Download as PDF, PPTX

![Access Patterns for Robots and Humans in Web Archives 2
0.204.48.255 - - [02/Feb/2012:06:57:19+0000] "GET http://wayback.archive.org/web/*/ahrefs.comHTTP/1.0"200 96037 "-" "Mozilla/5.0(Windows NT 6.1; rv:10.0) Gecko/20100101
Firefox/10.0"
0.241.150.135 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/*/hperlinknow.comHTTP/1.1"302 0 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:9.0.1)
Gecko/20100101Firefox/9.0.1"
0.227.253.171 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/20120202063732/http://b.scorecardresearch.com/beacon.jsHTTP/1.1"403 127
"http://liveweb.archive.org/http://www.modelmayhem.com/portfolio/pic/18225100""Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.7(KHTML, like Gecko) Chrome/16.0.912.77
Safari/535.7"
0.62.96.215 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/*/http://carbolicsmokeall.comHTTP/1.1"302 0 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US;
rv:1.9.2.26)Gecko/20120128BTRS87692Firefox/3.6.26( .NET CLR 3.5.30729; .NET4.0E)"
0.55.251.218 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/20020604064752fw_/http://www.airtrek.ne.jp/image/15_bar.gifHTTP/1.1"302 0
"http://web.archive.org/web/20020604064752fw_/http://www.airtrek.ne.jp/alltop.html""Mozilla/5.0(compatible;MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)"
0.123.255.46 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/20090321190441im_/http://www.chermside.com/wp-content/uploads/bowlsclub.gifHTTP/1.1"302 0
"http://web.archive.org/web/20090321190441/http://www.chermside.com/""Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.7(KHTML, like Gecko) Chrome/16.0.912.77Safari/535.7"
0.73.170.52 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/*/http://www.pornhub.comHTTP/1.1"302 0 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2)
AppleWebKit/534.51.22(KHTML, like Gecko) Version/5.1.1Safari/534.51.22"
0.172.74.45 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/20070122113841im_/http://www.newgrounds.com/layout04/newhf/bot_1.gifHTTP/1.1"302 0
"http://web.archive.org/web/20070122113841/http://www.newgrounds.com/portal/""Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11(KHTML, like Gecko)
Chrome/17.0.963.46Safari/535.11"
0.227.253.171 - - [02/Feb/2012:06:57:19+0000] "GET http://liveweb.archive.org/http://photos.modelmayhem.com/avatars/1/9/3/2/6/7/4f1e2fb2e4ed4_t.jpgHTTP/1.1"200 7682
"http://liveweb.archive.org/http://www.modelmayhem.com/portfolio/pic/18225100""Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.7(KHTML, like Gecko) Chrome/16.0.912.77
Safari/535.7"
0.172.74.45 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/20070122113841im_/http://www.newgrounds.com/layout04/newhf/sub_right.gifHTTP/1.1"302 0
"http://web.archive.org/web/20070122113841/http://www.newgrounds.com/portal/""Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11(KHTML, like Gecko)
Chrome/17.0.963.46Safari/535.11"
0.227.26.32 - - [02/Feb/2012:06:57:19+0000] "GET http://wayback.archive.org/web/*/http://www.friendscafe.orgHTTP/1.1"200 102279 "-" "Mozilla/5.0 (Windows NT 5.1; rv:9.0.1)
Gecko/20100101Firefox/9.0.1"
0.29.194.93 - - [02/Feb/2012:06:57:19+0000] "GET http://wayback.archive.org/web/*/http://tw.18dao.netHTTP/1.1"200 96951 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-TW;
rv:1.9.2.25)Gecko/20111212 AlexaToolbar/alxf-2.13Firefox/3.6.25( .NET CLR 3.5.30729)"
0.90.22.18 - - [02/Feb/2012:06:57:19+0000] "GET http://wayback.archive.org/web/*/http://www.bookingbug.comHTTP/1.1"200 104622 "-" "Mozilla/5.0 (Windows; U; Windows NT
6.1; en-US; rv:1.9.2.18)Gecko/20110614Firefox/3.6.18"
0.7.73.16 - - [02/Feb/2012:06:57:19+0000] "GET http://wayback.archive.orghttp://web.archive.org/web/20070930062203/http://profiles.yahoo.com/powertrip_02HTTP/1.1"302 0 "-"
