Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning Lab(ディープラーニング・ラボ)
PDF, PPTX
5,786 views
[Track4-3] AI・ディープラーニングを駆使して、「G検定合格者アンケートのフリーコメント欄」を分析してみた
2020/8/1 Deep Learning Digital Conference 株式会社電通国際情報サービス CDLE 日本ディープラーニング協会 小川 雄太郎 氏 / 御手洗 拓真 氏
Technology
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 61
2
/ 61
3
/ 61
4
/ 61
5
/ 61
6
/ 61
7
/ 61
8
/ 61
9
/ 61
10
/ 61
11
/ 61
12
/ 61
13
/ 61
14
/ 61
15
/ 61
16
/ 61
17
/ 61
18
/ 61
19
/ 61
20
/ 61
21
/ 61
22
/ 61
23
/ 61
24
/ 61
25
/ 61
26
/ 61
27
/ 61
28
/ 61
29
/ 61
30
/ 61
31
/ 61
32
/ 61
33
/ 61
34
/ 61
35
/ 61
36
/ 61
37
/ 61
38
/ 61
39
/ 61
40
/ 61
41
/ 61
42
/ 61
43
/ 61
44
/ 61
45
/ 61
46
/ 61
47
/ 61
48
/ 61
49
/ 61
50
/ 61
51
/ 61
52
/ 61
53
/ 61
54
/ 61
55
/ 61
56
/ 61
57
/ 61
58
/ 61
59
/ 61
60
/ 61
61
/ 61
More Related Content
PDF
基礎線形代数講座
by
SEGADevTech
PDF
研究分野をサーベイする
by
Takayuki Itoh
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PDF
最適輸送の解き方
by
joisino
PDF
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
強化学習その3
by
nishio
PDF
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
PPT
Raft
by
Preferred Networks
基礎線形代数講座
by
SEGADevTech
研究分野をサーベイする
by
Takayuki Itoh
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
最適輸送の解き方
by
joisino
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
強化学習その3
by
nishio
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
Raft
by
Preferred Networks
What's hot
PDF
先端技術とメディア表現1 #FTMA15
by
Yoichi Ochiai
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
PDF
【論文調査】XAI技術の効能を ユーザ実験で評価する研究
by
Satoshi Hara
PDF
合成変量とアンサンブル:回帰森と加法モデルの要点
by
Ichigaku Takigawa
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PDF
最近強化学習の良記事がたくさん出てきたので勉強しながらまとめた
by
Katsuya Ito
PPTX
深層学習の非常に簡単な説明
by
Seiichi Uchida
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PPTX
CatBoost on GPU のひみつ
by
Takuji Tahara
PDF
データに内在する構造をみるための埋め込み手法
by
Tatsuya Shirakawa
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PDF
大規模な組合せ最適化問題に対する発見的解法
by
Shunji Umetani
PPTX
【DL輪読会】Language Conditioned Imitation Learning over Unstructured Data
by
Deep Learning JP
PDF
Introduction to YOLO detection model
by
WEBFARMER. ltd.
PDF
[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介
by
Preferred Networks
PDF
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
PDF
ソーシャルゲームのためのデータベース設計
by
Yoshinori Matsunobu
PDF
Hyperoptとその周辺について
by
Keisuke Hosaka
先端技術とメディア表現1 #FTMA15
by
Yoichi Ochiai
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
Attentionの基礎からTransformerの入門まで
by
AGIRobots
【論文調査】XAI技術の効能を ユーザ実験で評価する研究
by
Satoshi Hara
合成変量とアンサンブル:回帰森と加法モデルの要点
by
Ichigaku Takigawa
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
最近強化学習の良記事がたくさん出てきたので勉強しながらまとめた
by
Katsuya Ito
深層学習の非常に簡単な説明
by
Seiichi Uchida
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
機械学習のためのベイズ最適化入門
by
hoxo_m
CatBoost on GPU のひみつ
by
Takuji Tahara
データに内在する構造をみるための埋め込み手法
by
Tatsuya Shirakawa
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
大規模な組合せ最適化問題に対する発見的解法
by
Shunji Umetani
【DL輪読会】Language Conditioned Imitation Learning over Unstructured Data
by
Deep Learning JP
Introduction to YOLO detection model
by
WEBFARMER. ltd.
[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介
by
Preferred Networks
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
ソーシャルゲームのためのデータベース設計
by
Yoshinori Matsunobu
Hyperoptとその周辺について
by
Keisuke Hosaka
Similar to [Track4-3] AI・ディープラーニングを駆使して、「G検定合格者アンケートのフリーコメント欄」を分析してみた
PDF
最近のディープラーニングのトレンド紹介_20200925
by
小川 雄太郎
PPTX
fastTextの実装を見てみた
by
Yoshihiko Shiraki
PDF
統計的係り受け解析入門
by
Yuya Unno
PDF
機械学習・ディープラーニング、ITの実装スキル学ぶ方法(と私の場合)
by
小川 雄太郎
PDF
ディープラーニング開発組織のつくり方と運営ノウハウ_DLLAB Case Study Day
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
tut_pfi_2012
by
Preferred Networks
PDF
Azure ML 強化学習を用いた最新アルゴリズムの活用手法
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
サポーターズ勉強会スライド
by
Kensuke Mitsuzawa
PDF
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
PDF
『モバゲーの大規模データマイニング基盤におけるHadoop活用』-Hadoop Conference Japan 2011- #hcj2011
by
Koichi Hamada
PDF
視点を可視化したデジタルドキュメントが促進するチーム活動
by
yamahige
PDF
E-SOINN
by
SOINN Inc.
PDF
BERTによる文書系AIの取り組みと、Azureを用いたテーブルデータの説明性実現!
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
BERTによる文書系AIの取り組みと、Azureを用いたテーブルデータの説明性_DLLAB_20191007
by
小川 雄太郎
PDF
Tokyo H2O.ai Meetup#2 by Iida
by
Hidenori Fujioka
PDF
営業現場で困らないためのディープラーニング
by
Satoru Yamamoto
PDF
JAWS FESTA 20191102
by
陽平 山口
PPTX
【Dll171201】深層学習利活用の紹介 掲載用
by
Hirono Jumpei
PPTX
Machine Learning Seminar (5)
by
Tomoya Nakayama
PDF
プロパティグラフに対するDISTINCT句を含む問合せ処理の高速化_IPSJ2024.pdf
by
ToshihiroIto4
最近のディープラーニングのトレンド紹介_20200925
by
小川 雄太郎
fastTextの実装を見てみた
by
Yoshihiko Shiraki
統計的係り受け解析入門
by
Yuya Unno
機械学習・ディープラーニング、ITの実装スキル学ぶ方法(と私の場合)
by
小川 雄太郎
ディープラーニング開発組織のつくり方と運営ノウハウ_DLLAB Case Study Day
by
Deep Learning Lab(ディープラーニング・ラボ)
tut_pfi_2012
by
Preferred Networks
Azure ML 強化学習を用いた最新アルゴリズムの活用手法
by
Deep Learning Lab(ディープラーニング・ラボ)
サポーターズ勉強会スライド
by
Kensuke Mitsuzawa
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
『モバゲーの大規模データマイニング基盤におけるHadoop活用』-Hadoop Conference Japan 2011- #hcj2011
by
Koichi Hamada
視点を可視化したデジタルドキュメントが促進するチーム活動
by
yamahige
E-SOINN
by
SOINN Inc.
BERTによる文書系AIの取り組みと、Azureを用いたテーブルデータの説明性実現!
by
Deep Learning Lab(ディープラーニング・ラボ)
BERTによる文書系AIの取り組みと、Azureを用いたテーブルデータの説明性_DLLAB_20191007
by
小川 雄太郎
Tokyo H2O.ai Meetup#2 by Iida
by
Hidenori Fujioka
営業現場で困らないためのディープラーニング
by
Satoru Yamamoto
JAWS FESTA 20191102
by
陽平 山口
【Dll171201】深層学習利活用の紹介 掲載用
by
Hirono Jumpei
Machine Learning Seminar (5)
by
Tomoya Nakayama
プロパティグラフに対するDISTINCT句を含む問合せ処理の高速化_IPSJ2024.pdf
by
ToshihiroIto4
More from Deep Learning Lab(ディープラーニング・ラボ)
PDF
深層強化学習と実装例
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track3-2] AI活用人材の社内育成に関する取り組みについて ~ダイキン情報技術大学~
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Edge AI ソリューションを支える Azure IoT サービス
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson x Azure ハンズオン DeepStream Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson x Azure ハンズオン DeepStream With Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
深層強化学習を用いた複合機の搬送制御
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track1-2] ディープラーニングを用いたワインブドウの収穫量予測
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
厚生労働分野におけるAI技術の利活用について
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Intel AI in Healthcare 各国事例からみるAIとの向き合い方
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
AIによる細胞診支援技術の紹介と、AI人材が考える医療バイオ領域における参入障壁の乗り越え方
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track1-1] AIの売上予測を発注システムに組み込んだリンガーハットのデータ活用戦略
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson 活用による スタートアップ企業支援
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
「言語」×AI Digital Device
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson x Azure ハンズオン DeepStream With Azure IoT 事前準備
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
医学と工学の垣根を越えた医療AI開発
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track3-4] アカデミックにおけるAI/ディープラーニング の教育と学習支援に関する研究
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track 4-6] ディープラーニングxものづくりが日本を強くする ~高専DCONの挑戦~
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
DLLAB Healthcare Day 2021 Event Report
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
先端技術がもたらす「より良いヘルスケアのかたち」
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
ICTを用いた健康なまちづくりの 取り組みとAI活用への期待
by
Deep Learning Lab(ディープラーニング・ラボ)
深層強化学習と実装例
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track3-2] AI活用人材の社内育成に関する取り組みについて ~ダイキン情報技術大学~
by
Deep Learning Lab(ディープラーニング・ラボ)
Edge AI ソリューションを支える Azure IoT サービス
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson x Azure ハンズオン DeepStream Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson x Azure ハンズオン DeepStream With Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
深層強化学習を用いた複合機の搬送制御
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track1-2] ディープラーニングを用いたワインブドウの収穫量予測
by
Deep Learning Lab(ディープラーニング・ラボ)
厚生労働分野におけるAI技術の利活用について
by
Deep Learning Lab(ディープラーニング・ラボ)
Intel AI in Healthcare 各国事例からみるAIとの向き合い方
by
Deep Learning Lab(ディープラーニング・ラボ)
AIによる細胞診支援技術の紹介と、AI人材が考える医療バイオ領域における参入障壁の乗り越え方
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track1-1] AIの売上予測を発注システムに組み込んだリンガーハットのデータ活用戦略
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson 活用による スタートアップ企業支援
by
Deep Learning Lab(ディープラーニング・ラボ)
「言語」×AI Digital Device
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson x Azure ハンズオン DeepStream With Azure IoT 事前準備
by
Deep Learning Lab(ディープラーニング・ラボ)
医学と工学の垣根を越えた医療AI開発
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track3-4] アカデミックにおけるAI/ディープラーニング の教育と学習支援に関する研究
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track 4-6] ディープラーニングxものづくりが日本を強くする ~高専DCONの挑戦~
by
Deep Learning Lab(ディープラーニング・ラボ)
DLLAB Healthcare Day 2021 Event Report
by
Deep Learning Lab(ディープラーニング・ラボ)
先端技術がもたらす「より良いヘルスケアのかたち」
by
Deep Learning Lab(ディープラーニング・ラボ)
ICTを用いた健康なまちづくりの 取り組みとAI活用への期待
by
Deep Learning Lab(ディープラーニング・ラボ)
Recently uploaded
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
[Track4-3] AI・ディープラーニングを駆使して、「G検定合格者アンケートのフリーコメント欄」を分析してみた
1.
DEEP LEARNING Digital
Conference 20年8月1日 15:20-15:45 AI・ディープラーニングを駆使して、 「G検定合格者アンケートのフリーコメント欄」 を分析してみた 株式会社電通国際情報サービス X(クロス)イノベーション本部 AIテクノロジー部 兼 CDLEメンバ 小川 雄太郎、御手洗拓真 [※本スライドは後ほど公開]
2.
2 本日の内容 ●発表者の小川です。CDLEメンバであり、ディープラーニング協会の委員でもあり ます ●2020年5月に実施した「G検定合格者がおススメする本アンケート」のフリーコ メント欄、「ディープラーニング協会へのご意見・ご要望」に寄せられた意見を、 「ディープラーニングのエンジニアらしく、機械学習を駆使して分析しようじゃな いか!」と実施した結果を紹介します ●本発表の流れ:自己紹介ののちに、最初に「解析したデモ動画」を紹介します ●その後、分析システムを共に構築したチームメンバ御手洗より、システム内で使 用されている自然言語処理技術を解説します
3.
3 会社紹介(省略) 株式会社電通 1975年に創業 電通グループのIT集団(SIer) General Electric Company(GE) 電通国際情報サービス(ISID)
4.
4 会社紹介(省略)
5.
簡単にISIDのAIテクノロジー部について紹介します 電通国際情報サービス(通称ISID)では、XI本部AIテクノロジー部を中心に、製造 業をはじめとする多様な領域において、100を超えるAIプロジェクトの推進 Microsoft TechSummit /
各種講演 放牧牛の行動予測 NHK 「人間ってナンだ?超AI入門」 AI事例 ワールドビジネスサテライト 5 DEEP LEARNING LAB ステアリングコミッティ 第10章 双日ツナファーム鷹島 養殖マグロの数の把握にAI活用 ISID-AIトランスフォーメーショ ンセンターの設立(日経XTEC) https://isid-ai.jp/
6.
6 小川 雄太郎 所属:電通国際情報サービス
クロスイノベーション本部 AIテクノロジー部 業務:AI案件のコンサル、リード、自社AI製品の開発 兼職:日本ディープラーニング協会 委員、早稲田大学 非常勤講師、執筆業 詳細:https://github.com/YutaroOgawa/about_me Twitter:https://twitter.com/ISID_AI_team 出版: PyTorch・発展ディープラーニング、深層強化学習、機械学習入門、因果分析 自己紹介
7.
自己紹介 所属:電通国際情報サービス クロスイノベーション本部 AIテクノロジー部 経歴: 2015年3月:慶應義塾大学総合政策学部卒 2015年4月:新卒でとあるSIerへ入社 Azureベースの機械学習システム導入案件を推進 2020年2月:ISID
AIテクノロジー部へ中途入社 業務: 機械学習システム開発・導入、自社のAIソフトウェアの開発、主にAzureによる アーキテクチャ設計 御手洗拓真
8.
アンケート分析 の概要
9.
アンケート分析の概要 人手でのフリーコメントの解析フロー [1] 全コメントを読みながら、似たような内容の文章を次々とグルーピング(クラスタリング)する [2] クラスタ内容を代表するキーワードを抽出 [3]
クラスタ内容の要約文章を作成 [4] ちなみに、今回使用したデータは以下のような感じです ・・・ 250件超。。。(大変、自然言語処理・機械学習技術でどうにかしたいというモチベーション)
10.
作成した分析ツールのMVP(プロトタイプ)のデモ動画を再生 デモ動画
11.
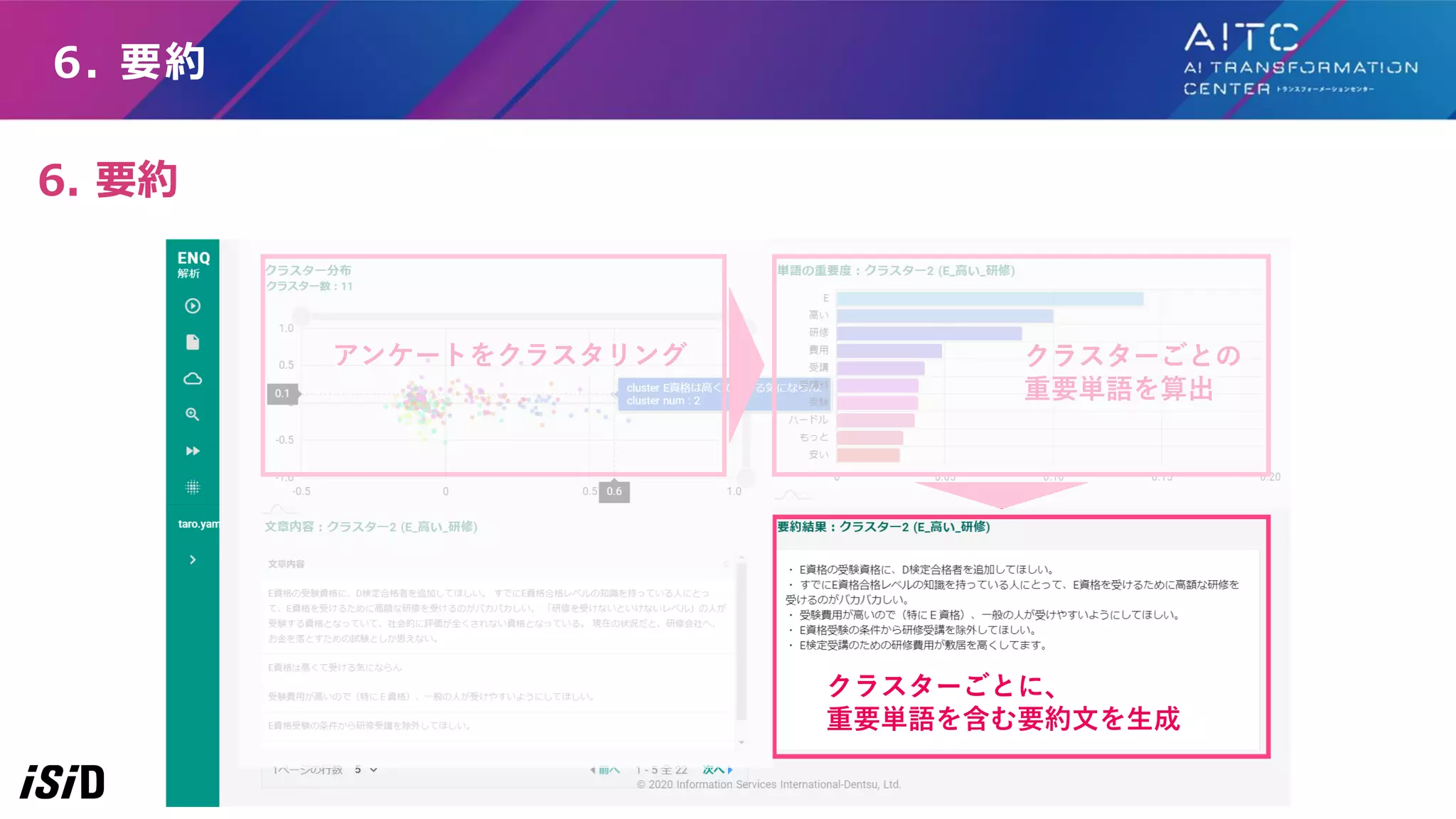
クラスタごとの要約 自動でのクラスタリングから要約結果(省略) C0:案内や情報発信が 良い感じです。 C5:良い勉強機会に なった。検定のブラン ディングをさらに伸ば して欲しい。 C3:G検定合格と業務での AI活用レベルに乖離があり、 業務レベルが身につく支援や 仕組みが欲しい C1:E資格の受験条件の緩和 を。 ※その他長文が多いクラスタ。 C4:G検定の問題バランス調整 や教育コンテンツ提供希望、な ど教育サービス提供について C2:E資格とG検定の間くらいの資 格の検討やE資格が高額。CDLEの 活性化で盛り上げて欲しい C6:検定・資格の認知度を 向上させてほしい、E取得が 取得しやすくしてほしい
12.
