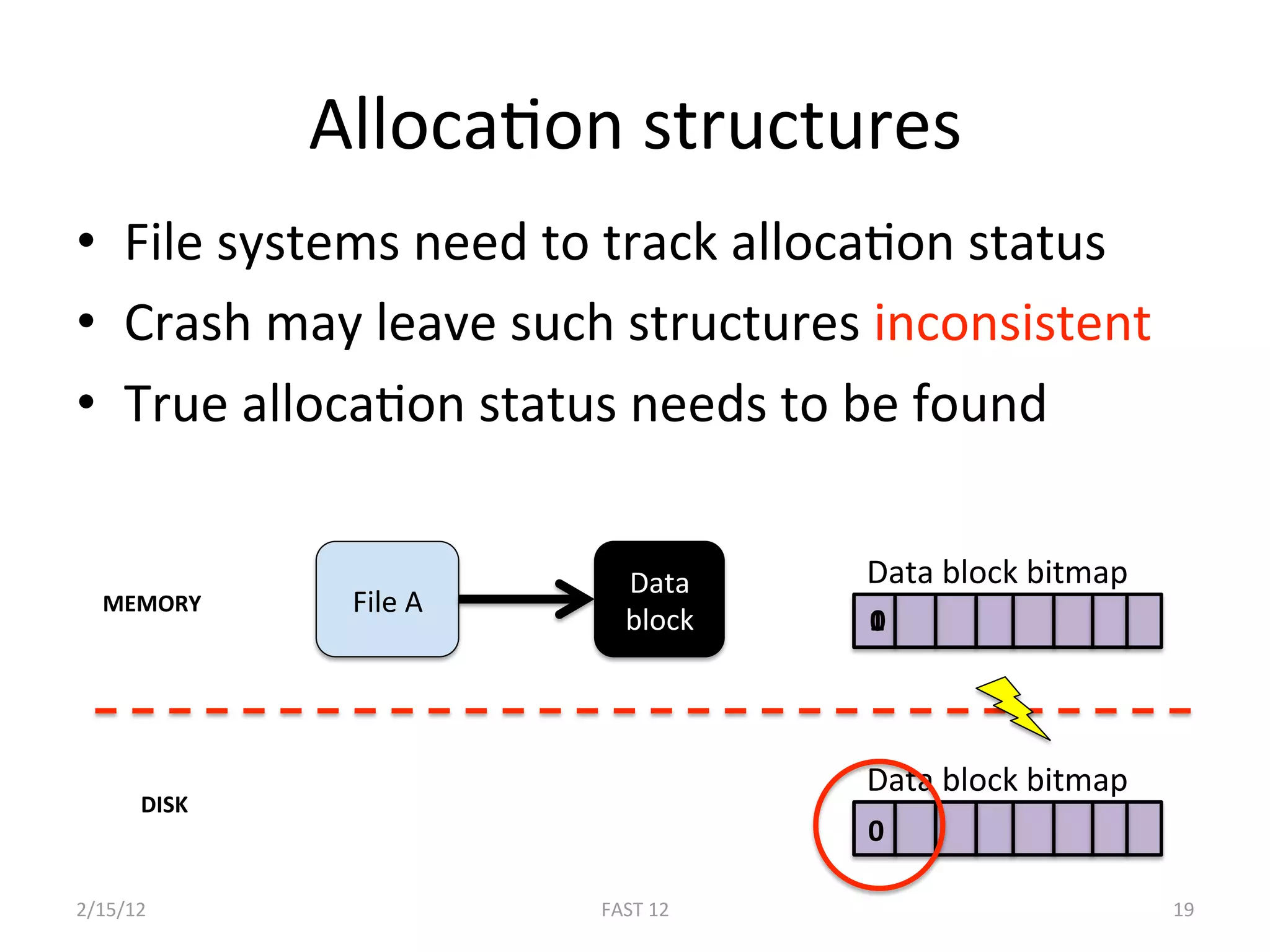
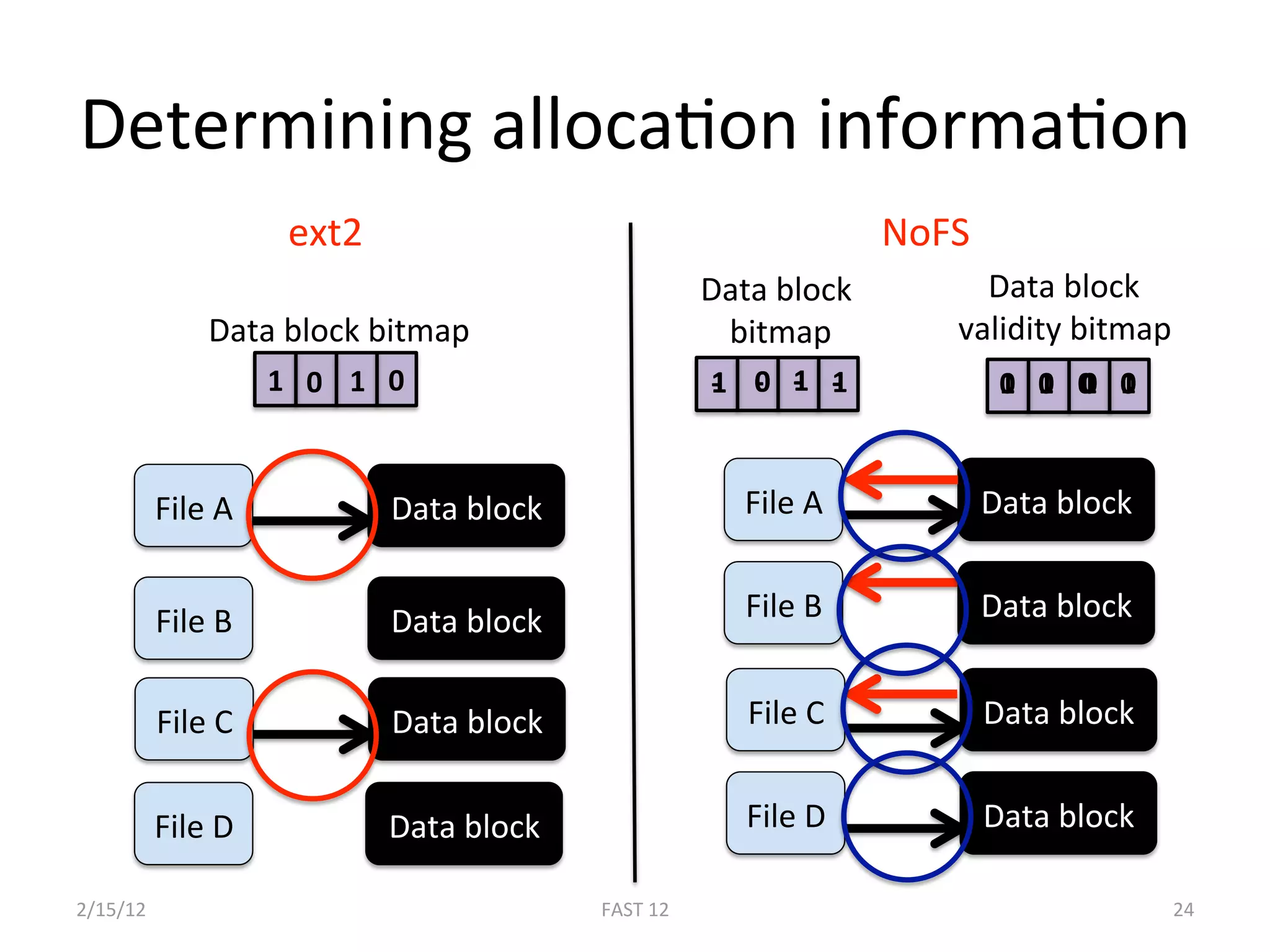
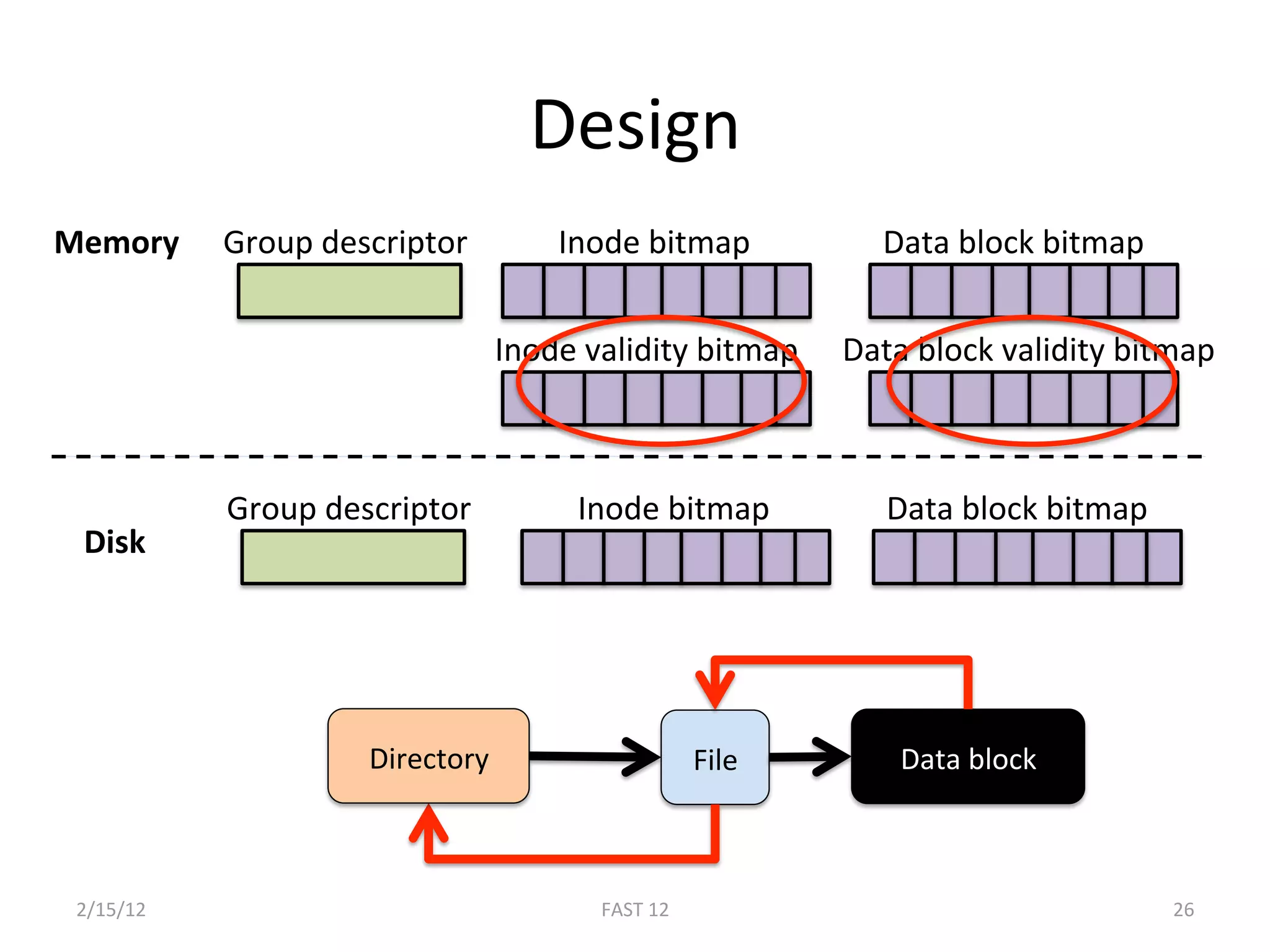
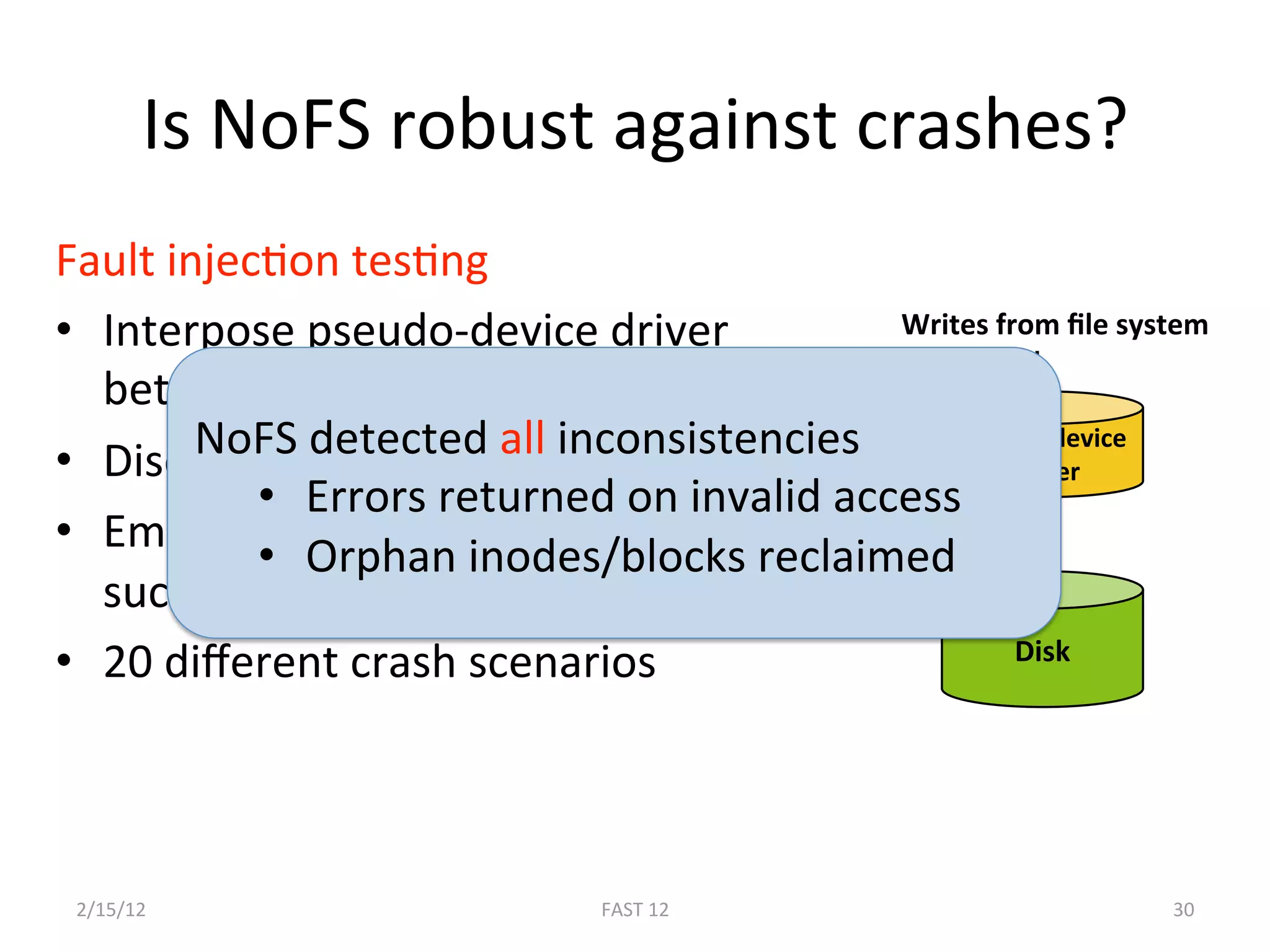
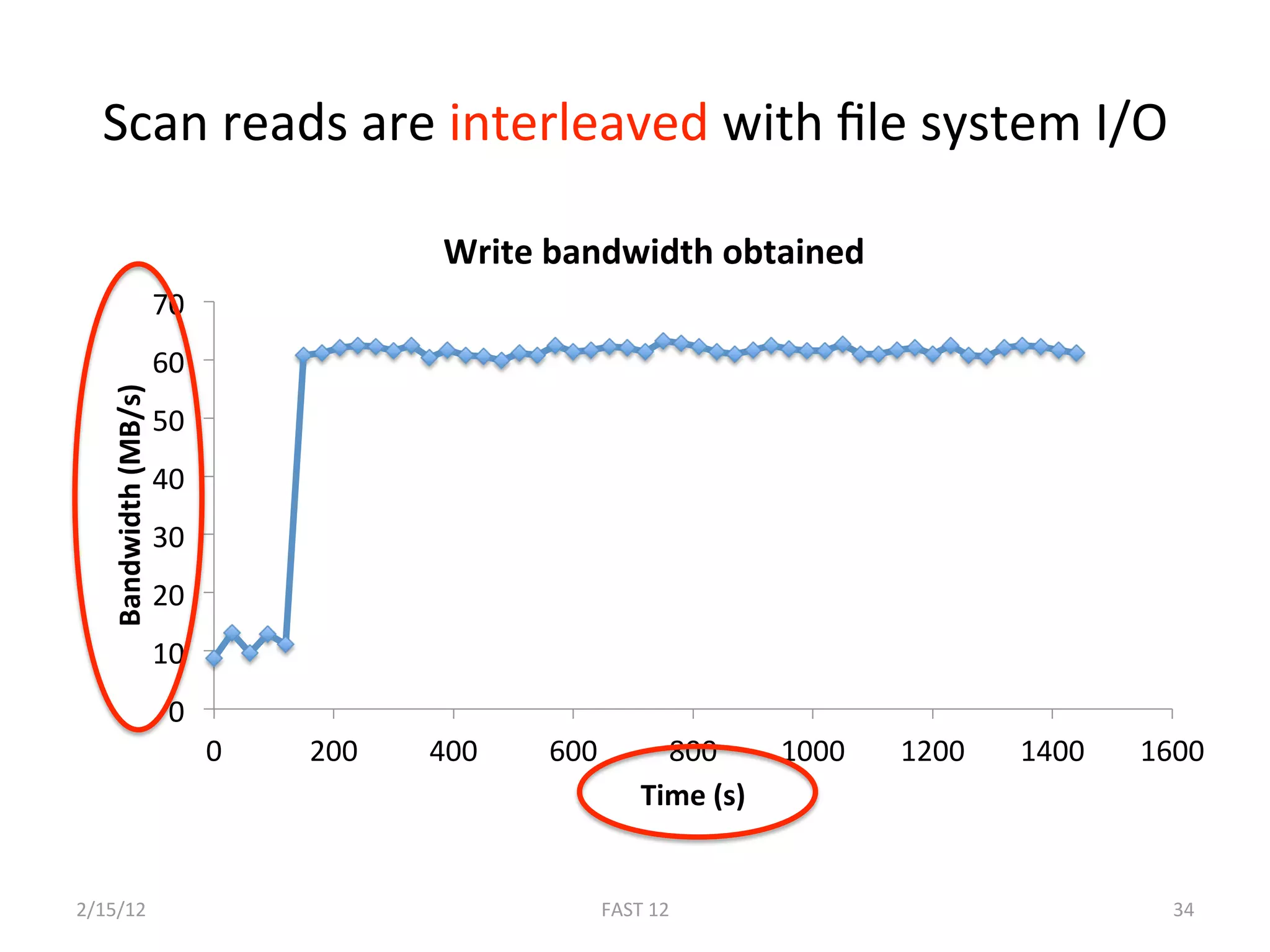
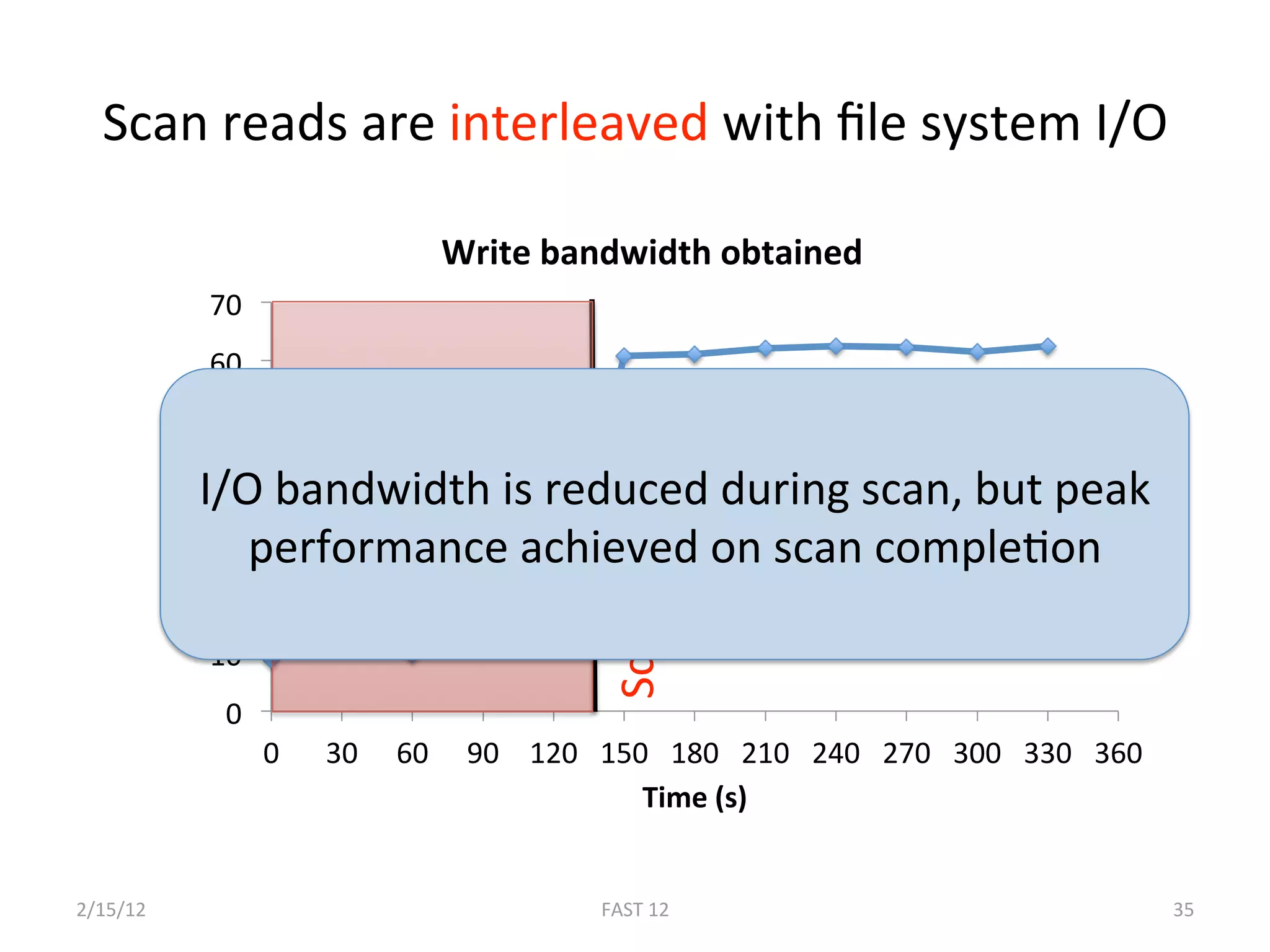
