Downloaded 133 times




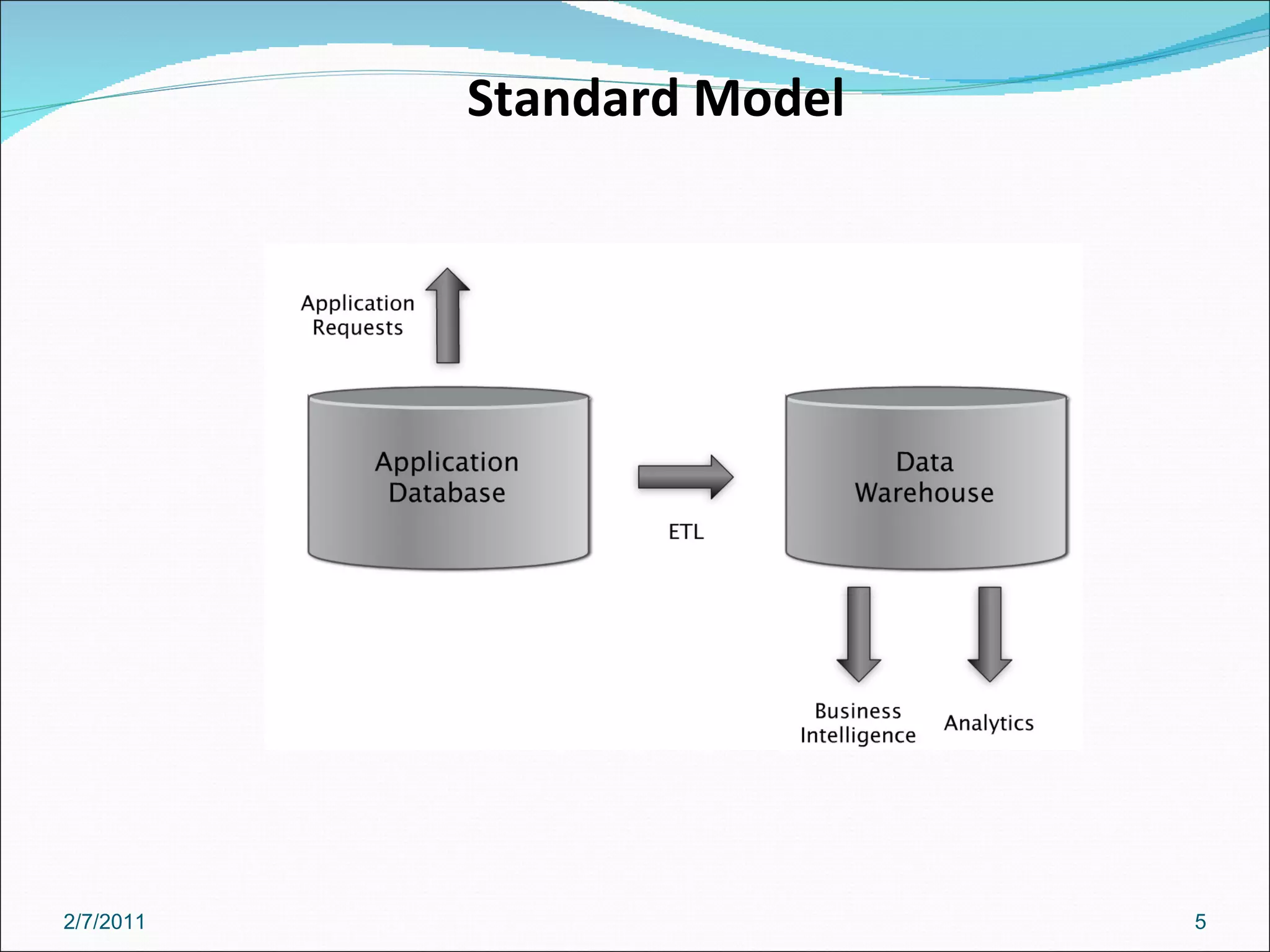
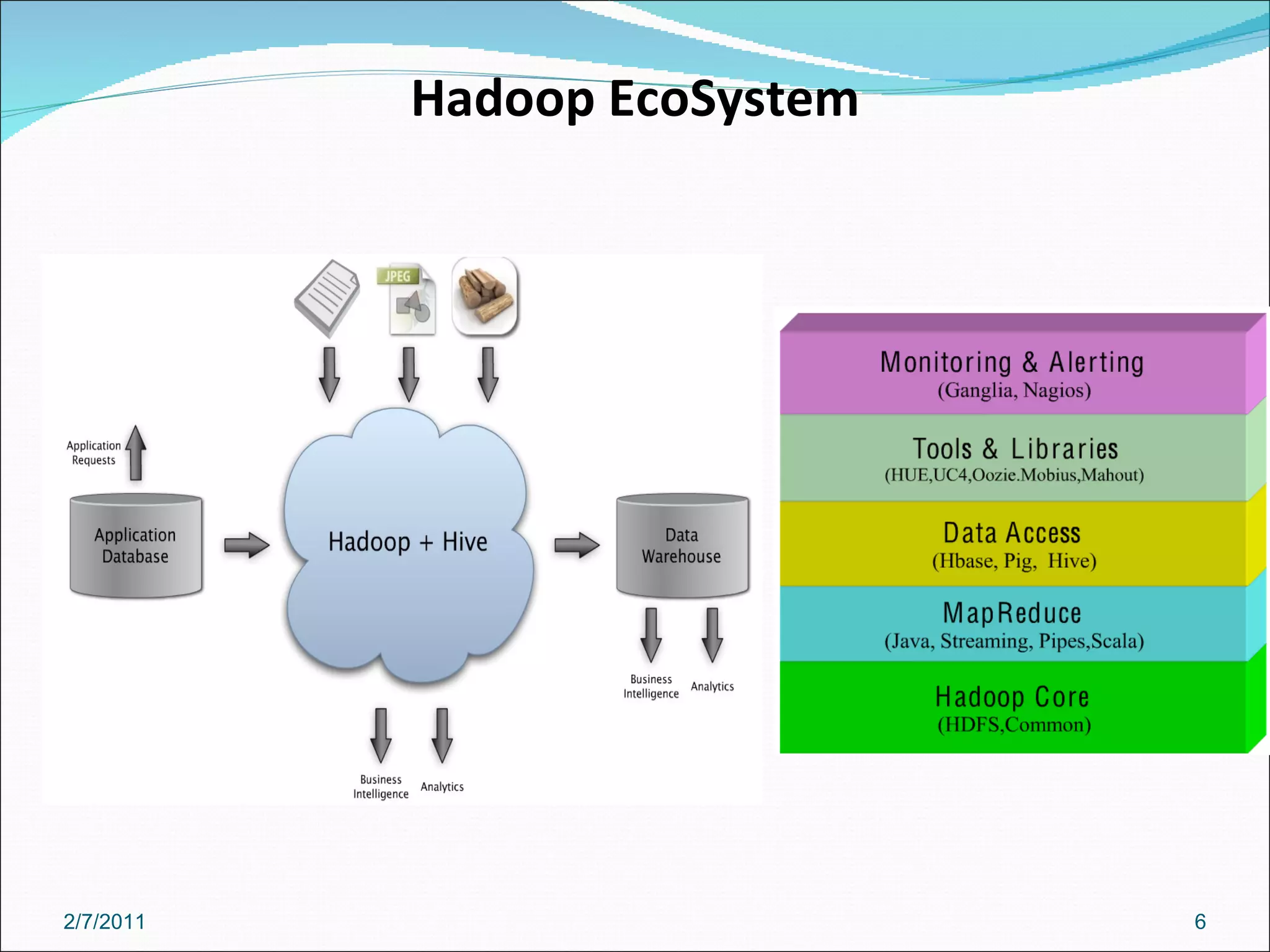




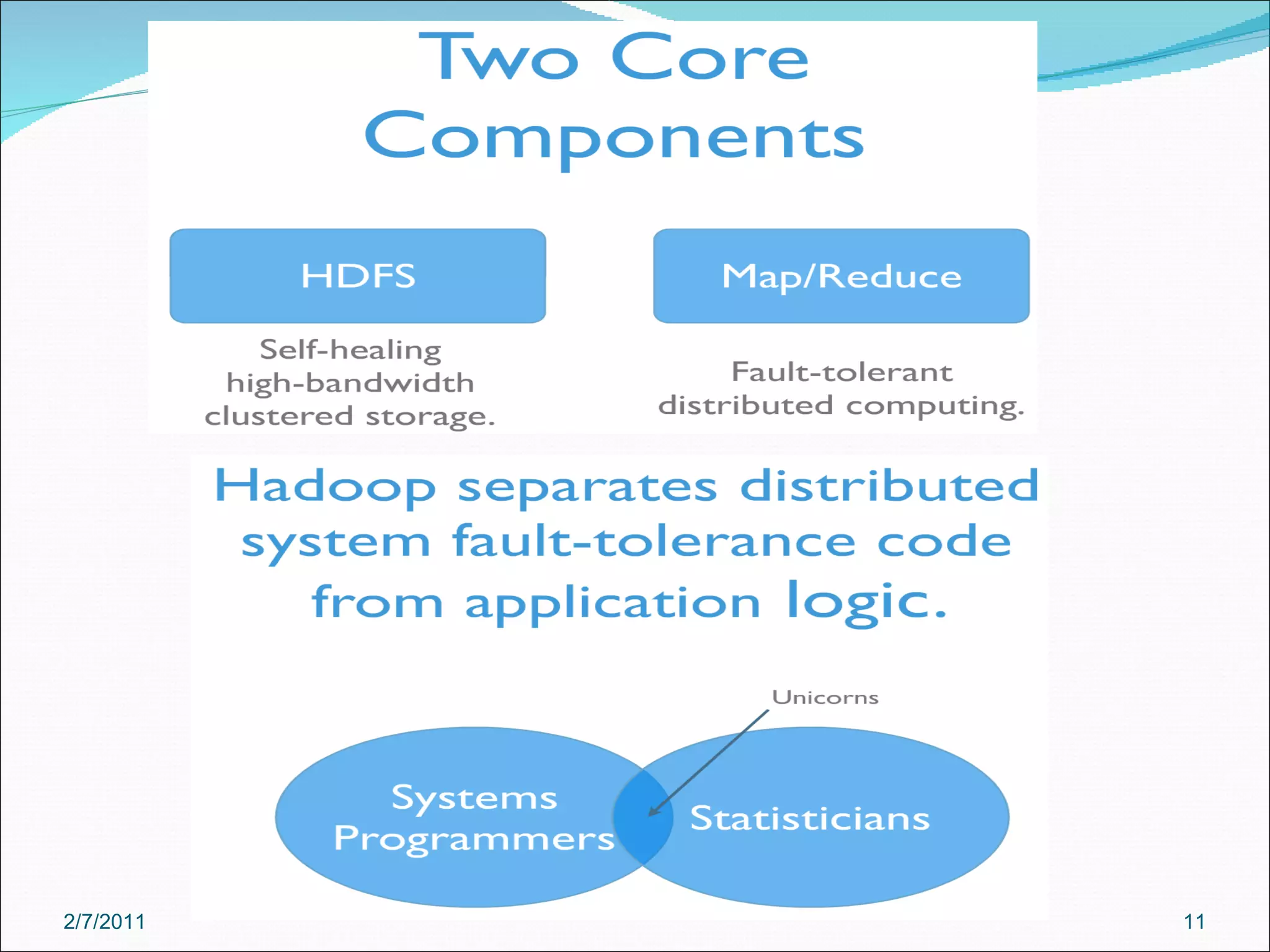