分析ツールからの結果 手作業との比較:概ね手作業と一致(省略) C0:案内や情報発信が良い感じです。 C1:E資格の受験条件の緩和を。※その他長文が多いクラスタ C2:E資格とG検定の間くらいの資格の検討や、CDLEの活性化で盛り上げて欲しい C3:G検定合格と業務でのAI活用レベルに乖離があり、業務レベルが身につく支援や仕組みが欲しい C4:G検定の問題バランス調整や教育コンテンツ提供希望、など教育サービス提供について C5:良い勉強機会になった。検定のブランディングをさらに伸ばして欲しい。 C6:検定・資格の認知度を向上させてほしい、E取得が取得しやすくしてほしい C0:ビジネス活用のサポートや最新AI情報の発信が欲しい C1:E資格の受験条件(認定会社受講必須)を見直して欲しい C2:資格を増やして欲しい C2:CDLEのslack関連 C3:G検定合格後のステップアップの支援が欲しい C4:G検定、E資格の過去問を公開してほしい C4:実装の支援が欲しい C4:セミナーを開催してほしい 手作業 C4: G検定、E資格の試験運用のカイゼン C4:G検定の問題内容のカイゼン C5:資格そのものの価値を向上して欲しい C6:資格を増やして欲しい C6:E資格、G検定が高額 ●今後も宜しくお願いします ●協会ホームページ改善 ●その他
13.
アンケート分析 ツールの技術詳細
14.
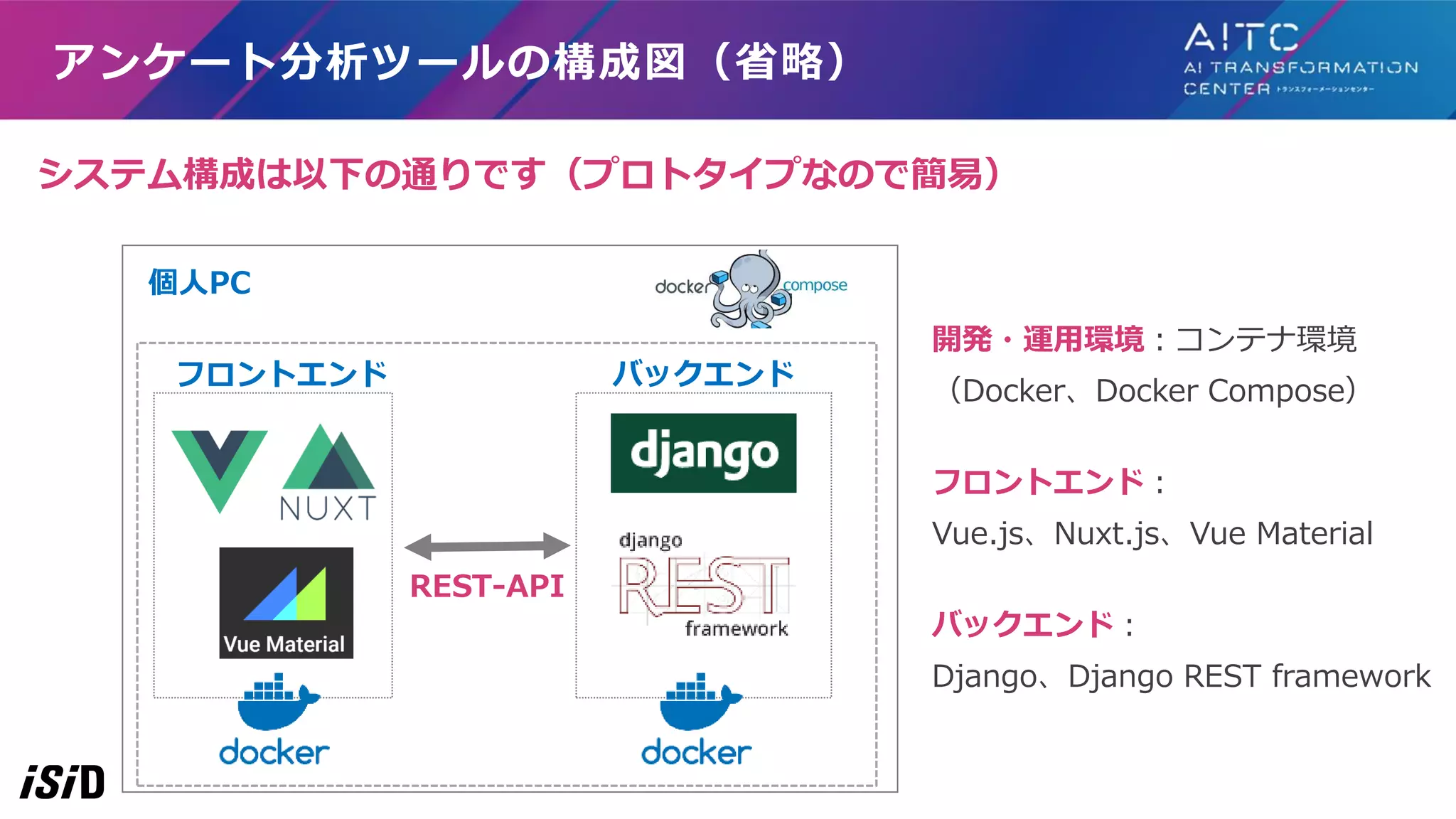
アンケート分析ツールの構成図(省略) システム構成は以下の通りです(プロトタイプなので簡易) 個人PC バックエンドフロントエンド 開発・運用環境:コンテナ環境 (Docker、Docker Compose) フロントエンド: Vue.js、Nuxt.js、Vue Material バックエンド: Django、Django
REST framework REST-API
15.
アンケート分析ツールで使ったAI技術 1. ワードクラウド 2. 文書の特徴量作成 3.
デンドログラム(樹形図や、階層別 or 階層的クラスタリングと呼ばれます) 4. クラスタリング 5. 重要単語の抽出 6. 要約 ※時間の関係上、各技術の詳細はスライド掲載のみで、分析の流れを重視して説明します。 分析ツールで使っているAI系の技術として、以下を順番に紹介します
16.
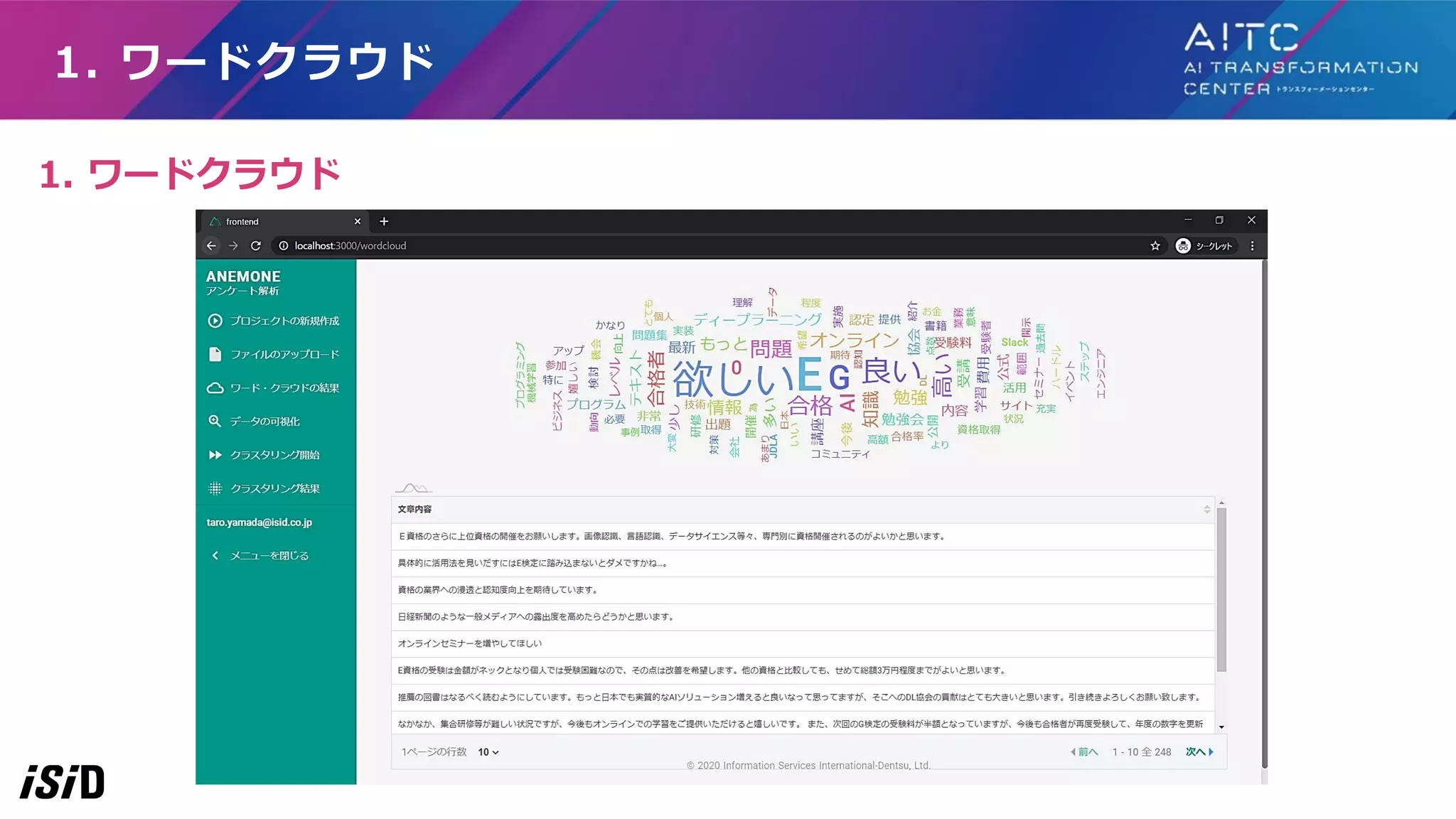
1. ワードクラウド 1. ワードクラウド
17.
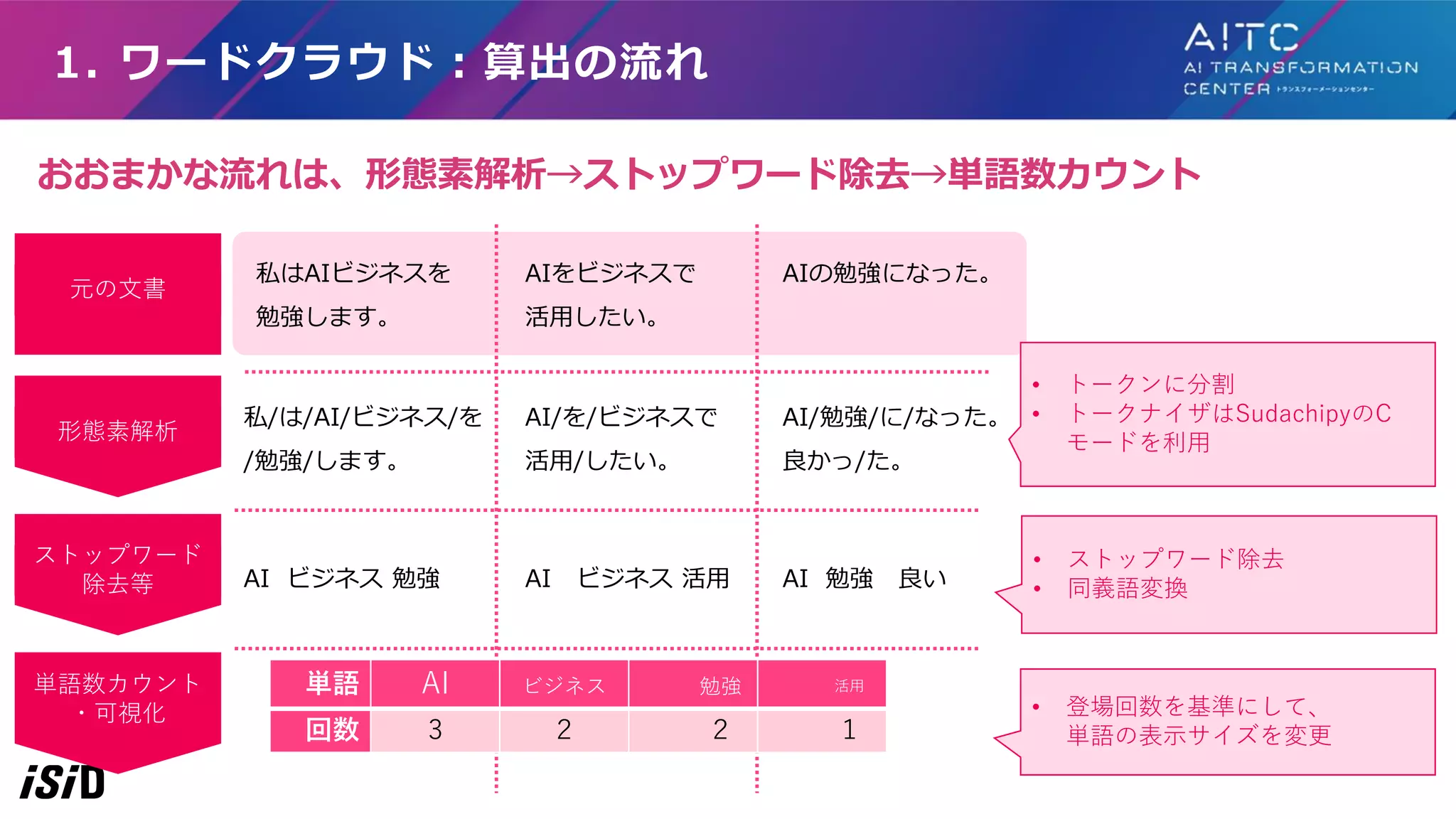
元の文書 ストップワード 除去等 単語数カウント ・可視化 私はAIビジネスを 勉強します。 AIをビジネスで 活用したい。 AIの勉強になった。 私/は/AI/ビジネス/を /勉強/します。 AI/を/ビジネスで 活用/したい。 AI/勉強/に/なった。 良かっ/た。 AI ビジネス 勉強
AI ビジネス 活用 AI 勉強 良い 単語 AI ビジネス 勉強 活用 回数 3 2 2 1 形態素解析 • トークンに分割 • トークナイザはSudachipyのC モードを利用 • ストップワード除去 • 同義語変換 • 登場回数を基準にして、 単語の表示サイズを変更 1. ワードクラウド:算出の流れ おおまかな流れは、形態素解析→ストップワード除去→単語数カウント
18.
