music
game play
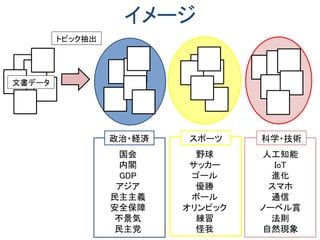
LDAの幾何学的解釈(3単語しかない世界)
play gamemusic
文書Aにおける単語分布
play game music
文書Bにおける単語分布
単語座標単体
各文書は単語座標
単体上の座標
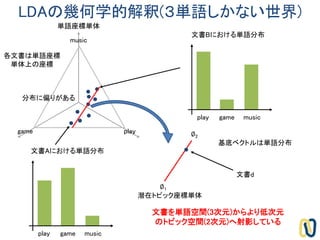
基底ベクトルは単語分布
潜在トピック座標単体
文書d
文書を単語空間(3次元)からより低次元
のトピック空間(2次元)へ射影している
分布に偏りがある
∅1
∅2
Kmeansでクラスタリング
vec_list = []
forn in range(len(corpus)):
vec_list.append([lda[corpus[n]][i][1] for i in range(10)])
result = KMeans(n_clusters=10).fit_predict(vec_list)














![4.文書のベクトル化 (bag of words)
corpus = [dictionary.doc2bow(doc) for doc in docs]
出力形式
・
・
・
doc_id word_id frequency
5 1382 5
5 1395 2
5 1402 1
5 1405 3
辞書の単語数次元のベクトルに変換
単語の順序は無視(文脈は加味しな
い)](https://image.slidesharecdn.com/random-170131010305/85/slide-18-320.jpg)
![5.LDAのモデルに投入
lda = gensim.models.LdaModel(corpus=corpus, id2word=dictionary,
num_topics=10)
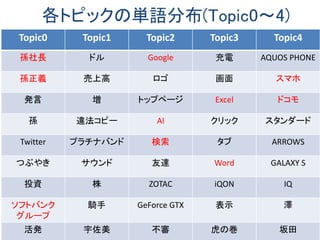
結果①各トピックの単語分布
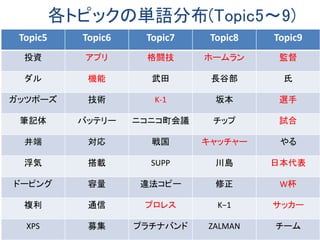
結果②各ドキュメントのトピック分布
[(0, 0.0011494875610395532), (1, 0.0011495216687281548),
(2, 0.0011496757886118457), (3, 0.0011495369772548966),
(4, 0.0011494898792352231), (5, 0.0011495350667500301),
(6, 0.0011494309427501576), (7, 0.0011495365332948294),
(8, 0.0011494727694675608), (9, 0.98965431281286775)]
topic_0: [('機能', 0.012867980011525922), ('情報', 0.012866562485143618),
('参加', 0.012864776822333324), ('組織', 0.01286474405616749),
('サービス', 0.0097301626205478289), ('提供', 0.009729611435667529),
('日立', 0.0097275009231823951), ('情報共有', 0.0097274642885800313),
('サイバー攻撃', 0.0097273991777577958), ('コミュニティ', 0.0097272270792)]](https://image.slidesharecdn.com/random-170131010305/85/slide-19-320.jpg)



![Kmeansでクラスタリング
vec_list = []
for n in range(len(corpus)):
vec_list.append([lda[corpus[n]][i][1] for i in range(10)])
result = KMeans(n_clusters=10).fit_predict(vec_list)](https://image.slidesharecdn.com/random-170131010305/85/slide-27-320.jpg)






























![[第2版]Python機械学習プログラミング 第8章](https://cdn.slidesharecdn.com/ss_thumbnails/20181015-181029035714-thumbnail.jpg?width=640&height=640&fit=bounds)






