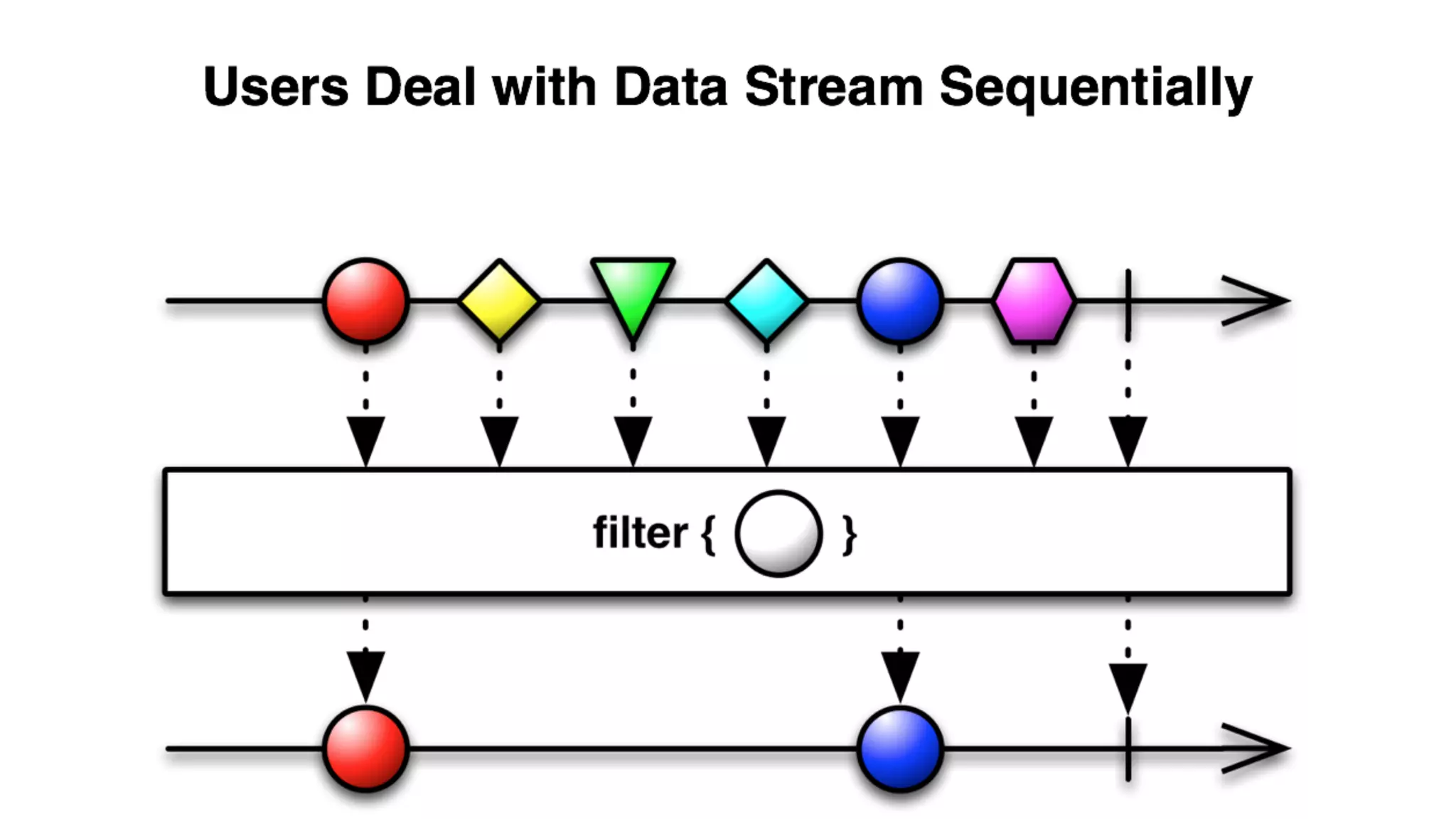
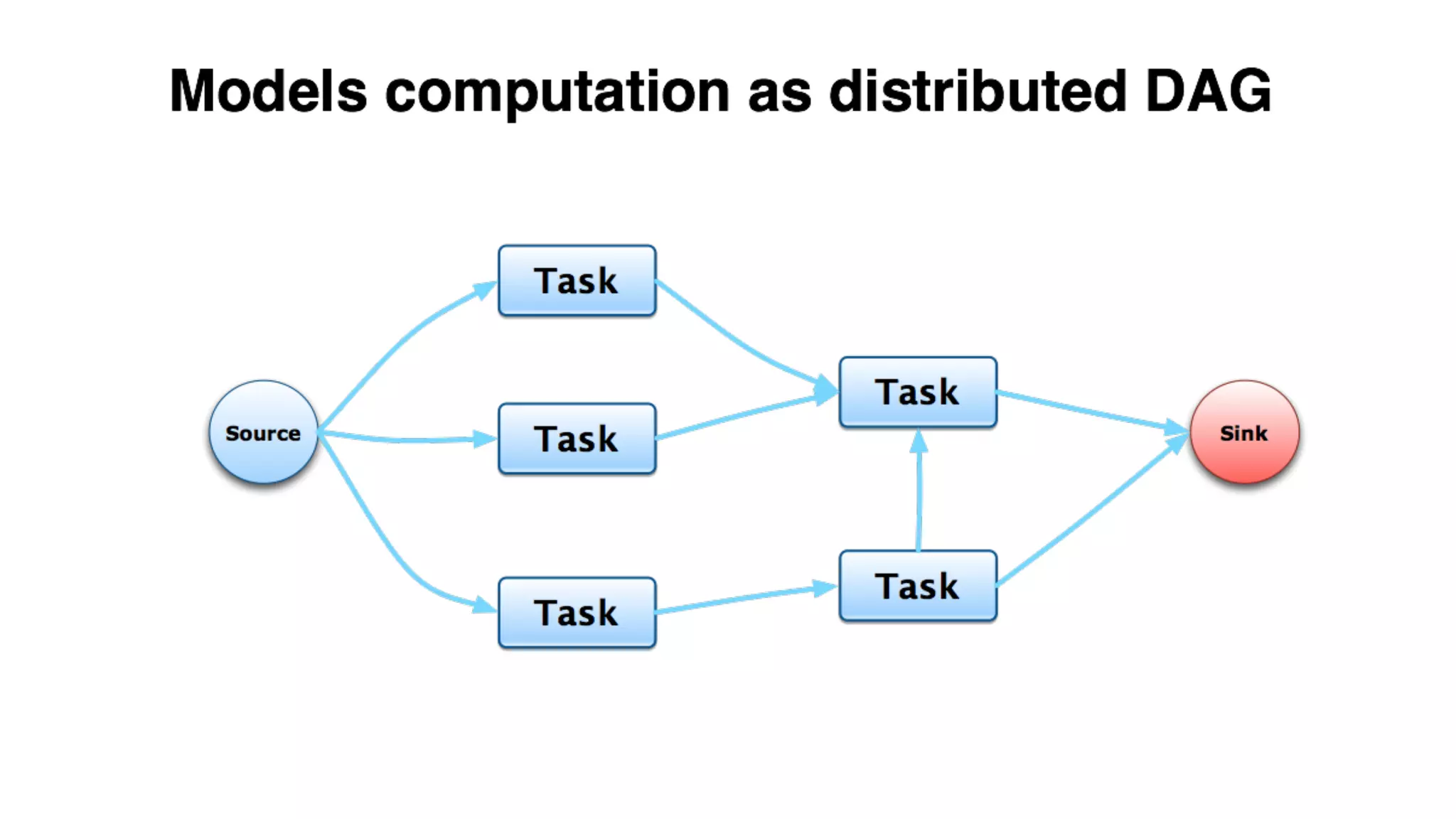
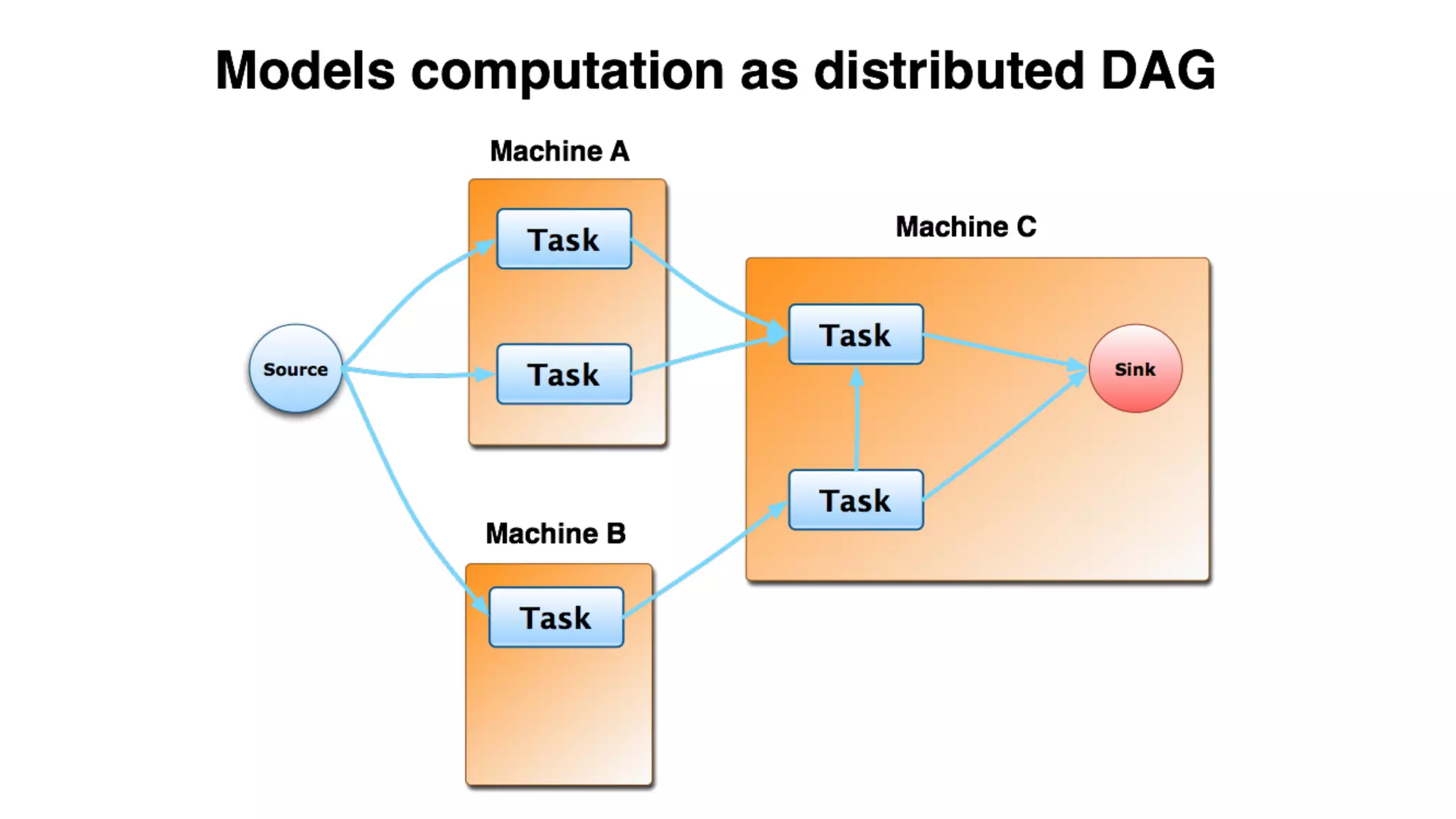

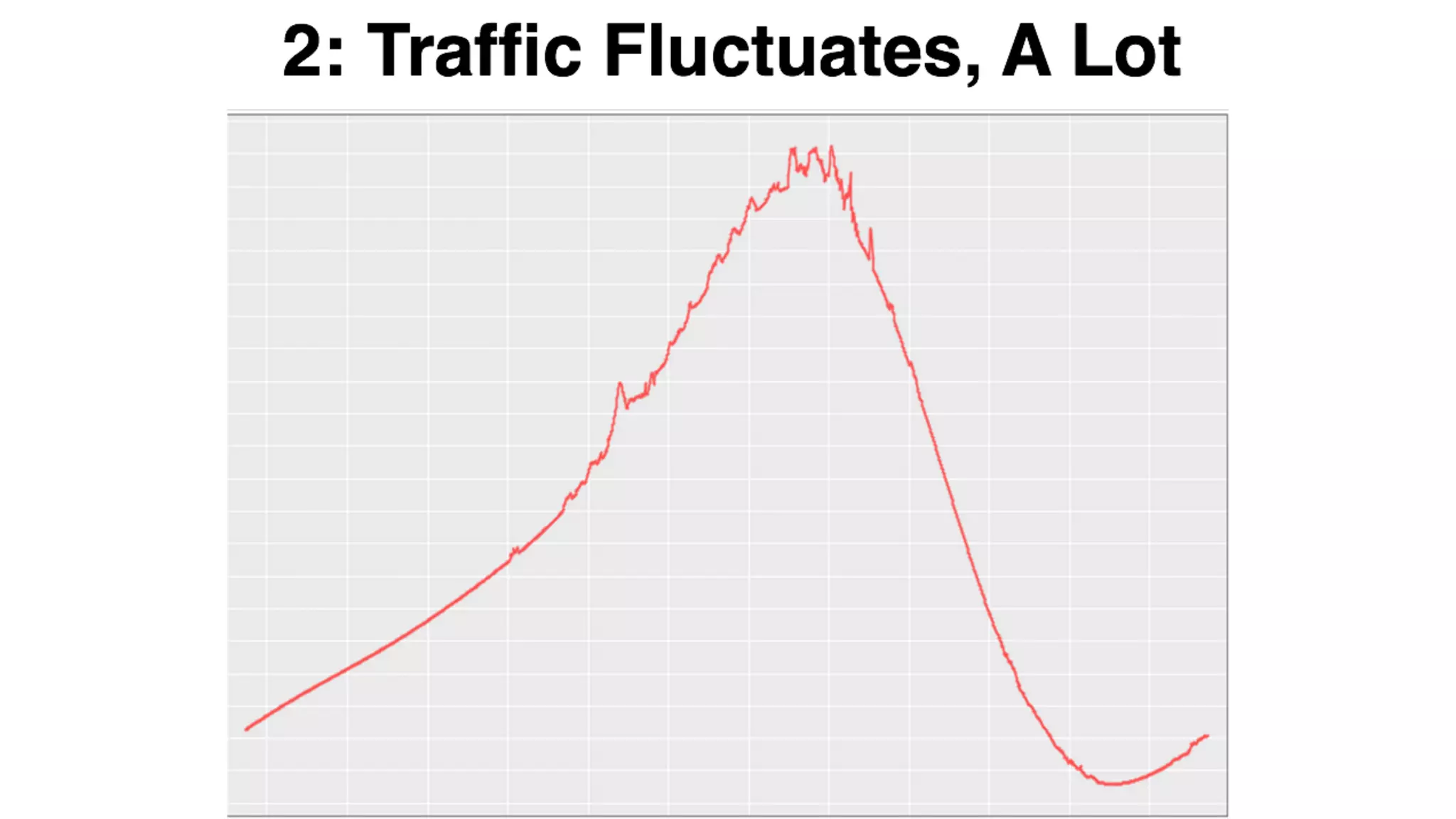
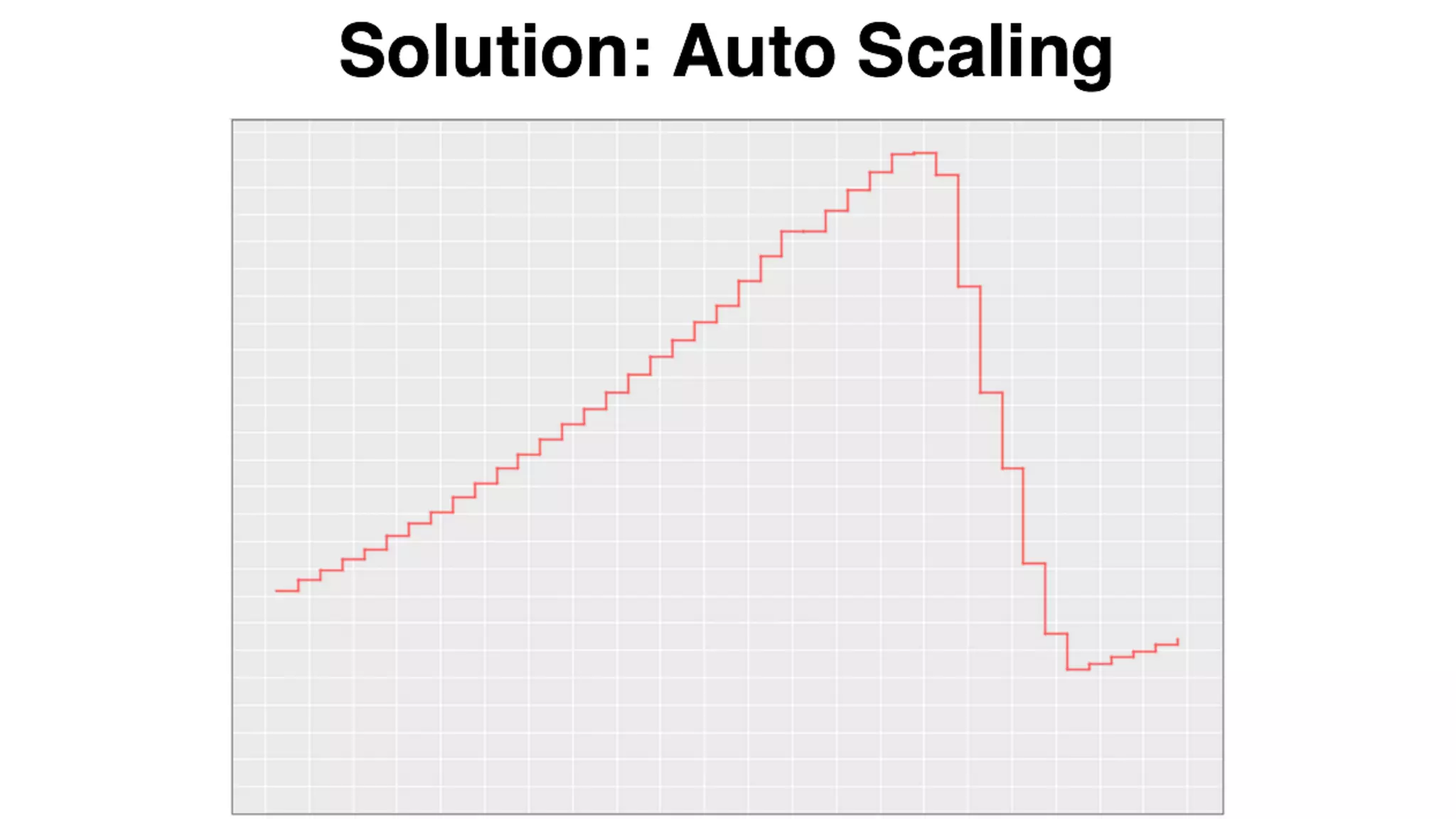