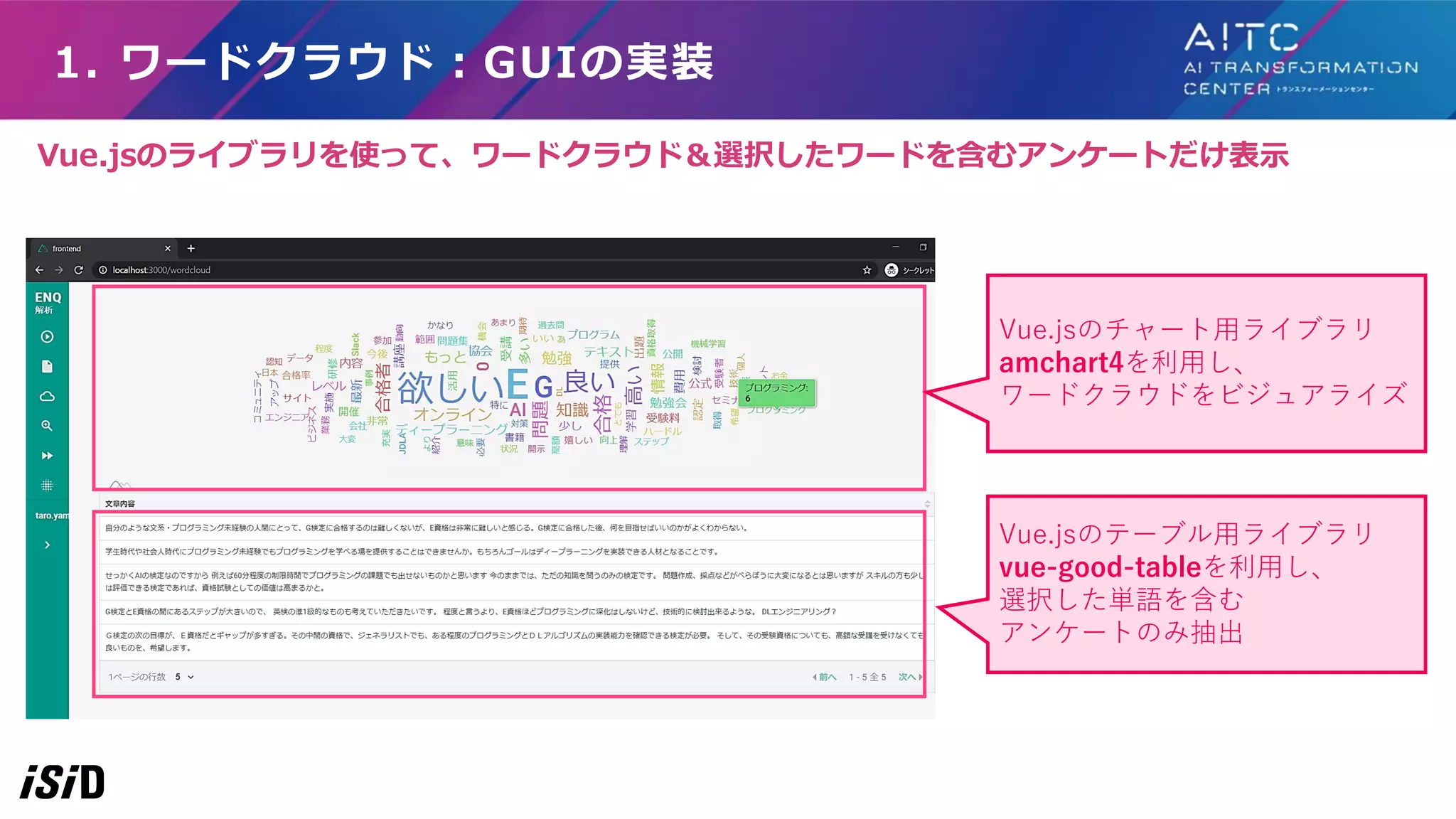
1. ワードクラウド:GUIの実装 Vue.jsのチャート用ライブラリ amchart4を利用し、 ワードクラウドをビジュアライズ Vue.jsのテーブル用ライブラリ vue-good-tableを利用し、 選択した単語を含む アンケートのみ抽出 Vue.jsのライブラリを使って、ワードクラウド&選択したワードを含むアンケートだけ表示
19.
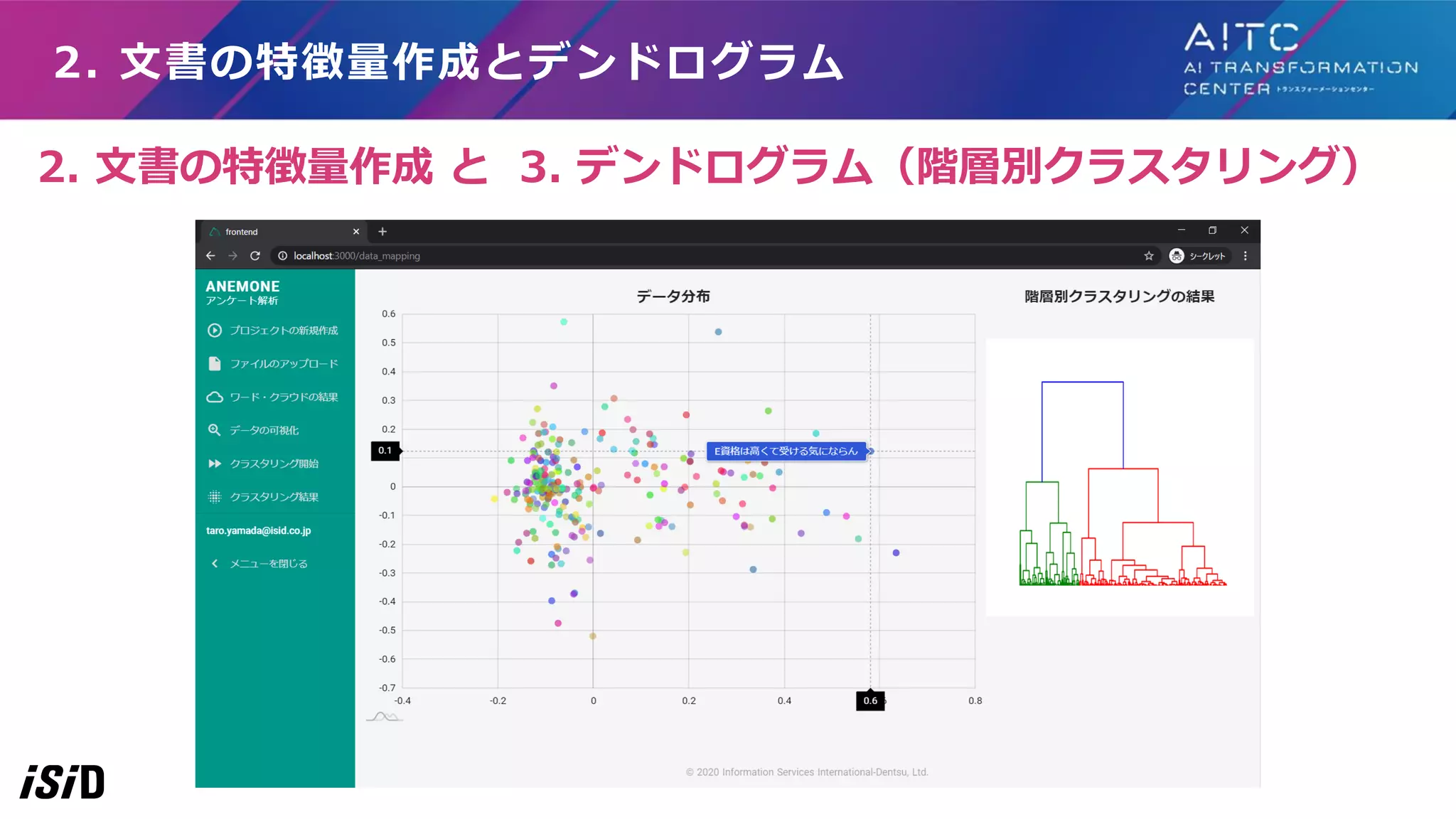
2. 文書の特徴量作成とデンドログラム 2. 文書の特徴量作成
と 3. デンドログラム(階層別クラスタリング)
20.
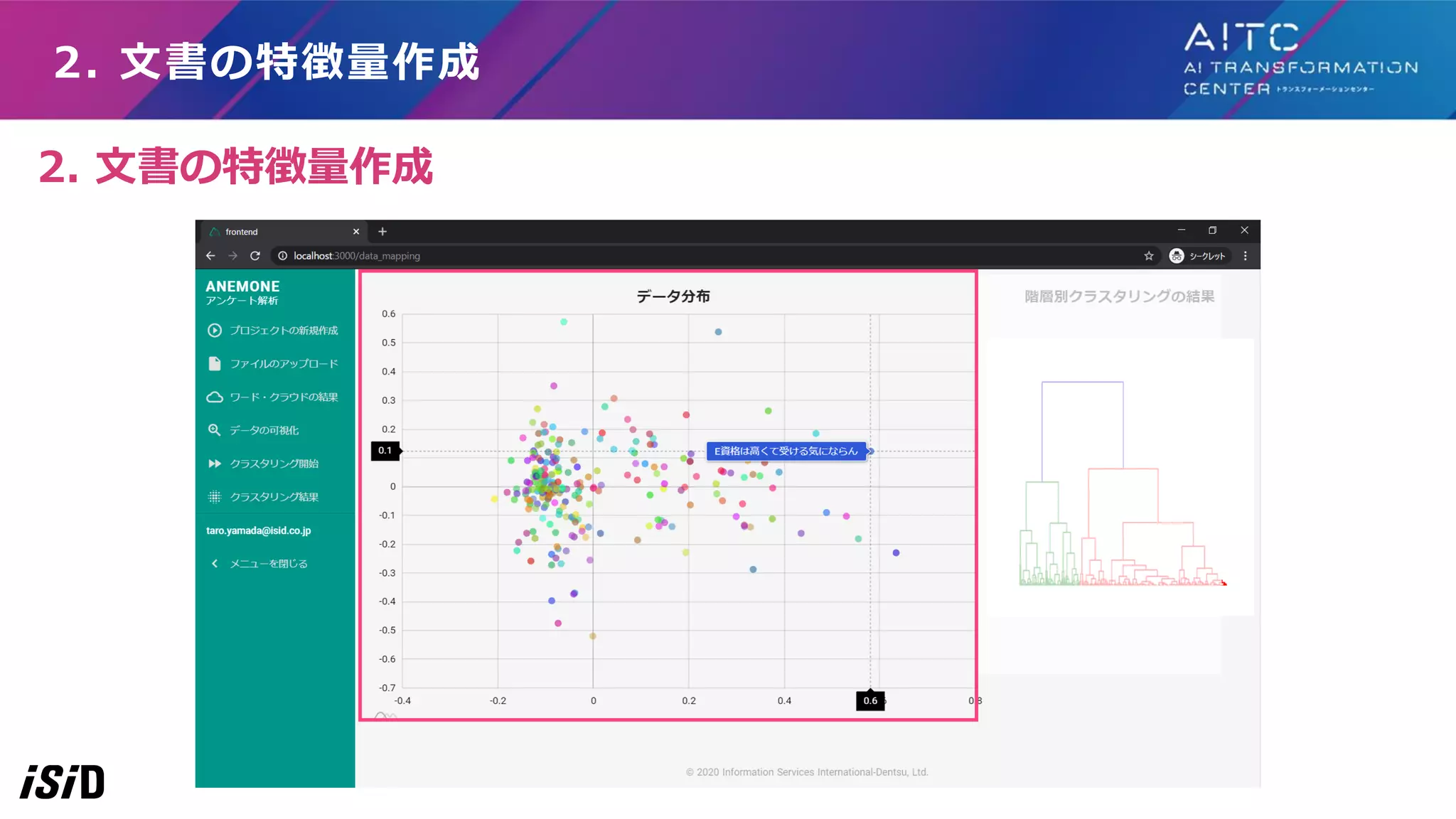
2. 文書の特徴量作成 2. 文書の特徴量作成
21.
2. 文書の特徴量作成 No. アンケート単語 1
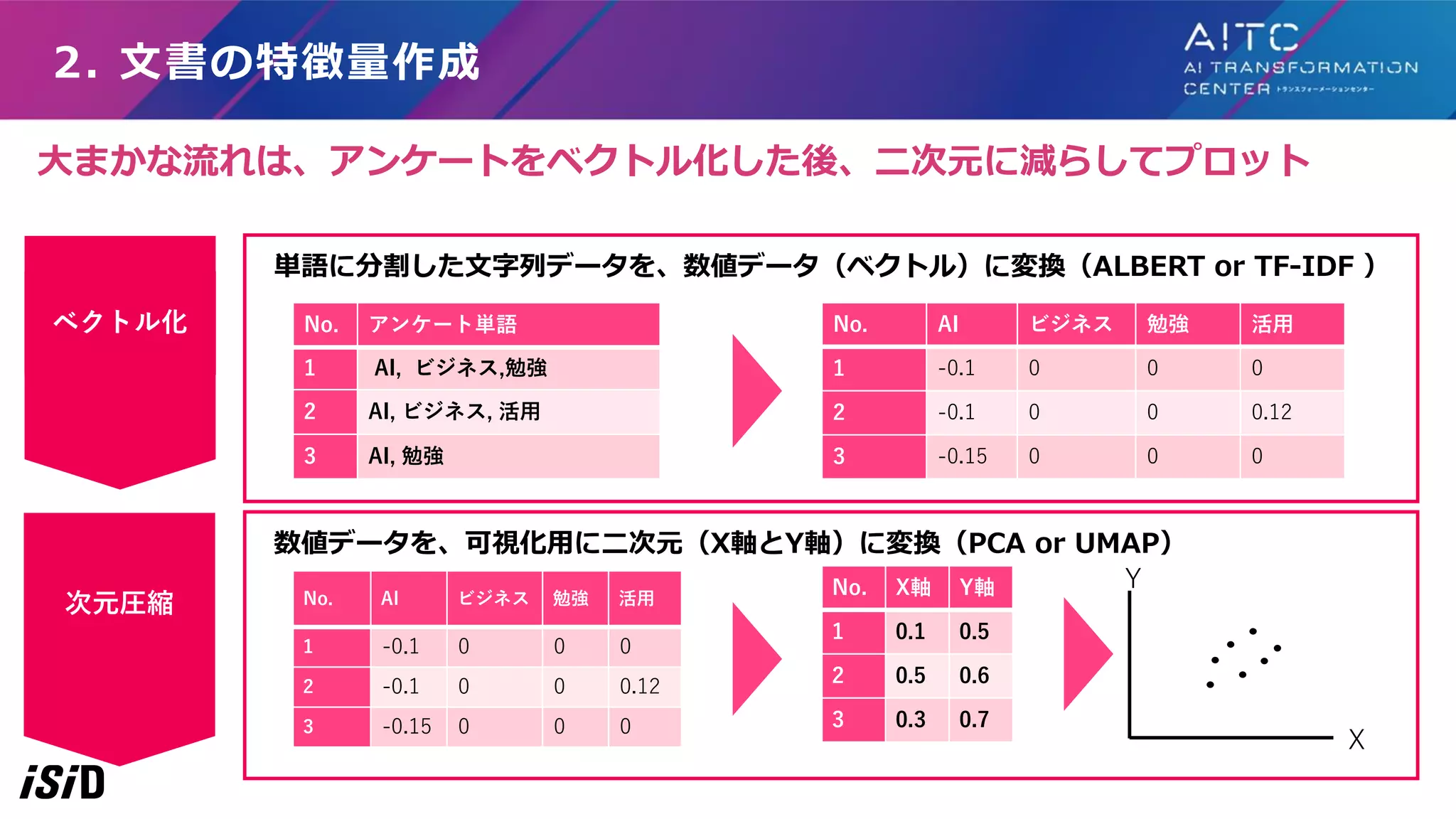
AI, ビジネス,勉強 2 AI, ビジネス, 活用 3 AI, 勉強 No. AI ビジネス 勉強 活用 1 -0.1 0 0 0 2 -0.1 0 0 0.12 3 -0.15 0 0 0 単語に分割した文字列データを、数値データ(ベクトル)に変換(ALBERT or TF-IDF ) 数値データを、可視化用に二次元(X軸とY軸)に変換(PCA or UMAP) No. X軸 Y軸 1 0.1 0.5 2 0.5 0.6 3 0.3 0.7 ベクトル化 次元圧縮 No. AI ビジネス 勉強 活用 1 -0.1 0 0 0 2 -0.1 0 0 0.12 3 -0.15 0 0 0 X Y 大まかな流れは、アンケートをベクトル化した後、二次元に減らしてプロット
22.
2. 文書の特徴量作成:ALBERT https://www.itmedia.co.jp/news/articles/1910/27/news014.html 2019年10月末、Googleは検索エンジン(英語版)に、 意図をくんで答えるBERTというディープラーニングを導入 TF-IDF PCA UMAP ベクト ル化 次元 圧縮 ALBERT
23.