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.2.15)Gecko/20110303Firefox/3.6.15& vbCrlfAccept:text/javascript,image/gif,image/x-xbitmap,image/jpeg,image/pjpeg,
application/x-shockwave-flash,application/vnd.ms-excel,applicati"
0.49.73.161 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/20061230183944im_/http://www.i3dthemes.com/_images/icons/rss_small.jpgHTTP/1.1"302 0 "-"
"Mozilla/5.0"
…](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-2-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives 3
0.204.48.255 - - [02/Feb/2012:06:57:19+0000] "GET http://wayback.archive.org/web/*/ahrefs.comHTTP/1.0"200 96037 "-" "Mozilla/5.0(Windows NT 6.1; rv:10.0) Gecko/20100101
Firefox/10.0"
0.241.150.135 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/*/hperlinknow.comHTTP/1.1"302 0 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:9.0.1)
Gecko/20100101Firefox/9.0.1"
0.227.253.171 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/20120202063732/http://b.scorecardresearch.com/beacon.jsHTTP/1.1"403 127
"http://liveweb.archive.org/http://www.modelmayhem.com/portfolio/pic/18225100""Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.7(KHTML, like Gecko) Chrome/16.0.912.77
Safari/535.7"
0.62.96.215 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/*/http://carbolicsmokeall.comHTTP/1.1"302 0 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US;
rv:1.9.2.26)Gecko/20120128BTRS87692Firefox/3.6.26( .NET CLR 3.5.30729; .NET4.0E)"
0.55.251.218 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/20020604064752fw_/http://www.airtrek.ne.jp/image/15_bar.gifHTTP/1.1"302 0
"http://web.archive.org/web/20020604064752fw_/http://www.airtrek.ne.jp/alltop.html""Mozilla/5.0(compatible;MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)"
0.123.255.46 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/20090321190441im_/http://www.chermside.com/wp-content/uploads/bowlsclub.gifHTTP/1.1"302 0
"http://web.archive.org/web/20090321190441/http://www.chermside.com/""Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.7(KHTML, like Gecko) Chrome/16.0.912.77Safari/535.7"
0.73.170.52 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/*/http://www.pornhub.comHTTP/1.1"302 0 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2)
AppleWebKit/534.51.22(KHTML, like Gecko) Version/5.1.1Safari/534.51.22"
0.172.74.45 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/20070122113841im_/http://www.newgrounds.com/layout04/newhf/bot_1.gifHTTP/1.1"302 0
"http://web.archive.org/web/20070122113841/http://www.newgrounds.com/portal/""Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11(KHTML, like Gecko)
Chrome/17.0.963.46Safari/535.11"
0.227.253.171 - - [02/Feb/2012:06:57:19+0000] "GET http://liveweb.archive.org/http://photos.modelmayhem.com/avatars/1/9/3/2/6/7/4f1e2fb2e4ed4_t.jpgHTTP/1.1"200 7682
"http://liveweb.archive.org/http://www.modelmayhem.com/portfolio/pic/18225100""Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.7(KHTML, like Gecko) Chrome/16.0.912.77
Safari/535.7"
0.172.74.45 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/20070122113841im_/http://www.newgrounds.com/layout04/newhf/sub_right.gifHTTP/1.1"302 0
"http://web.archive.org/web/20070122113841/http://www.newgrounds.com/portal/""Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11(KHTML, like Gecko)
Chrome/17.0.963.46Safari/535.11"
0.227.26.32 - - [02/Feb/2012:06:57:19+0000] "GET http://wayback.archive.org/web/*/http://www.friendscafe.orgHTTP/1.1"200 102279 "-" "Mozilla/5.0 (Windows NT 5.1; rv:9.0.1)
Gecko/20100101Firefox/9.0.1"