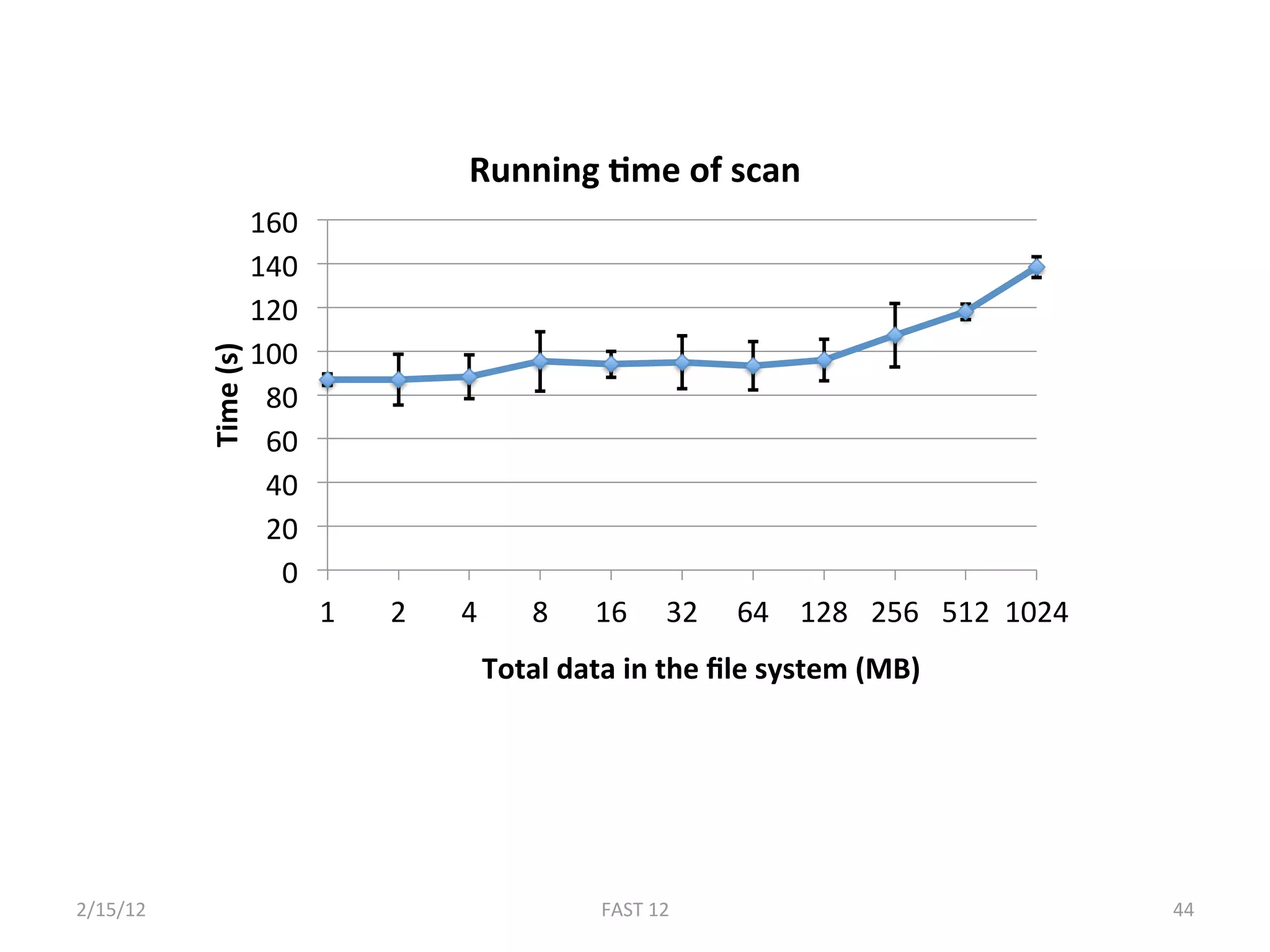
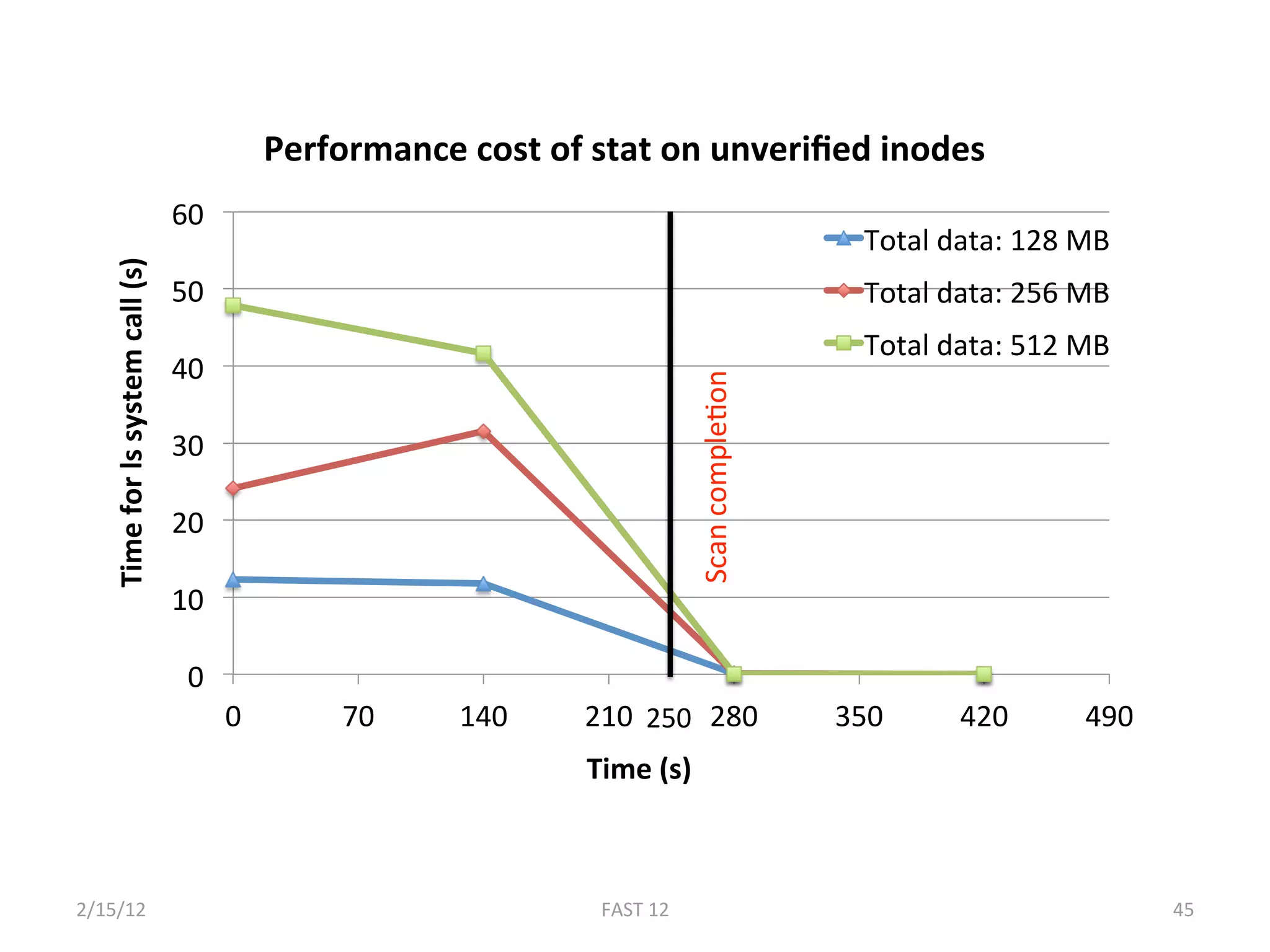
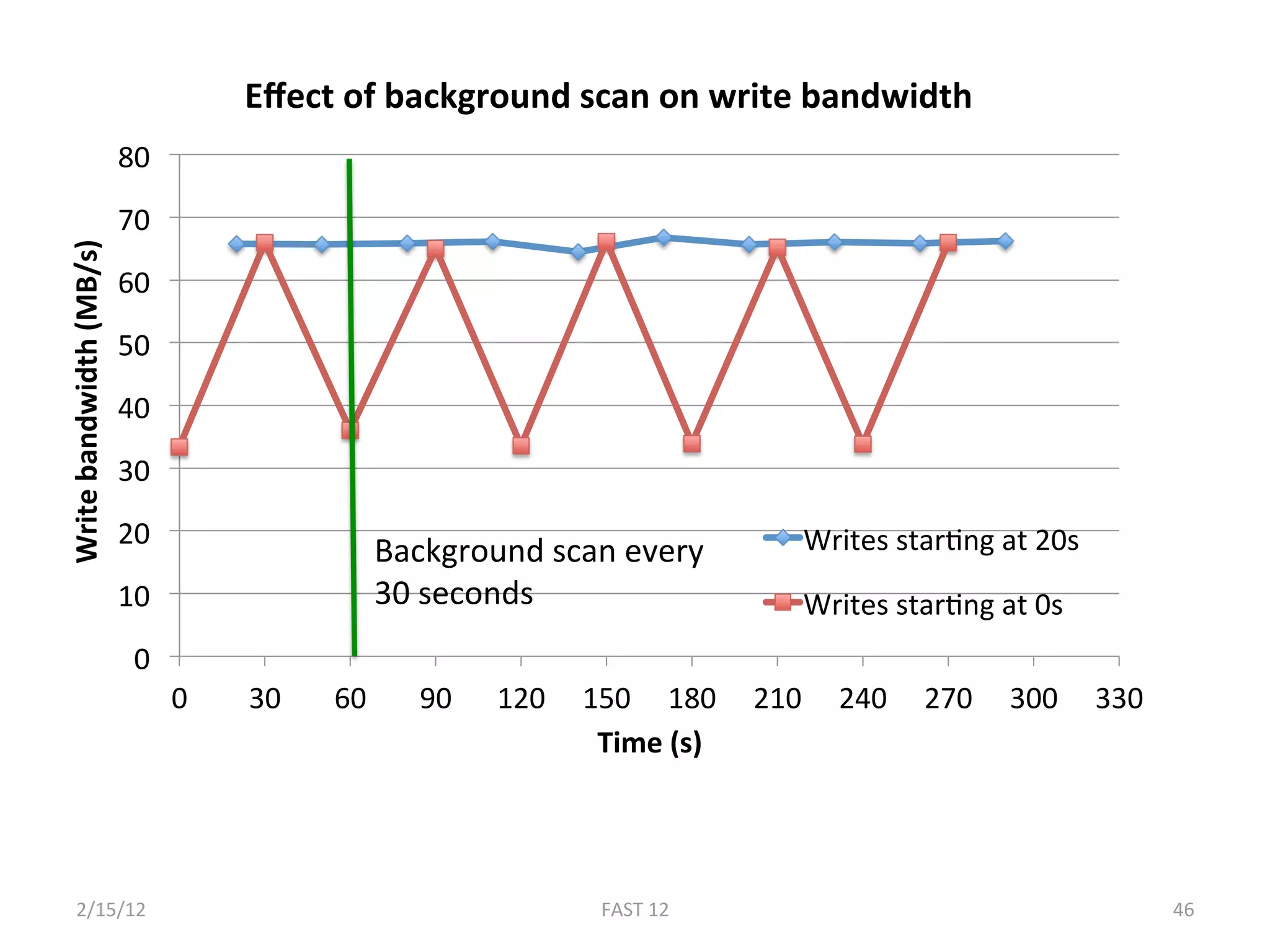
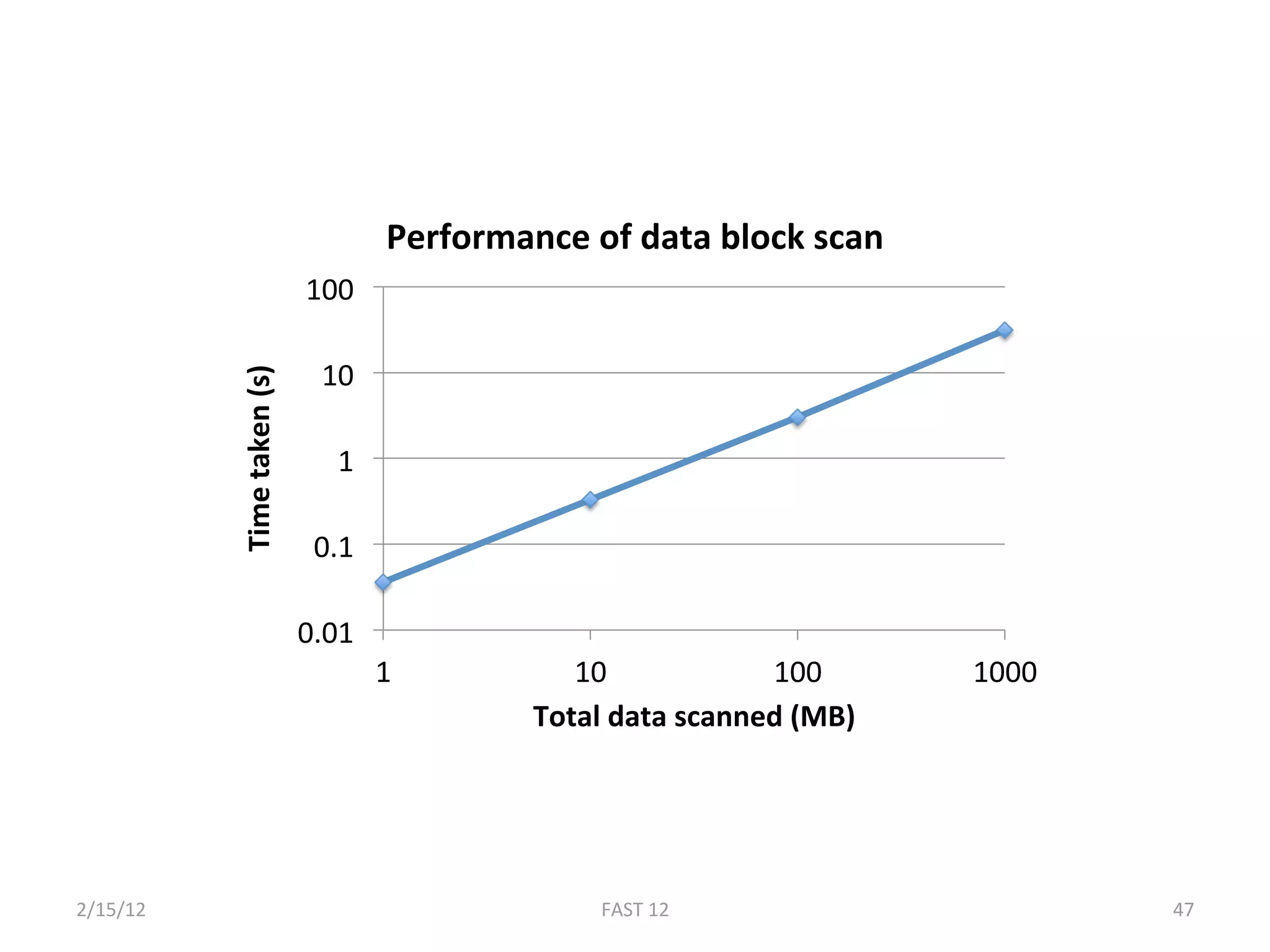
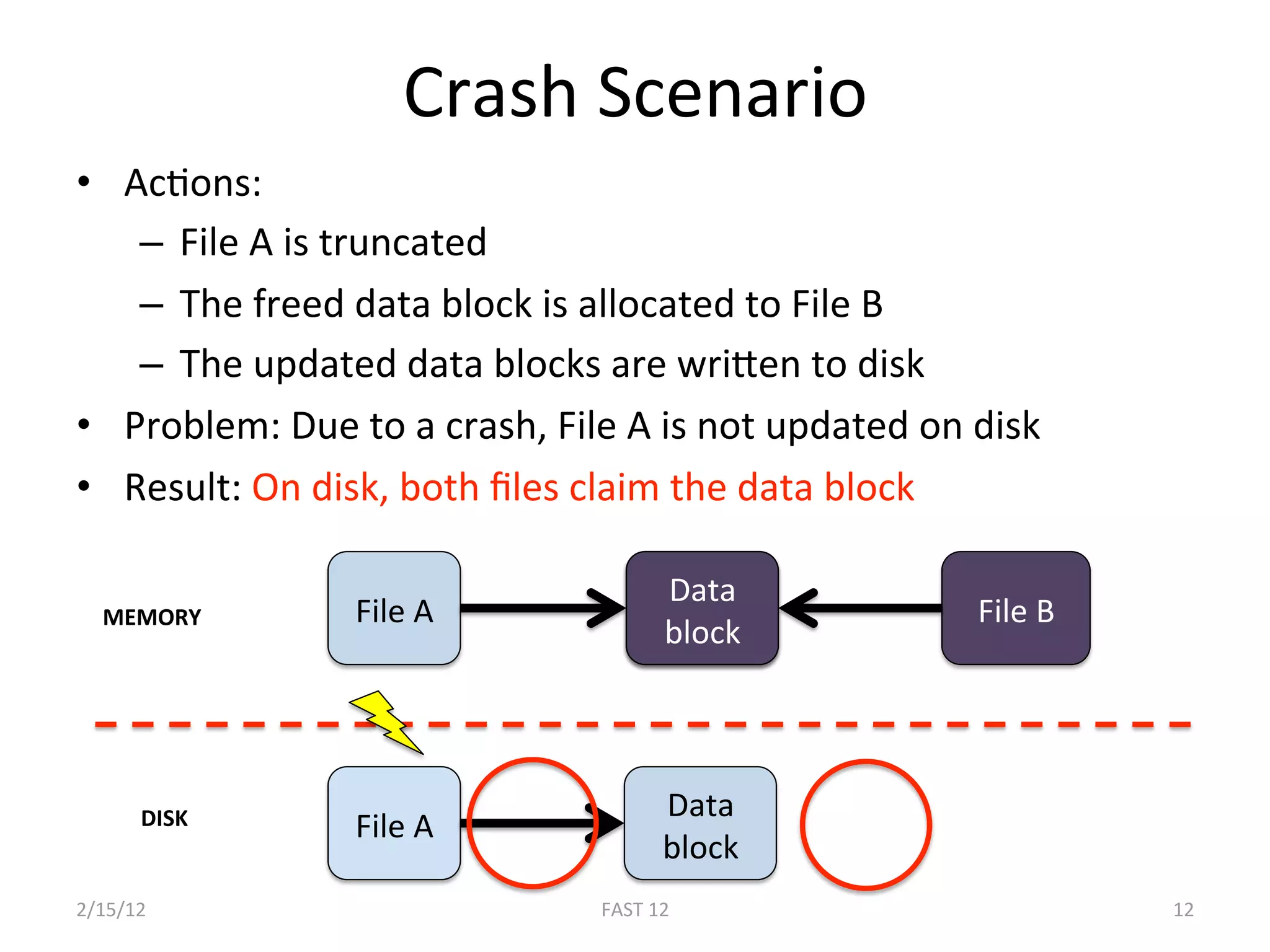