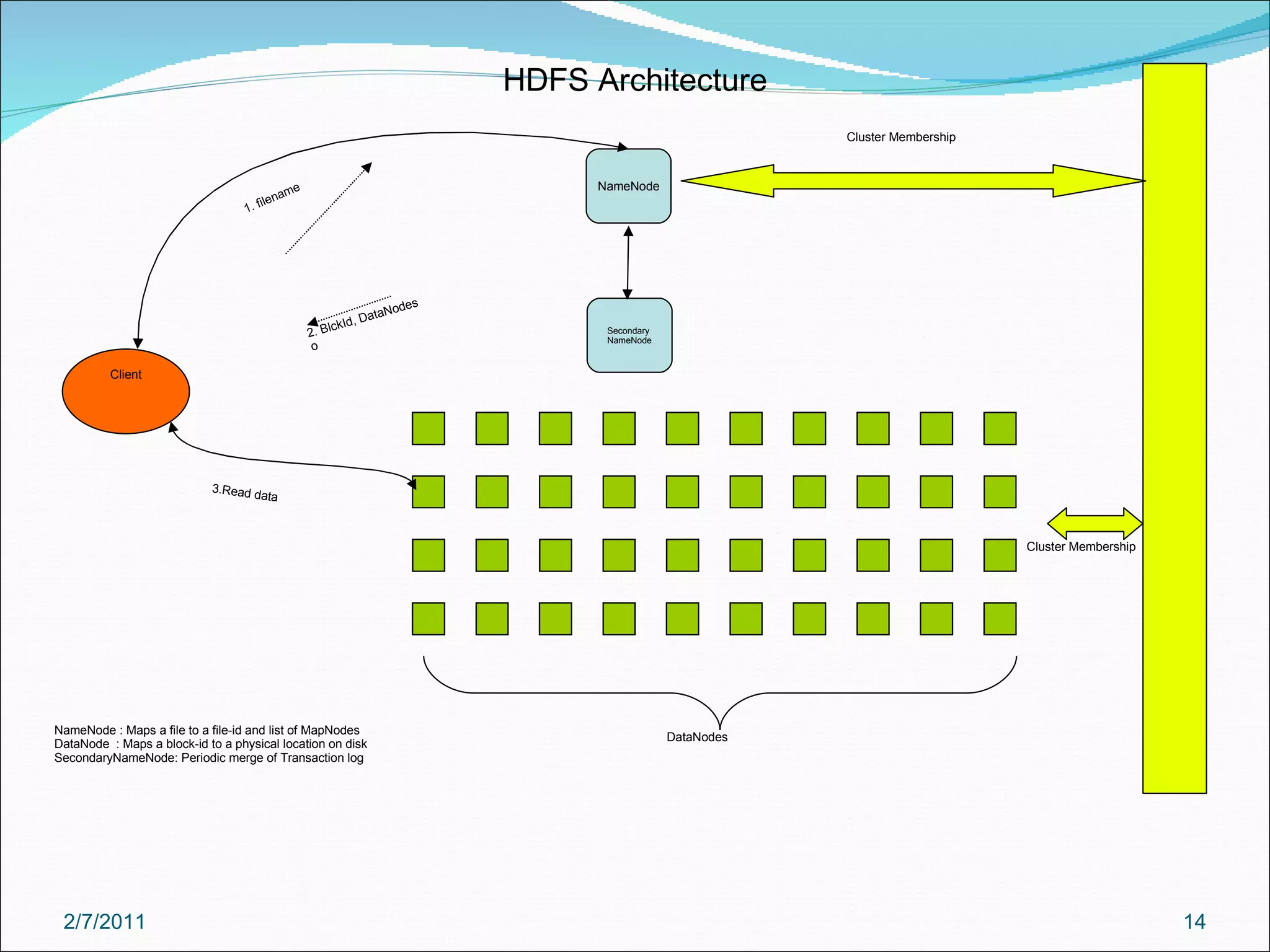
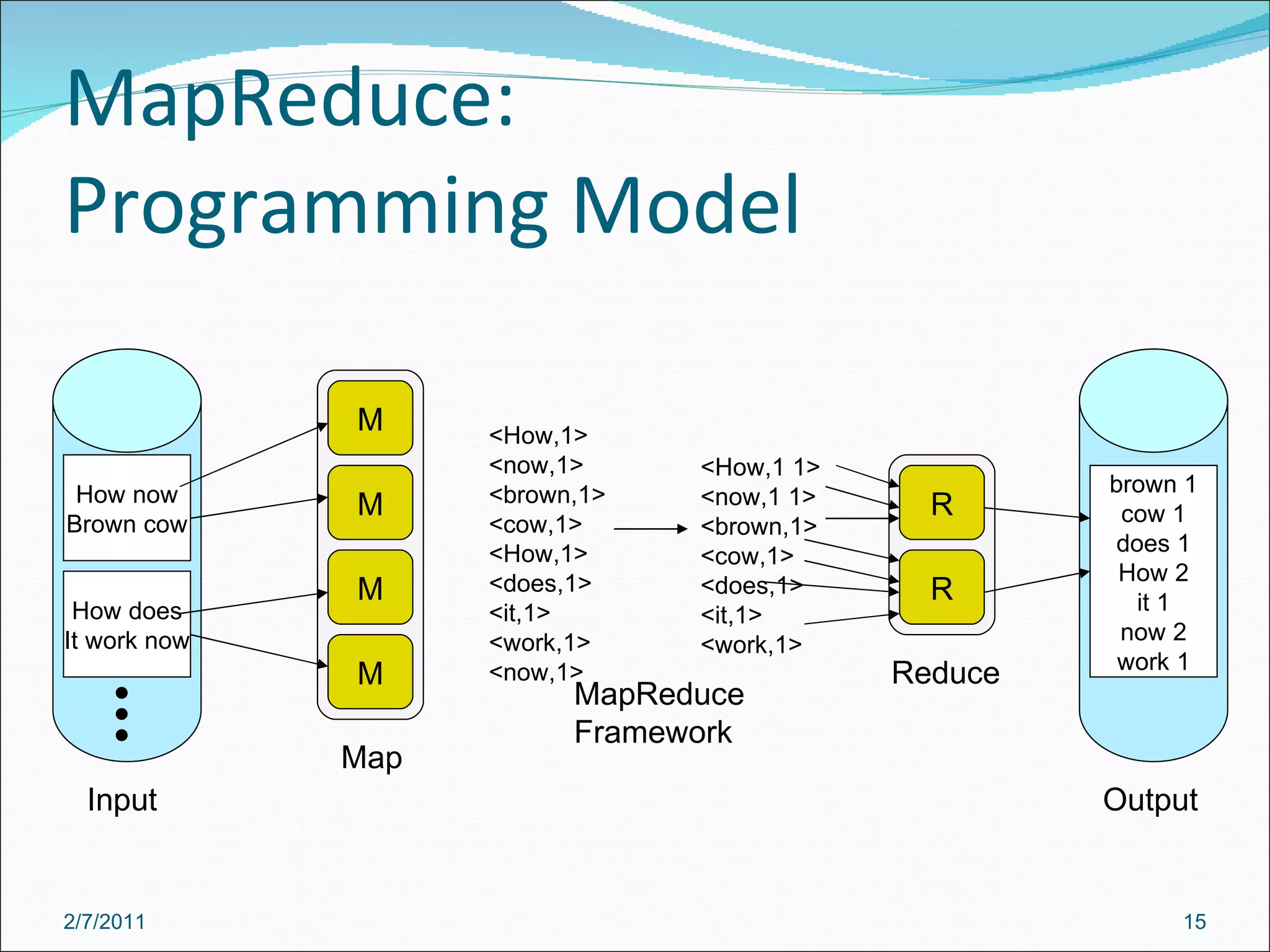


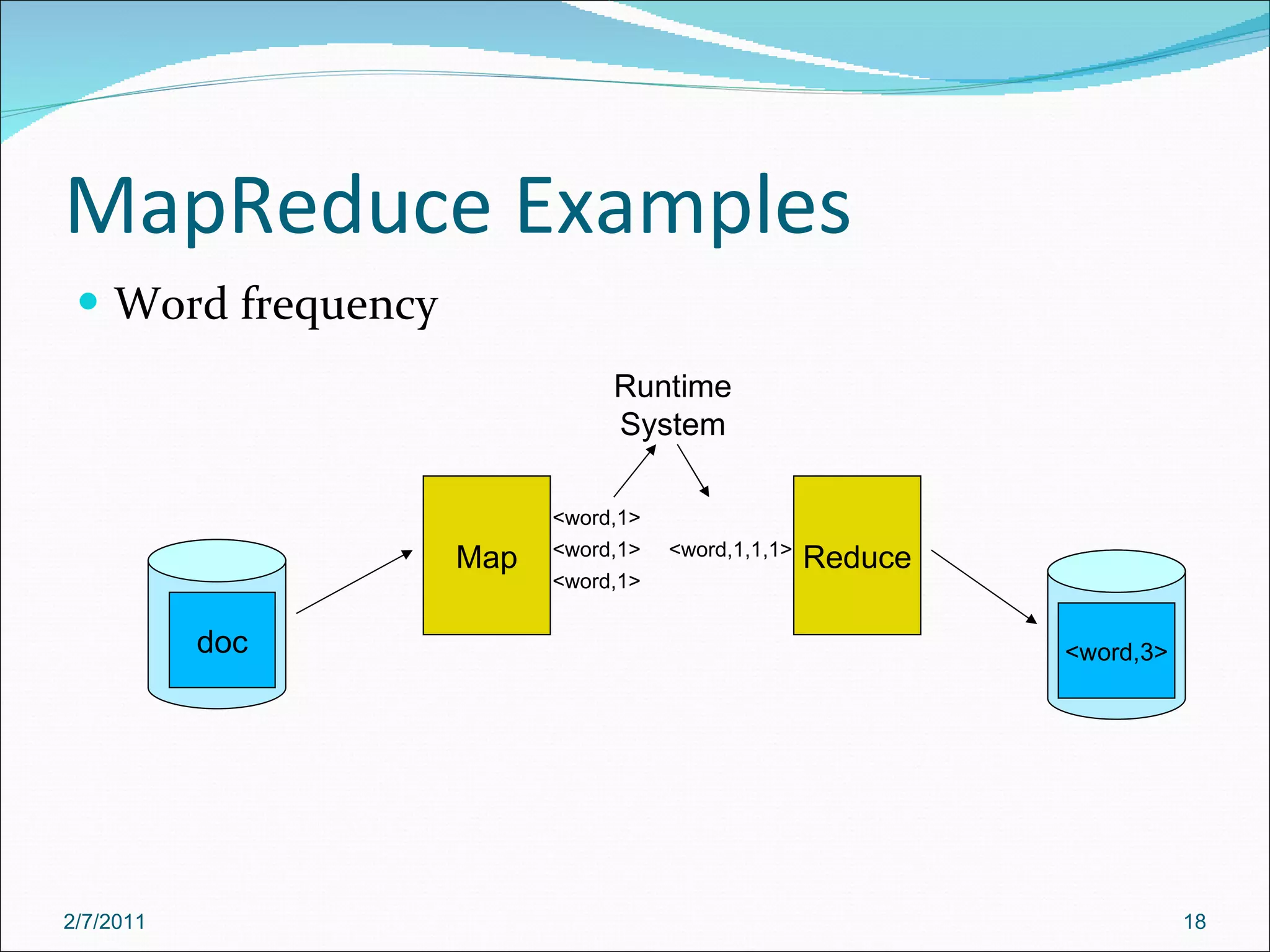