0.29.194.93 - - [02/Feb/2012:06:57:19+0000] "GET http://wayback.archive.org/web/*/http://tw.18dao.netHTTP/1.1"200 96951 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-TW;
rv:1.9.2.25)Gecko/20111212 AlexaToolbar/alxf-2.13Firefox/3.6.25( .NET CLR 3.5.30729)"
0.90.22.18 - - [02/Feb/2012:06:57:19+0000] "GET http://wayback.archive.org/web/*/http://www.bookingbug.comHTTP/1.1"200 104622 "-" "Mozilla/5.0 (Windows; U; Windows NT
6.1; en-US; rv:1.9.2.18)Gecko/20110614Firefox/3.6.18"
0.7.73.16 - - [02/Feb/2012:06:57:19+0000] "GET http://wayback.archive.orghttp://web.archive.org/web/20070930062203/http://profiles.yahoo.com/powertrip_02HTTP/1.1"302 0 "-"
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.2.15)Gecko/20110303Firefox/3.6.15& vbCrlfAccept:text/javascript,image/gif,image/x-xbitmap,image/jpeg,image/pjpeg,
application/x-shockwave-flash,application/vnd.ms-excel,applicati"
0.49.73.161 - - [02/Feb/2012:06:57:19+0000] "GET http://web.archive.org/web/20061230183944im_/http://www.i3dthemes.com/_images/icons/rss_small.jpgHTTP/1.1"302 0 "-"
"Mozilla/5.0"
…](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-3-2048.jpg)



![Access Patterns for Robots and Humans in Web Archives
Sample of Wayback Machine
access logs
7
0.247.222.86 - - [02/Feb/2012:07:03:46 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200
96433 "http://www.archive.org/web/web.php" "Mozilla/5.0 (Macintosh;
Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko)
Chrome/16.0.912.77 Safari/535.7"
0.247.222.86 - - [02/Feb/2012:07:03:55 +0000] "GET
http://web.archive.org/web/20130318135600/http://www.cnn.com HTTP/1.1"
200 18875 "http://wayback.archive.org/web/*/http://www.aura.vu"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8) AppleWebKit/535.7
(KHTML, like Gecko) Chrome/16.0.912.77 Safari/535.7"}](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-7-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Sample of Wayback Machine
access logs
8
0.247.222.86 - - [02/Feb/2012:07:03:46 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200
96433 "http://www.archive.org/web/web.php" "Mozilla/5.0 (Macintosh;
Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko)
Chrome/16.0.912.77 Safari/535.7"
• Client IP: 0.247.222.86](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-8-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Sample of Wayback Machine
access logs
9
0.247.222.86 - - [02/Feb/2012:07:03:46 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200
96433 "http://www.archive.org/web/web.php" "Mozilla/5.0 (Macintosh;
Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko)
Chrome/16.0.912.77 Safari/535.7"
• Client IP: 0.247.222.86
IPs had been anonymized by Internet Archive](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-9-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Sample of Wayback Machine
access logs
10
0.247.222.86 - - [02/Feb/2012:07:03:46 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200
96433 "http://www.archive.org/web/web.php" "Mozilla/5.0 (Macintosh;
Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko)
Chrome/16.0.912.77 Safari/535.7"
• Client IP: 0.247.222.86
• Access time: 02/Feb/2012:07:03:46 +0000](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-10-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Sample of Wayback Machine
access logs
11
0.247.222.86 - - [02/Feb/2012:07:03:46 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200
96433 "http://www.archive.org/web/web.php" "Mozilla/5.0 (Macintosh;
Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko)
Chrome/16.0.912.77 Safari/535.7"
• Client IP: 0.247.222.86
• Access time: 02/Feb/2012:07:03:46 +0000
• HTTP request method: GET](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-11-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Sample of Wayback Machine
