Downloaded 65 times
![Eat My Data: (now with 20% more rant!) How everybody gets file I/O wrong Stewart Smith [email_address] Senior Software Engineer, MySQL Cluster MySQL AB](https://image.slidesharecdn.com/eatmydata-110825033816-phpapp01/75/Eat-my-data-1-2048.jpg)



















































































































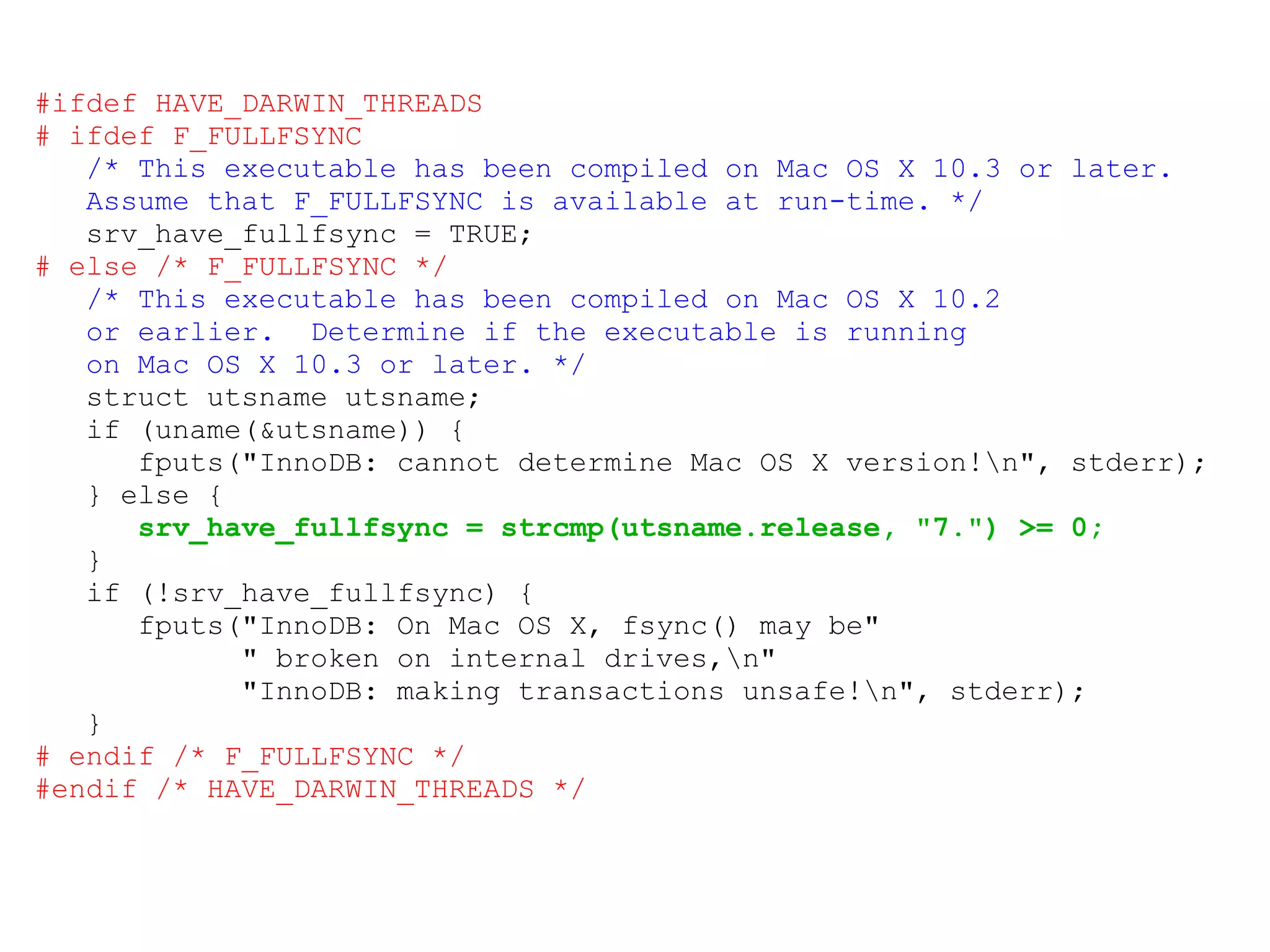






























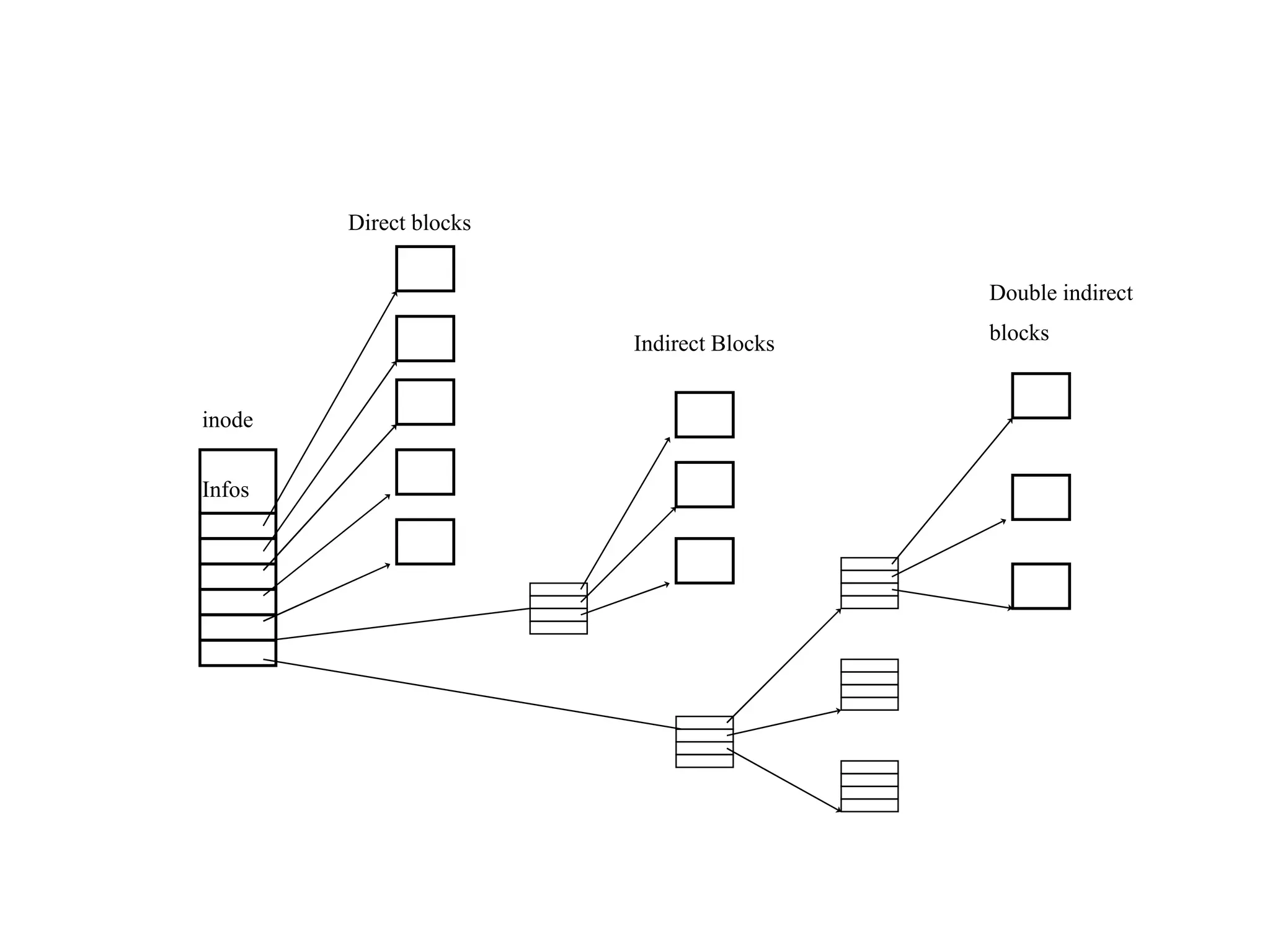




















The document discusses common mistakes made in file input/output (I/O) that can lead to data loss. It notes that asynchronous I/O is faster than synchronous I/O but introduces consistency issues. File systems provide weaker consistency guarantees than databases, and operations like close() and rename() do not guarantee data is flushed to disk. The document recommends using transactions and writing to a temporary file followed by renaming to improve data durability.



































