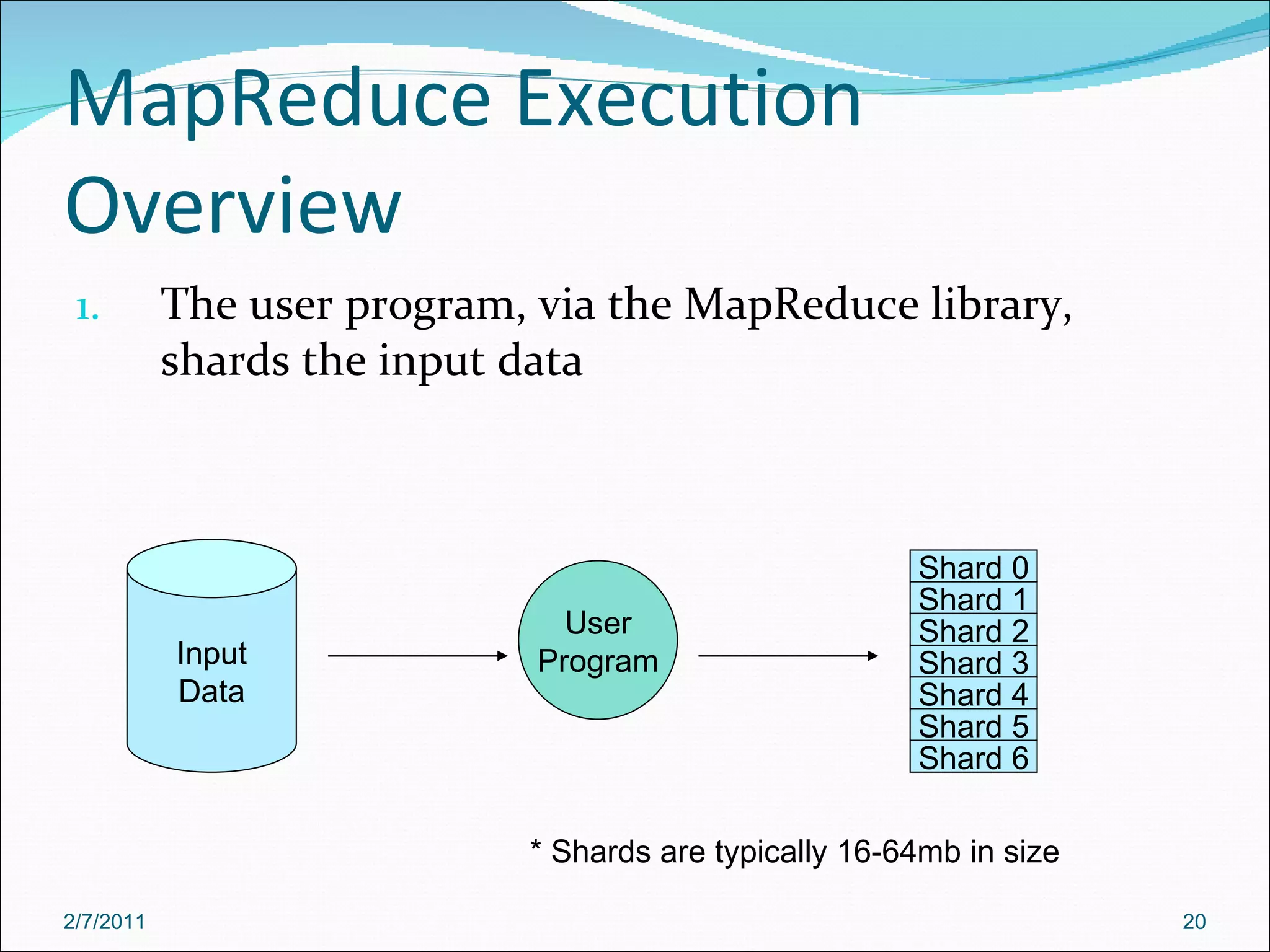
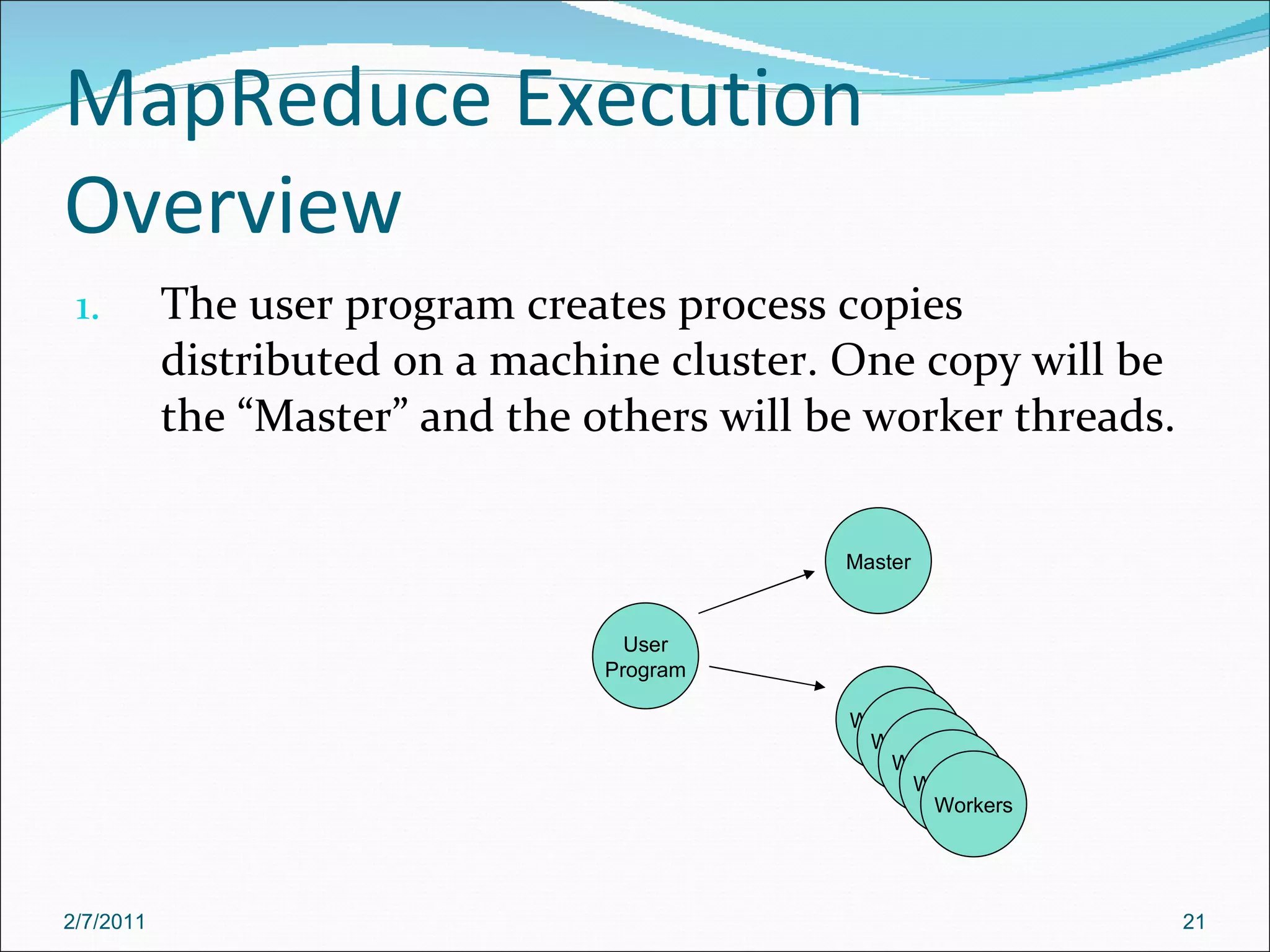

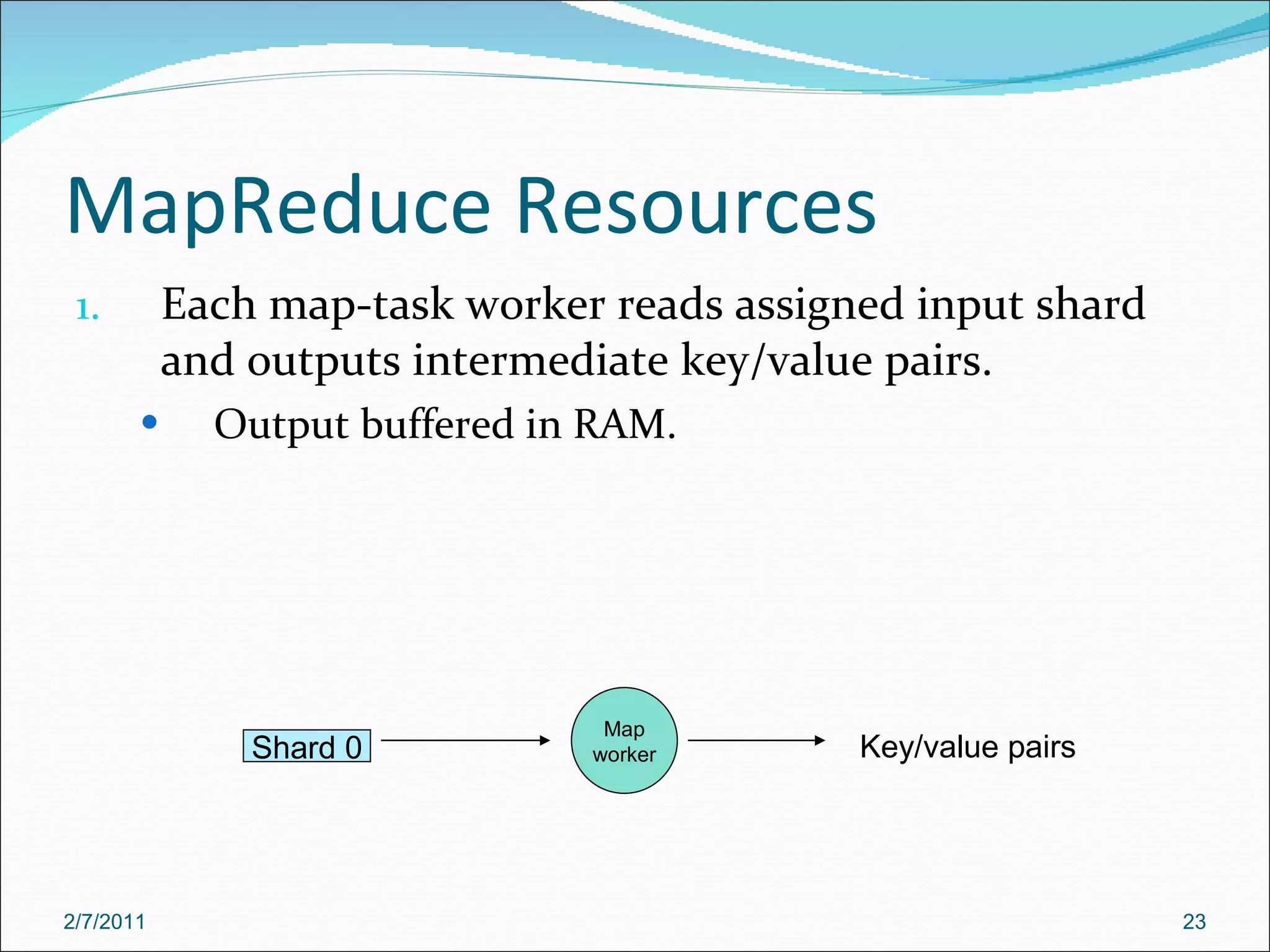