access logs
12
0.247.222.86 - - [02/Feb/2012:07:03:46 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200
96433 "http://www.archive.org/web/web.php" "Mozilla/5.0 (Macintosh;
Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko)
Chrome/16.0.912.77 Safari/535.7"
• Client IP: 0.247.222.86
• Access time: 02/Feb/2012:07:03:46 +0000
• HTTP request method: GET
• URI: http://wayback.archive.org/web/*/http://www.cnn.com](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-12-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Sample of Wayback Machine
access logs
13
0.247.222.86 - - [02/Feb/2012:07:03:46 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200
96433 "http://www.archive.org/web/web.php" "Mozilla/5.0 (Macintosh;
Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko)
Chrome/16.0.912.77 Safari/535.7"
• Client IP: 0.247.222.86
• Access time: 02/Feb/2012:07:03:46 +0000
• HTTP request method: GET
• URI: http://wayback.archive.org/web/*/http://www.cnn.com
TimeMap](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-13-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Sample of Wayback Machine
access logs
14
0.247.222.86 - - [02/Feb/2012:07:03:46 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200
96433 "http://www.archive.org/web/web.php" "Mozilla/5.0 (Macintosh;
Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko)
Chrome/16.0.912.77 Safari/535.7"
• Client IP: 0.247.222.86
• Access time: 02/Feb/2012:07:03:46 +0000
• HTTP request method: GET
• URI: http://wayback.archive.org/web/20130318135600/http://www.cnn.com
0.247.222.86 - - [02/Feb/2012:07:03:55 +0000] "GET
http://web.archive.org/web/20130318135600/http://www.cnn.com/
HTTP/1.1" 200 18875
"http://wayback.archive.org/web/*/http://www.cnn.com"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8)
AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.77
Safari/535.7"} Memento
TimeMap](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-14-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Sample of Wayback Machine
access logs
15
0.247.222.86 - - [02/Feb/2012:07:03:46 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200
96433 "http://www.archive.org/web/web.php" "Mozilla/5.0 (Macintosh;
Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko)
Chrome/16.0.912.77 Safari/535.7"
• Client IP: 0.247.222.86
• Access time: 02/Feb/2012:07:03:46 +0000
• HTTP request method: GET
• URI: http://wayback.archive.org/web/*/http://www.cnn.com
• Protocol: HTTP/1.1](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-15-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Sample of Wayback Machine
access logs
16
0.247.222.86 - - [02/Feb/2012:07:03:46 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200
96433 "http://www.archive.org/web/web.php" "Mozilla/5.0 (Macintosh;
Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko)
Chrome/16.0.912.77 Safari/535.7"
• Client IP: 0.247.222.86
• Access time: 02/Feb/2012:07:03:46 +0000
• HTTP request method: GET
• URI: http://wayback.archive.org/web/*/http://www.cnn.com
• Protocol: HTTP/1.1
• HTTP status code: 200](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-16-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Sample of Wayback Machine
access logs
17
0.247.222.86 - - [02/Feb/2012:07:03:46 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200
96433 "http://www.archive.org/web/web.php" "Mozilla/5.0 (Macintosh;
Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko)
Chrome/16.0.912.77 Safari/535.7"
• Client IP: 0.247.222.86
• Access time: 02/Feb/2012:07:03:46 +0000
• HTTP request method: GET
• URI: http://wayback.archive.org/web/*/http://www.cnn.com
