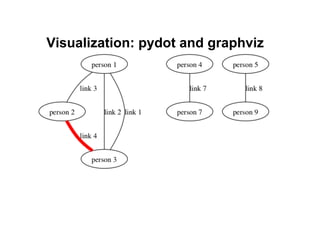
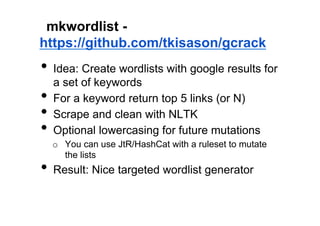
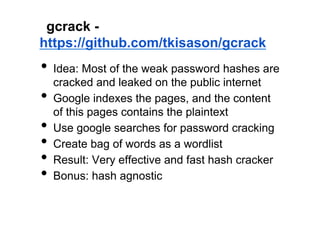
The document discusses leveraging publicly available internet data and open source intelligence (OSINT) for data analysis purposes. It describes how digitizing information creates opportunities to mine "big data" using techniques from fields like intelligence agencies. Specific tools and techniques are presented for OSINT, including using search engines to build wordlists and crack passwords. Examples of simple Python scripts and libraries for data analysis, visualization and crawling websites are also provided. The document encourages experimenting with publicly available data to gain insights and solve problems.