Peter van derGraaf
• 18 jaar SEO expert
• Opvolgend actief in branches waar SEO nog
het verschil kon maken
• Platforminrichting en Linkbuilding
• Bureau Booming
3.
Zoekmachines vs Spammers
•Altavista, Lycos, Hotbot en Yahoo
streden intensief tegen SEO spam:
Hoog scoren werd voornamelijk een kwestie van
het inzetten van steeds weer nieuwe trucs
• Google pakte dergelijke trucage het beste aan en
won daarmee het marktleiderschap
• Spammers worden steeds vernuftiger en een
statisch algoritme kan dit niet bijbenen
• Machine learning was nodig om onnatuurlijkheid
het hoofd te bieden
4.
Google richtlijnen
• Hetbeste antwoord voor de zoeker zou het
beste moeten scoren
• Manipulatie moet bestraft worden en in ieder
geval niet beloond
– Panda: Content moet toegevoegde waarde
hebben en uniek geschreven zijn
– Penguin: Links moeten als stem van vertrouwen
verdiend zijn
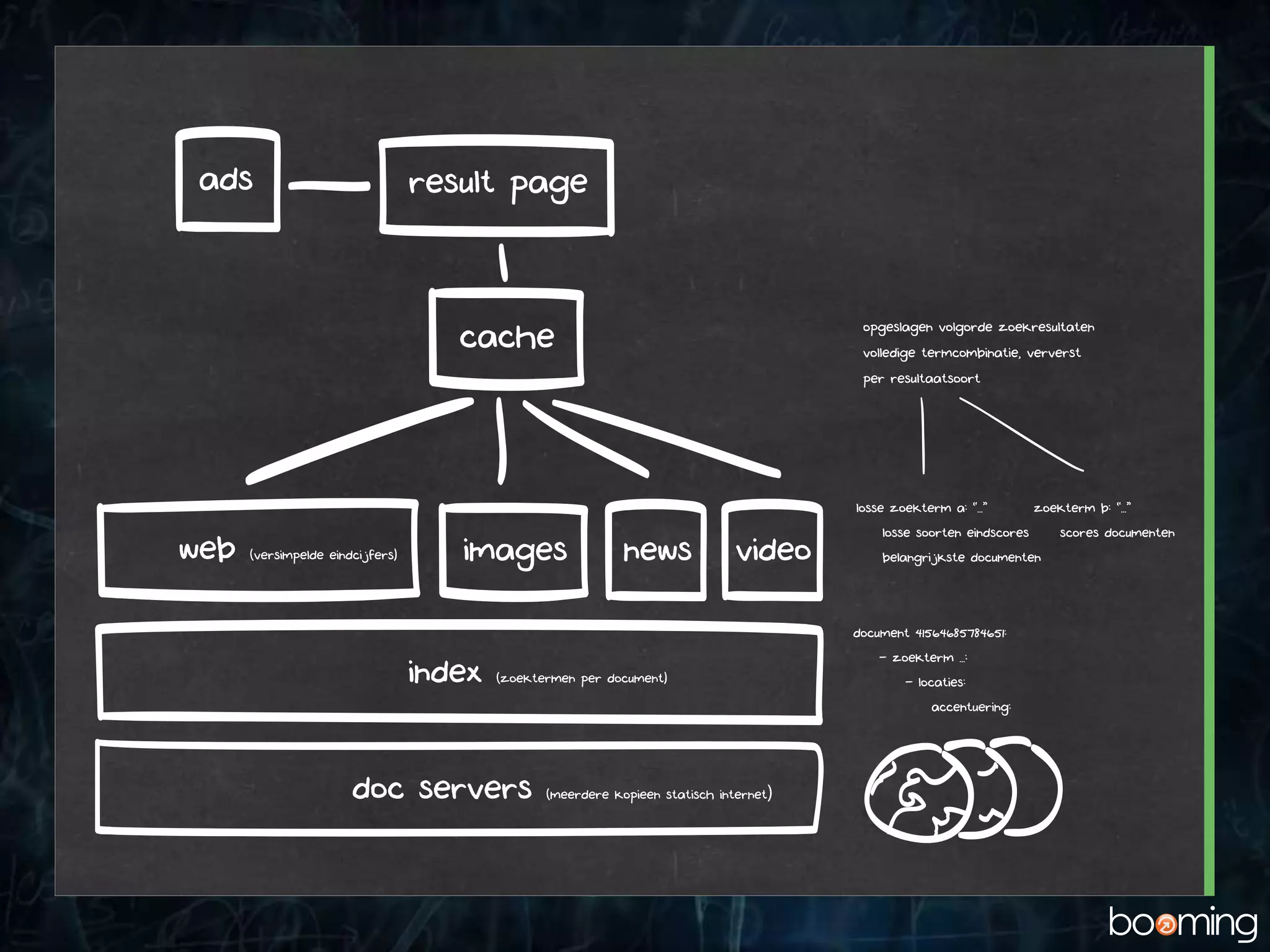
Hoe werkt Google?
1.Verzamelen van alle eigenschappen
2. Continu updaten externe eigenschappen
3. Versimpelen tot diverse eindcijfers
4. Verder versimpelen tot gecodeerde ranking factoren
5. Op volgorde zetten voor zoekopdracht (cache)
6. Filteren en herschikken op eigenschappen individu
7. Tonen resultaten
• Verversen kost rekenkracht
• Factoren toevoegen/vervangen erg moeilijk
• Waardering van factoren aanpassen is wel flexibel
Machine learning bijGoogle
• Welk patroon legt manipulatie bloot?