• Protocol: HTTP/1.1
• HTTP status code: 200
• Bytes sent: 96433](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-17-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Sample of Wayback Machine
access logs
18
0.247.222.86 - - [02/Feb/2012:07:03:46 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200
96433 "http://www.archive.org/web/web.php" "Mozilla/5.0 (Macintosh;
Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko)
Chrome/16.0.912.77 Safari/535.7"
• Client IP: 0.247.222.86
• Access time: 02/Feb/2012:07:03:46 +0000
• HTTP request method: GET
• URI: http://wayback.archive.org/web/*/http://www.cnn.com
• Protocol: HTTP/1.1
• HTTP status code: 200
• Bytes sent: 96433
• Referring URI: http://www.archive.org/web/web.php](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-18-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Sample of Wayback Machine
access logs
19
0.247.222.86 - - [02/Feb/2012:07:03:46 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200
96433 "http://www.archive.org/web/web.php" "Mozilla/5.0 (Macintosh;
Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko)
Chrome/16.0.912.77 Safari/535.7"
• Client IP: 0.247.222.86
• Access time: 02/Feb/2012:07:03:46 +0000
• HTTP request method: GET
• URI: http://wayback.archive.org/web/*/http://www.cnn.com
• Protocol: HTTP/1.1
• HTTP status code: 200
• Bytes sent: 96433
• Referring URI: http://www.archive.org/web/web.php
• User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8) AppleWebKit/535.7
(KHTML, like Gecko) Chrome/16.0.912.77 Safari/535.7](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-19-2048.jpg)


![Access Patterns for Robots and Humans in Web Archives
Data Cleaning
22
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308/http
://www.jcdl.org/ HTTP/1.1" 200 2137 "-"
"Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308im_/h
ttp://www.jcdl.org/images/jcdl2007-edie.jpg
HTTP/1.1" 200 2137 "-" "Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://staticweb.archive.org/images/toolbar/wa
yback-toolbar-logo.png HTTP/1.1" 200 3700 "–"
"Mozilla/5.0"
0.151.147.108 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20100102003557/abou
t:blank HTTP/1.1" 302 0 "www.xx.com"
"Mozilla/4.0"
0.26.129.146 - - [02/Feb/2012:00:01:54] "GET
http://web.archive.org/web/20140004100000/http
://www.jcdl.org/ HTTP/1.1" 302 0 "-"
"Mozilla/5.0"
http://web.archive.org/web/20070519015308/
http://www.jcdl.org/](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-22-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Embedded Resources
23
http://web.archive.org/web/20070519015308/
http://www.jcdl.org/
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308/http
://www.jcdl.org/ HTTP/1.1" 200 2137 "-"
"Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308im_/h
ttp://www.jcdl.org/images/jcdl2007-edie.jpg
HTTP/1.1" 200 2137 "-" "Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://staticweb.archive.org/images/toolbar/wa
yback-toolbar-logo.png HTTP/1.1" 200 3700 "–"
"Mozilla/5.0"
0.151.147.108 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20100102003557/abou
t:blank HTTP/1.1" 302 0 "www.xx.com"
"Mozilla/4.0"
0.26.129.146 - - [02/Feb/2012:00:01:54] "GET
http://web.archive.org/web/20140004100000/http
://www.jcdl.org/ HTTP/1.1" 302 0 "-"
"Mozilla/5.0"](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-23-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Embedded Resources
24
http://web.archive.org/web/20070519015308/
http://www.jcdl.org/
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308/http
://www.jcdl.org/ HTTP/1.1" 200 2137 "-"
"Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308im_/h
ttp://www.jcdl.org/images/jcdl2007-edie.jpg