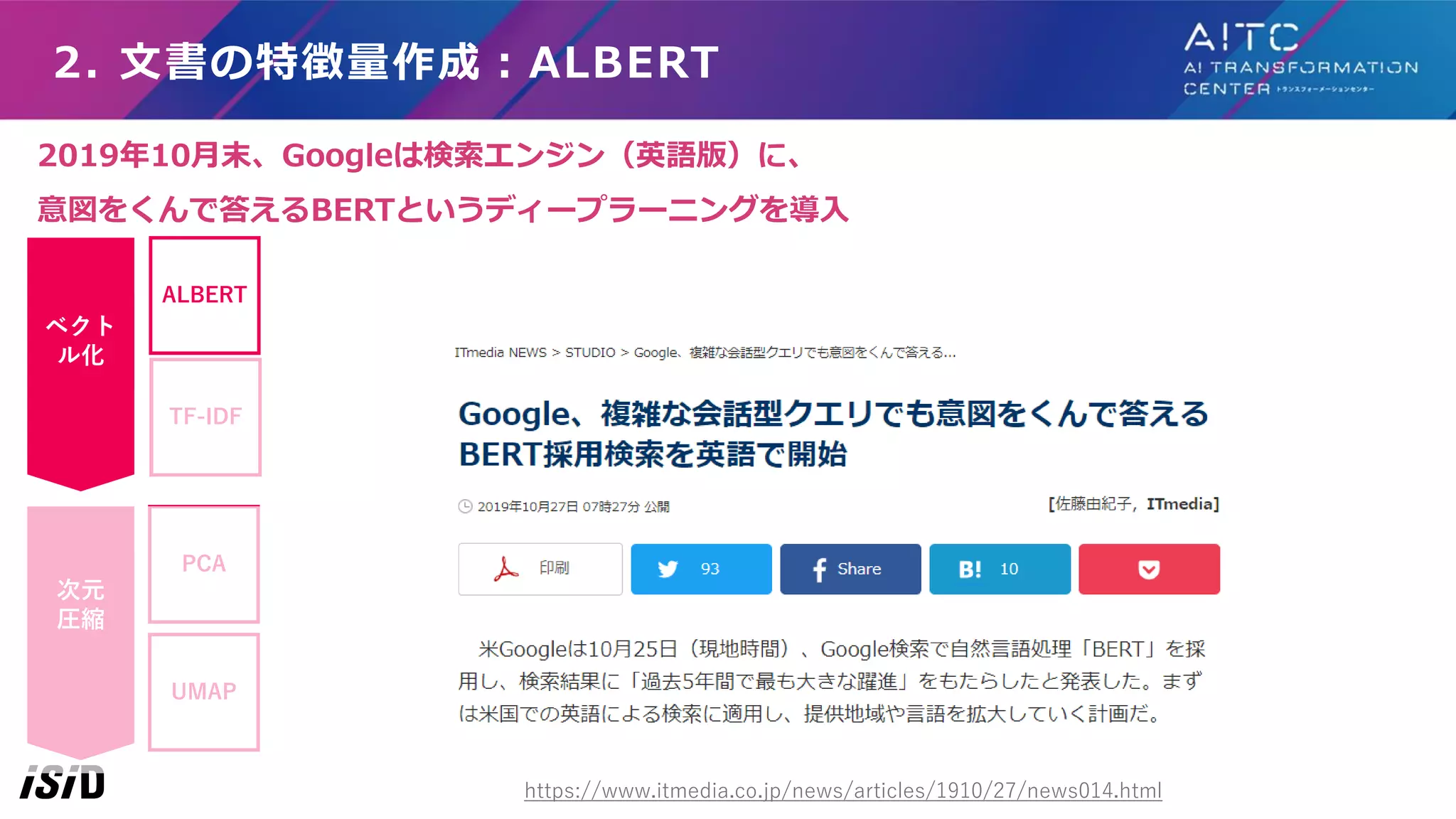
2. 文書の特徴量作成:ALBERT BERTとは、、、 ①ディープラーニング技術を用いたAIの一種です ②文脈を考慮して、単語や文章の意味を理解できる技術です 例えば、以下の3つの文章があるとします。 ①昨日、会社をくびになった。 ②昨日、たくさん運動して、くびと脚が筋肉痛だ。 ③先日、やらかしてしまい、会社を解雇された。 このときBERTは、文章①のくびは、②のくび、よりも、③の解雇、に意味が近い という文脈の意図を組むことができるディープラーニング・エンジンです。 BERTにより曖昧な検索クエリでも文章を検索したり、 文書同士の類似性を比較しやすくなります。 よって、BERTを各種製品に組み込みたいのですが、2つの大きな問題がありました PCA UMAP ベクト ル化 次元 圧縮 TF-IDF ALBERT
24.
アンケート分析ツールで使った技術の紹介 ①モデルのファイルサイズがでかすぎる(約450MB) ②入力できる文章の長さが短い(512文字:原稿用紙1枚ちょっと) この問題はGoogleも困っており、2019年12月20日に、 A Lite BERT(ALBERT)、と呼ばれる、サイズが小さいBERTモデルをGoogle が開発しました。 ISIDで私たちは、自分たちで学習させた日本語版ALBERTを使用しています https://ai.googleblog.com/2019/12/albert-lite-bert-for-self-supervised.html BERTの問題点 PCA UMAP ベクト ル化 次元 圧縮 TF-IDF ALBERT
25.
2. 文書の特徴量作成:ALBERT https://www.slideshare.net/DeepLearningLab/nlp- 236520444?ref=https://dllab.connpass.com/event/177785/presentation/ ALBERT(A Lite
BERT)については、 7/2の「自然言語処理ナイト」で詳しく解説したので、そちらをご覧ください PCA UMAP ベクト ル化 次元 圧縮 TF-IDF ALBERT
26.
2. 文書の特徴量作成:TF-IDFの仕組み① TF-IDF PCA UMAP ベクト ル化 次元 圧縮 No. 単語 1
AI,ビジネス, 勉強 2 AI, ビジネス, 活用 3 AI, 勉強 No AI ビジネス 勉強 活用 1 -0.1 0 0 0 2 -0.1 0 0 0.12 3 -0.15 0 0 0 No. [AI,ビジネス,勉強,活用] 1 [ -0.1, 0 , 0, 0] 2 [-0.1, 0, 0.12 ] 3 [-0.15, 0, 0,0] TF-IDF は、 単語の重要度スコア ▼形態素解析 ▼TF-IDFでベクトル化 イメージは、「重要な単語はポイントを高く」 「そうでもない単語はポイント低く」して文章をベクトル化 ALBERT
27.
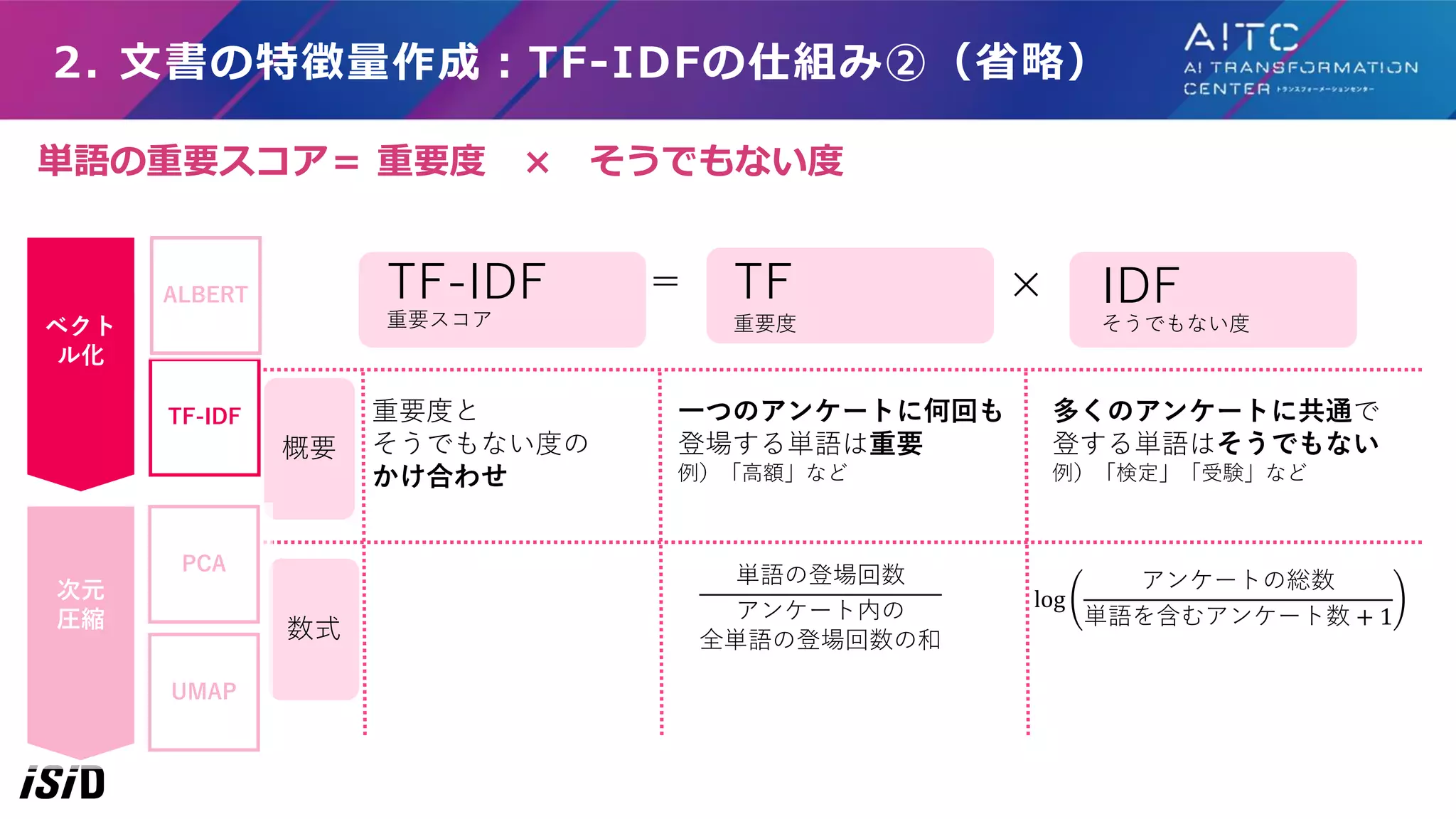
2. 文書の特徴量作成:TF-IDFの仕組み②(省略) 重要度 そうでもない度 一つのアンケートに何回も 登場する単語は重要 例)「高額」など 多くのアンケートに共通で 登する単語はそうでもない 例)「検定」「受験」など log アンケートの総数 単語を含むアンケート数
+ 1 TF-IDF 重要スコア TF IDF= × 重要度と そうでもない度の かけ合わせ 概要 数式 単語の登場回数 アンケート内の 全単語の登場回数の和 単語の重要スコア= 重要度 × そうでもない度 PCA UMAP ベクト ル化 次元 圧縮 TF-IDF ALBERT
28.
2. 文書の特徴量作成:TF-IDFの仕組み③(省略) 重要度 そうでもない度 TF-IDF 重要スコア TF
IDF= × 例 計算 No. アンケートのトークン表現 1 AI, ビジネス, 勉強 2 AI, ビジネス, 活用 3 AI, 勉強, AI ビジ ネス 勉強 活用 IDF値 -0.3 0.0 0.0 0.4 No. AI ビジ ネス 勉強 活用 1 0.3 0.3 0.3 0 2 0.3 0.3 0 0.3 3 0.5 0 0.5 0 No. AI ビジ ネス 勉 強 活用 1 -0.1 0 0 0 2 -0.1 0 0 0.12 3 -0.15 0 0 0 単語の重要スコア= 重要度 × そうでもない度 PCA UMAP ベクト ル化 次元 圧縮 TF-IDF ALBERT
29.
2. 文書の特徴量作成:PCA(主成分分析)の仕組み 第一主成分 次元圧縮する前の状態 ばらつきが大きくなる ように新しい軸をとる 新しい軸の座標で、 データを表現する 最初はXY軸上の座標で 点は表現される 元の次元数分だけ、 第一主成分と直角に軸を取れる X Y
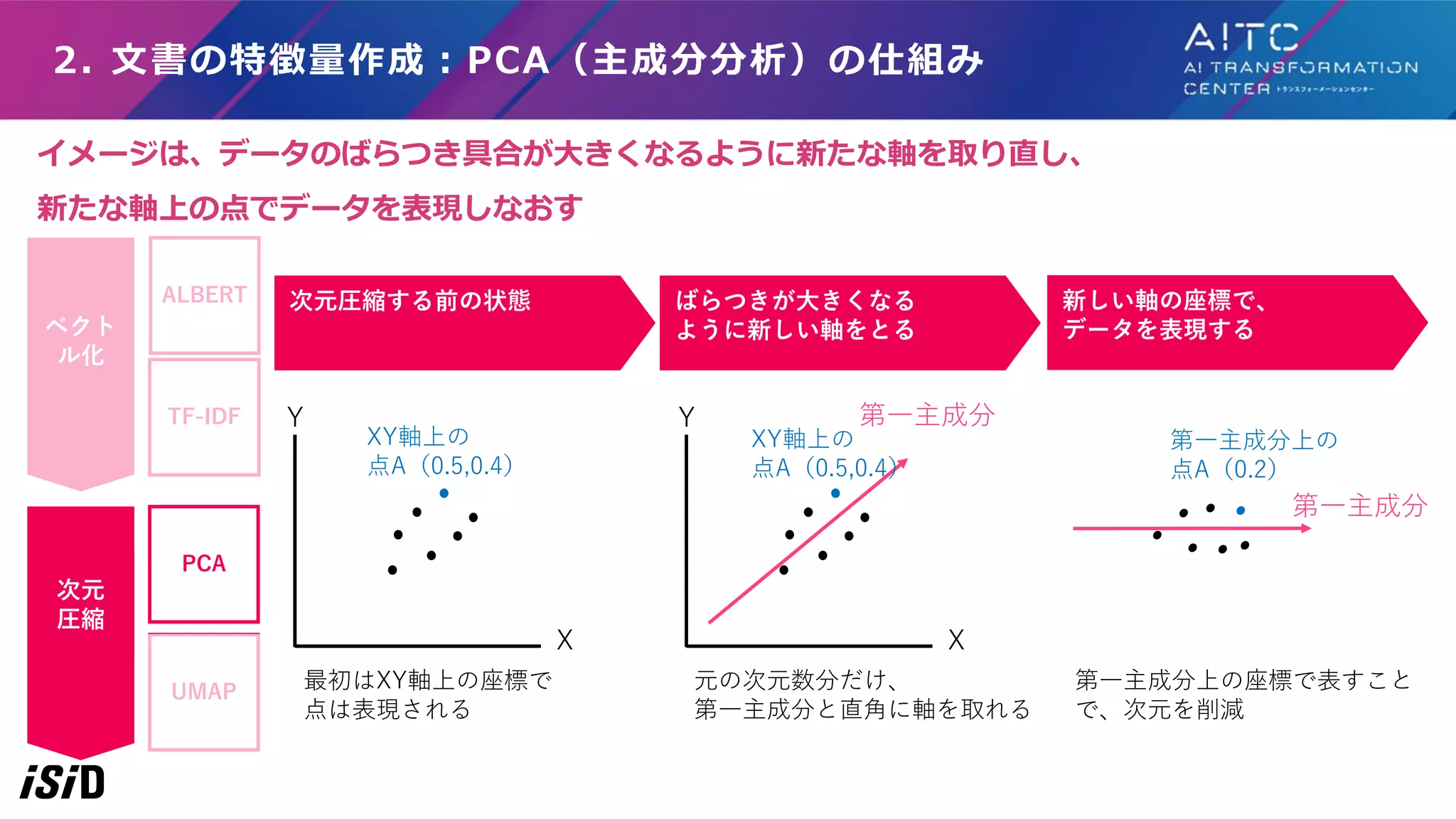
第一主成分 XY軸上の 点A(0.5,0.4) X Y XY軸上の 点A(0.5,0.4) 第一主成分上の 点A(0.2) 第一主成分上の座標で表すこと で、次元を削減 イメージは、データのばらつき具合が大きくなるように新たな軸を取り直し、 新たな軸上の点でデータを表現しなおす TF-IDF PCA UMAP ベクト ル化 次元 圧縮 ALBERT
30.
2. 文書の特徴量作成:UMAPの仕組み https://pair-code.github.io/understanding-umap/ • 色
クラスラベルだと思ってください (出典には色についての記載なし) • 円 半径が重複する点どうしを接続する 半径の色の濃さは接続の可能性 • エッジ • ポイント間の接続を示す イメージは、高次元データの構造と同じような構造を、 低次元の状態でも再現できるように学習する PCA UMAP 次元 圧縮 TF-IDF ベクト ル化 ALBERT
31.