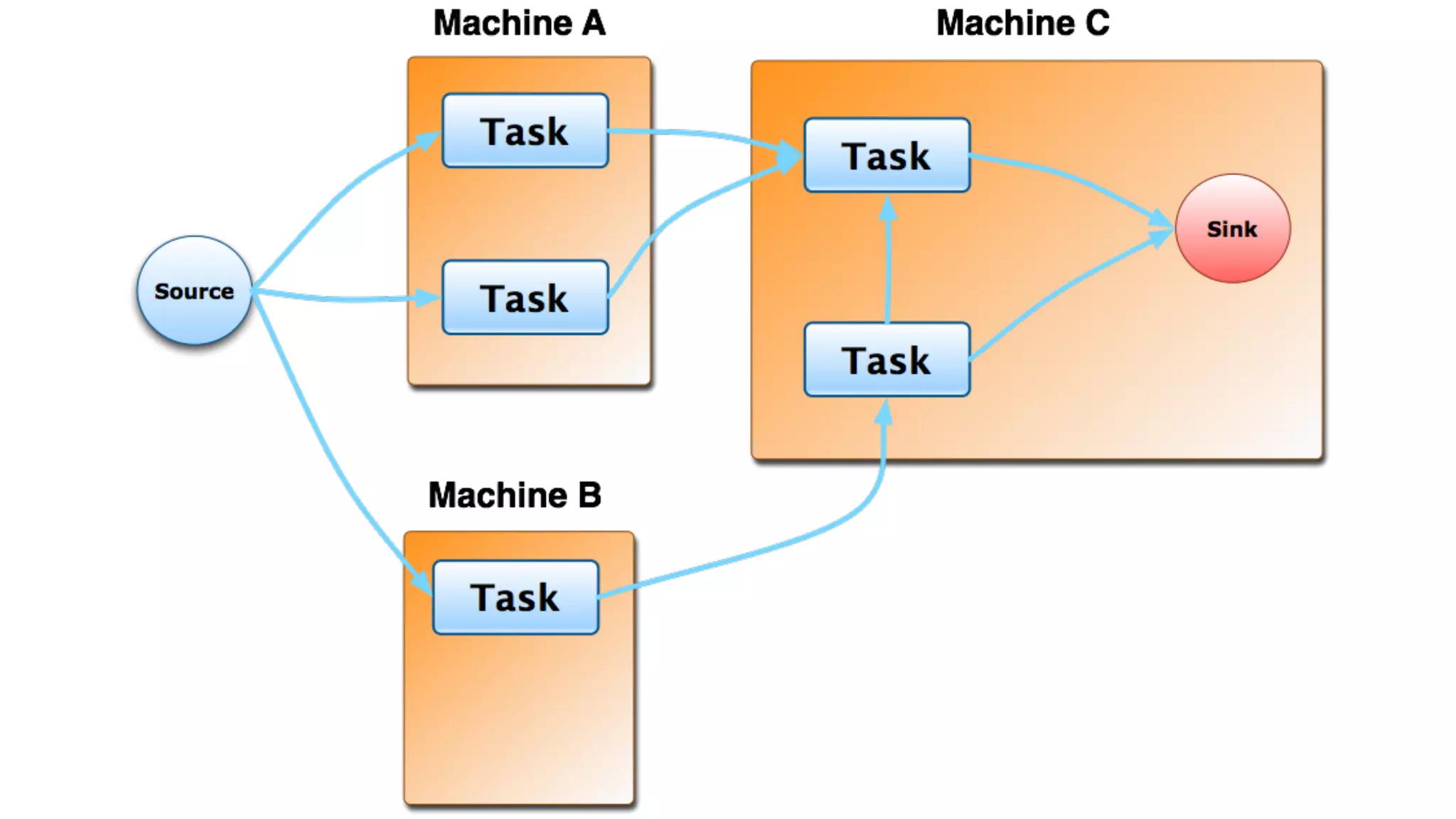
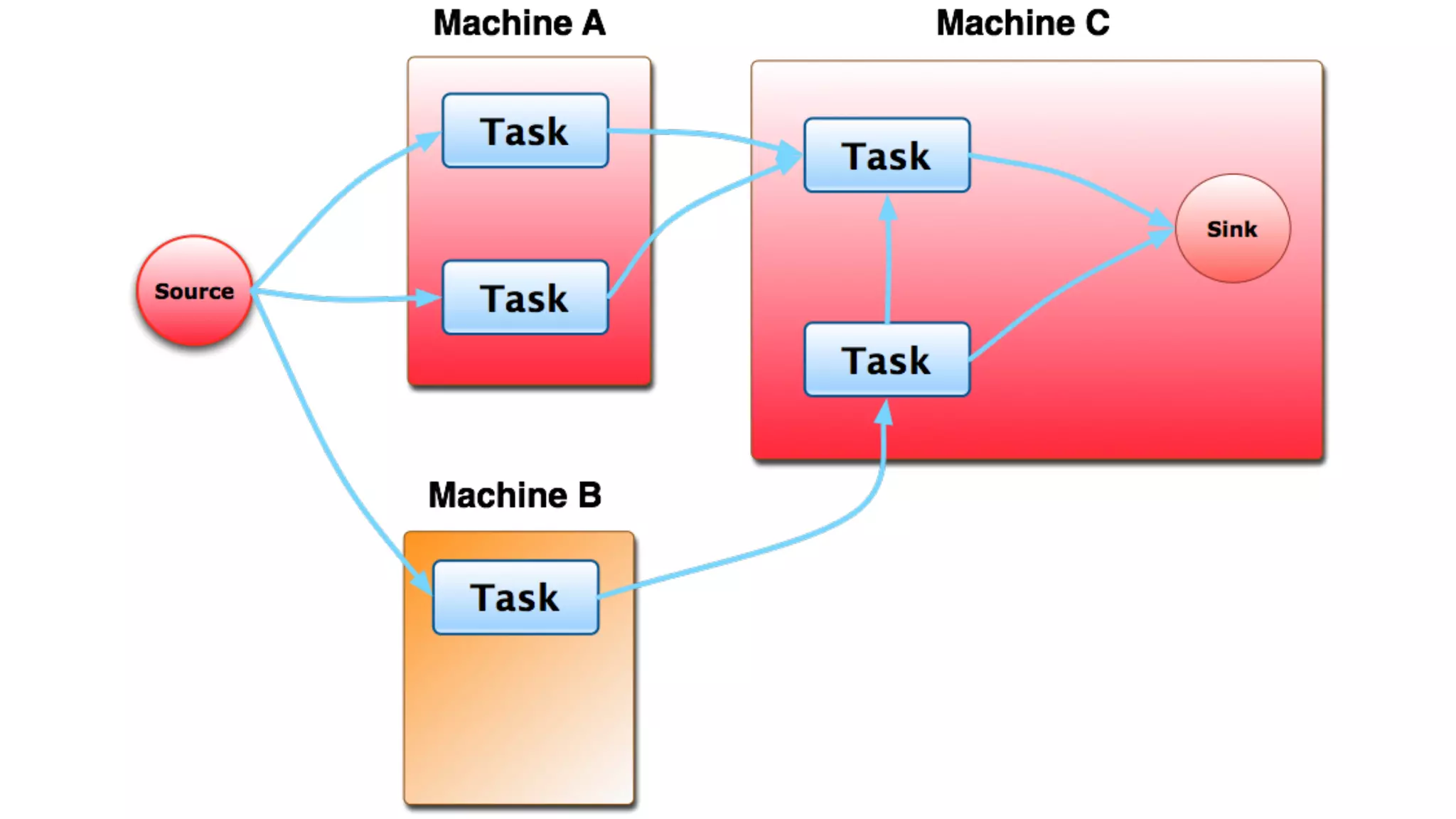
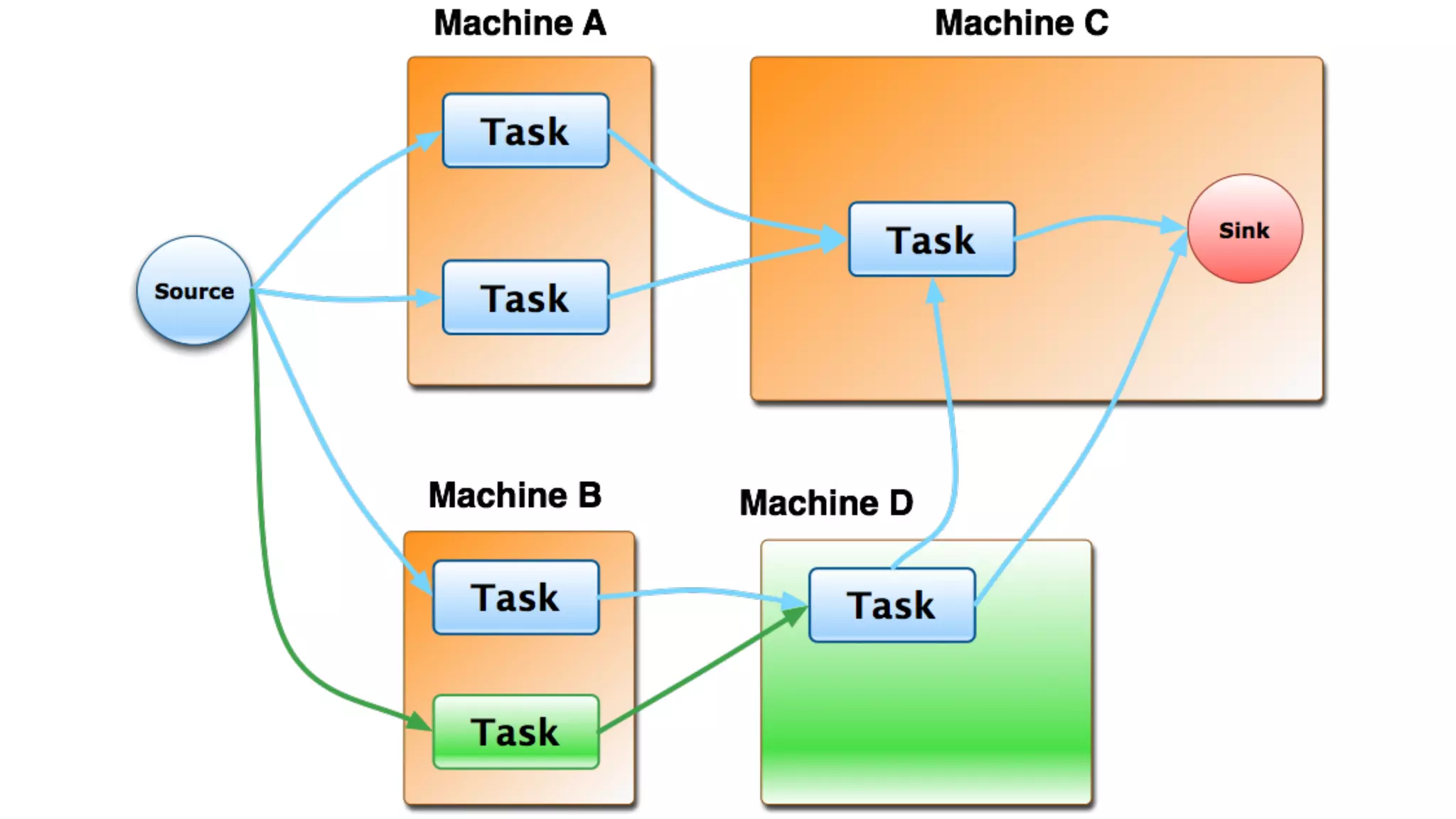

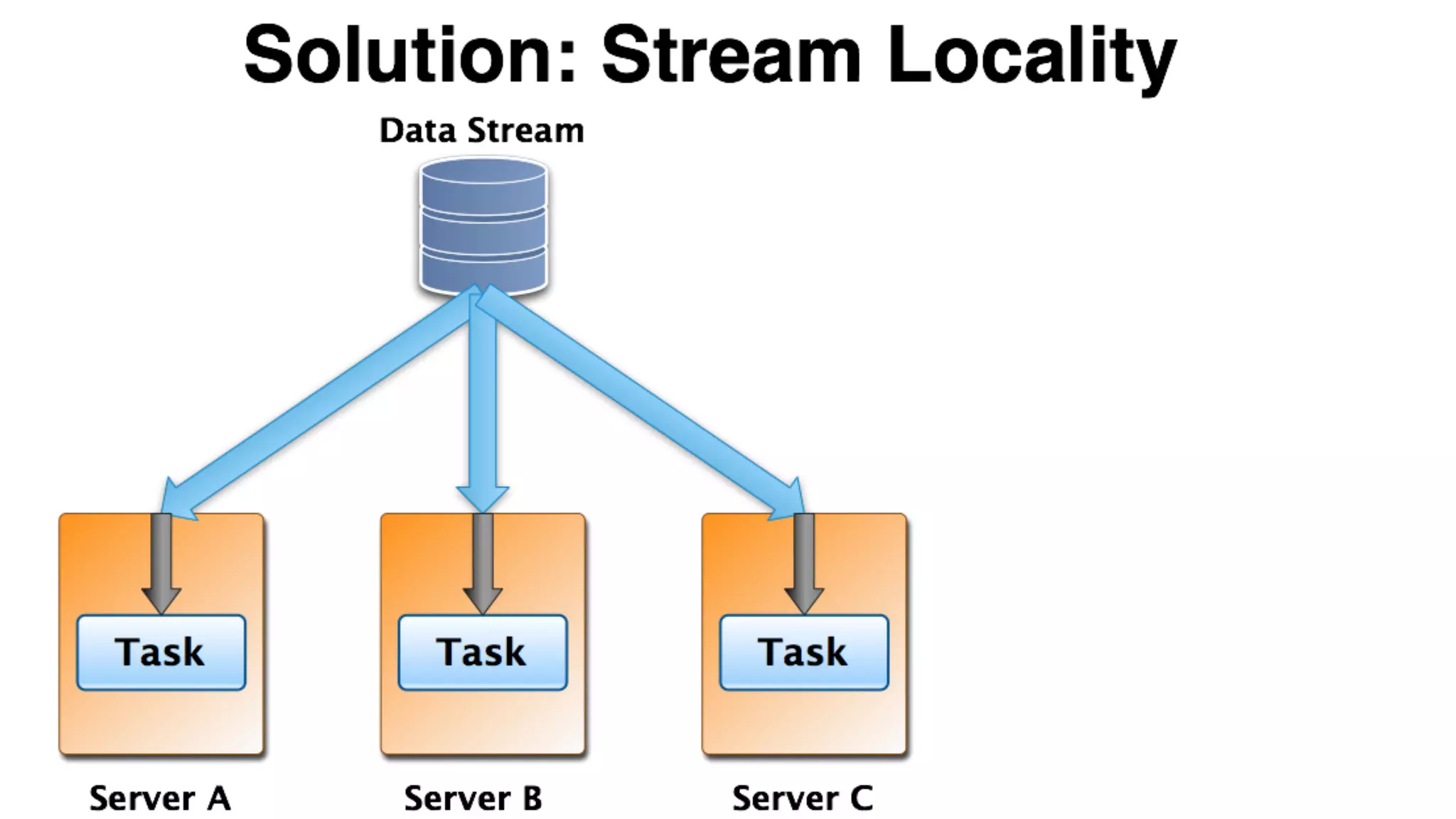
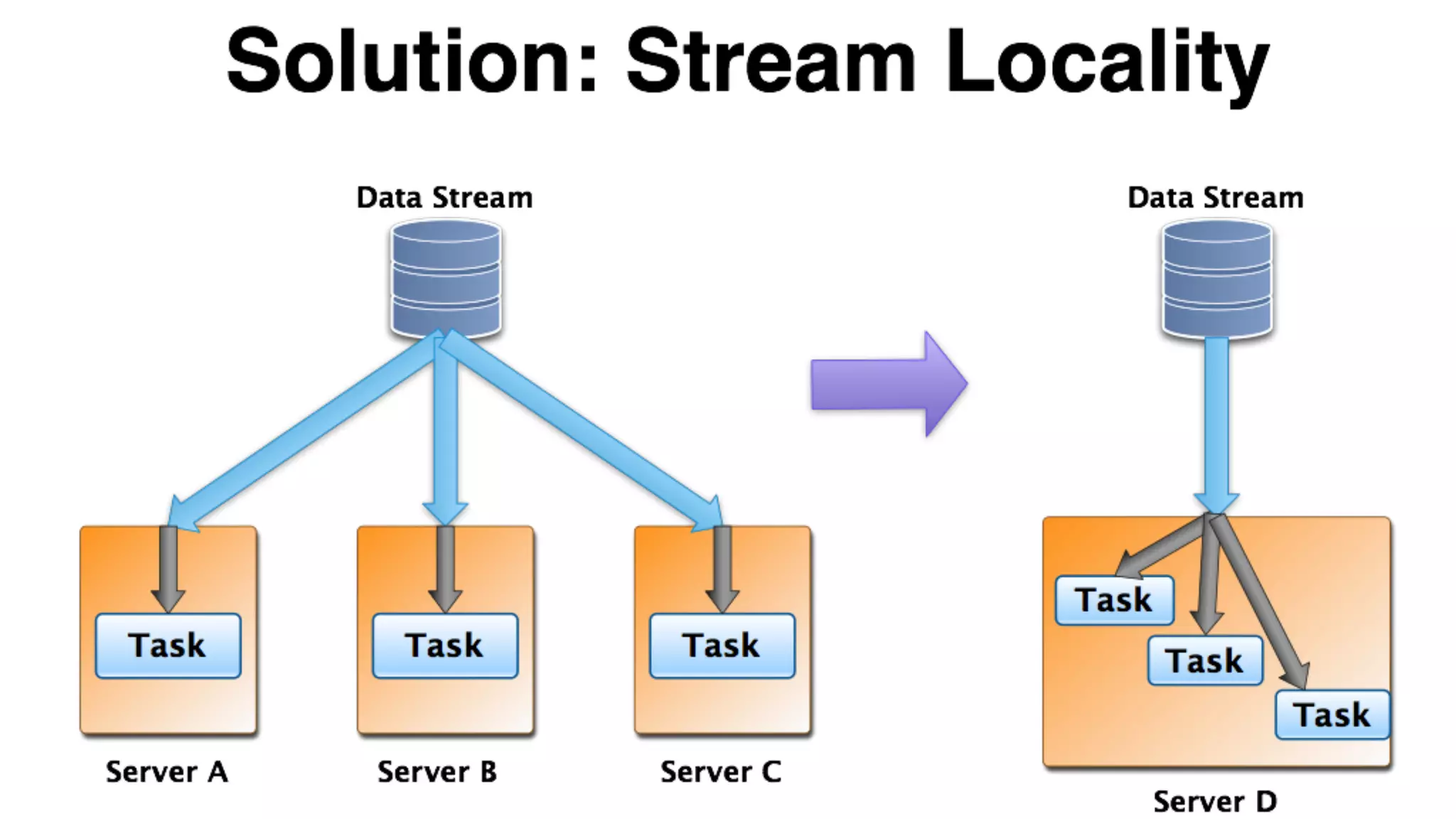