• Naar welke factoren mag het systeem kijken?
• Welk controlemiddel scheidt goed van slecht?
10.
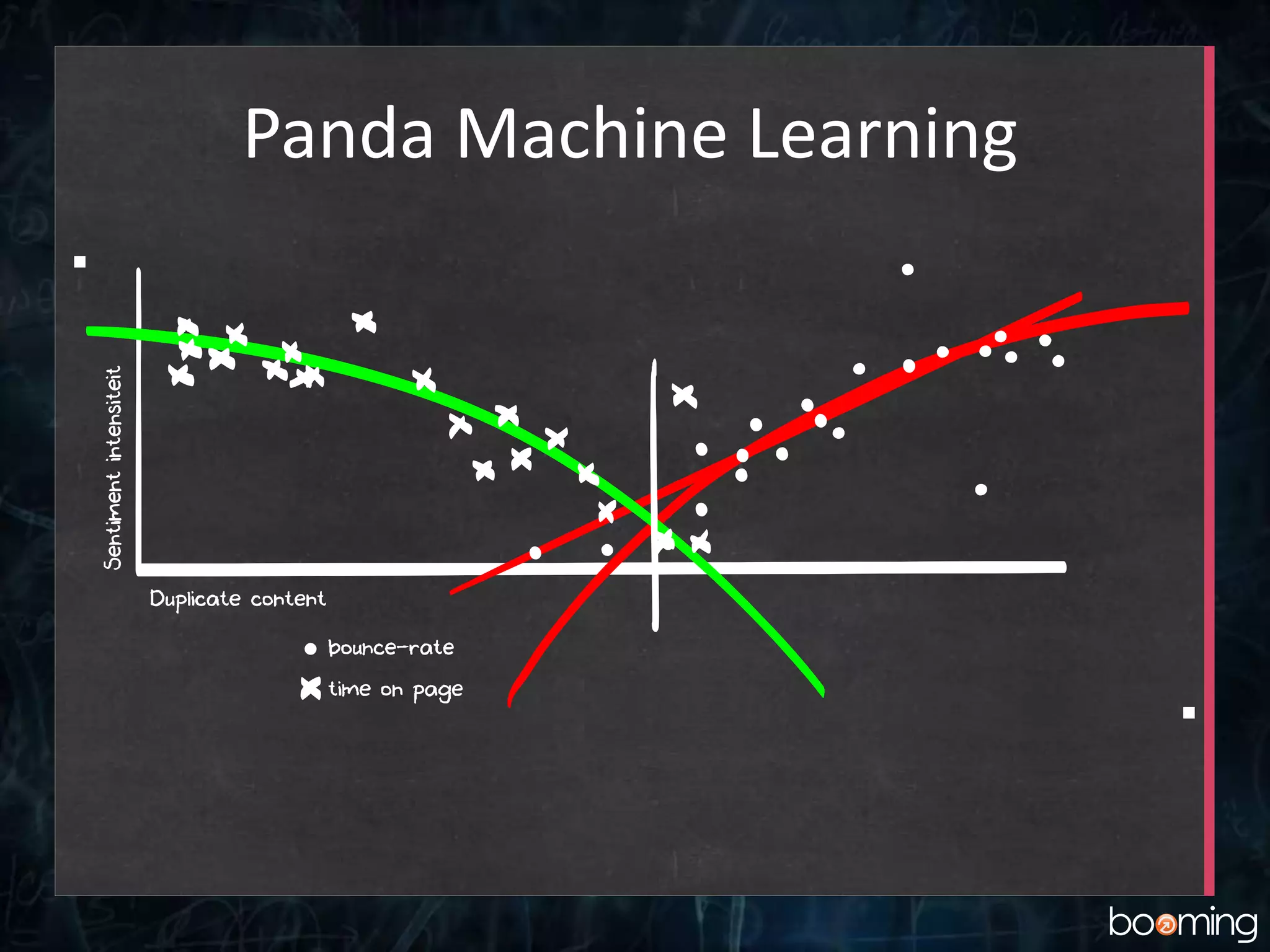
Panda
Communicatie vanuit Google(2011):
“De Panda-update heeft als doel het belonen van
kwaliteitscontent en het devalueren van sites met
geringe meerwaarde voor bezoekers.”
Officiële eigenschappen:
Geen spamdetectie, maar herevalutatie
kwaliteitsindicatoren.
Vernoemd naar Google (distributed tree learning)
engineer Biswanath Panda
Panda: Patronen
• Classificatieen regressie
over grote datasets
– Systeem bepaalt
classificatie op basis van
overeenkomstige
attributen
– Blijft opsplitsen tot te grote
diversiteit optreedt
– Uitgangspunt:
Voorspelbaarheid nieuwe
datasets door controleren
van slechts enkele
variabelen
13.
Initieel geen livealgoritme
• Op de achtergrond in statische dataset patronen
ontdekken
• Mensen bepalen eerste controlemiddelen
(meestal tekenen van goede of slechte gebruikerservaring)
• Mensen controleren voor false positives en negatives
voor het resultaat (reeksen controlepunten) live gezet wordt
• Met elke iteratie wordt het resultaat stabieler
• Zo stabiel dat Panda een Live algoritme kon worden
• Zogenaamde Panda Updates alleen nog nodig als het
learning systeem zelf aangepast wordt