3. デンドログラム(階層別クラスタリング) 3. デンドログラム(階層別クラスタリング)
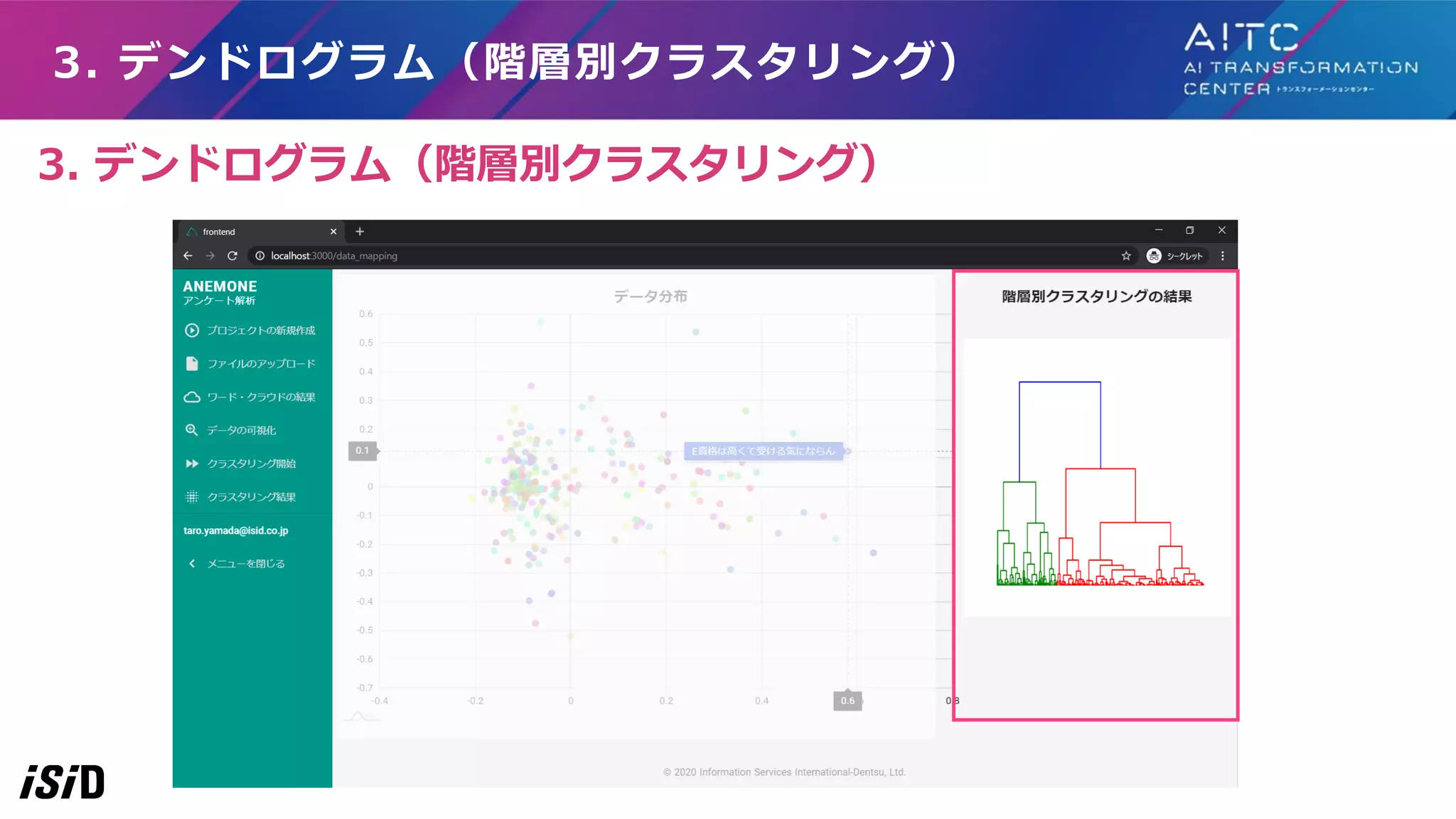
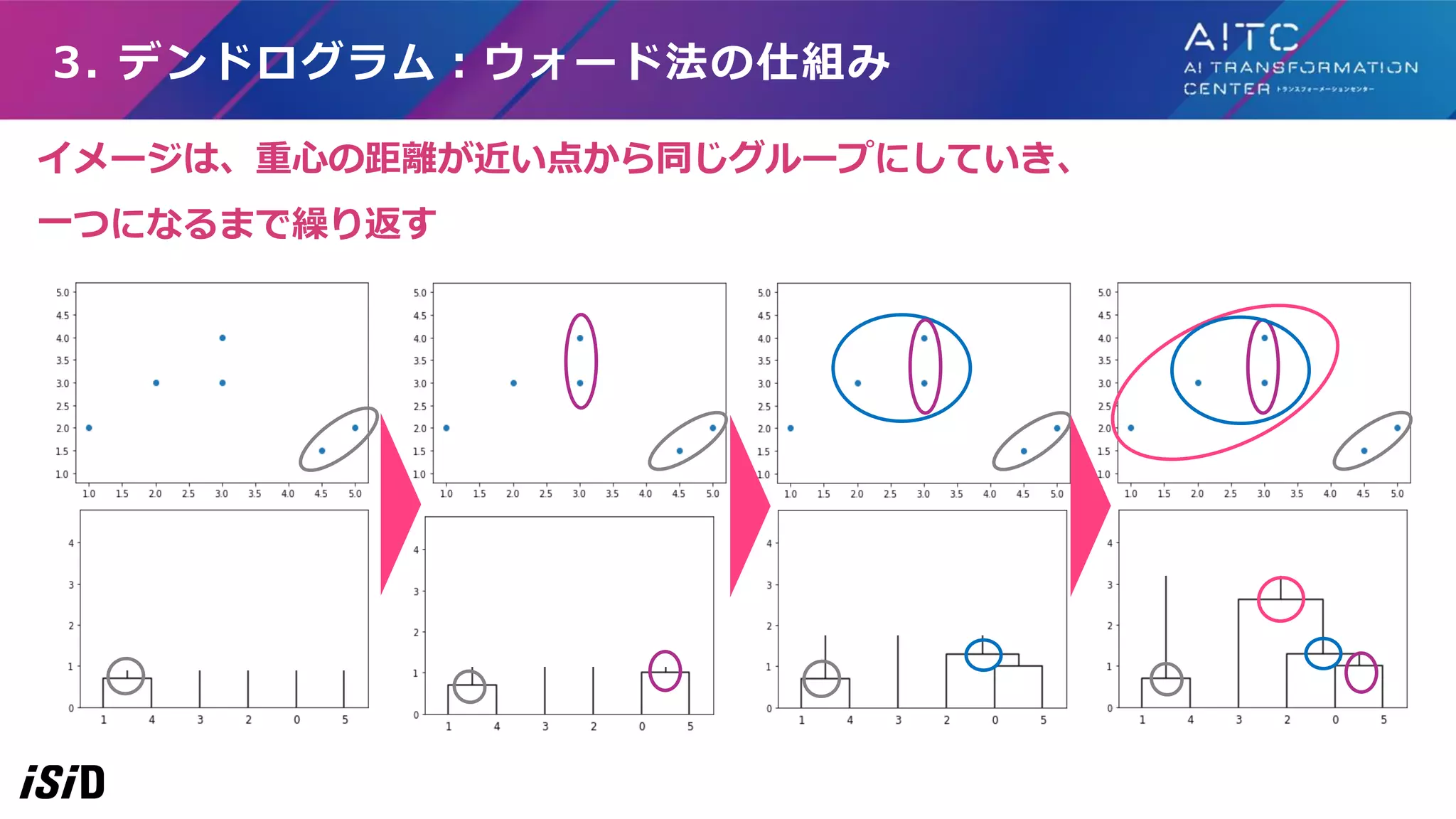
32.
3. デンドログラム:ウォード法の仕組み イメージは、重心の距離が近い点から同じグループにしていき、 一つになるまで繰り返す
33.
4. クラスタリング、5. 重要単語、
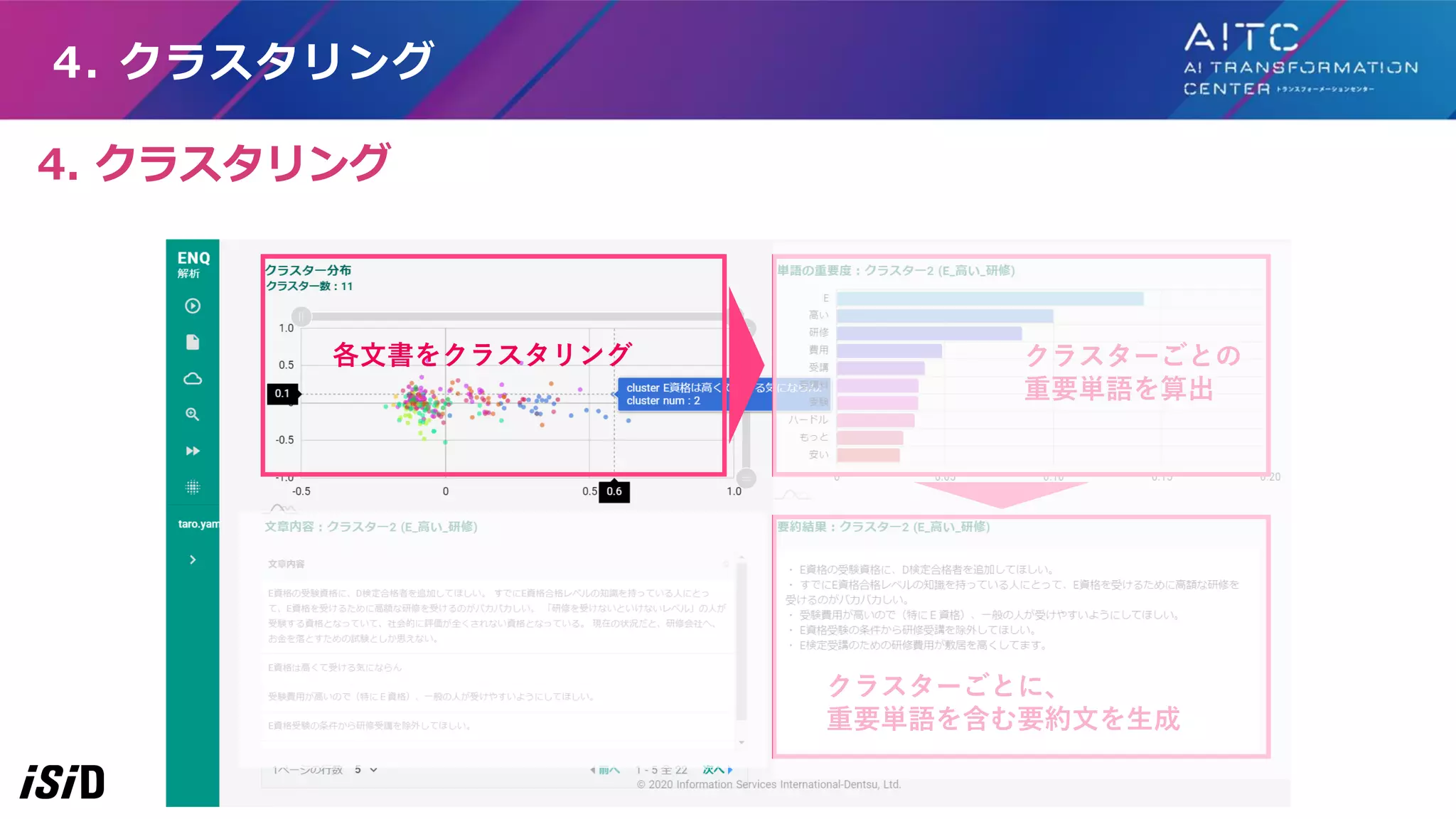
6. 要約 4. クラスタリング、5. 重要単語、 6. 要約
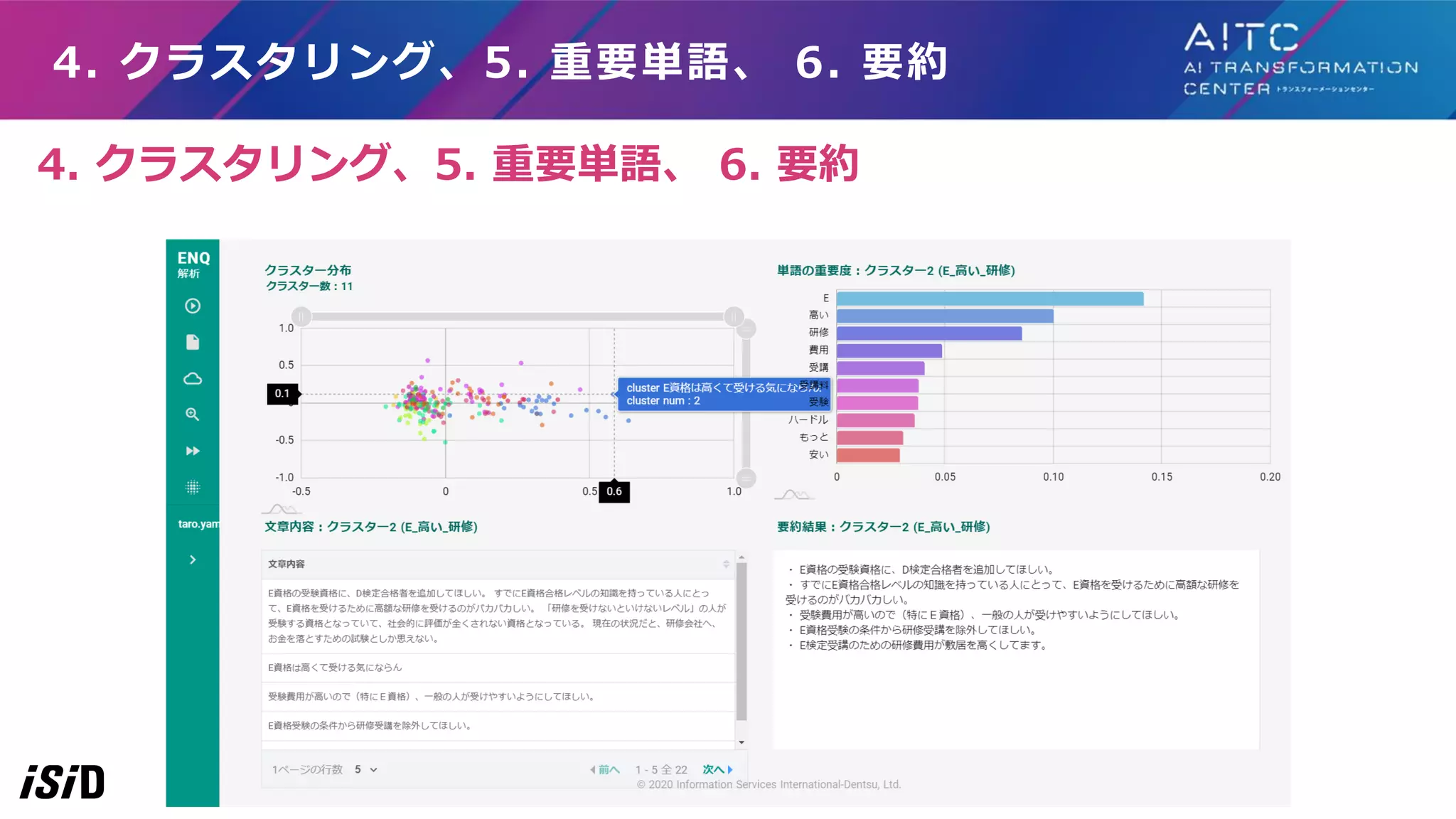
34.
4. クラスタリング、5. 重要単語、
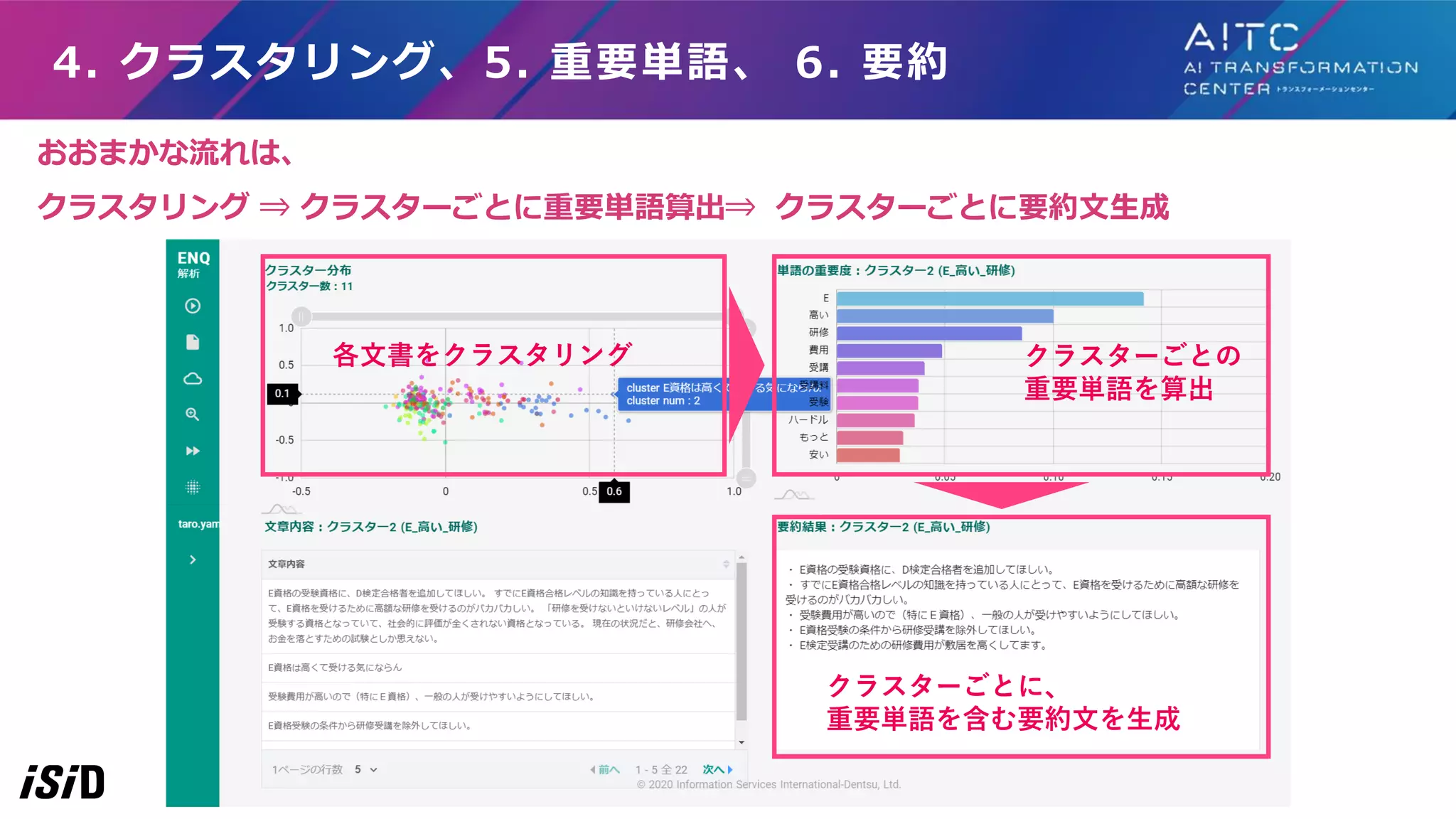
6. 要約 各文書をクラスタリング クラスターごとの 重要単語を算出 クラスターごとに、 重要単語を含む要約文を生成 おおまかな流れは、 クラスタリング ⇒ クラスターごとに重要単語算出⇒ クラスターごとに要約文生成
35.
各文書をクラスタリング クラスターごとの 重要単語を算出 クラスターごとに、 重要単語を含む要約文を生成 4. クラスタリング 4.
クラスタリング
36.
