Downloaded 16 times






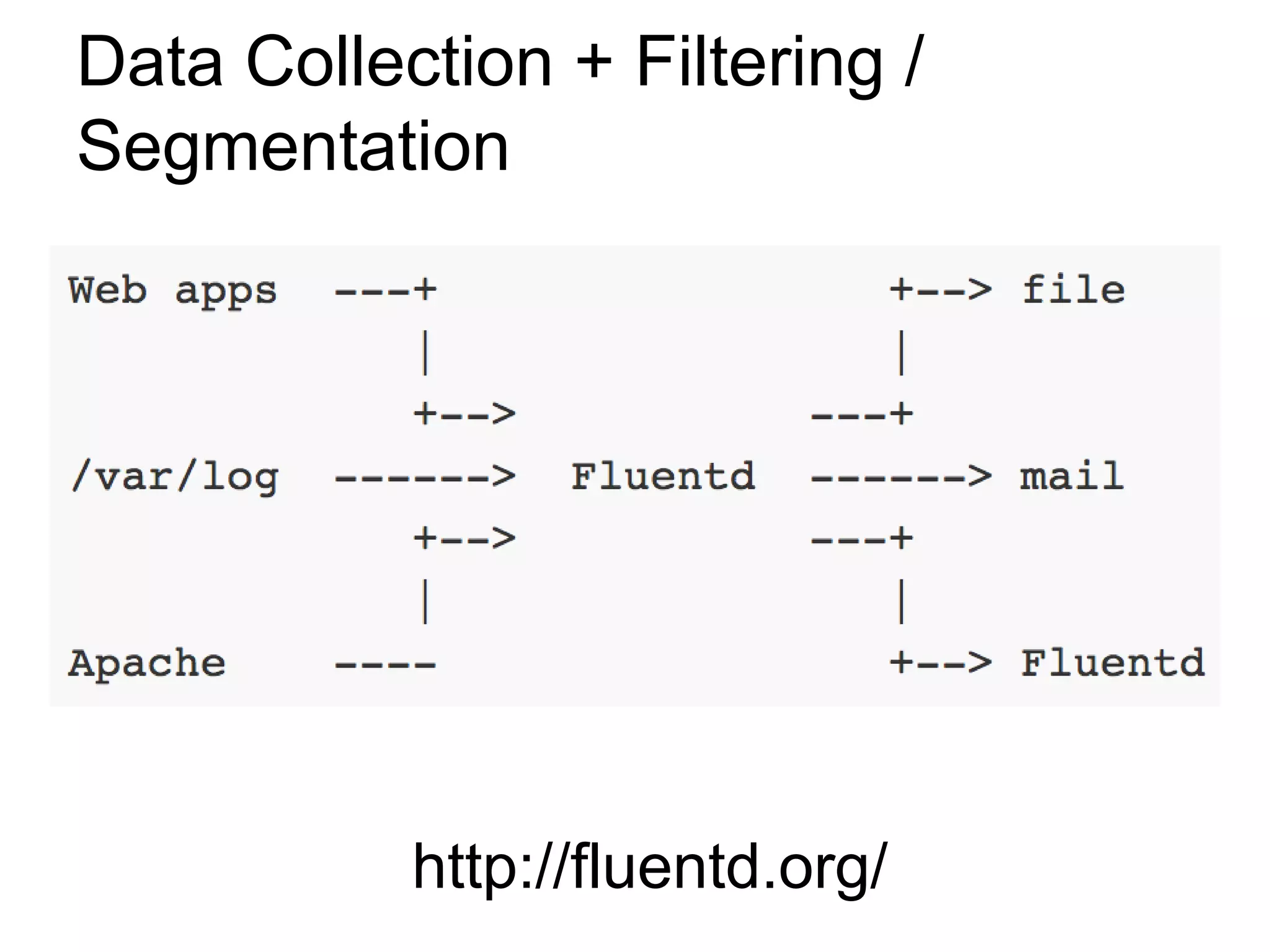
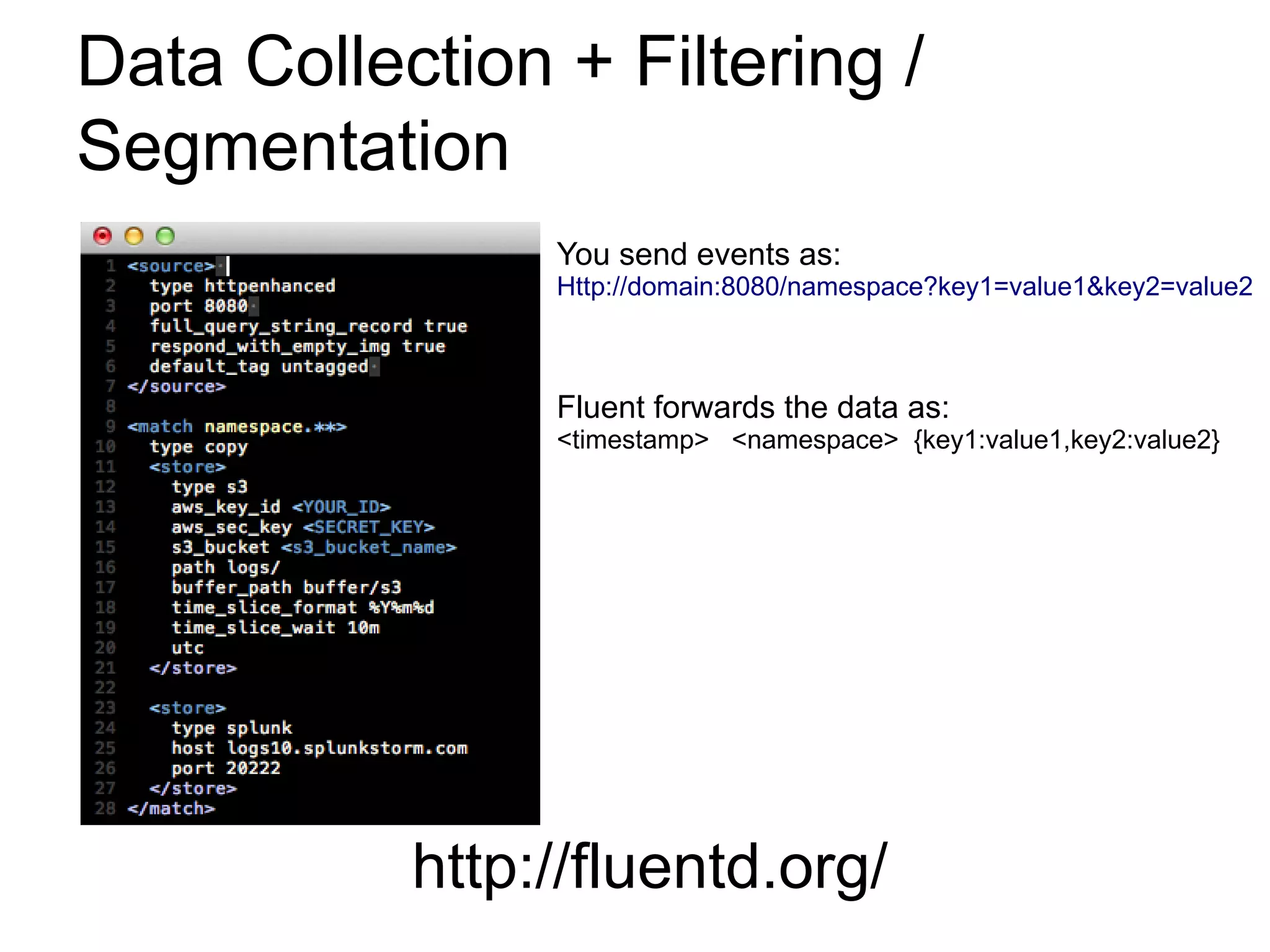
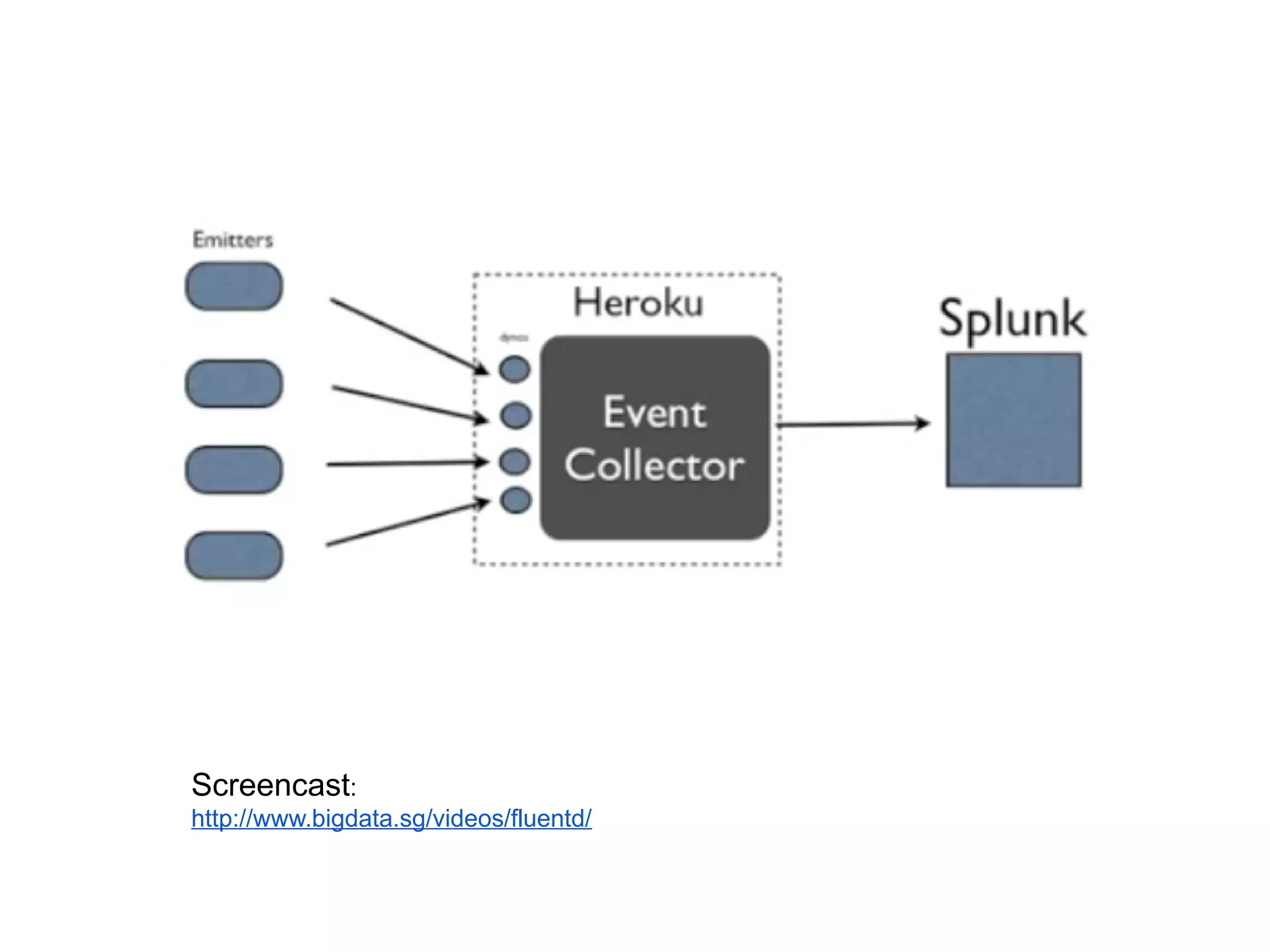