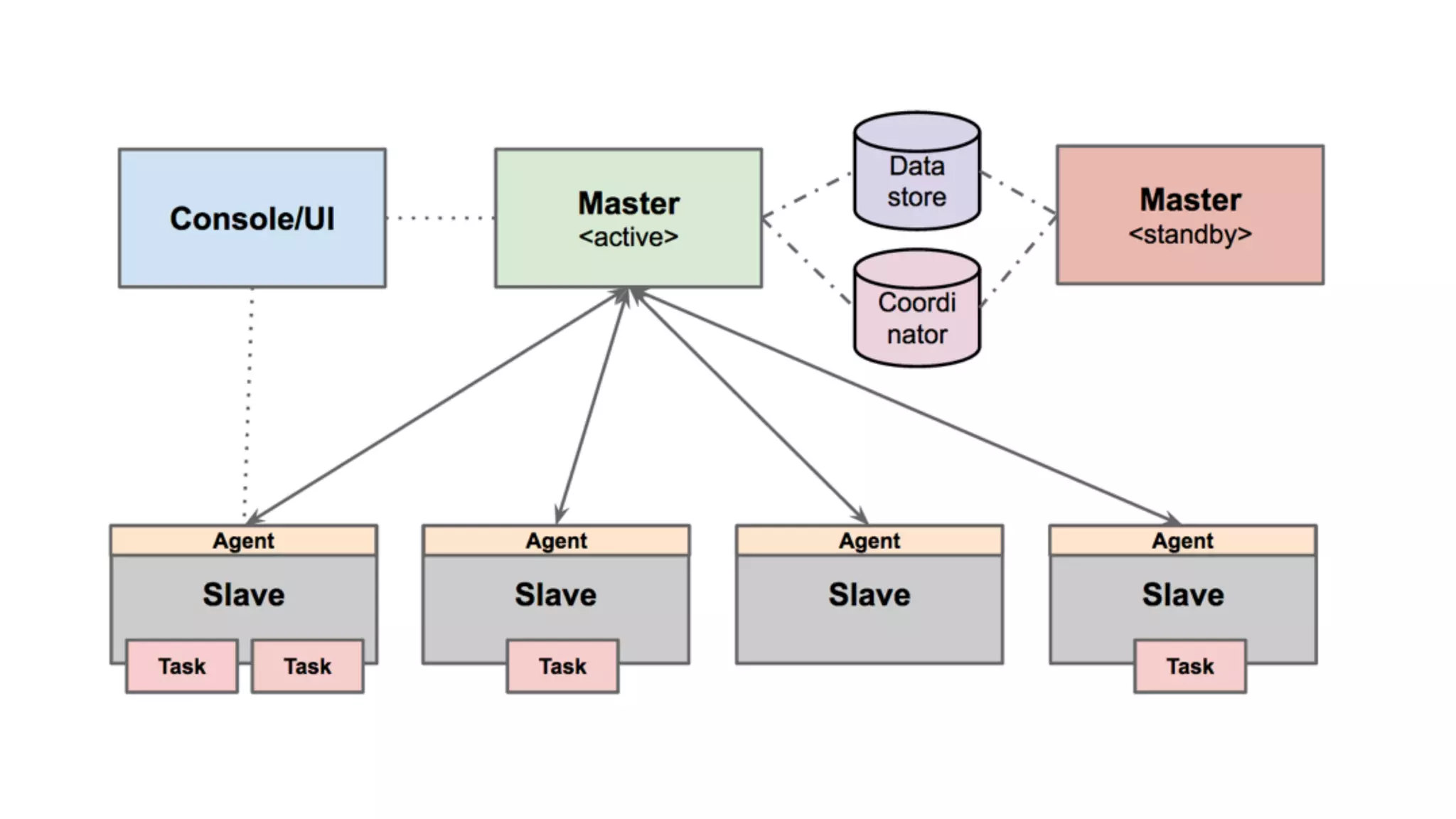






























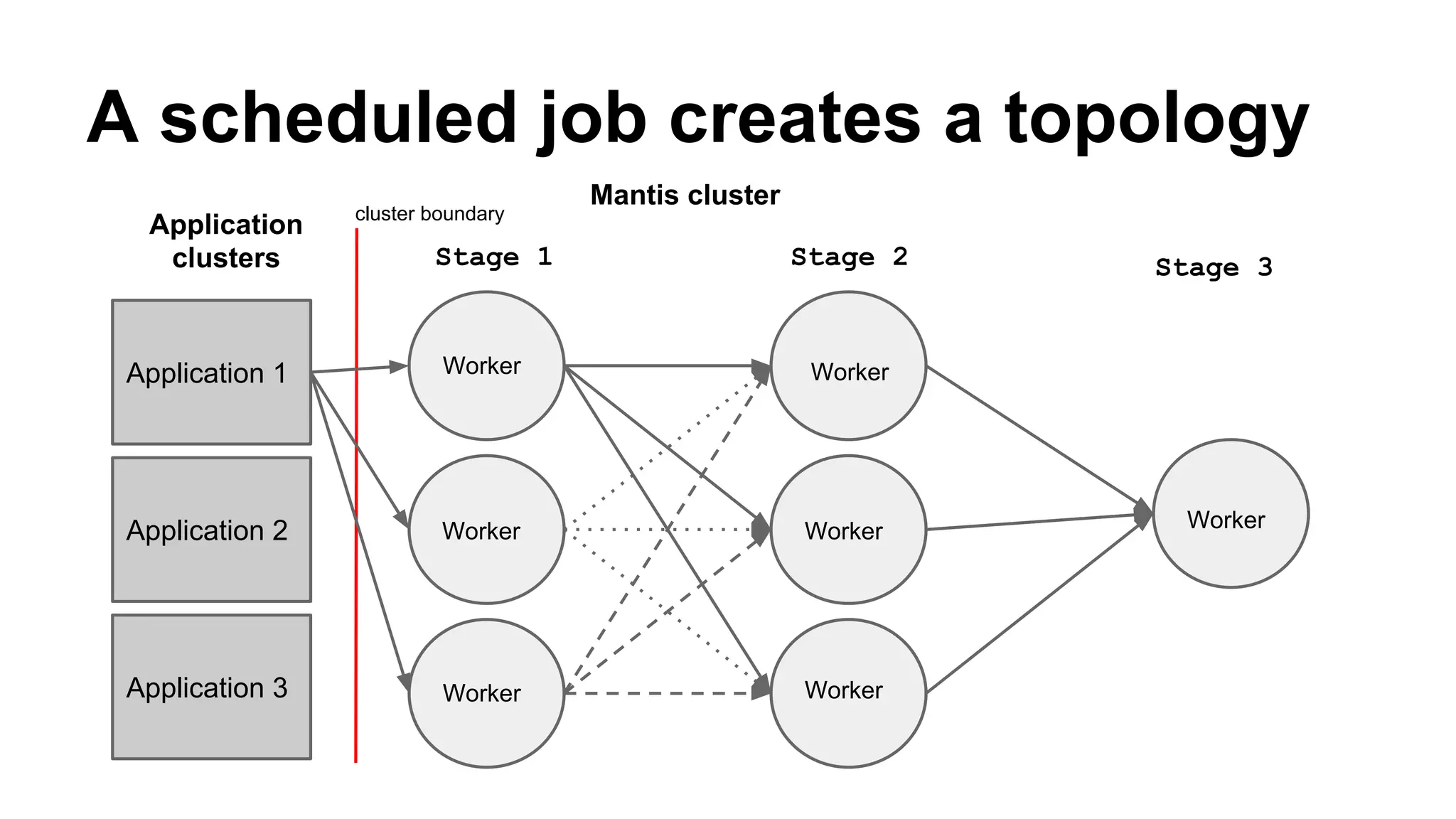
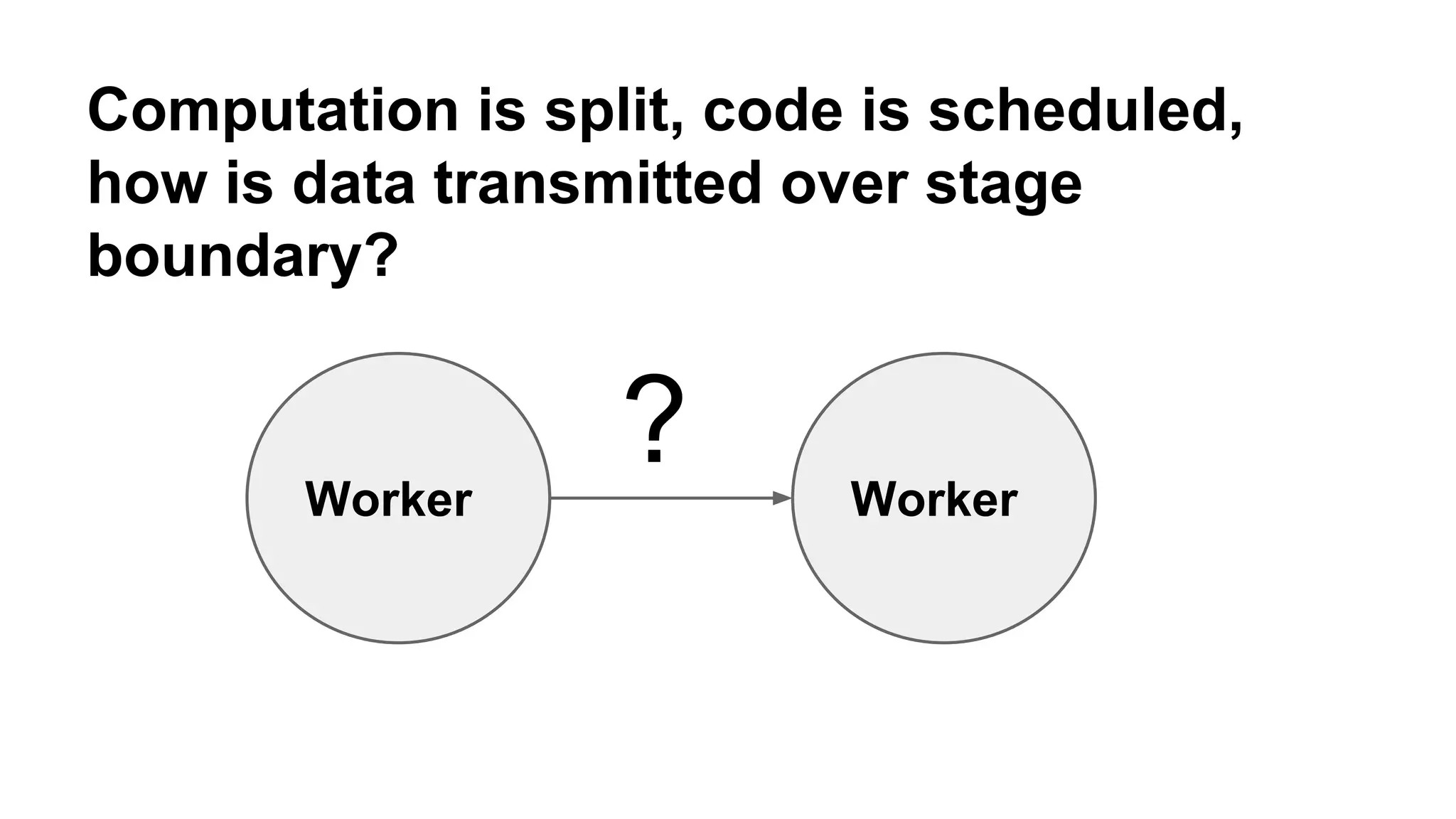
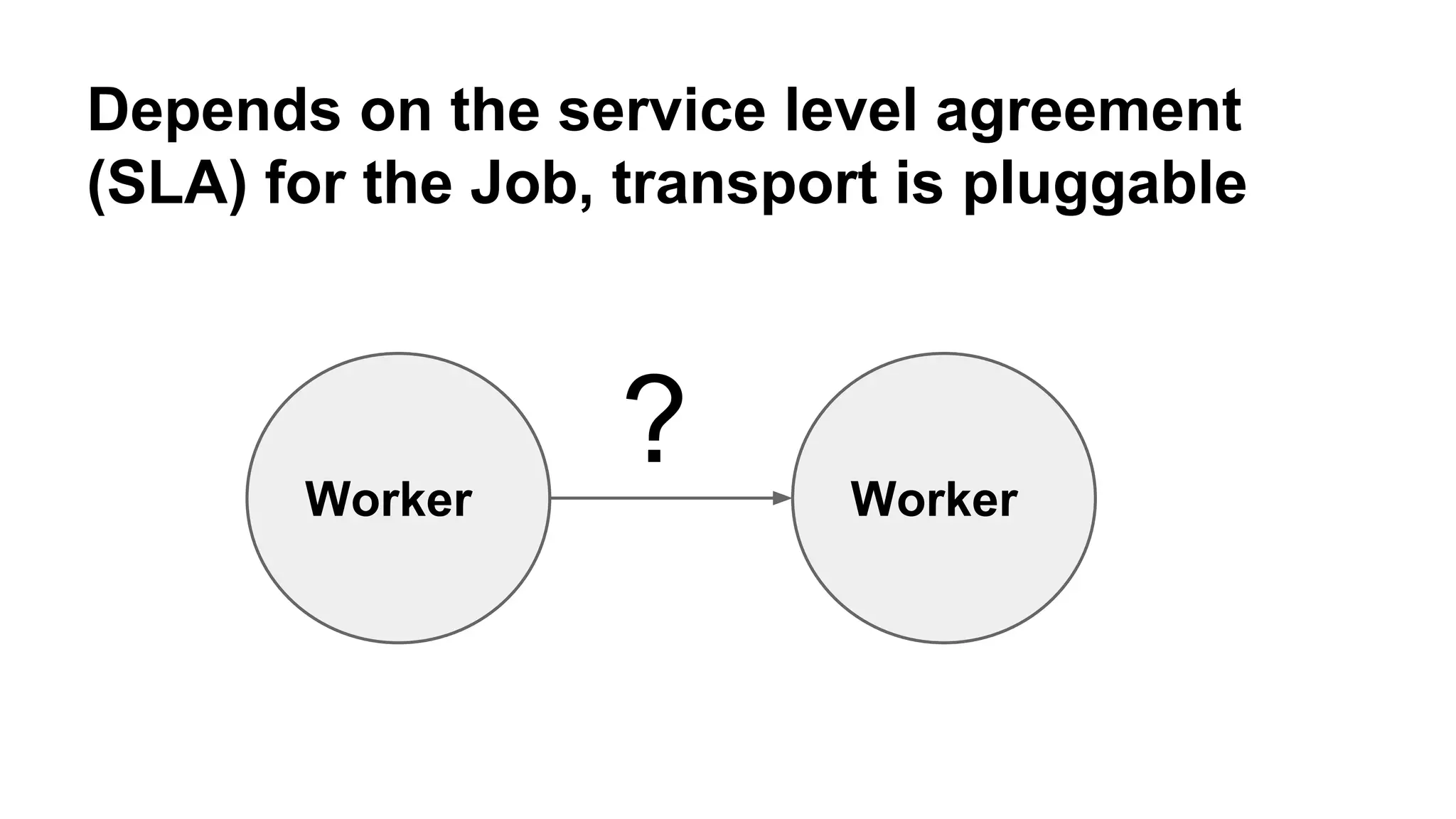