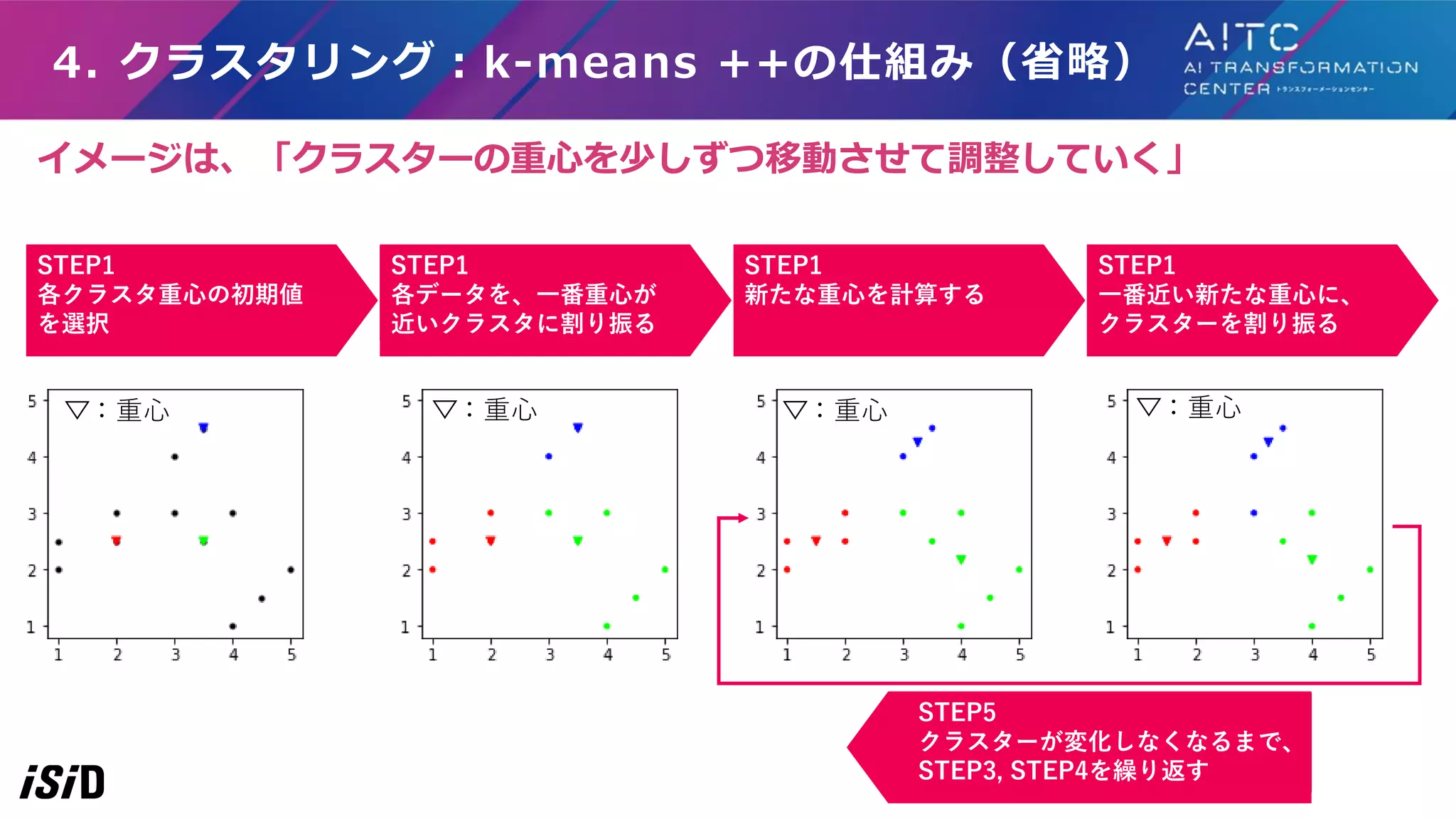
4. クラスタリング:k-means ++の仕組み(省略) STEP1 各クラスタ重心の初期値 を選択 STEP1 各データを、一番重心が 近いクラスタに割り振る STEP1 新たな重心を計算する STEP1 一番近い新たな重心に、 クラスターを割り振る STEP5 クラスターが変化しなくなるまで、 STEP3,
STEP4を繰り返す :重心 :重心 :重心 :重心 イメージは、「クラスターの重心を少しずつ移動させて調整していく」
37.
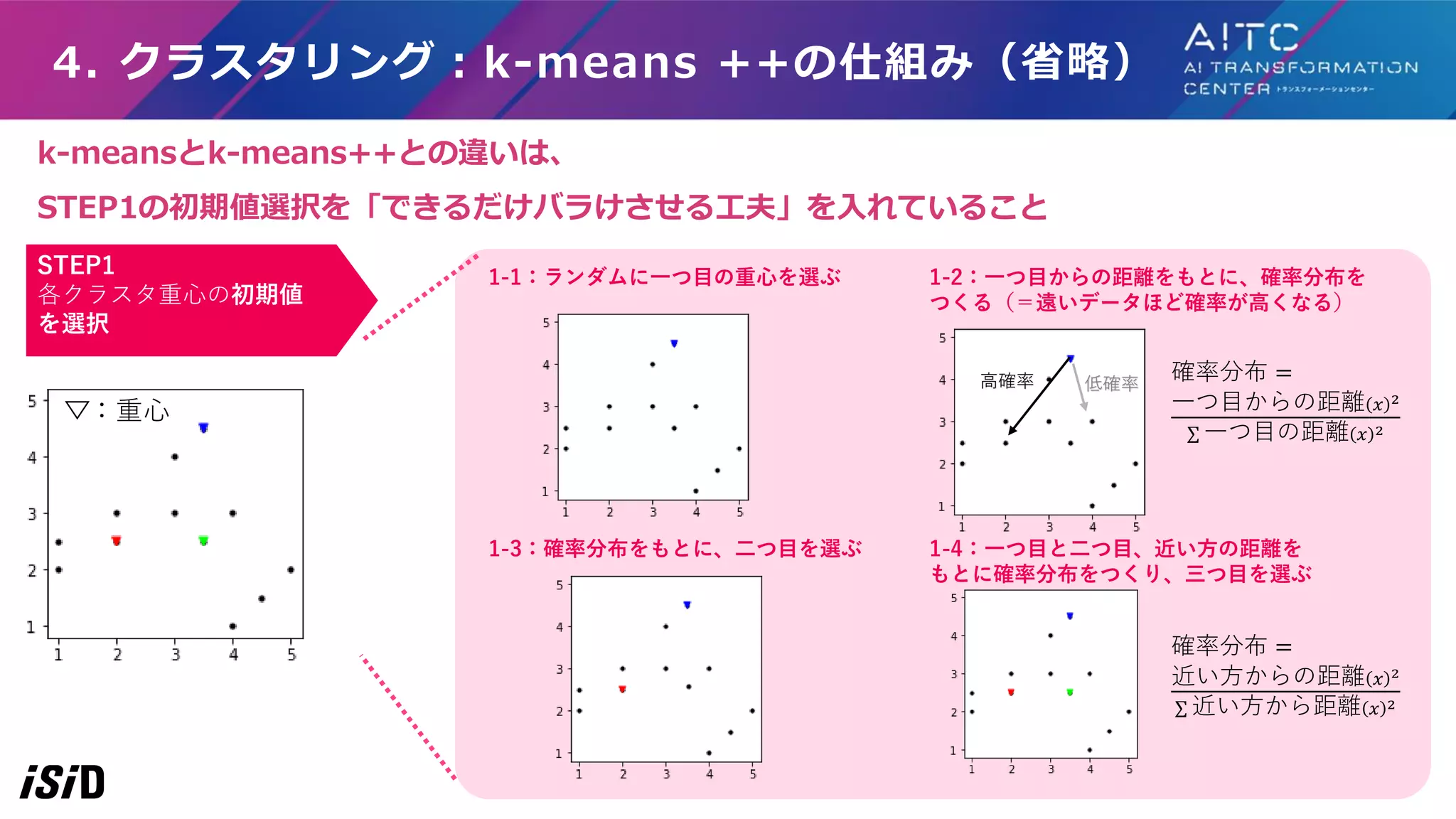
4. クラスタリング:k-means ++の仕組み(省略) STEP1 各クラスタ重心の初期値 を選択 1-1:ランダムに一つ目の重心を選ぶ
1-2:一つ目からの距離をもとに、確率分布を つくる(=遠いデータほど確率が高くなる) 1-3:確率分布をもとに、二つ目を選ぶ 1-4:一つ目と二つ目、近い方の距離を もとに確率分布をつくり、三つ目を選ぶ 確率分布 = 一つ目からの距離 𝑥 2 一つ目の距離 𝑥 2 高確率 低確率 確率分布 = 近い方からの距離 𝑥 2 近い方から距離 𝑥 2 :重心 k-meansとk-means++との違いは、 STEP1の初期値選択を「できるだけバラけさせる工夫」を入れていること
38.
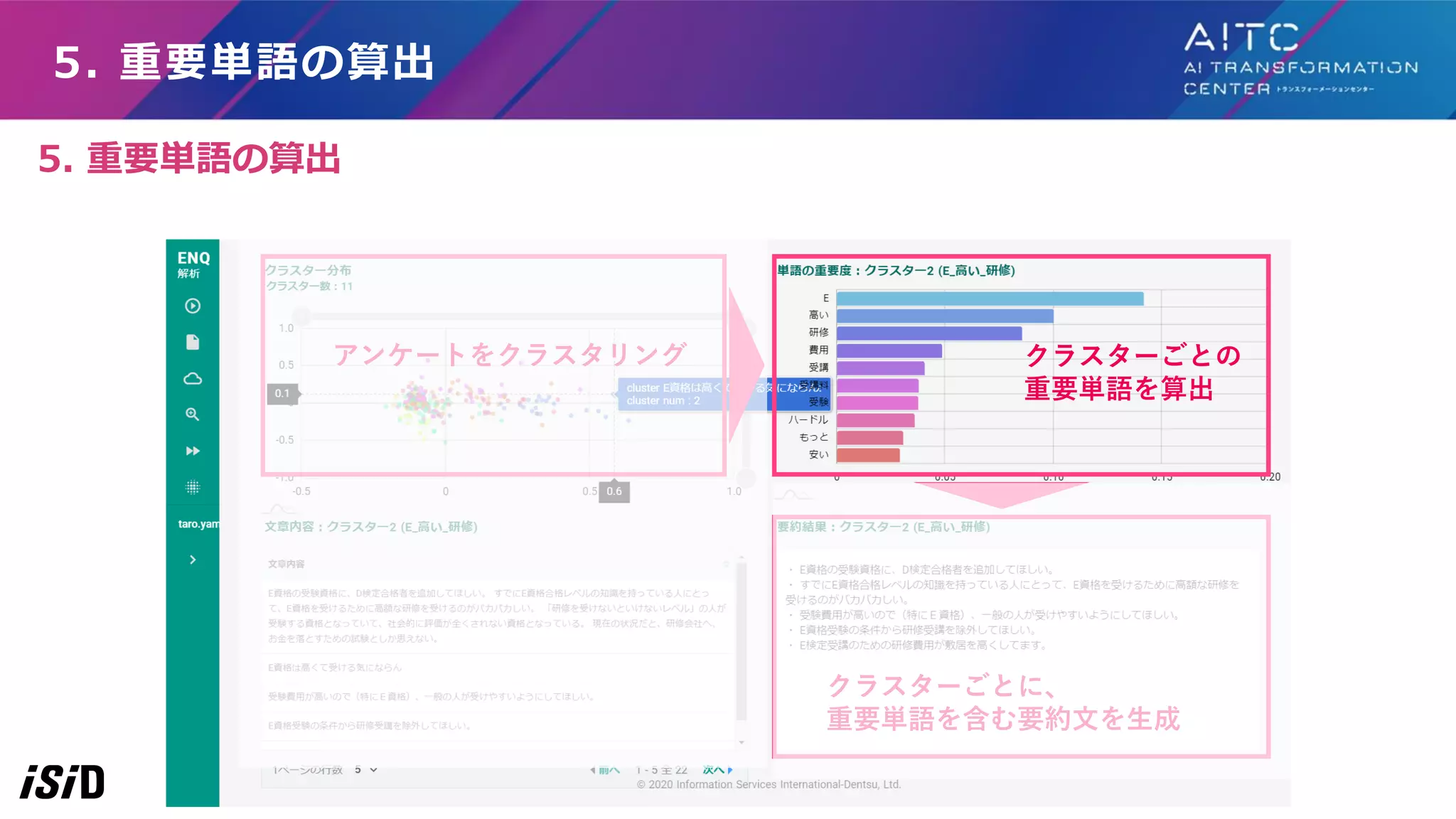
5. 重要単語の算出 アンケートをクラスタリング クラスターごとの 重要単語を算出 クラスターごとに、 重要単語を含む要約文を生成 5.
重要単語の算出
39.
アンケート分析ツールで使った技術の紹介(省略) 「静的なタイプ」 1. クラスタ内の単語の頻度、tf-idf値、クラスタ間での頻度などから判定 2. クラスタ全文書の平均ベクトルと近い単語ベクトル 「クラスタごとに教師あり学習に置き換えるタイプ」:各クラスタとその他(1
VS ALL)を分離するモ デルをクラスタ数分作成 A) L1ノルム罰則の回帰:Lassoで、モデルの係数が大きい単語を重要単語とする B) ランダムフォレスト、LightGBM(グラディエントブースティング)などのモデルをクラスタ数分作成し、 Feature Importance(特徴量の重要度)が高い単語を重要単語とする C) LIMEもしくはSHAPでモデルを作成し、各文章の重要単語の情報から、グローバルに重要な単語を抽出 D) MSのInterpretML-Text(Unified Information Explainer≒ノイズへの頑強性から重要単語検出、 Introspective Rationale Explainer≒学習時に重要単語抽出モデルも作成 )の使用 クラスタを代表する重要単語を抽出する手法(を考えてみた) https://www.youtube.com/watch?v=oL0P5n6jZBc https://github.com/interpretml/interpret-text
40.
アンケート分析ツールで使った技術の紹介 今回は、 「クラスタごとに教師あり学習に置き換えるタイプ」:各クラスタとその他(1 VS ALL)を分離するモ デルをクラスタ数分作成 B)ランダムフォレスト、LightGBM(グラディエントブースティング)などのモデルをクラスタ数分作成し、 Feature
Importance(特徴量の重要度)が高い単語を重要単語とする を使用。tf-idfでベクトル化してランダムフォレストで1 VS ALLのモデルをクラスタ数分作り、クラスタごとに Feature Importanceの高い単語を重要単語として抽出 クラスターを代表する重要単語を抽出する手法
41.
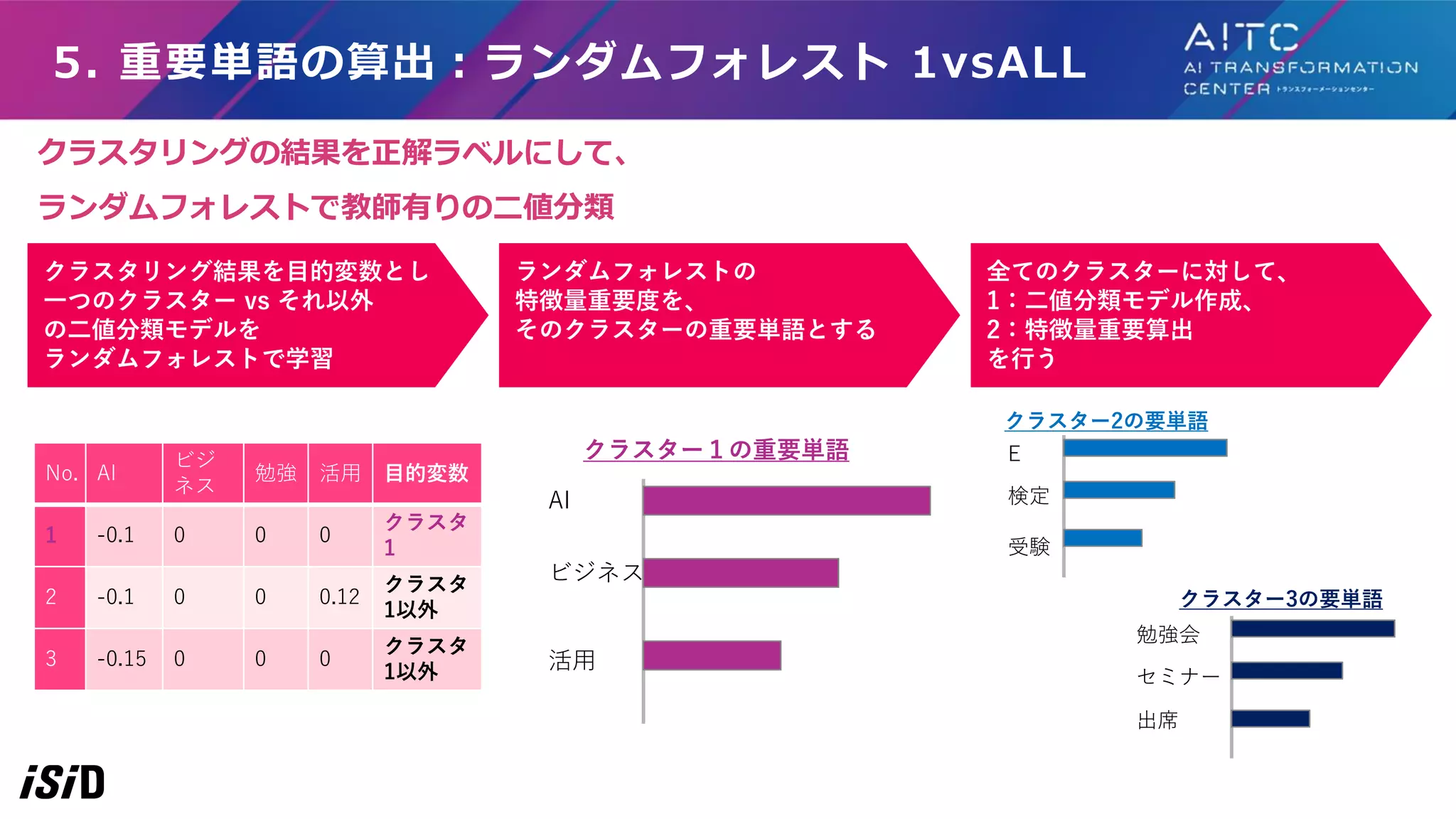
5. 重要単語の算出:ランダムフォレスト 1vsALL クラスタリング結果を目的変数とし 一つのクラスター
vs それ以外 の二値分類モデルを ランダムフォレストで学習 No. AI ビジ ネス 勉強 活用 目的変数 1 -0.1 0 0 0 クラスタ 1 2 -0.1 0 0 0.12 クラスタ 1以外 3 -0.15 0 0 0 クラスタ 1以外 AI ビジネス 活用 E 検定 受験 勉強会 セミナー 出席 クラスター1の重要単語 クラスター2の要単語 クラスター3の要単語 ランダムフォレストの 特徴量重要度を、 そのクラスターの重要単語とする 全てのクラスターに対して、 1:二値分類モデル作成、 2:特徴量重要算出 を行う クラスタリングの結果を正解ラベルにして、 ランダムフォレストで教師有りの二値分類
42.