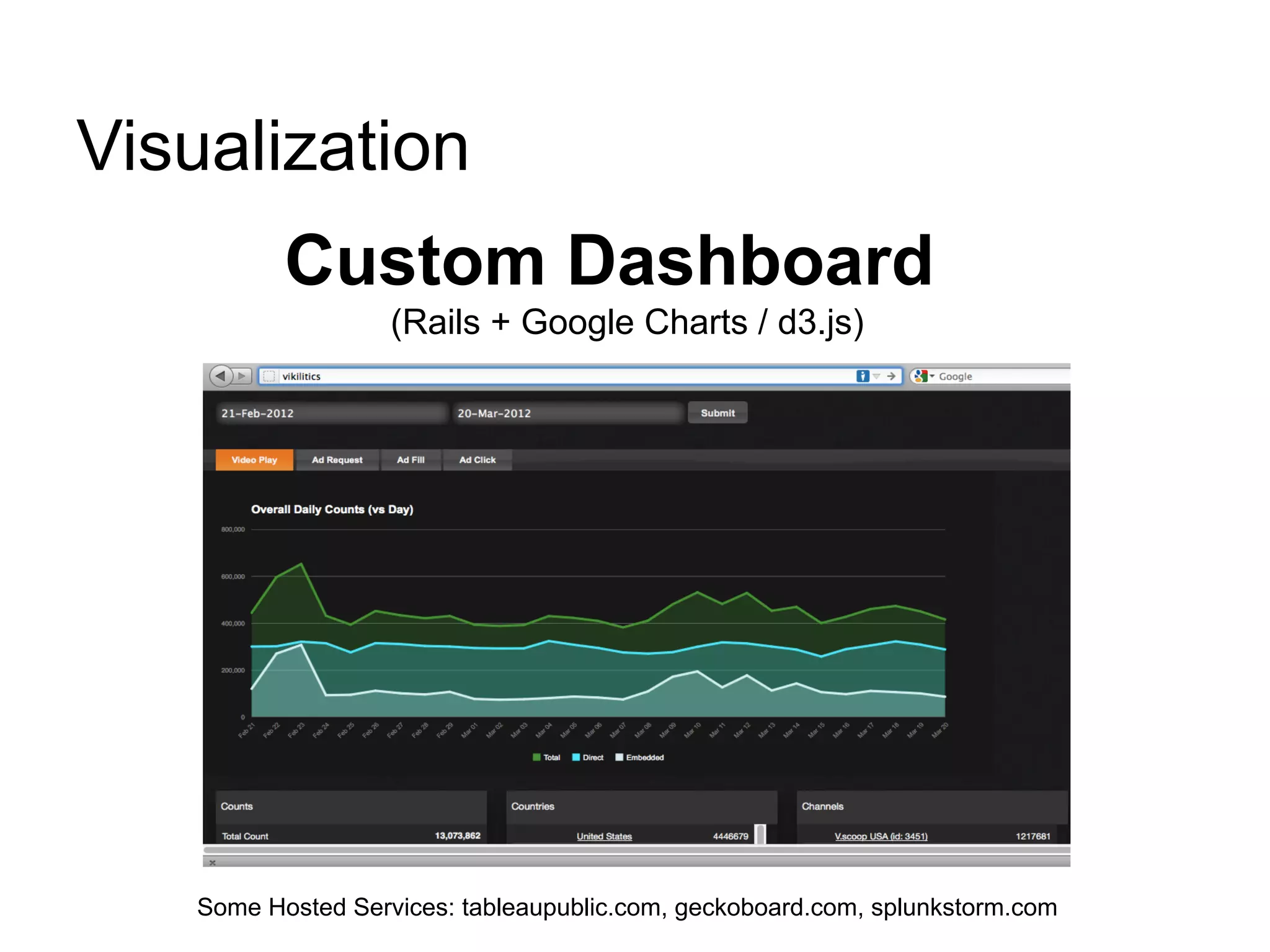


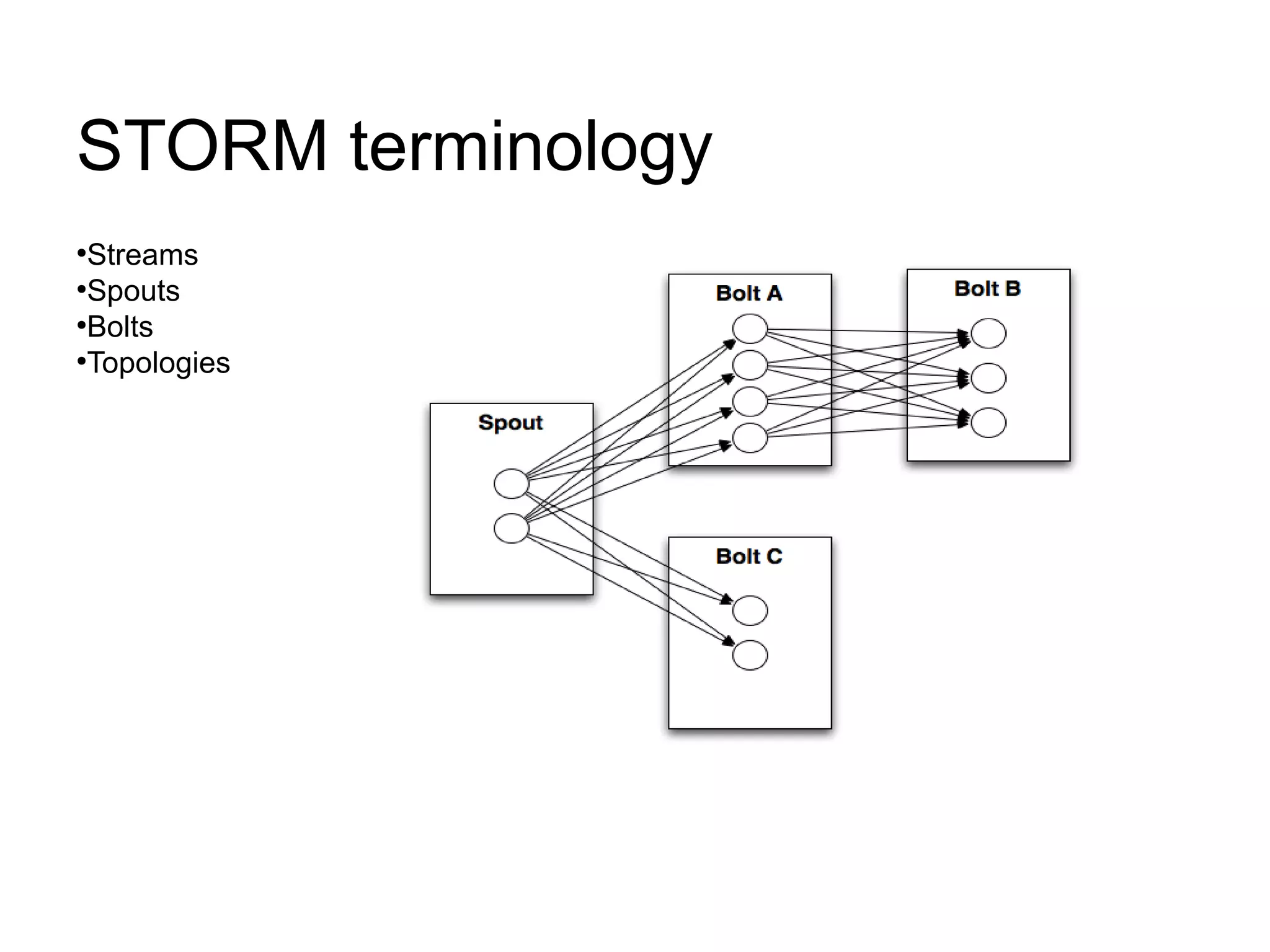

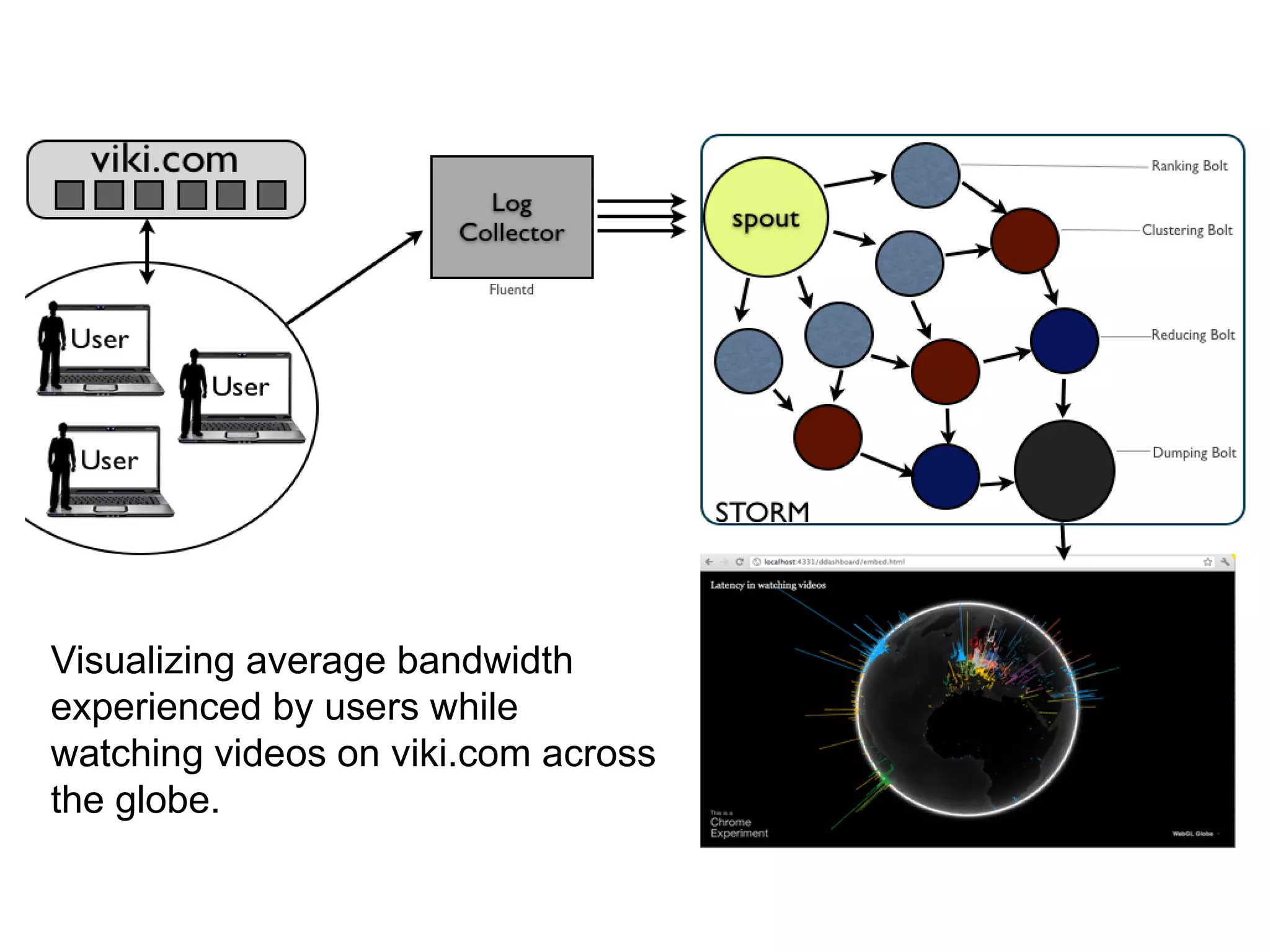