HTTP/1.1" 200 2137 "-" "Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://staticweb.archive.org/images/toolbar/wa
yback-toolbar-logo.png HTTP/1.1" 200 3700 "–"
"Mozilla/5.0"
0.151.147.108 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20100102003557/abou
t:blank HTTP/1.1" 302 0 "www.xx.com"
"Mozilla/4.0"
0.26.129.146 - - [02/Feb/2012:00:01:54] "GET
http://web.archive.org/web/20140004100000/http
://www.jcdl.org/ HTTP/1.1" 302 0 "-"
"Mozilla/5.0"](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-24-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Static Resources
25
http://web.archive.org/web/20070519015308/
http://www.jcdl.org/
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308/http
://www.jcdl.org/ HTTP/1.1" 200 2137 "-"
"Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308im_/h
ttp://www.jcdl.org/images/jcdl2007-edie.jpg
HTTP/1.1" 200 2137 "-" "Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://staticweb.archive.org/images/toolbar/wa
yback-toolbar-logo.png HTTP/1.1" 200 3700 "–"
"Mozilla/5.0"
0.151.147.108 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20100102003557/abou
t:blank HTTP/1.1" 302 0 "www.xx.com"
"Mozilla/4.0"
0.26.129.146 - - [02/Feb/2012:00:01:54] "GET
http://web.archive.org/web/20140004100000/http
://www.jcdl.org/ HTTP/1.1" 302 0 "-"
"Mozilla/5.0"](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-25-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Static Resources
26
http://web.archive.org/web/20070519015308/
http://www.jcdl.org/
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308/http
://www.jcdl.org/ HTTP/1.1" 200 2137 "-"
"Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308im_/h
ttp://www.jcdl.org/images/jcdl2007-edie.jpg
HTTP/1.1" 200 2137 "-" "Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://staticweb.archive.org/images/toolbar/wa
yback-toolbar-logo.png HTTP/1.1" 200 3700 "–"
"Mozilla/5.0"
0.151.147.108 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20100102003557/abou
t:blank HTTP/1.1" 302 0 "www.xx.com"
"Mozilla/4.0"
0.26.129.146 - - [02/Feb/2012:00:01:54] "GET
http://web.archive.org/web/20140004100000/http
://www.jcdl.org/ HTTP/1.1" 302 0 "-"
"Mozilla/5.0"](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-26-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Invalid requests
27
http://web.archive.org/web/20100102003557/
about:blank
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308/http
://www.jcdl.org/ HTTP/1.1" 200 2137 "-"
"Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308im_/h
ttp://www.jcdl.org/images/jcdl2007-edie.jpg
HTTP/1.1" 200 2137 "-" "Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://staticweb.archive.org/images/toolbar/wa
yback-toolbar-logo.png HTTP/1.1" 200 3700 "–"
"Mozilla/5.0"
0.151.147.108 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20100102003557/abou
t:blank HTTP/1.1" 302 0 "www.xx.com"
"Mozilla/4.0"
0.26.129.146 - - [02/Feb/2012:00:01:54] "GET
http://web.archive.org/web/20140004100000/http
://www.jcdl.org/ HTTP/1.1" 302 0 "-"
"Mozilla/5.0"](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-27-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Invalid requests
28
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308/http
://www.jcdl.org/ HTTP/1.1" 200 2137 "-"
"Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308im_/h
ttp://www.jcdl.org/images/jcdl2007-edie.jpg
HTTP/1.1" 200 2137 "-" "Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://staticweb.archive.org/images/toolbar/wa
yback-toolbar-logo.png HTTP/1.1" 200 3700 "–"
"Mozilla/5.0"
0.151.147.108 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20100102003557/abou
t:blank HTTP/1.1" 302 0 "www.xx.com"
"Mozilla/4.0"