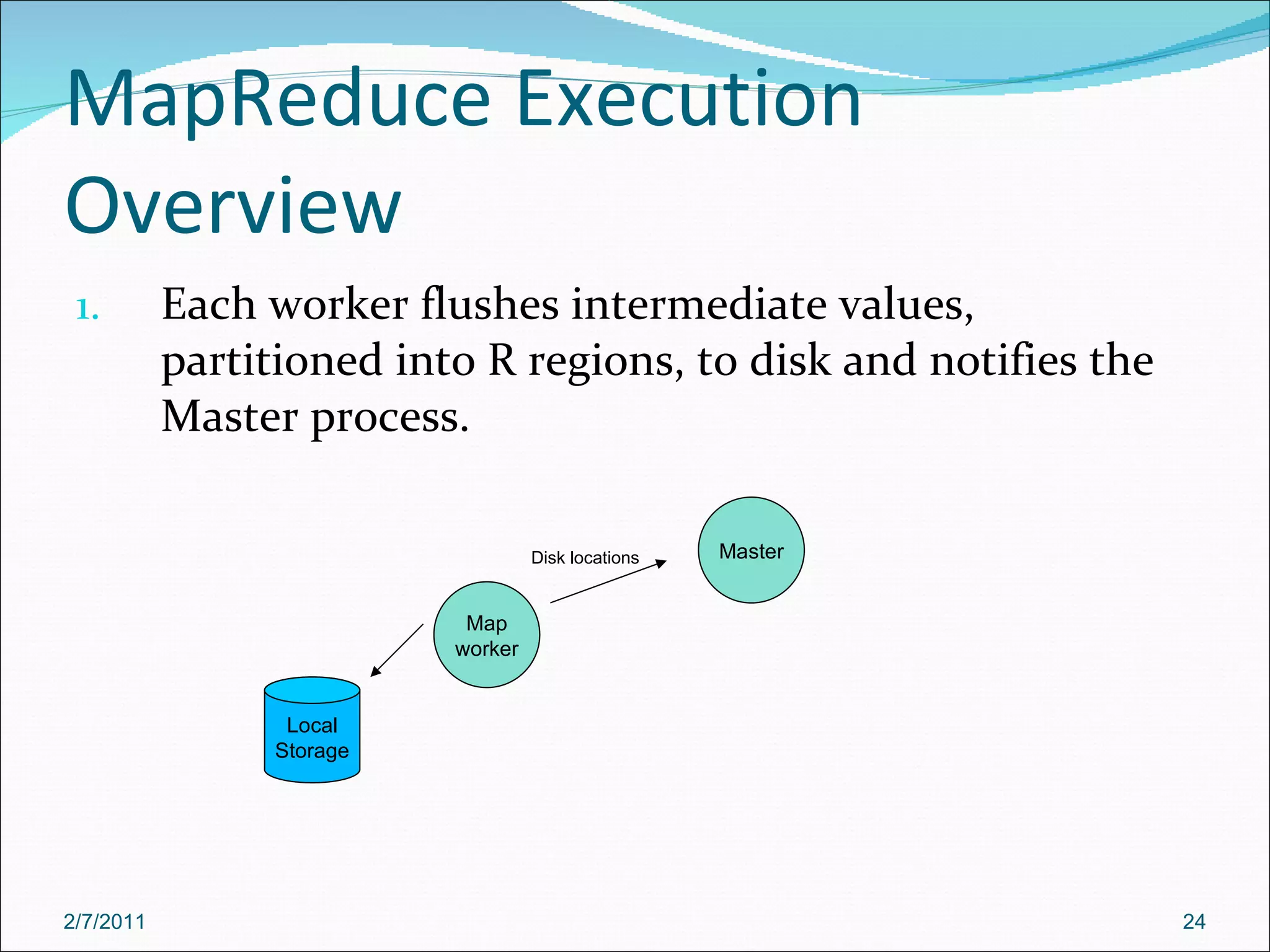
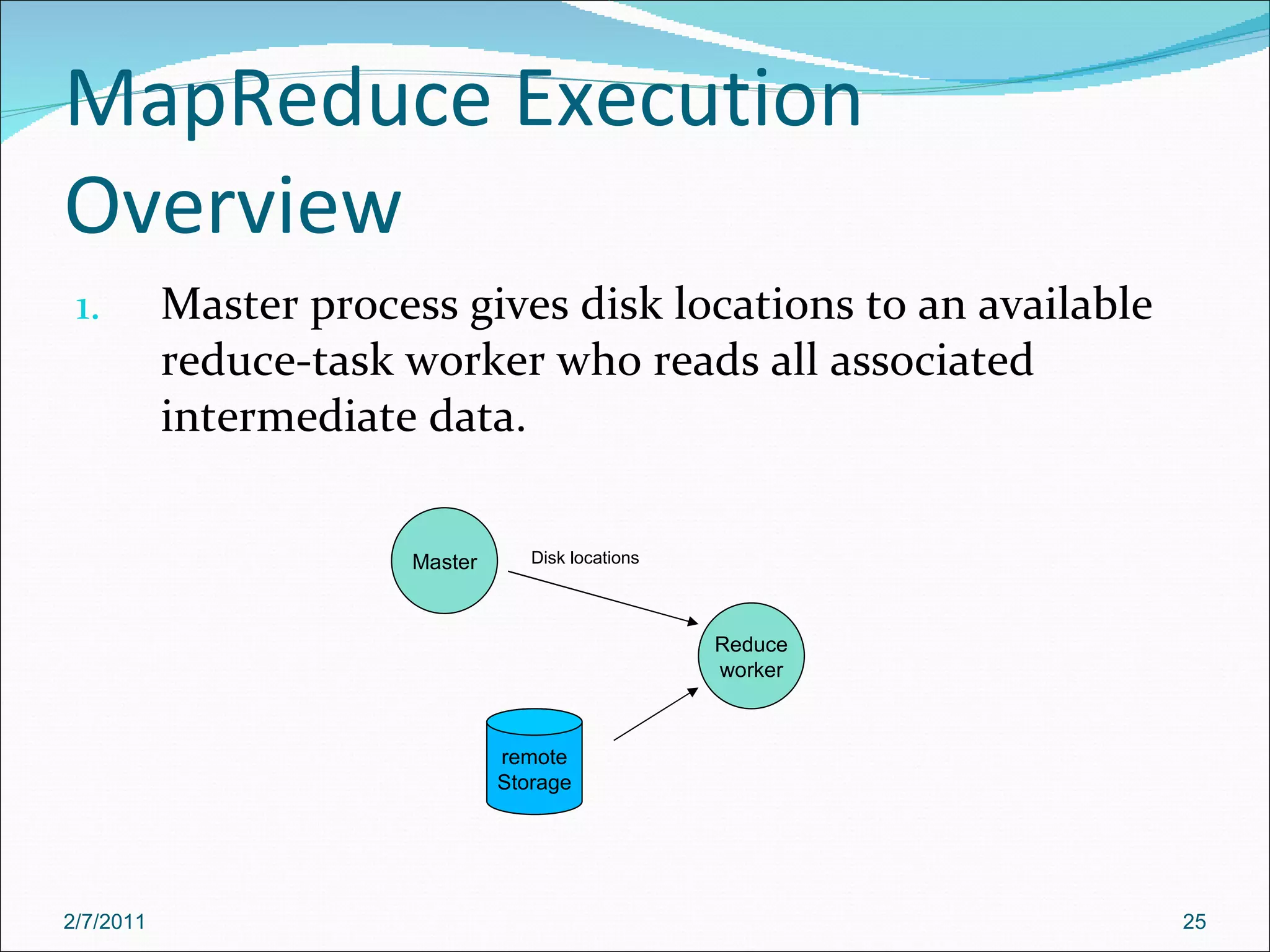
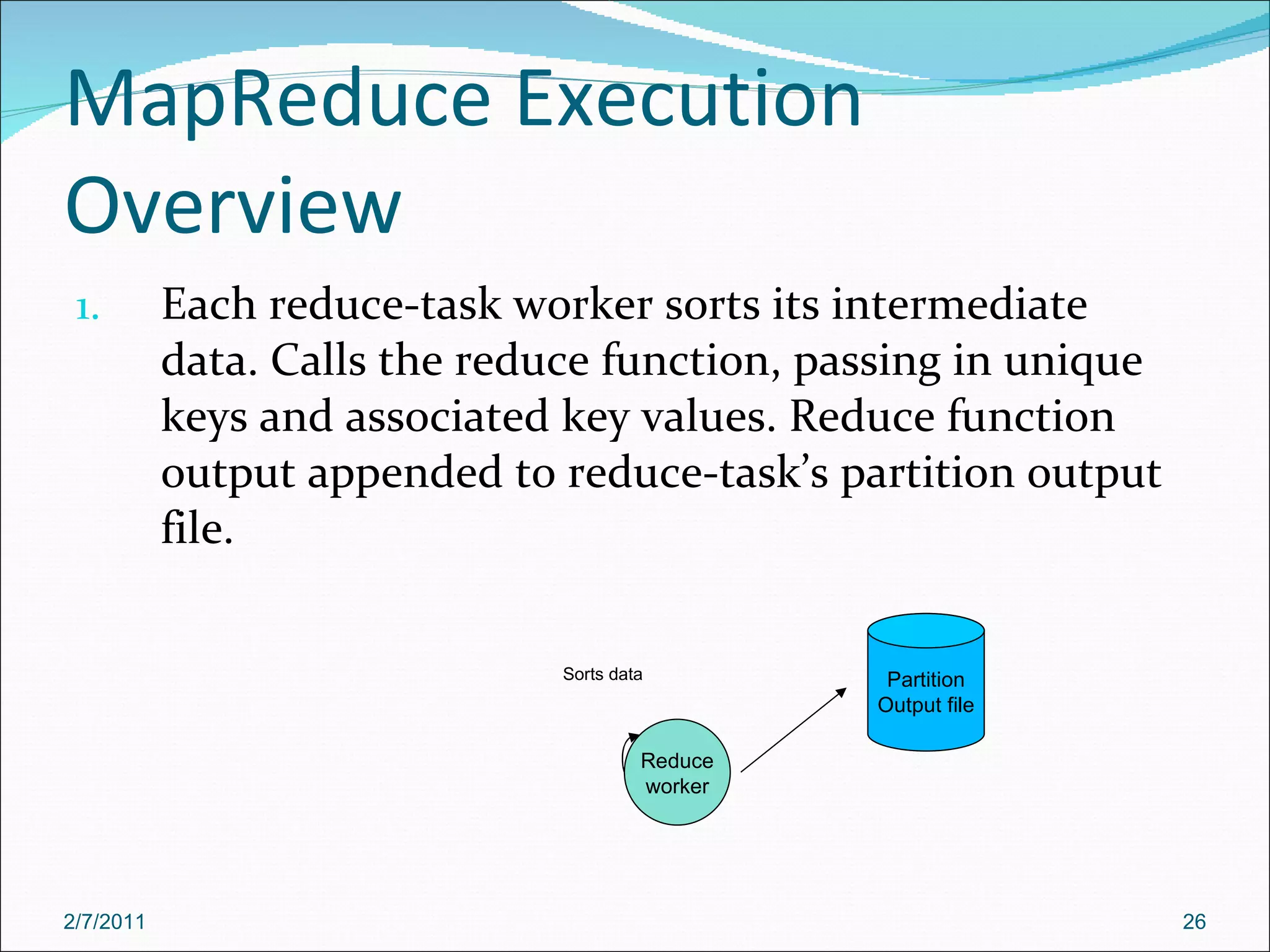