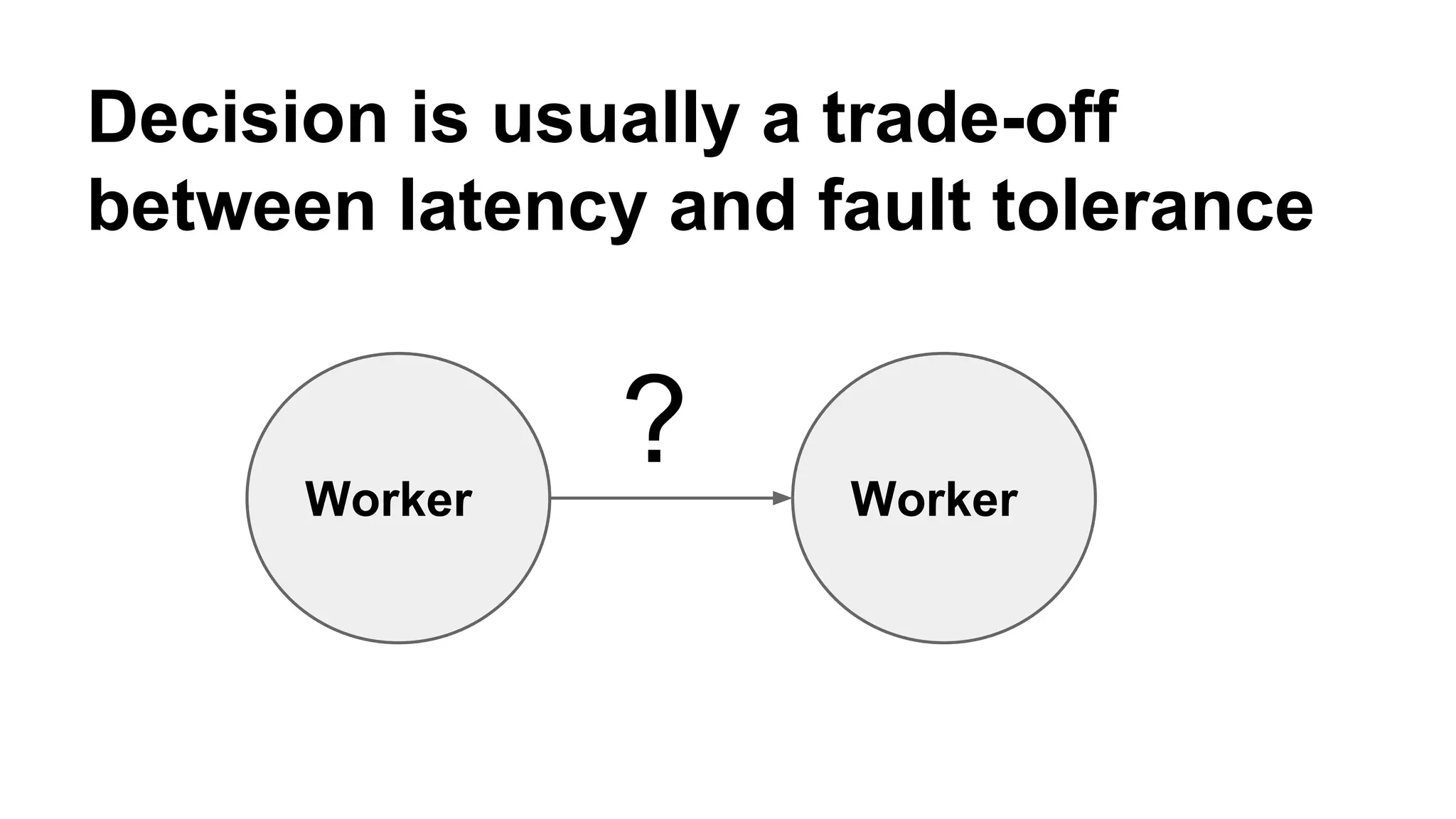
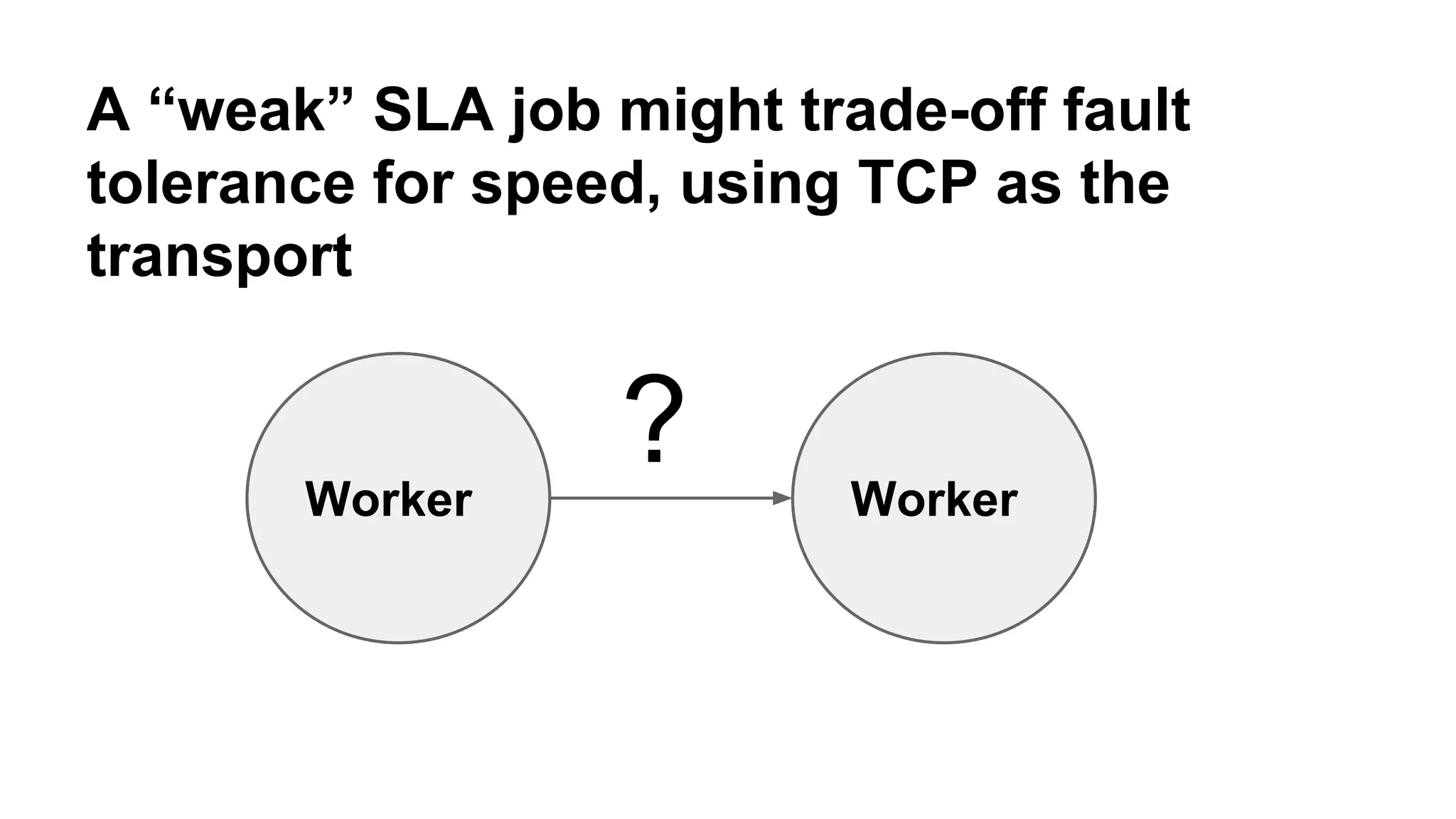
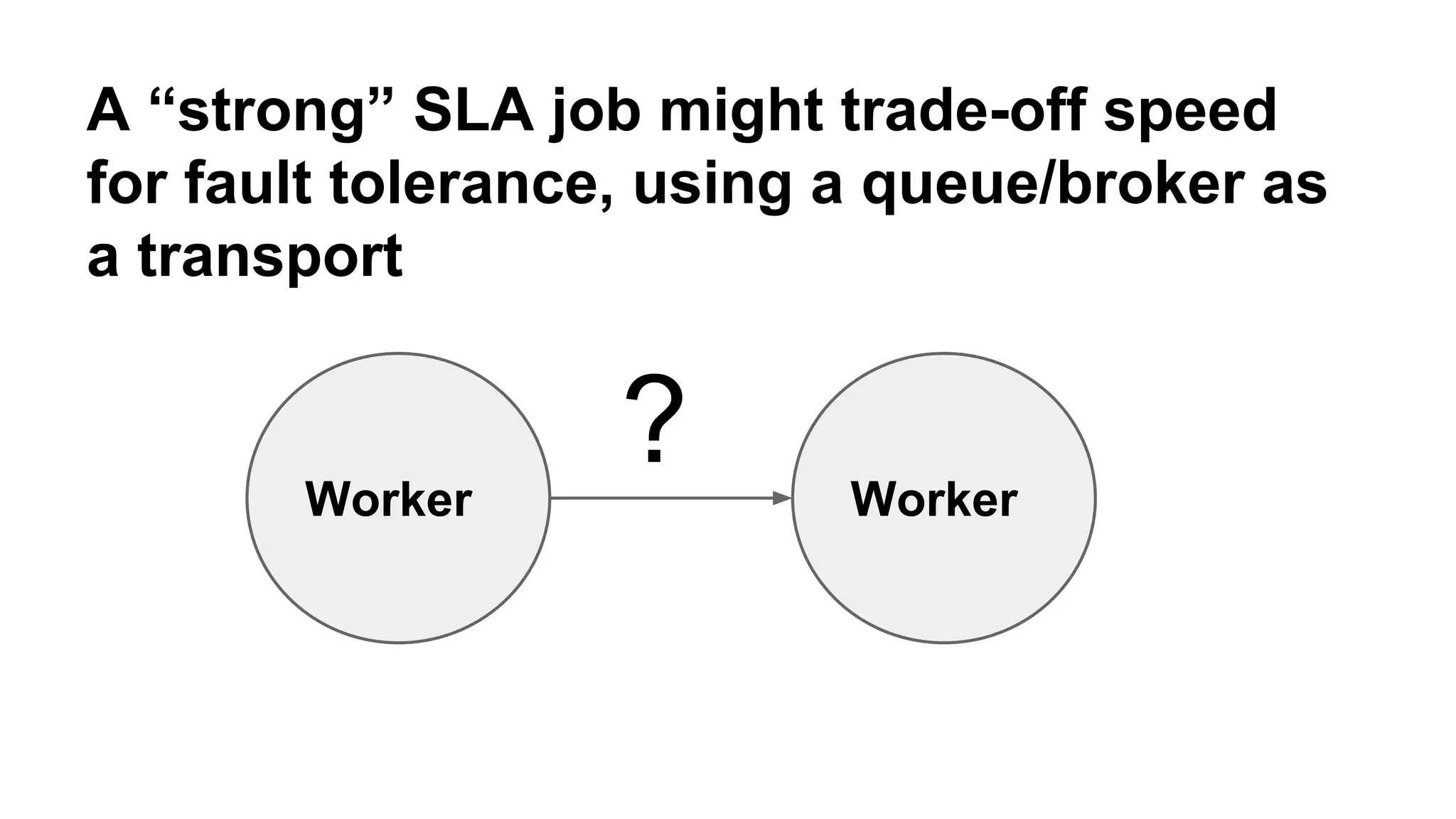
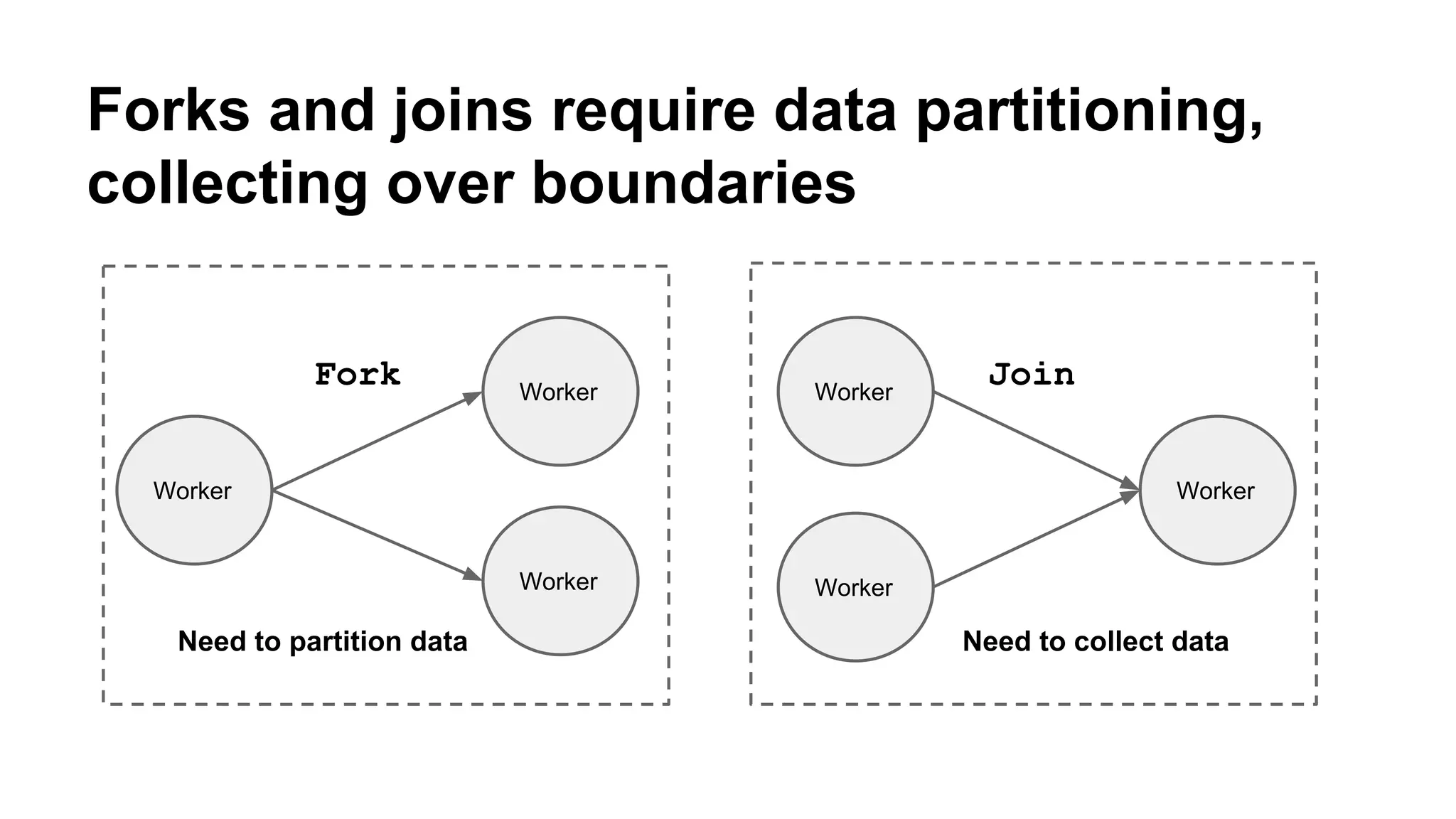
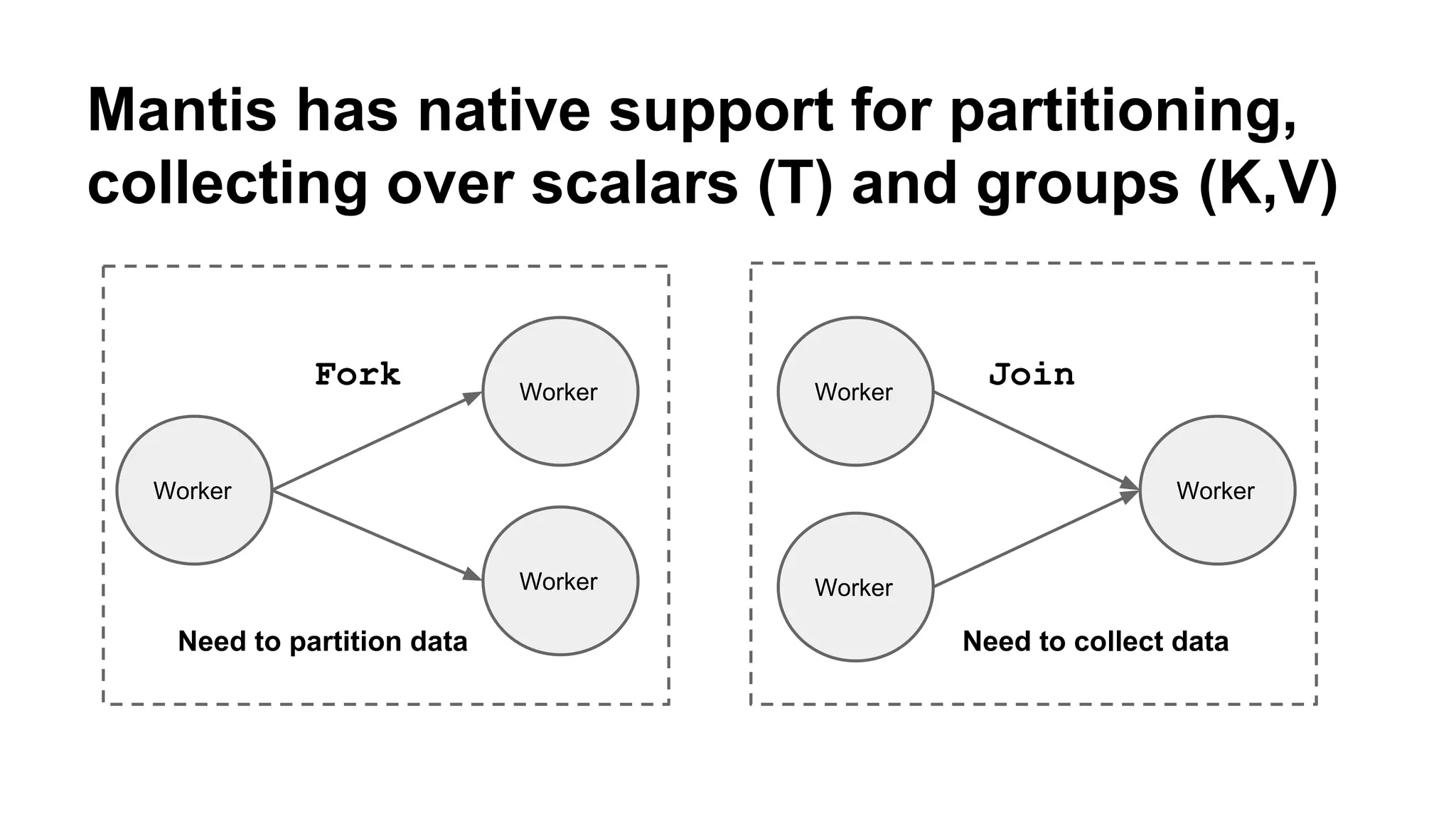














Mantis is Netflix's event stream processing system designed for handling large volumes of metrics and app events efficiently. It emphasizes a 'push' model for real-time data processing by utilizing reactive extensions to manage streams of events, enabling quick detection and resolution of issues like failing movies. The system aims to scale horizontally and adjust dynamically based on job demands and input data volume, ensuring low latency and cost-effectiveness.


































![[Sneak Preview] Apache Spark: Preparing for the next wave of Reactive Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/coll-report-typesafe-apache-spark-slide-share-150127023731-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)








































