0.26.129.146 - - [02/Feb/2012:00:01:54] "GET
http://web.archive.org/web/20140004100000/http
://www.jcdl.org/ HTTP/1.1" 302 0 "-"
"Mozilla/5.0"
http://web.archive.org/web/20100102003557/
about:blank](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-28-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Requests that had 3xx status code
29
http://web.archive.org/web/20130114160045/
http://www.jcdl.org/0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308/http
://www.jcdl.org/ HTTP/1.1" 200 2137 "-"
"Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308im_/h
ttp://www.jcdl.org/images/jcdl2007-edie.jpg
HTTP/1.1" 200 2137 "-" "Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://staticweb.archive.org/images/toolbar/wa
yback-toolbar-logo.png HTTP/1.1" 200 3700 "–"
"Mozilla/5.0"
0.151.147.108 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20100102003557/abou
t:blank HTTP/1.1" 302 0 "www.xx.com"
"Mozilla/4.0"
0.26.129.146 - - [02/Feb/2012:00:01:54] "GET
http://web.archive.org/web/20140004100000/http
://www.jcdl.org/ HTTP/1.1" 302 0 "-"
"Mozilla/5.0"](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-29-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Requests that had 3xx status code
30
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308/http
://www.jcdl.org/ HTTP/1.1" 200 2137 "-"
"Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308im_/h
ttp://www.jcdl.org/images/jcdl2007-edie.jpg
HTTP/1.1" 200 2137 "-" "Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://staticweb.archive.org/images/toolbar/wa
yback-toolbar-logo.png HTTP/1.1" 200 3700 "–"
"Mozilla/5.0"
0.151.147.108 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20100102003557/abou
t:blank HTTP/1.1" 302 0 "www.xx.com"
"Mozilla/4.0"
0.26.129.146 - - [02/Feb/2012:00:01:54] "GET
http://web.archive.org/web/20140004100000/http
://www.jcdl.org/ HTTP/1.1" 302 0 "-"
"Mozilla/5.0"
http://web.archive.org/web/20130114160045/
http://www.jcdl.org/
curl -I "http://web.archive.org/web/20140004100000/http://www.jcdl.org/"
HTTP/1.1 302 Moved Temporarily
Server: Tengine/1.4.3
Date: Tue, 02 Jul 2013 19:48:59 GMT
Content-Type: application/octet-stream
Content-Length: 0
Connection: keep-alive
set-cookie: wayback_server=10; Domain=archive.org; Path=/; Expires=Thu, 01-Aug-13 19:48:59 GMT;
Location: /web/20130114160045/http://www.jcdl.org/](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-30-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
Requests that had 3xx status code
31
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308/http
://www.jcdl.org/ HTTP/1.1" 200 2137 "-"
"Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20070519015308im_/h
ttp://www.jcdl.org/images/jcdl2007-edie.jpg
HTTP/1.1" 200 2137 "-" "Mozilla/5.0"
0.11.160.135 [02/Feb/2012:00:01:03] "GET
http://staticweb.archive.org/images/toolbar/wa
yback-toolbar-logo.png HTTP/1.1" 200 3700 "–"
"Mozilla/5.0"
0.151.147.108 [02/Feb/2012:00:01:03] "GET
http://web.archive.org/web/20100102003557/abou
t:blank HTTP/1.1" 302 0 "www.xx.com"
"Mozilla/4.0"
0.26.129.146 - - [02/Feb/2012:00:01:54] "GET
http://web.archive.org/web/20140004100000/http
://www.jcdl.org/ HTTP/1.1" 302 0 "-"
"Mozilla/5.0"
http://web.archive.org/web/20130114160045/
http://www.jcdl.org/](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-31-2048.jpg)





![Access Patterns for Robots and Humans in Web Archives
User-Agent Check
0.182.141.149 - -
[02/Feb/2012:00:01:51 +0000] "GET
http://wayback.archive.org/web/199906
01000000*/http://www.belizefirst.com/
HTTP/1.0" 200 98507 "-"
"Python-urllib/1.17"
37](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-37-2048.jpg)
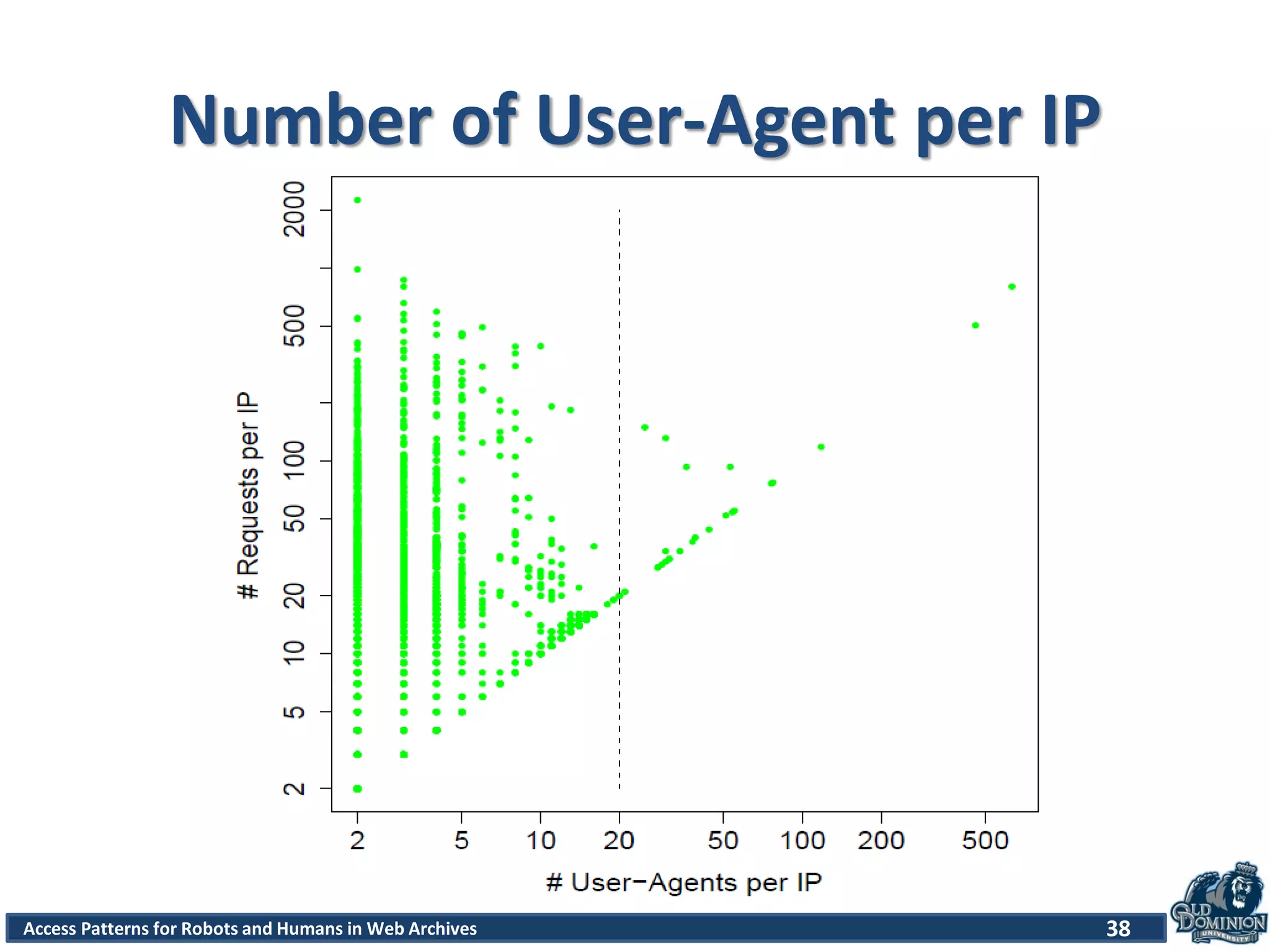
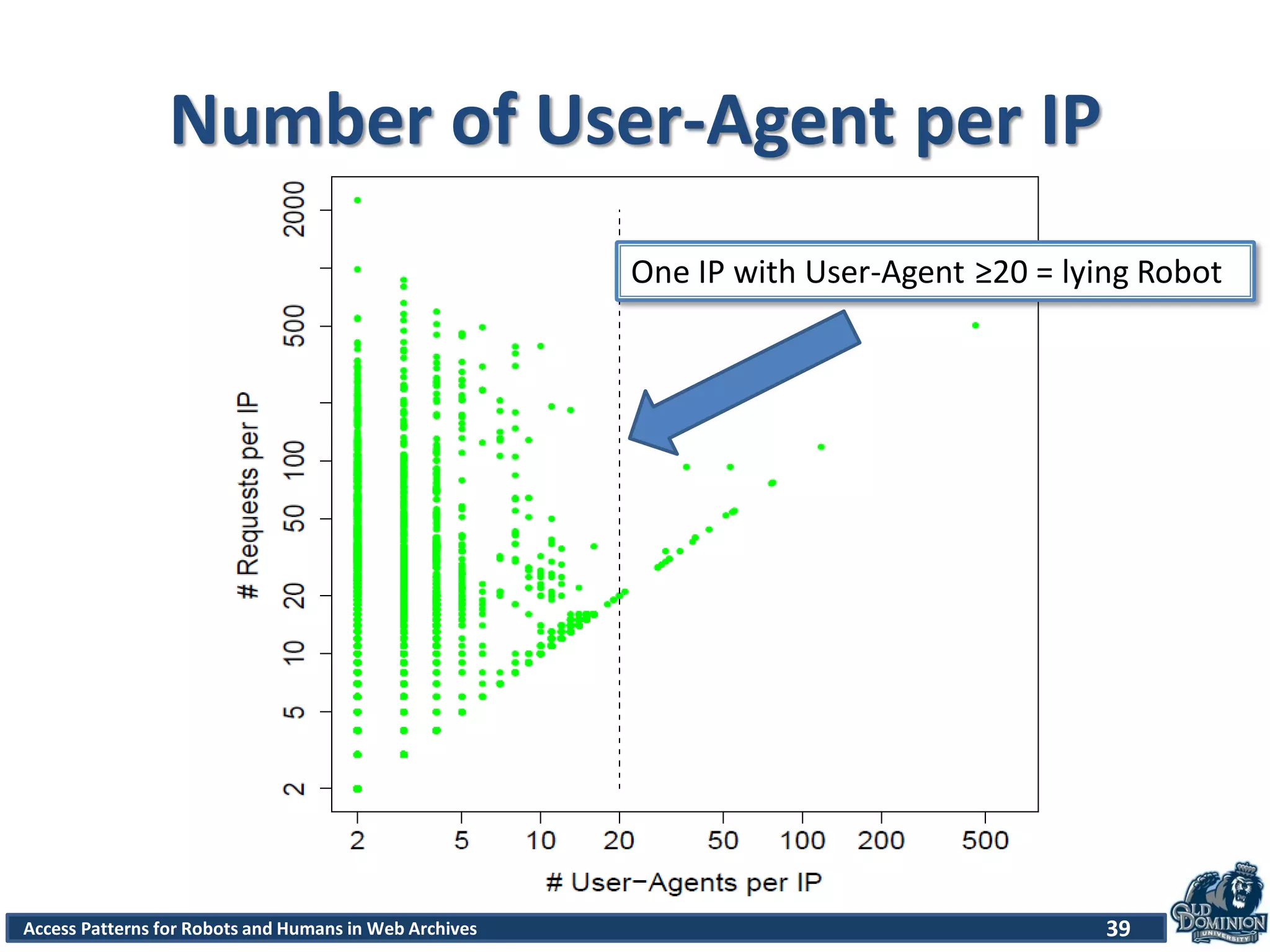