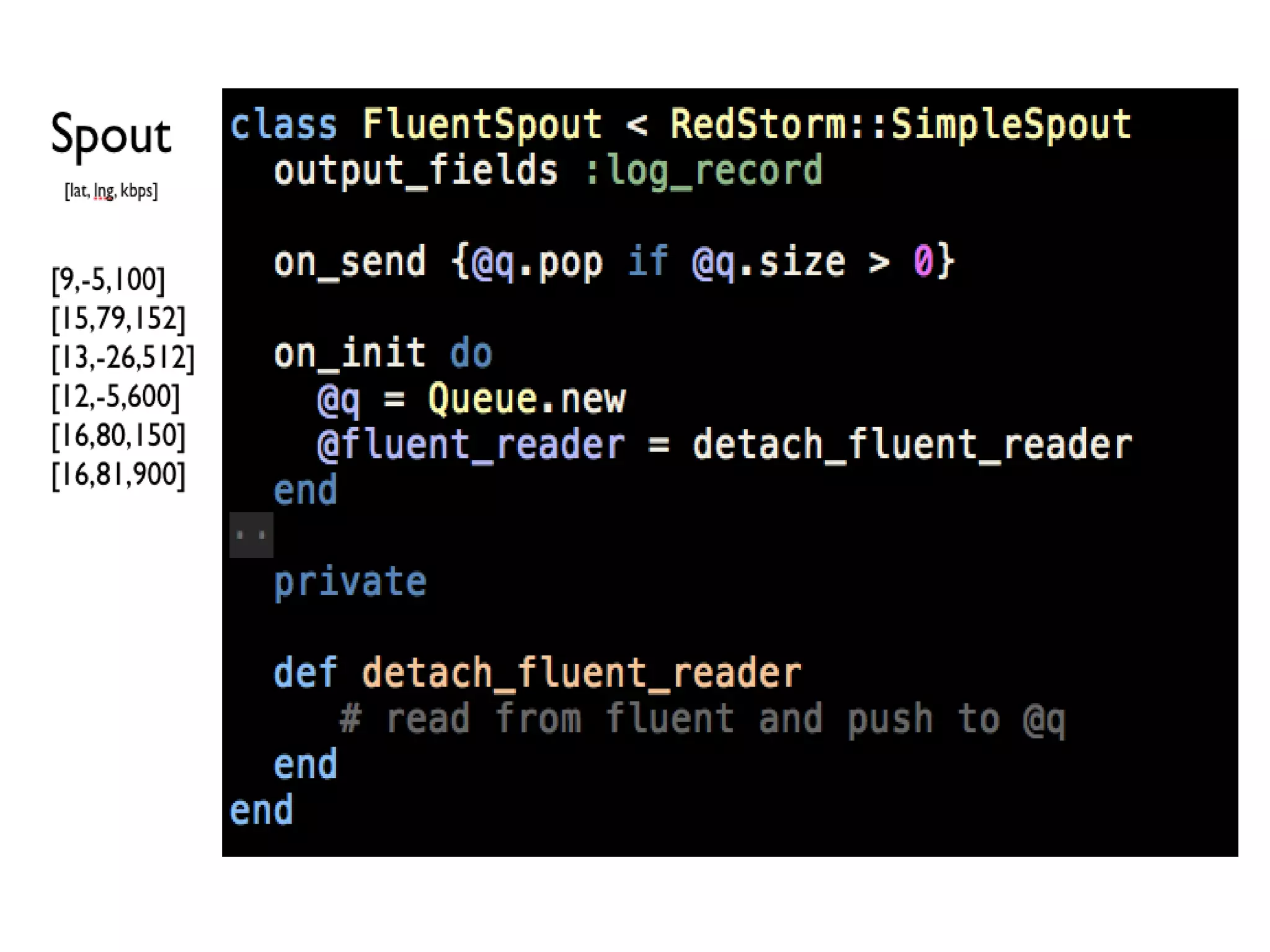
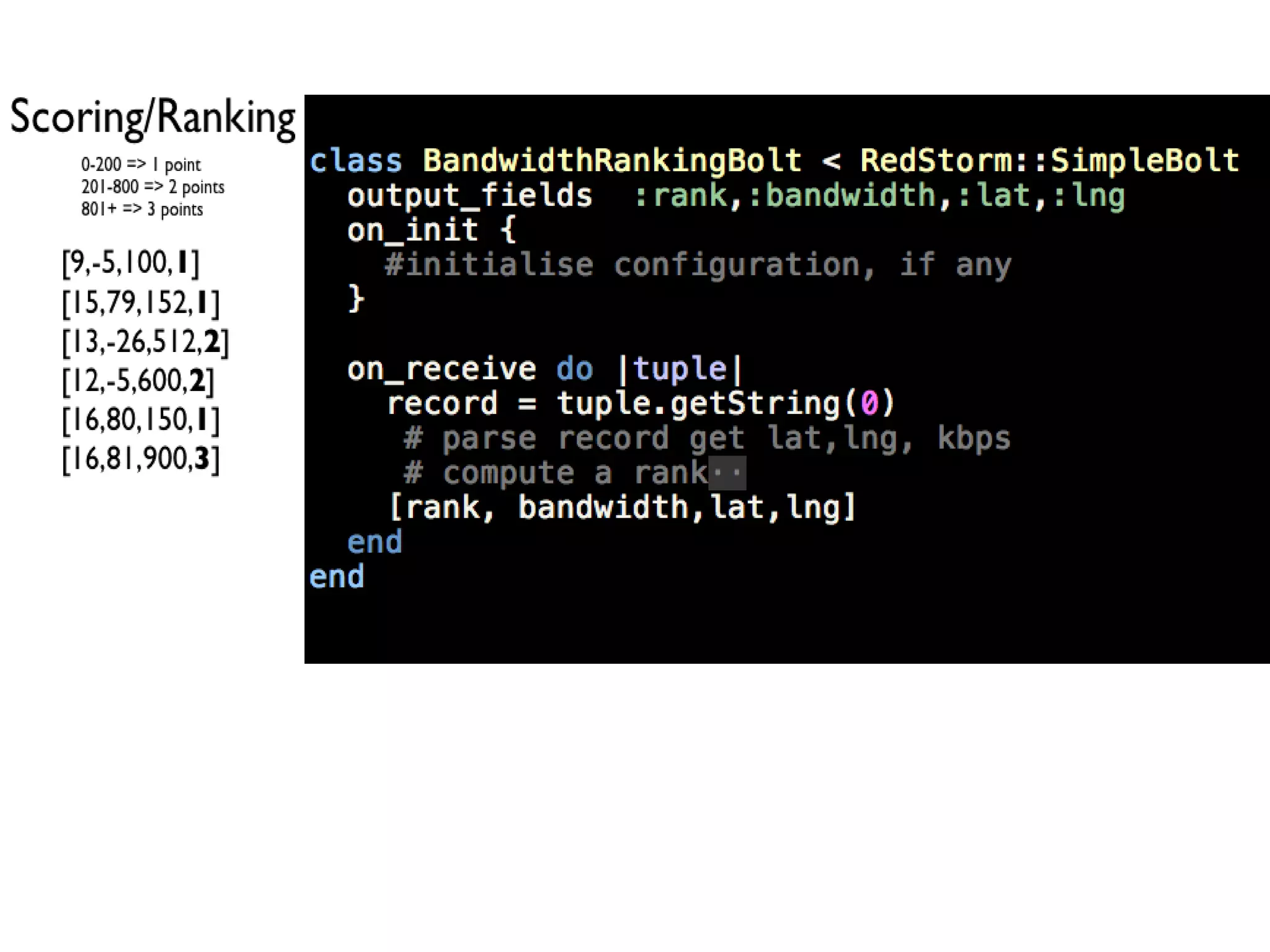

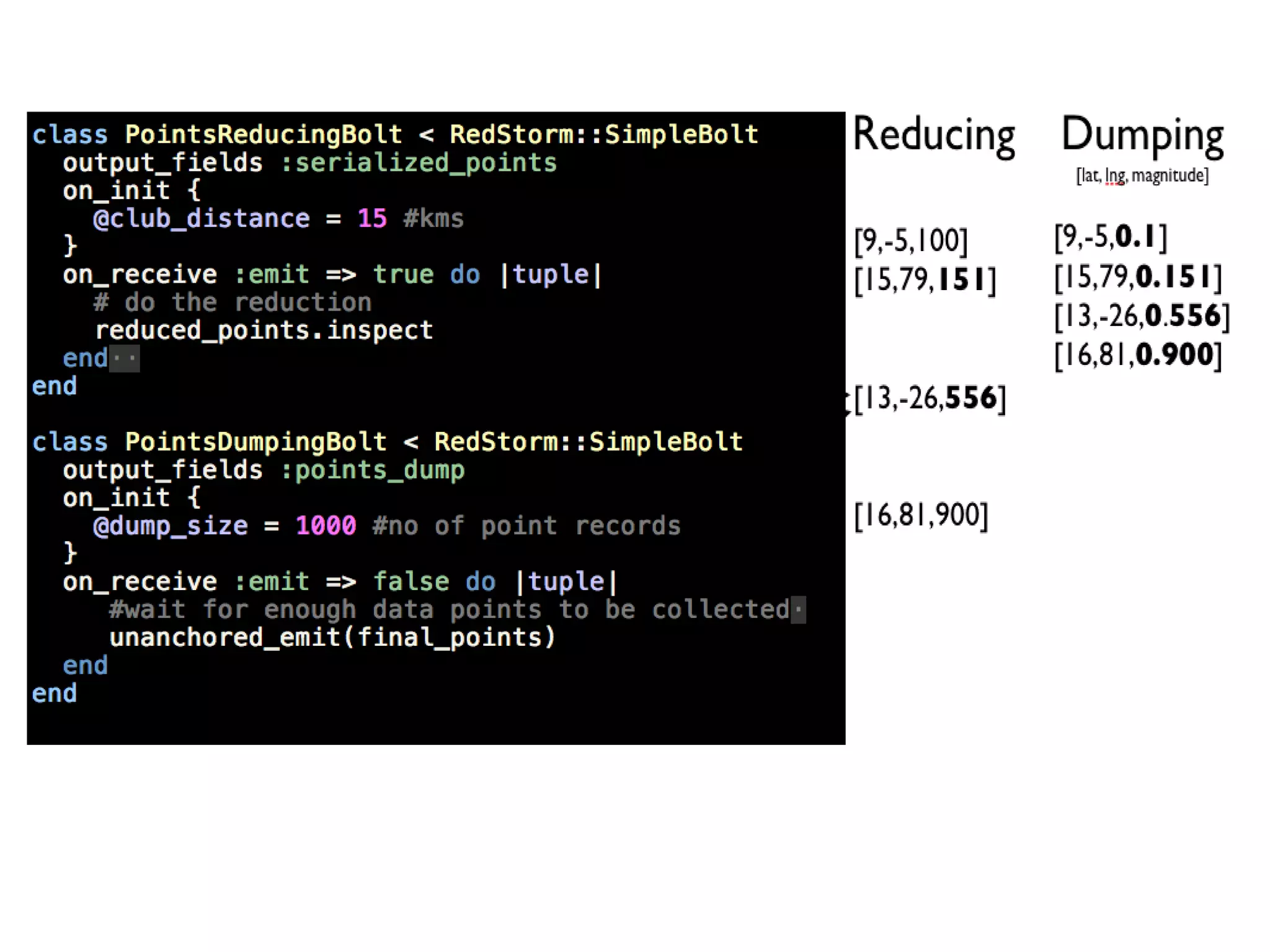
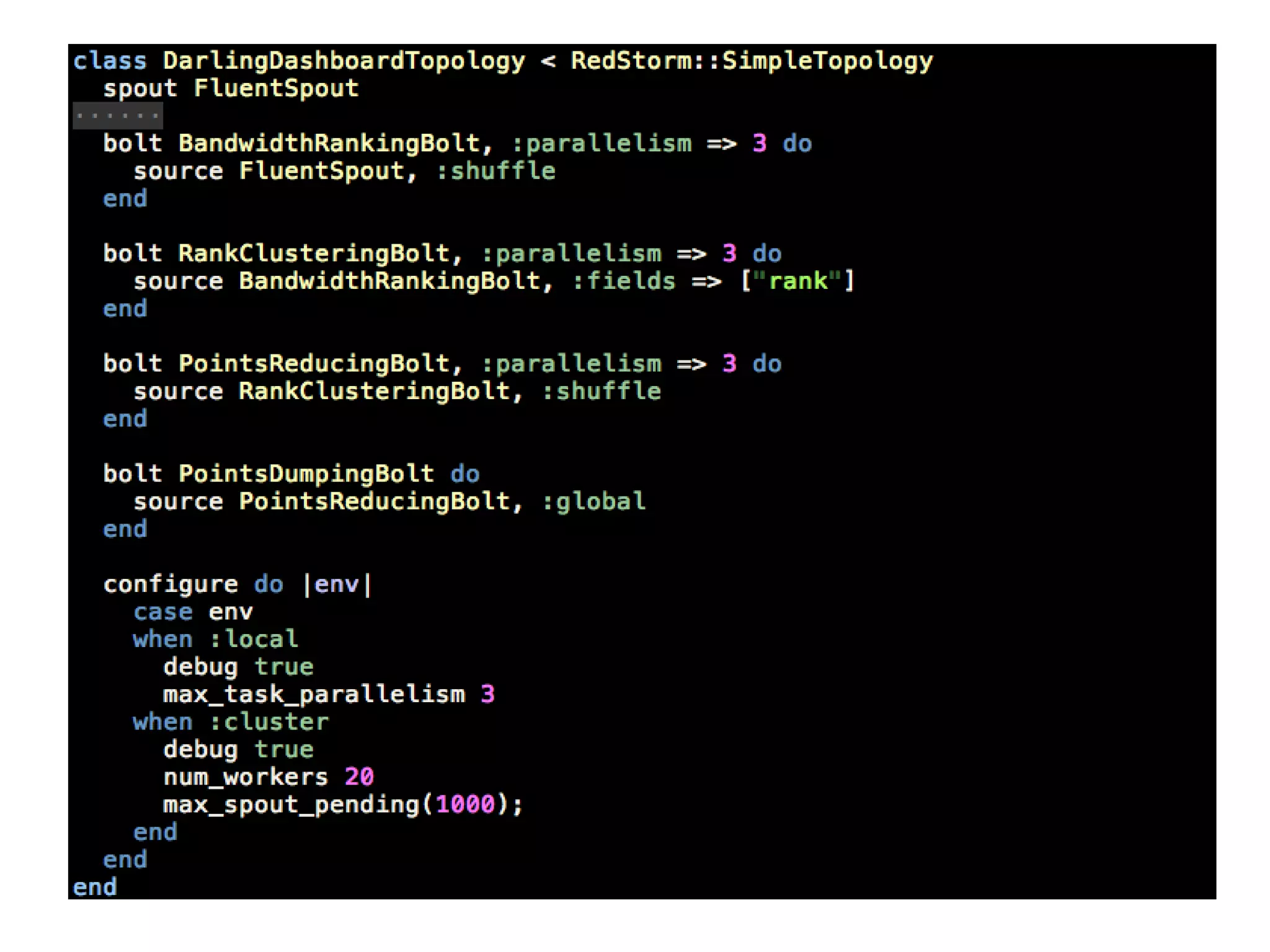


This document discusses big data challenges and trends in data collection, storage, analysis, and stream processing. It introduces tools like Fluentd for data collection and filtering, Hadoop and OpenTSDB for storage, Hadoop Streaming and Hive for analysis, and custom dashboards or services like Tableau for visualization. It also covers stream computing with STORM, describing streams, spouts, bolts, and topologies, and provides an example of visualizing bandwidth usage with RedStorm on JRuby. The document is presented by an engineering team lead who founded BigData.SG and contributes to fluentd, pfeed, and other projects.

































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)