6. 要約 アンケートをクラスタリング クラスターごとの 重要単語を算出 クラスターごとに、 重要単語を含む要約文を生成 6.
要約
43.
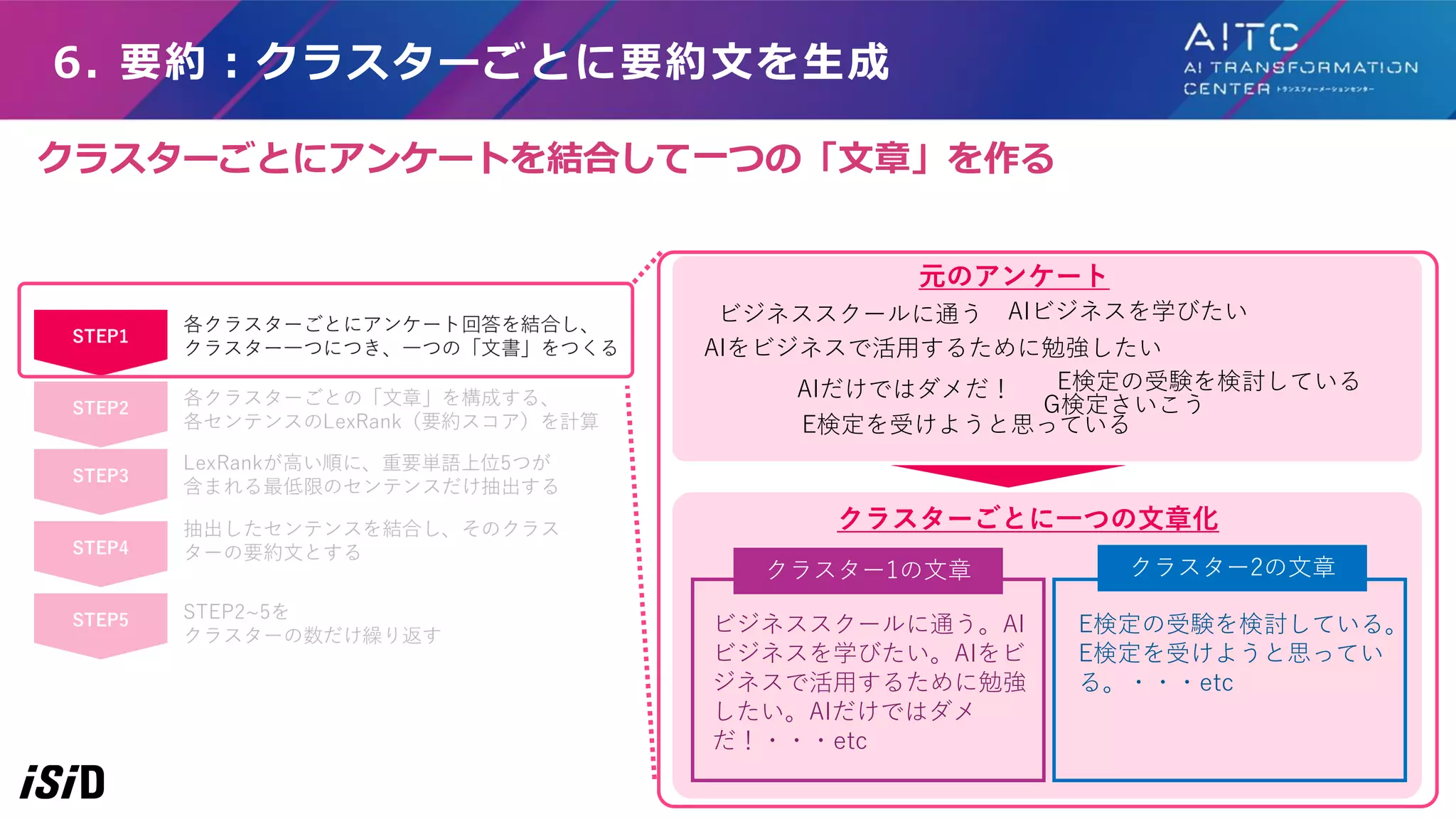
STEP1 STEP3 STEP4 STEP2 STEP5 各クラスターごとにアンケート回答を結合し、 クラスター一つにつき、一つの「文書」をつくる 各クラスターごとの「文章」を構成する、 各センテンスのLexRank(要約スコア)を計算(LexRankはあとで説明) LexRankが高い順に、重要単語上位5つが 含まれる最低限のセンテンスだけ抽出する STEP2~5を クラスターの数だけ繰り返す 抽出したセンテンスを結合し、そのクラス ターの要約文とする 6. 要約:クラスターごとに要約文を生成 大まかな流れは、各クラスターごとのアンケートを「一つの文章」とみなし、 その文章の要約文を生成する
44.
6. 要約:クラスターごとに要約文を生成 ビジネススクールに通う。AI ビジネスを学びたい。AIをビ ジネスで活用するために勉強 したい。AIだけではダメ だ!・・・etc E検定の受験を検討している。 E検定を受けようと思ってい る。・・・etc 元のアンケート クラスターごとに一つの文章化 クラスター1の文章 クラスター2の文章 AIビジネスを学びたい AIをビジネスで活用するために勉強したい G検定さいこう ビジネススクールに通う AIだけではダメだ!
E検定の受験を検討している E検定を受けようと思っている クラスターごとにアンケートを結合して一つの「文章」を作る
45.
6. 要約:クラスターごとに要約文を生成 ▼クラスタ1の要約スコア ※LexRankによる要約スコア算出の仕組みは後述 センテンス LexRank (要約スコア) ビジネススクールに通う 0.2 AIビジネスを学びたい
0.3 AIをビジネスで活用するために勉強したい 0.4 AIだけではダメだ! 0.2 G検定さいこう! 0.1 各クラスターごとの「文章」を構成する、各センテンスのLexRank(要約スコア)を計算
46.
6. 要約:クラスターごとに要約文を生成 ▼クラスター1から抽出するセンテンス センテンス LexRank (要約スコア) AIをビジネスで活用するために勉強したい 0.4 AIビジネスを学びたい
0.3 ▼クラスター1の重要単語TOP5 AI ビジネス 活用 学び 勉強 LexRankが高い順に、重要単語上位5つが含まれる最低限のセンテンスだけ抽出する
47.
6. 要約:クラスターごとに要約文を生成 ▼生成されたクラスター1の要約文 • AIをビジネスで活用するために勉強したい •
AIビジネスを学びたい 抽出したセンテンスを結合し、そのクラスターの要約文とする
48.
6. 要約:クラスターごとに要約文を生成 ▼クラスター1の要約文 • AIをビジネスで活用するために勉強したい •
AIビジネスを学びたい ▼クラスター2の要約文 • E検定を受けようと思っている • E検定の受験を検討している ▼クラスター3の要約文 • 勉強会を主催してほしい • AIに関する勉強会に出席するきっかけになった STEP2~5をクラスターの数だけ繰り返す
49.
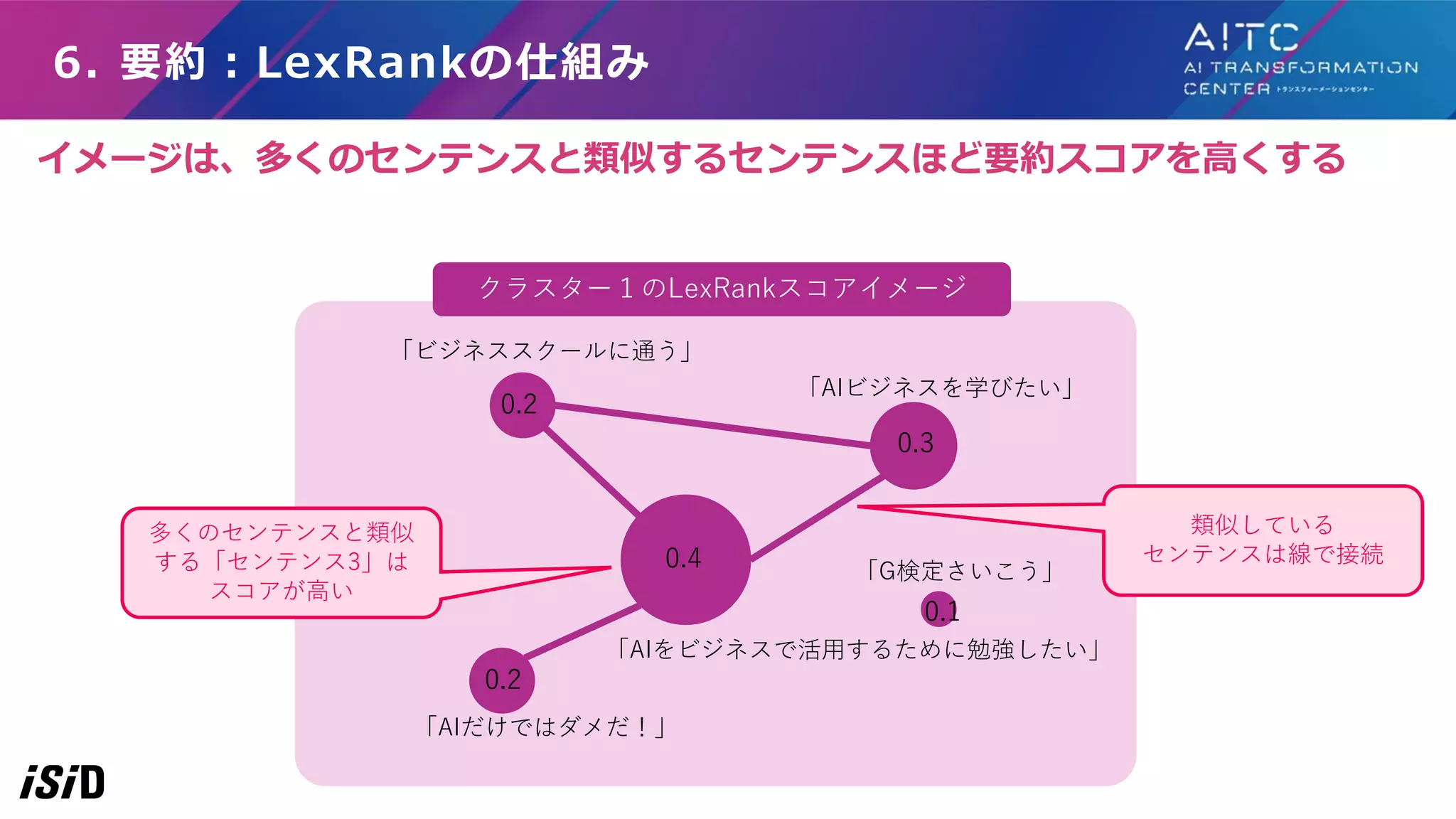
6. 要約:LexRankの仕組み 「AIビジネスを学びたい」 「AIをビジネスで活用するために勉強したい」 「G検定さいこう」 0.2 0.2 0.4 0.3 0.1 類似している センテンスは線で接続 多くのセンテンスと類似 する「センテンス3」は スコアが高い クラスター1のLexRankスコアイメージ 「ビジネススクールに通う」 「AIだけではダメだ!」 イメージは、多くのセンテンスと類似するセンテンスほど要約スコアを高くする
50.
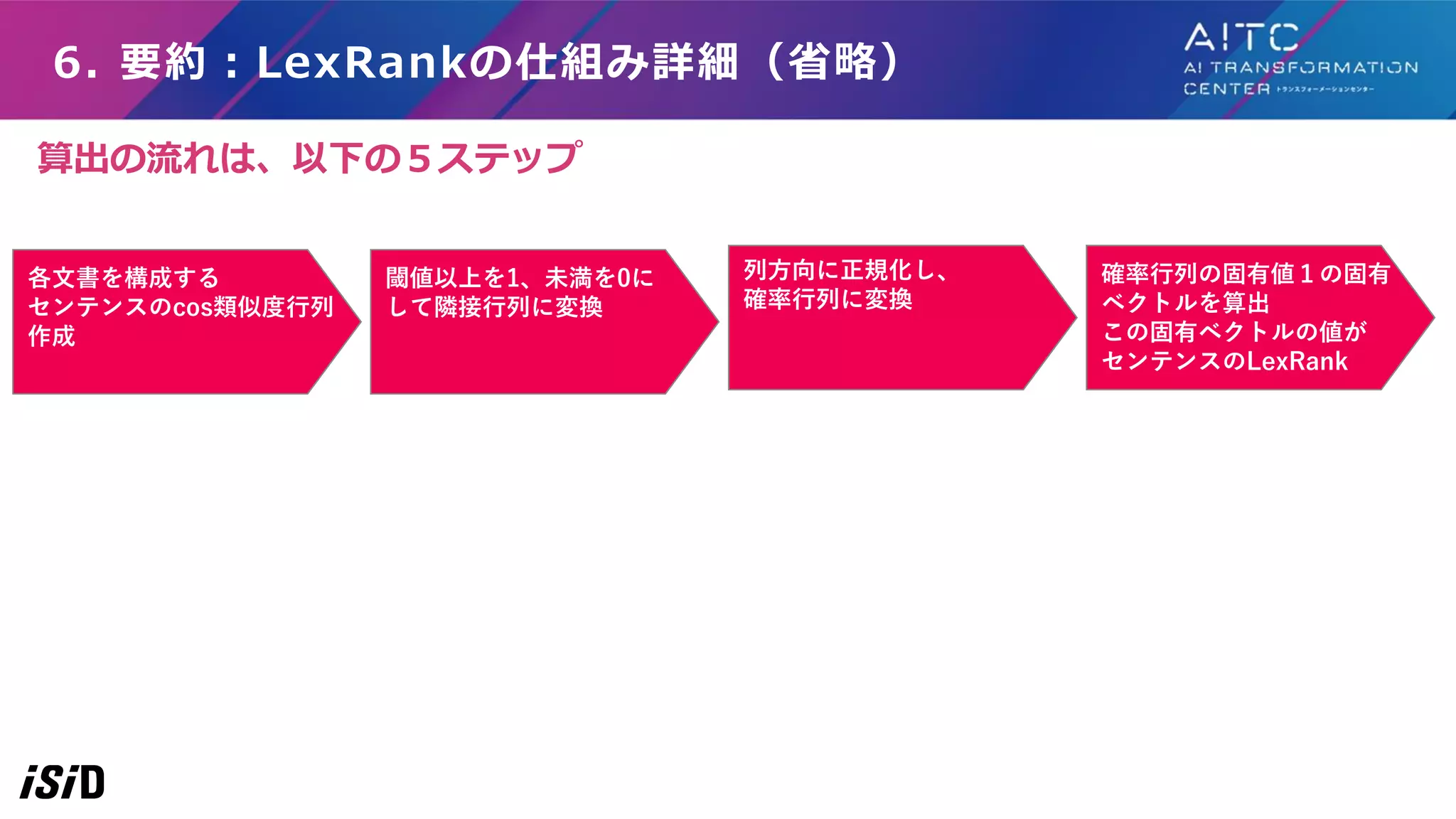
6. 要約:LexRankの仕組み詳細(省略) 各文書を構成する センテンスのcos類似度行列 作成 閾値以上を1、未満を0に して隣接行列に変換 列方向に正規化し、 確率行列に変換 確率行列の固有値1の固有 ベクトルを算出 この固有ベクトルの値が センテンスのLexRank 算出の流れは、以下の5ステップ
51.
6. 要約:LexRankの仕組み詳細(省略) ビジネススクールに 通う AIビジネスを学 びたい AIをビジネスで活用す るために勉強したい ビジネススクールに通 う 1 0.3
0.2 AIビジネスを学びたい 0.3 1 0.5 AIをビジネスで活用す るために勉強したい 0.2 0.5 1 ▼クラスター1の類似度行列 「AIビジネスを学びたい」 と「AIをビジネスで活用する ために勉強したい」 の類似度は「0.5」 各文書を構成する センテンスのcos類似度行列 作成 閾値以上を1、未満を0に して隣接行列に変換 列方向に正規化し、 確率行列に変換 確率行列の固有値1の固有 ベクトルを算出 この固有ベクトルの値が センテンスのLexRank 「センテンス同士の類似度」行列(=類似度行列)を作成
52.