![Access Patterns for Robots and Humans in Web Archives
Robots.txt file
• Session that contains an access for robot.txt is
a robot
40
0.182.141.149 - - [02/Feb/2012:06:20:46 +0000] "GET
http://web.archive.org/robots.txt HTTP/1.0" 200 125 "-"
"Mozilla/5.0 (compatible; MJ12bot/v1.4.1;
http://www.majestic12.co.uk/bot.php?+)"
0.182.141.149 - - [02/Feb/2012:06:20:19 +0000] "GET
http://wayback.archive.org/web/*/http://www.devilscafe.in
HTTP/1.1" 404 2168 "-" "Mozilla/5.0 (compatible;
MJ12bot/v1.4.1; http://www.majestic12.co.uk/bot.php?+)"
0.182.141.149 - - [02/Feb/2012:06:21:19 +0000] "GET
http://wayback.archive.org/web/*/http://www.genie.co.il
HTTP/1.1" 200 96205 "-" "Mozilla/5.0 (compatible;
MJ12bot/v1.4.1; http://www.majestic12.co.uk/bot.php?+)"](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-40-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
6 requests, 2 seconds robot
41
0.182.141.149 - - [02/Feb/2012:07:00:01 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200 106433 “-"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8)
0.182.141.149 - - [02/Feb/2012:07:00:01 +0000] "GET
http://wayback.archive.org/web/*/http://www.bbc.com HTTP/1.1" 200 566433 "-"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8)
0.182.141.149 - - [02/Feb/2012:07:00:02 +0000] "GET
http://wayback.archive.org/web/*/http://www.google.com HTTP/1.1" 200 96433 "-"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8)
0.182.141.149 - - [02/Feb/2012:07:00:02 +0000] "GET
http://wayback.archive.org/web/*/http://www.yahoo.com HTTP/1.1" 200 933333 "-"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8)
0.182.141.149 - - [02/Feb/2012:07:00:02 +0000] "GET
http://wayback.archive.org/web/*/http://www.bing.com HTTP/1.1" 200 964333 “-"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8)
0.182.141.149 - - [02/Feb/2012:07:00:3 +0000] "GET
http://wayback.archive.org/web/*/http://www.jcdl.org HTTP/1.1" 200 123233 “-"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8)](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-41-2048.jpg)
![Access Patterns for Robots and Humans in Web Archives
3 requests, 520 seconds
(9 minutes) human
42
0.11.160.13 - - [02/Feb/2012:07:00:00 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200 106433 "-"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8)
0.11.160.13 - - [02/Feb/2012:07:03:46 +0000] "GET
http://wayback.archive.org/web/20100330042821/http://www.cnn.com HTTP/1.1" 200
566433 " http://wayback.archive.org/web/*/http://www.cnn.com" "Mozilla/5.0
(Macintosh; Intel Mac OS X 10_6_8)
0.11.160.13 - - [02/Feb/2012:07:08:00 +0000] "GET
http://wayback.archive.org/web/*/http://www.cnn.com HTTP/1.1" 200 96433 "
http://wayback.archive.org/web/*/http://www.cnn.com" "Mozilla/5.0 (Macintosh;
Intel Mac OS X 10_6_8)](https://image.slidesharecdn.com/logsppt-130725073716-phpapp02/75/Access-Patterns-for-Robots-and-Humans-in-Web-Archives-42-2048.jpg)

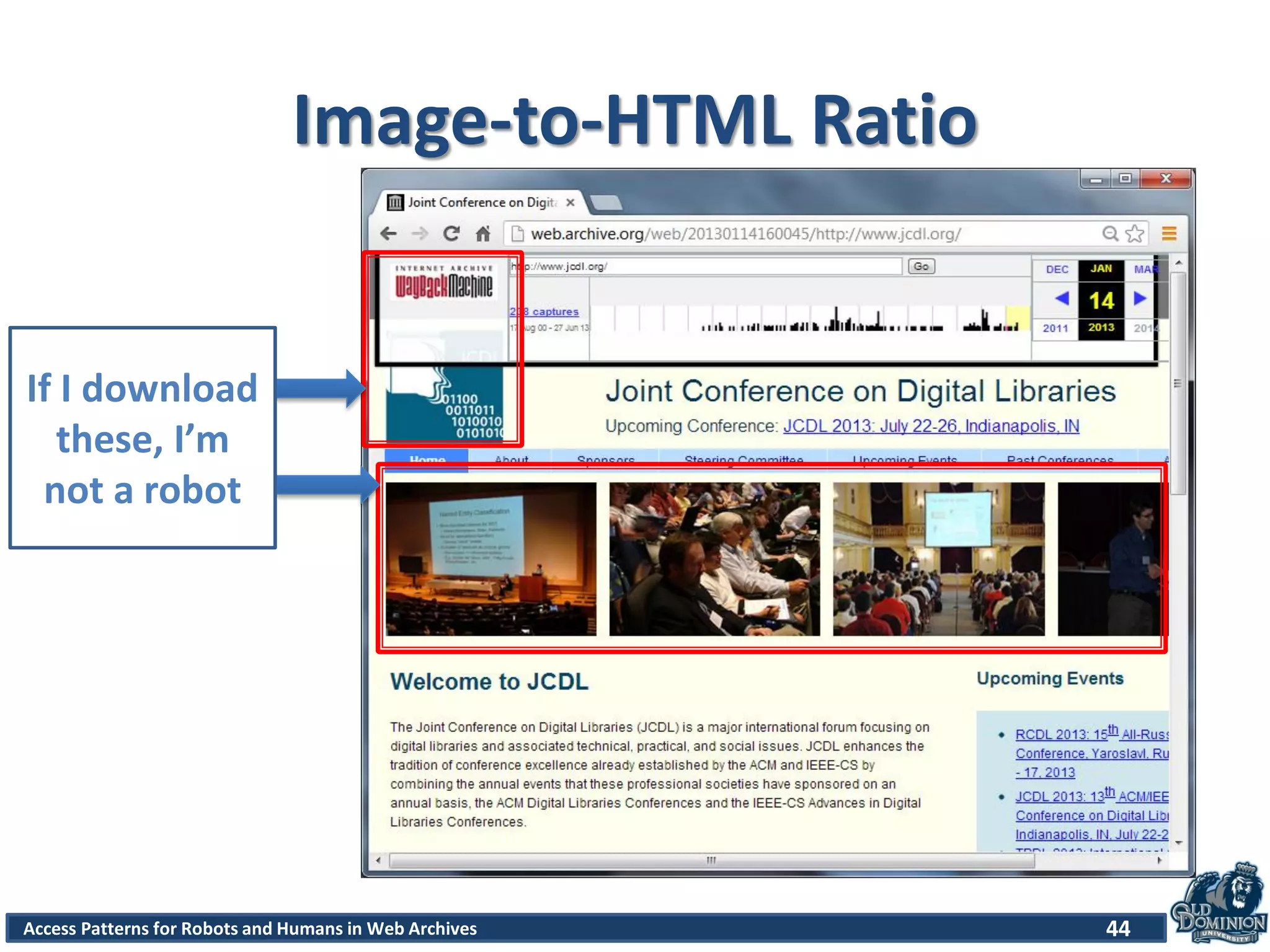



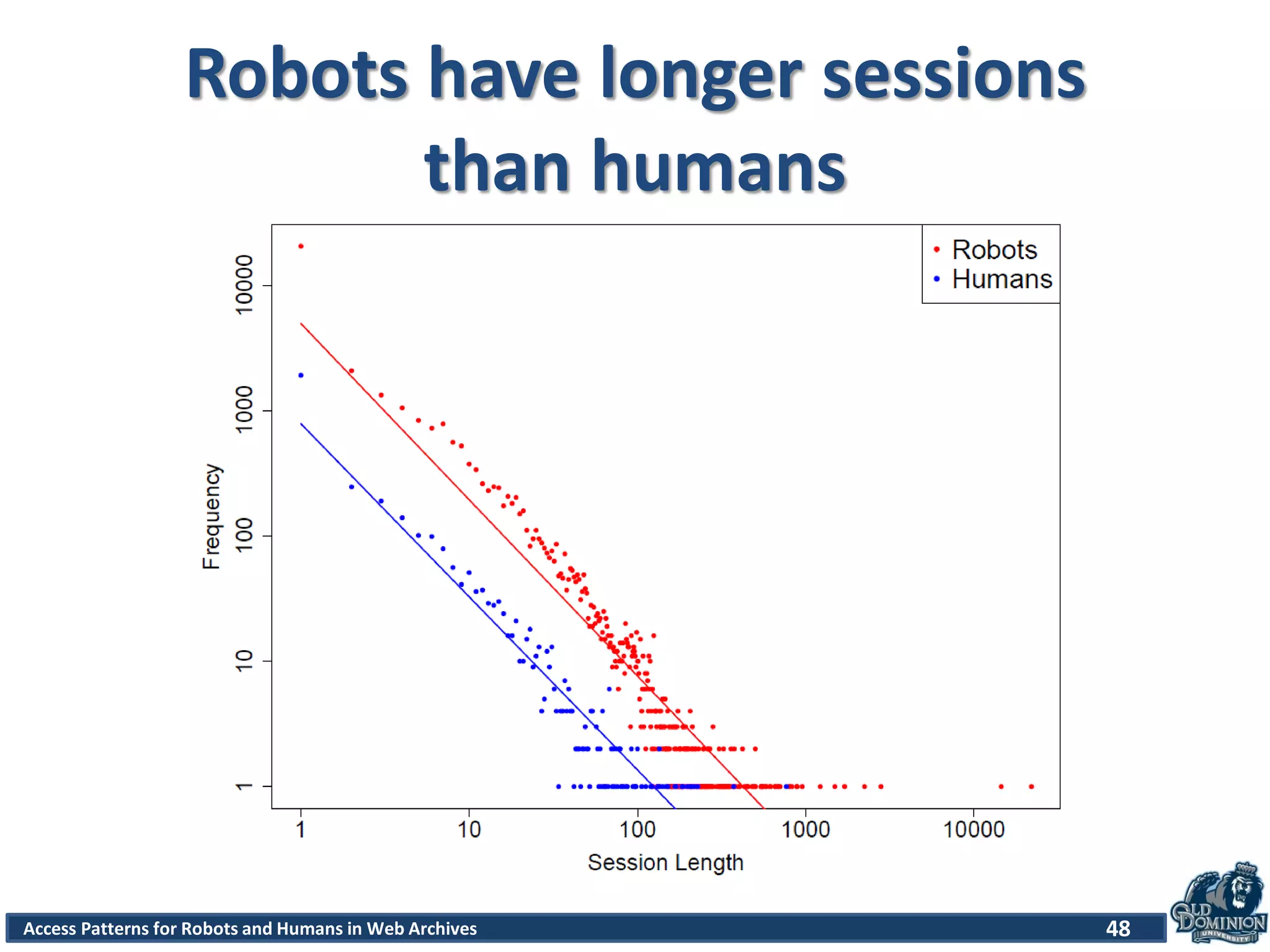
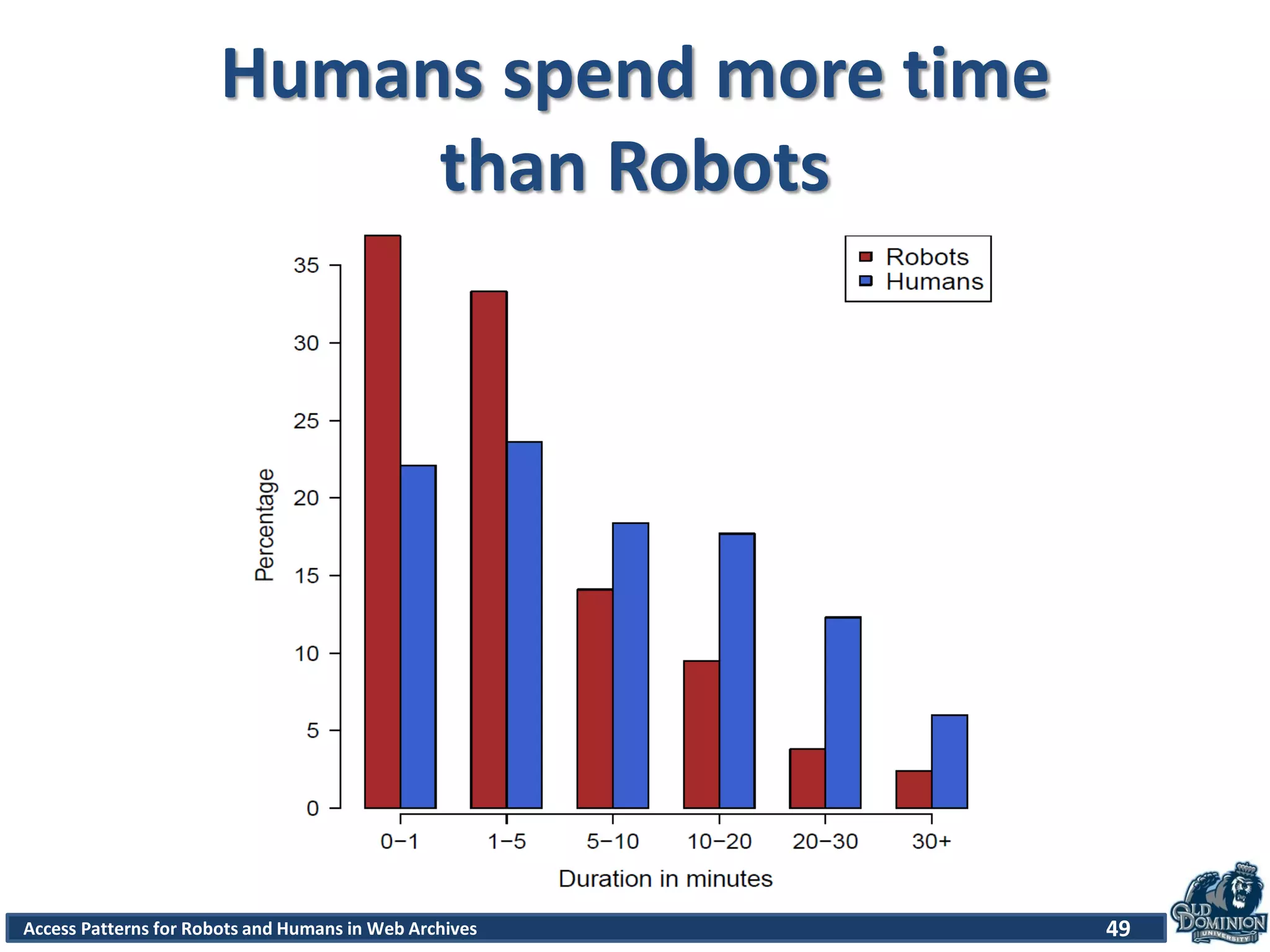




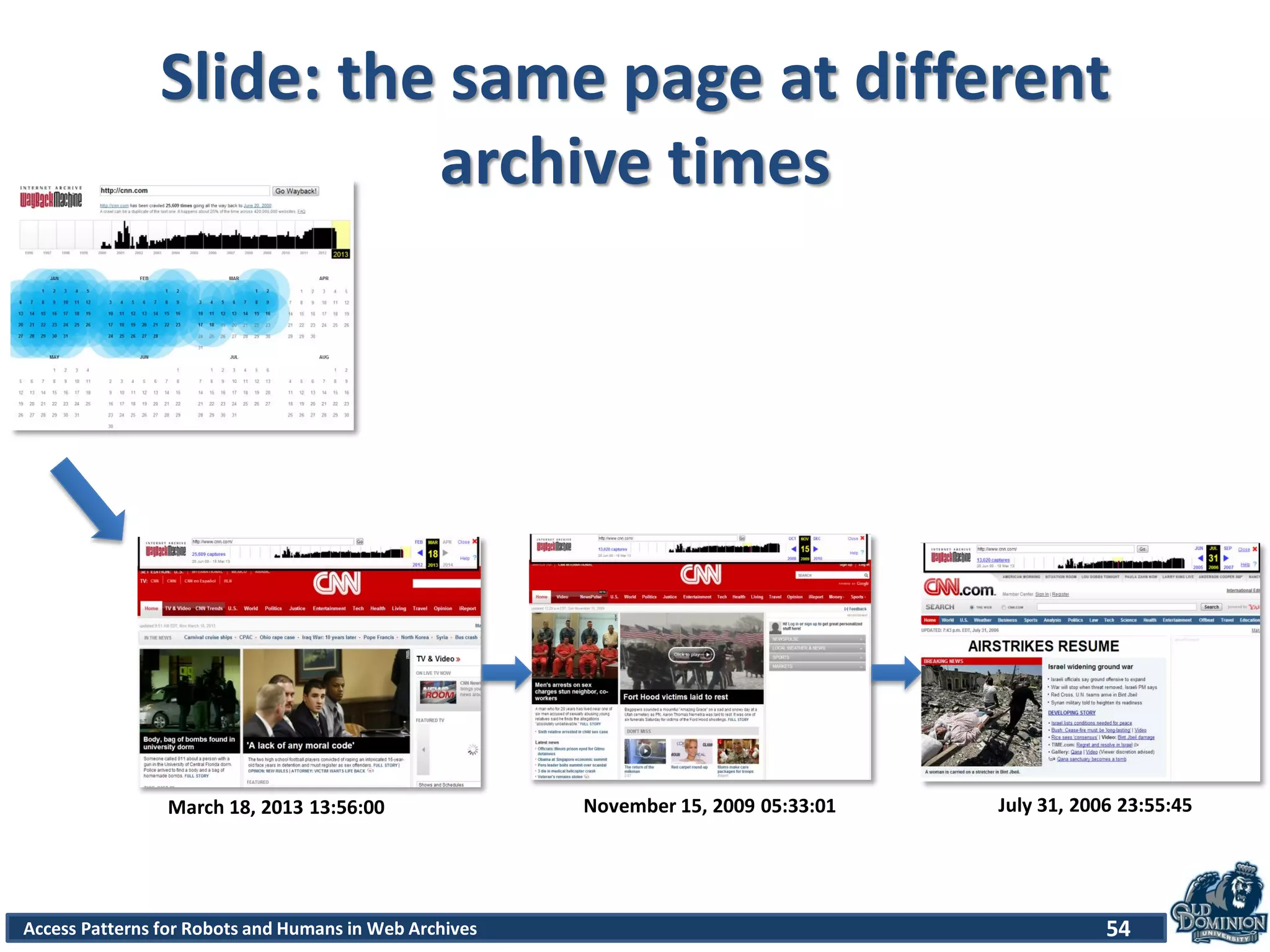

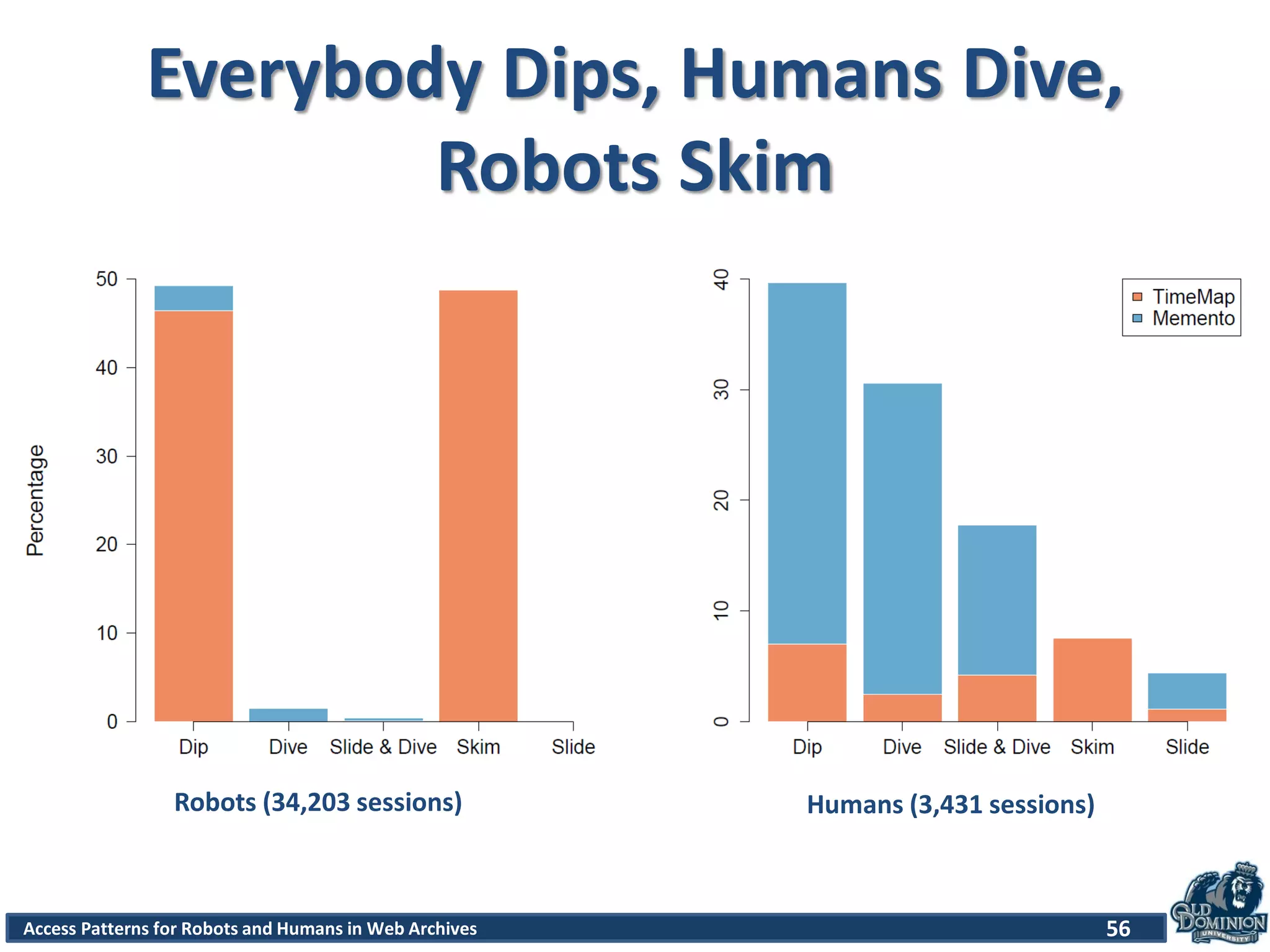
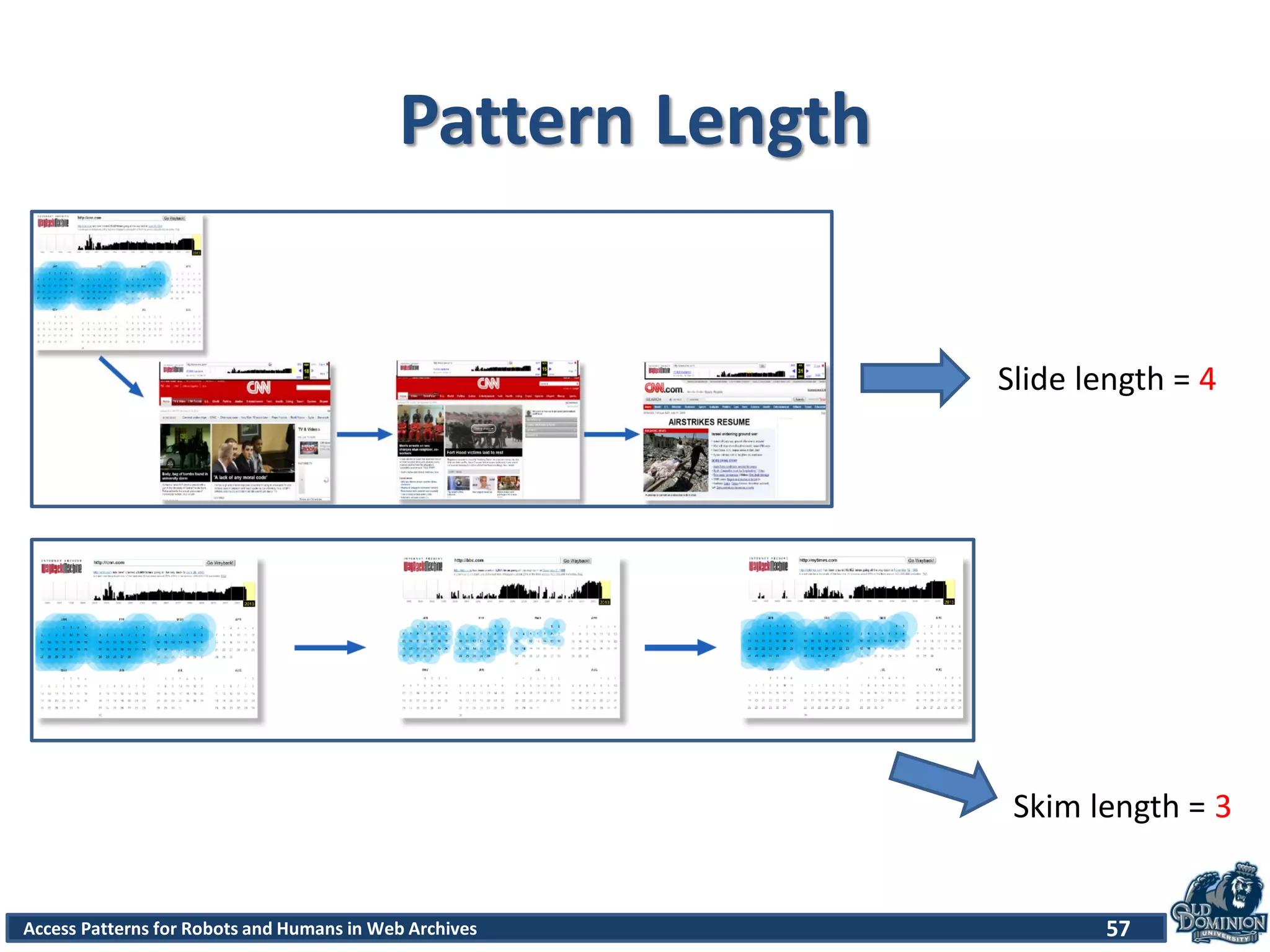





The document discusses a study of access patterns for robots and humans on web archive sites. It aims to analyze web server logs from the Internet Archive to understand how users access archived web pages. The study seeks to determine differences in how humans and robots/crawlers interact with web archives. The methodology section indicates the researchers analyzed sample logs from the Wayback Machine to classify requests and discover patterns.
















































