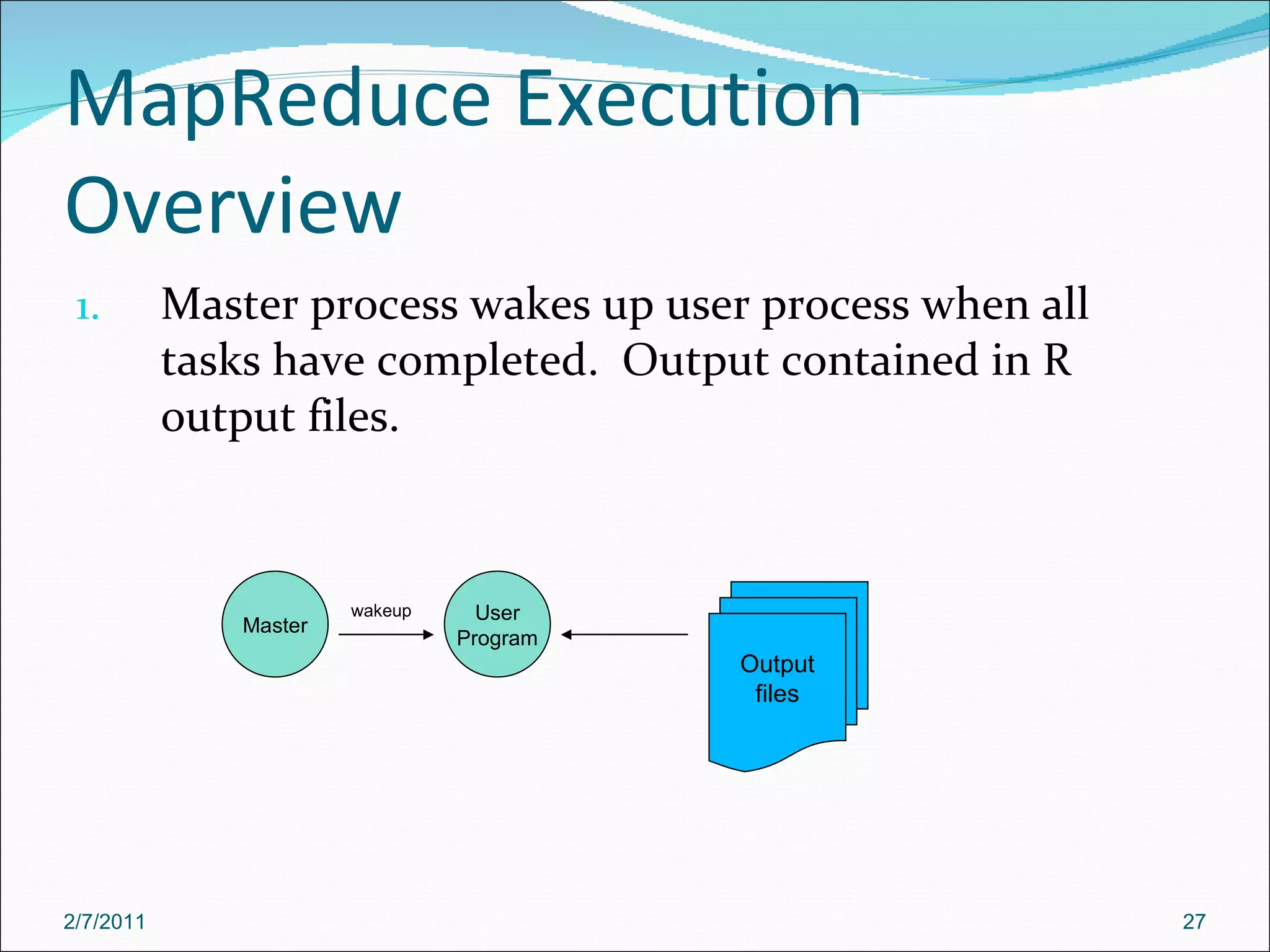
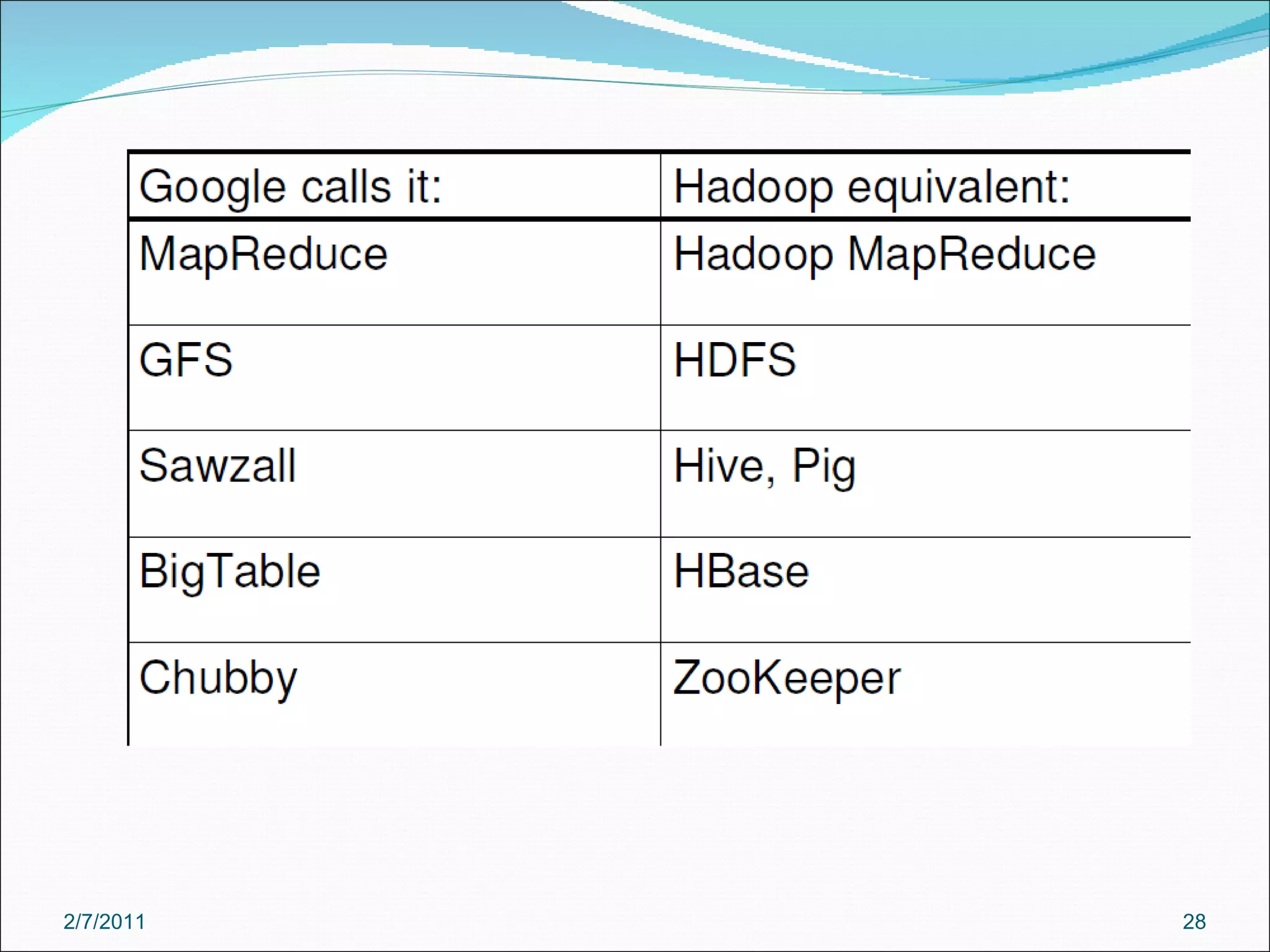







The document provides an overview of Hadoop distributed computing. It discusses how Hadoop uses MapReduce and HDFS to efficiently process large amounts of data across clusters of commodity servers. Key features of Hadoop include scaling to large datasets, handling failures automatically, and providing a simple programming model through MapReduce.













































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