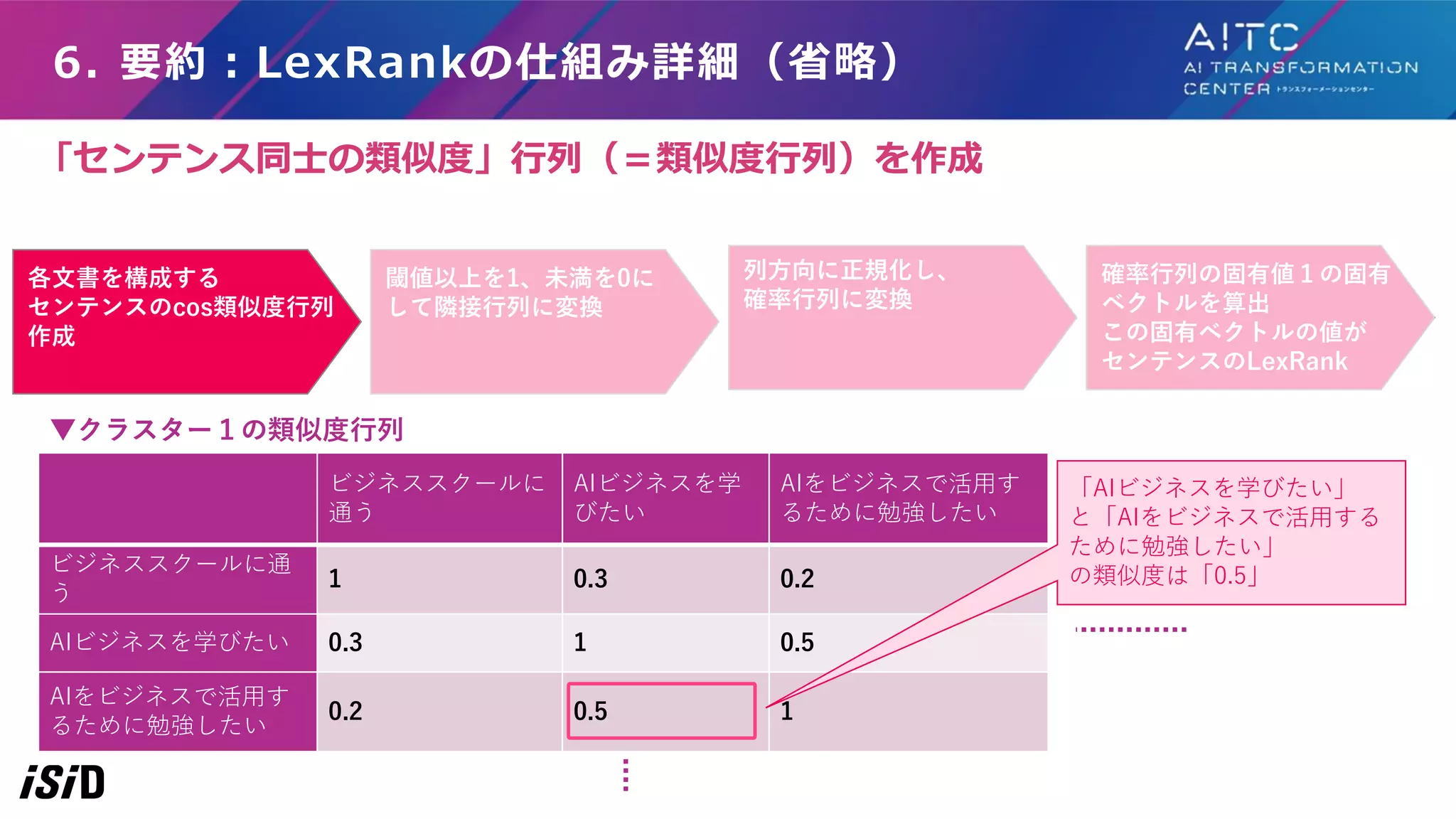
6. 要約:LexRankの仕組み詳細(省略) 各文書を構成する センテンスのcos類似度行列 作成 閾値以上を1、未満を0に して隣接行列に変換 列方向に正規化し、 確率行列に変換 ビジネススクールに 通う AIビジネスを学 びたい AIをビジネスで活用す るために勉強したい ビジネススクールに通 う 1 0
0 AIビジネスを学びたい 0 1 1 AIをビジネスで活用す るために勉強したい 0 1 1 確率行列の固有値1の固有 ベクトルを算出 この固有ベクトルの値が センテンスのLexRank ▼閾値を0.5とした場合のクラスター1の隣接行列 「AIビジネスを学びたい」 と「AIをビジネスで活用する ために勉強したい」には 類似フラグを立てる 類似度を閾値以上は1、閾値未満は0にして、 「センテンス同士の類似フラグ」の行列(=隣接行列)にする
53.
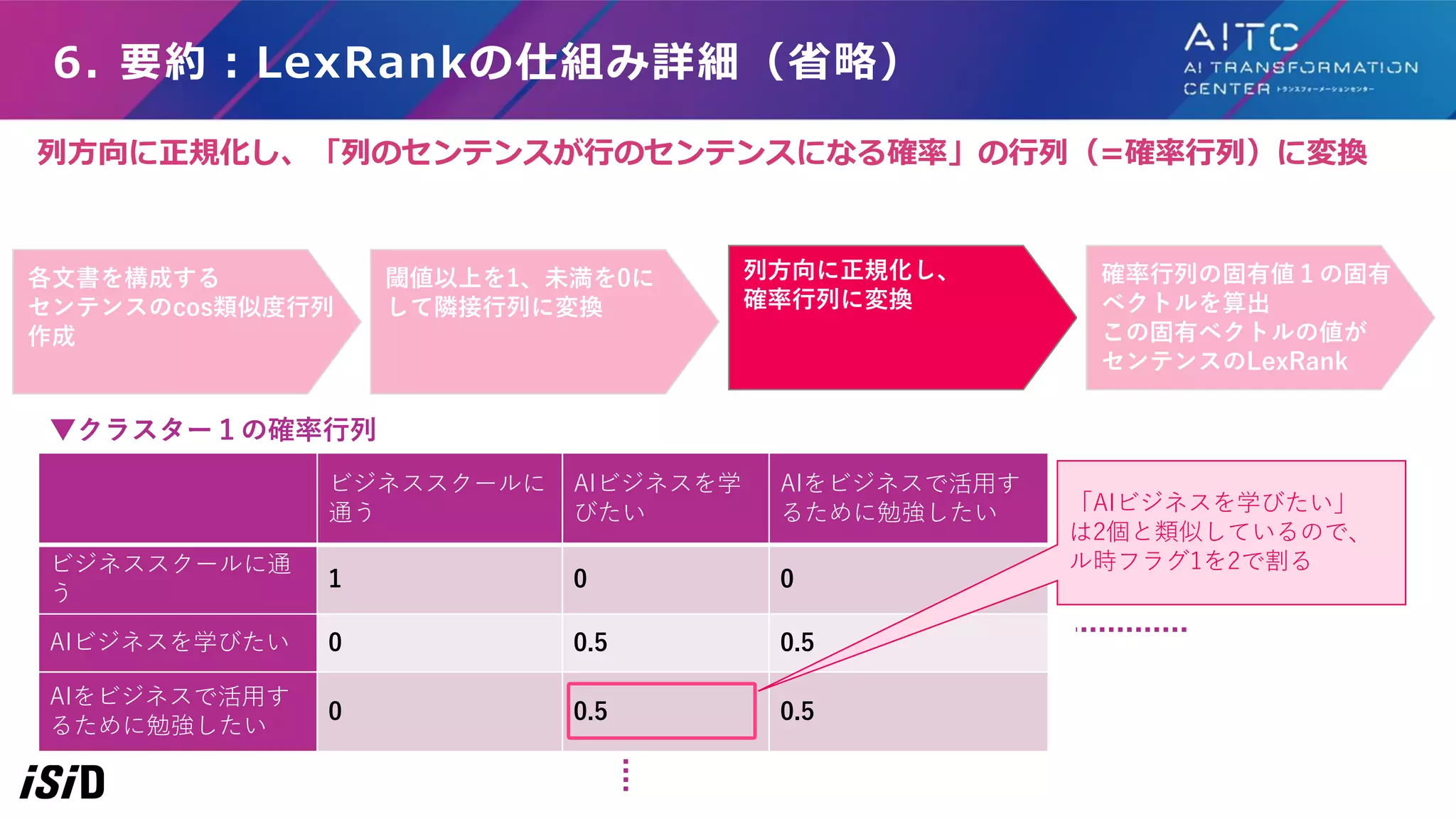
6. 要約:LexRankの仕組み詳細(省略) ▼クラスター1の確率行列 各文書を構成する センテンスのcos類似度行列 作成 閾値以上を1、未満を0に して隣接行列に変換 列方向に正規化し、 確率行列に変換 ビジネススクールに 通う AIビジネスを学 びたい AIをビジネスで活用す るために勉強したい ビジネススクールに通 う 1 0
0 AIビジネスを学びたい 0 0.5 0.5 AIをビジネスで活用す るために勉強したい 0 0.5 0.5 確率行列の固有値1の固有 ベクトルを算出 この固有ベクトルの値が センテンスのLexRank 「AIビジネスを学びたい」 は2個と類似しているので、 ル時フラグ1を2で割る 列方向に正規化し、「列のセンテンスが行のセンテンスになる確率」の行列(=確率行列)に変換
54.
6. 要約:LexRankの仕組み詳細(省略) LexRank ビジネススクールに通 う 0.2 AIビジネスを学びたい 0.3 AIをビジネスで活用す るために勉強したい 0.4 ▼確率行列の固有ベクトル この固有ベクトルの値が 「LexRank」に相当する 各文書を構成する センテンスのcos類似度行列 作成 閾値以上を1、未満を0に して隣接行列に変換 列方向に正規化し、 確率行列に変換 確率行列の固有値1の固有 ベクトルを算出 この固有ベクトルの値が センテンスのLexRank https://qiita.com/sugulu/items/960116ec90b54bf924d7 「確率行列をいくらかけても変わらない、センテンス固有の重要さ」 (=固有値1の固有ベクトル)を算出
55.
まとめ
56.
まとめ ●「AI」と聞くと、【自動化・人間の代替】のイメージが強いですが、今回の取り組みは「人間協調 型AI」です。 ●アンケートのフリーコメントを機械学習&ディープラーニングで、ある程度まで自動でクラスタリ ングと要約してくれることで、人がフリーコメントなどの大量文書の全体像を理解しやすくしました ●(反省)途中までtf-idfで作っていて、最後にALBERTに変えたので「重要単語の検出」が、tf-idf ベースのままであった。この点がALBERTでのクラスタリング結果の要約文の質を下げていた(よう に感じる) ●「重要単語の検出」もALBERTベースにすることで、さらに性能が上がり、様々な文書・テキスト 情報を扱う際の協調型AIを構築することができると期待される
57.
付録:最近の私たちのAI関連の発表スライド等
58.
付録:最近の私たちのAI関連の発表スライド [1] NLP ソリューション開発の最前線,
DLLAB 自然言語処理ナイト, 20年7月. [2] SIerで自然言語処理AI製品をアジャイル開発した際の試行錯誤, Machine Learning 15minutes!, 20年7月. https://www.slideshare.net/DeepLearningLab/nlp-236520444 https://drive.google.com/file/d/1xT_o7YbfLWfSBrjSw4l3- h2uAolS9jPe/view?fbclid=IwAR3SlNzvg1kCVYZpD7IFOiBkoy9kz9RmDIkIbFGyCPw43ZpuNCCnuuaJMLM
59.
付録:最近の私たちのAI関連の発表スライド [3] OSS プロジェクトの
Issue 議論内容に対する BERT および AutoML を用いた文章分類の提案, 山田, 櫨山, 小川, 人工知能学会 2020@熊本, 20年6月. [4] 進化するSIerの最前線!電通国際情報サービス(ISID)が先端技術の活用事例を紹介【AI編】, 芝田, 小川, 19年12月. https://confit.atlas.jp/guide/event/jsai2020/subject/3Rin4-08/advanced https://techplay.jp/column/910?fbclid=IwAR3Di0Wad0y2sjjnlyZHlUaa_mHzC9Cf0aSaBY6MwE_ll8tMH9rsORo7E3k https://techplay.jp/eventreport/758740
60.
付録:最近の私たちのAI関連の発表スライド [5] BlackBox モデルの説明性・解釈性技術の実装,
DLLAB_interpretabilityNight, 19年10月. [6] 電通国際情報サービスAIトランスフォーメーションセンター, 20年2月設立. https://www.slideshare.net/DeepLearningLab/blackbox-198324328 https://isid-ai.jp/
61.
CONFIDENTIAL 【お問い合わせ先】 • 株式会社 電通国際情報サービス •
X(クロス)イノベーション本部 AIテクノロジー部 • E-mail:g-isid-ai@group.isid.co.jp
Download
![DEEP LEARNING Digital Conference
20年8月1日 15:20-15:45
AI・ディープラーニングを駆使して、
「G検定合格者アンケートのフリーコメント欄」
を分析してみた
株式会社電通国際情報サービス
X(クロス)イノベーション本部 AIテクノロジー部
兼 CDLEメンバ
小川 雄太郎、御手洗拓真
[※本スライドは後ほど公開]](https://image.slidesharecdn.com/43dllab20200801isid-200807101606/75/Track4-3-AI-G-1-2048.jpg)






![アンケート分析の概要
人手でのフリーコメントの解析フロー
[1] 全コメントを読みながら、似たような内容の文章を次々とグルーピング(クラスタリング)する
[2] クラスタ内容を代表するキーワードを抽出
[3] クラスタ内容の要約文章を作成
[4] ちなみに、今回使用したデータは以下のような感じです
・・・
250件超。。。(大変、自然言語処理・機械学習技術でどうにかしたいというモチベーション)](https://image.slidesharecdn.com/43dllab20200801isid-200807101606/75/Track4-3-AI-G-9-2048.jpg)







![2. 文書の特徴量作成:TF-IDFの仕組み①
TF-IDF
PCA
UMAP
ベクト
ル化
次元
圧縮
No. 単語
1 AI,ビジネス, 勉強
2 AI, ビジネス, 活用
3 AI, 勉強
No AI ビジネス 勉強 活用
1 -0.1 0 0 0
2 -0.1 0 0 0.12
3 -0.15 0 0 0
No. [AI,ビジネス,勉強,活用]
1 [ -0.1, 0 , 0, 0]
2 [-0.1, 0, 0.12 ]
3 [-0.15, 0, 0,0]
TF-IDF は、 単語の重要度スコア
▼形態素解析 ▼TF-IDFでベクトル化
イメージは、「重要な単語はポイントを高く」
「そうでもない単語はポイント低く」して文章をベクトル化
ALBERT](https://image.slidesharecdn.com/43dllab20200801isid-200807101606/75/Track4-3-AI-G-26-2048.jpg)














![付録:最近の私たちのAI関連の発表スライド
[1] NLP ソリューション開発の最前線, DLLAB 自然言語処理ナイト, 20年7月.
[2] SIerで自然言語処理AI製品をアジャイル開発した際の試行錯誤, Machine Learning 15minutes!, 20年7月.
https://www.slideshare.net/DeepLearningLab/nlp-236520444
https://drive.google.com/file/d/1xT_o7YbfLWfSBrjSw4l3-
h2uAolS9jPe/view?fbclid=IwAR3SlNzvg1kCVYZpD7IFOiBkoy9kz9RmDIkIbFGyCPw43ZpuNCCnuuaJMLM](https://image.slidesharecdn.com/43dllab20200801isid-200807101606/75/Track4-3-AI-G-58-2048.jpg)
![付録:最近の私たちのAI関連の発表スライド
[3] OSS プロジェクトの Issue 議論内容に対する BERT および AutoML を用いた文章分類の提案, 山田, 櫨山,
小川, 人工知能学会 2020@熊本, 20年6月.
[4] 進化するSIerの最前線!電通国際情報サービス(ISID)が先端技術の活用事例を紹介【AI編】, 芝田, 小川,
19年12月.
https://confit.atlas.jp/guide/event/jsai2020/subject/3Rin4-08/advanced
https://techplay.jp/column/910?fbclid=IwAR3Di0Wad0y2sjjnlyZHlUaa_mHzC9Cf0aSaBY6MwE_ll8tMH9rsORo7E3k
https://techplay.jp/eventreport/758740](https://image.slidesharecdn.com/43dllab20200801isid-200807101606/75/Track4-3-AI-G-59-2048.jpg)
![付録:最近の私たちのAI関連の発表スライド
[5] BlackBox モデルの説明性・解釈性技術の実装, DLLAB_interpretabilityNight, 19年10月.
[6] 電通国際情報サービスAIトランスフォーメーションセンター, 20年2月設立.
https://www.slideshare.net/DeepLearningLab/blackbox-198324328
https://isid-ai.jp/](https://image.slidesharecdn.com/43dllab20200801isid-200807101606/75/Track4-3-AI-G-60-2048.jpg)


























![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[Track3-2] AI活用人材の社内育成に関する取り組みについて ~ダイキン情報技術大学~](https://cdn.slidesharecdn.com/ss_thumbnails/3-2dllabconferencedaikinisid2020-07-20-2-200819034039-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Track1-2] ディープラーニングを用いたワインブドウの収穫量予測](https://cdn.slidesharecdn.com/ss_thumbnails/dldc20200801nssoltokutake-200819025900-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Track1-1] AIの売上予測を発注システムに組み込んだリンガーハットのデータ活用戦略](https://cdn.slidesharecdn.com/ss_thumbnails/datumstudiomitsuda-200819031400-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Track3-4] アカデミックにおけるAI/ディープラーニング の教育と学習支援に関する研究](https://cdn.slidesharecdn.com/ss_thumbnails/20200731dldcyamashita-200817042234-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Track 4-6] ディープラーニングxものづくりが日本を強くする ~高専DCONの挑戦~](https://cdn.slidesharecdn.com/ss_thumbnails/integraixdllpdf-200819065852-thumbnail.jpg?width=640&height=640&fit=bounds)