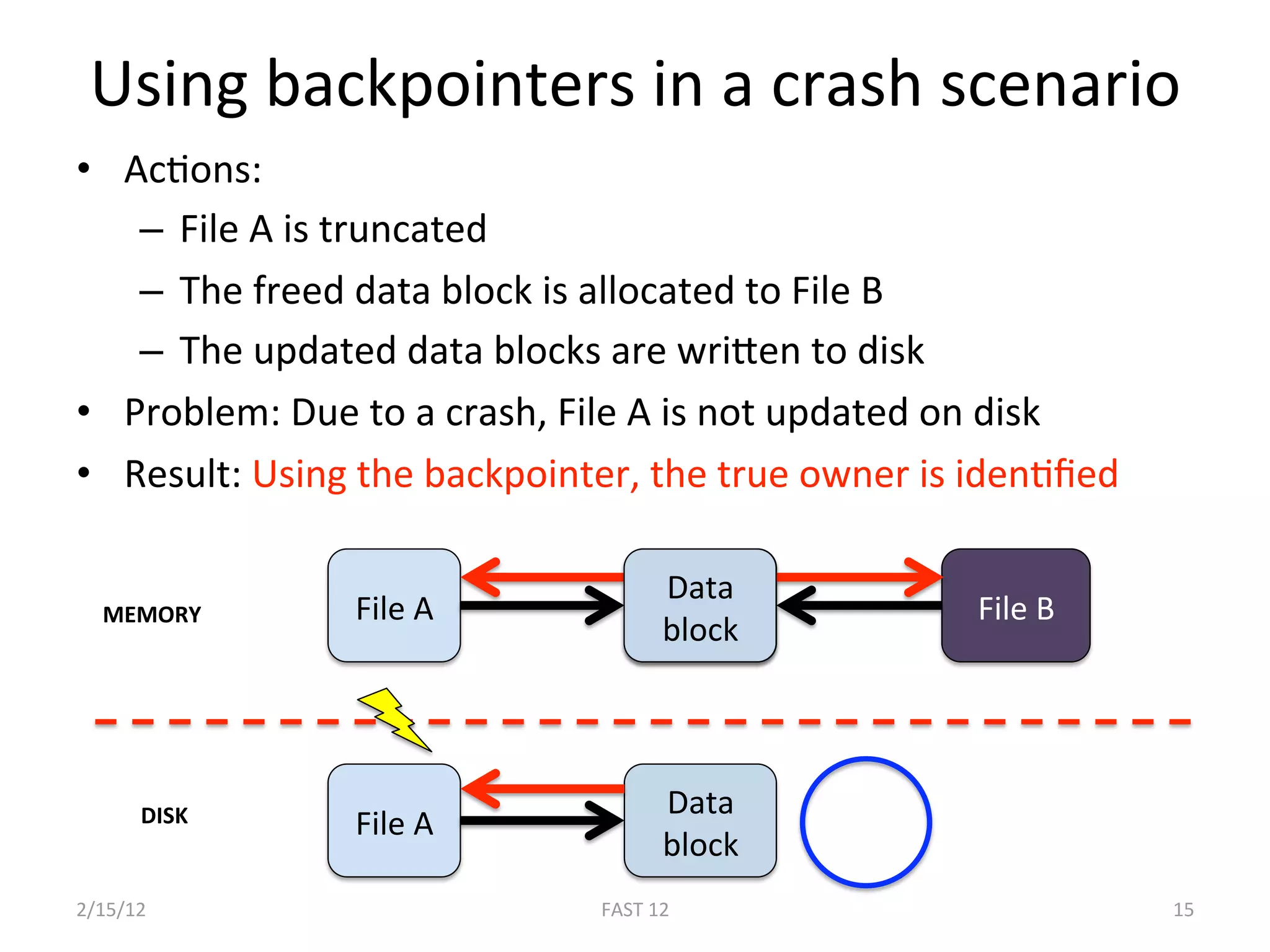
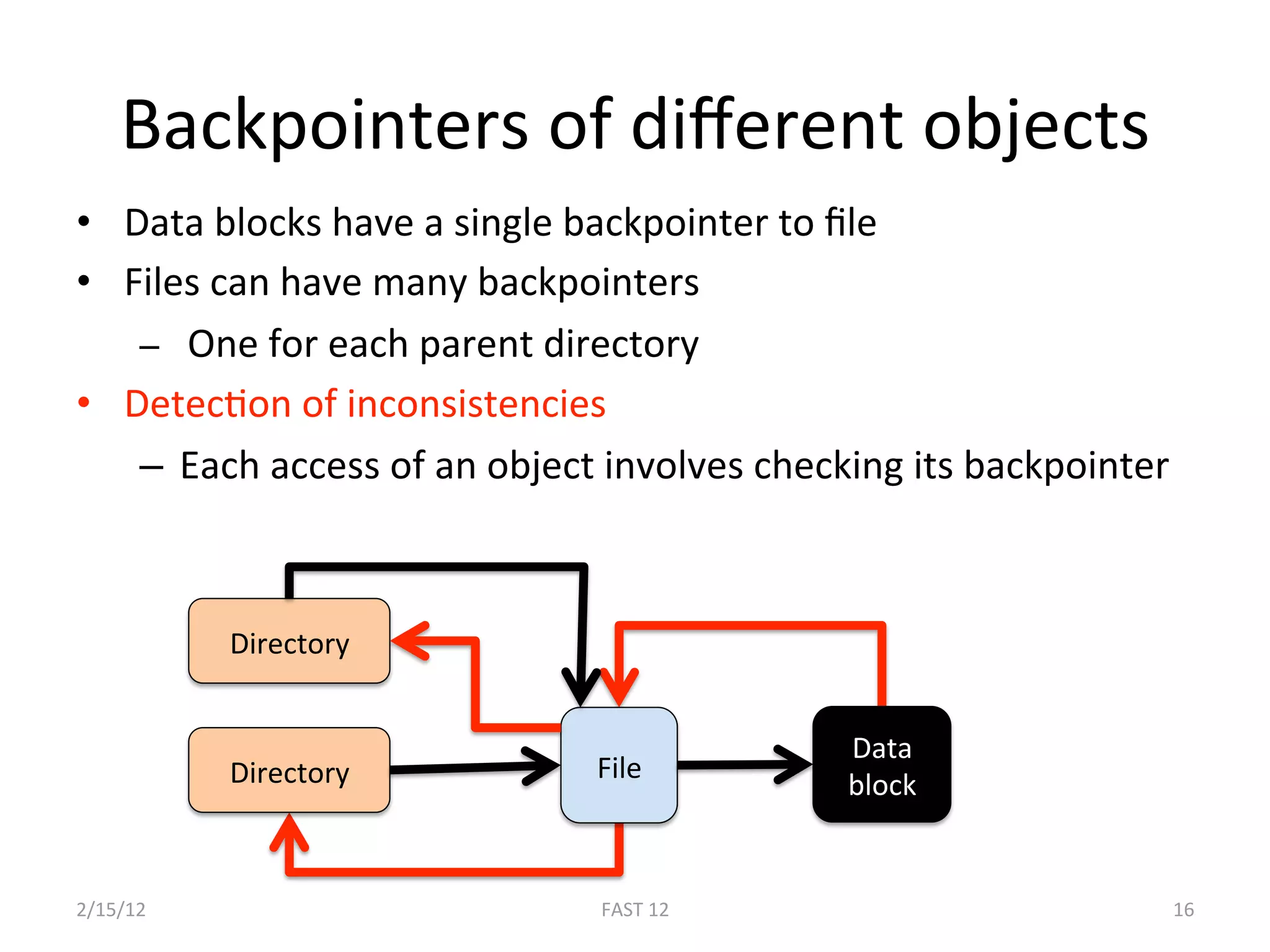
The document discusses the challenge of ensuring crash consistency in file systems, presenting a no-order file system (nofs) that utilizes backpointer-based consistency (bbc) for strong reliability without the need for strict write ordering. It contrasts lazy and eager approaches to disk writing, highlighting the performance and complexity implications of each. The results show that nofs can maintain consistency comparable to existing systems like ext2 and ext3, while simplifying the process and avoiding reliance on potentially untrustworthy lower-level storage commands.


![SoluBon #1: Lazy, opBmisBc approach
• Write blocks to disk in any order
– Fix inconsistencies upon reboot
• Advantage: Simple, High performance
• Disadvantage: Expensive recovery
• Example: ext2 with fsck [Card94]
2/15/12 FAST 12 3](https://image.slidesharecdn.com/nofs-fast12-121104201550-phpapp02/75/Consistency-Without-Ordering-3-2048.jpg)
![SoluBon #2: Eager, pessimisBc approach
• Carefully order writes to disk
• Advantage: Quick recovery
• Disadvantage: Perpetual performance penalty
• Examples
– SoE updates (FFS) [Ganger94]
– Journaling (CFS) [Hangmann87]
– Copy‐on‐write (ZFS) [Bonwick04]
2/15/12 FAST 12 4](https://image.slidesharecdn.com/nofs-fast12-121104201550-phpapp02/75/Consistency-Without-Ordering-4-2048.jpg)








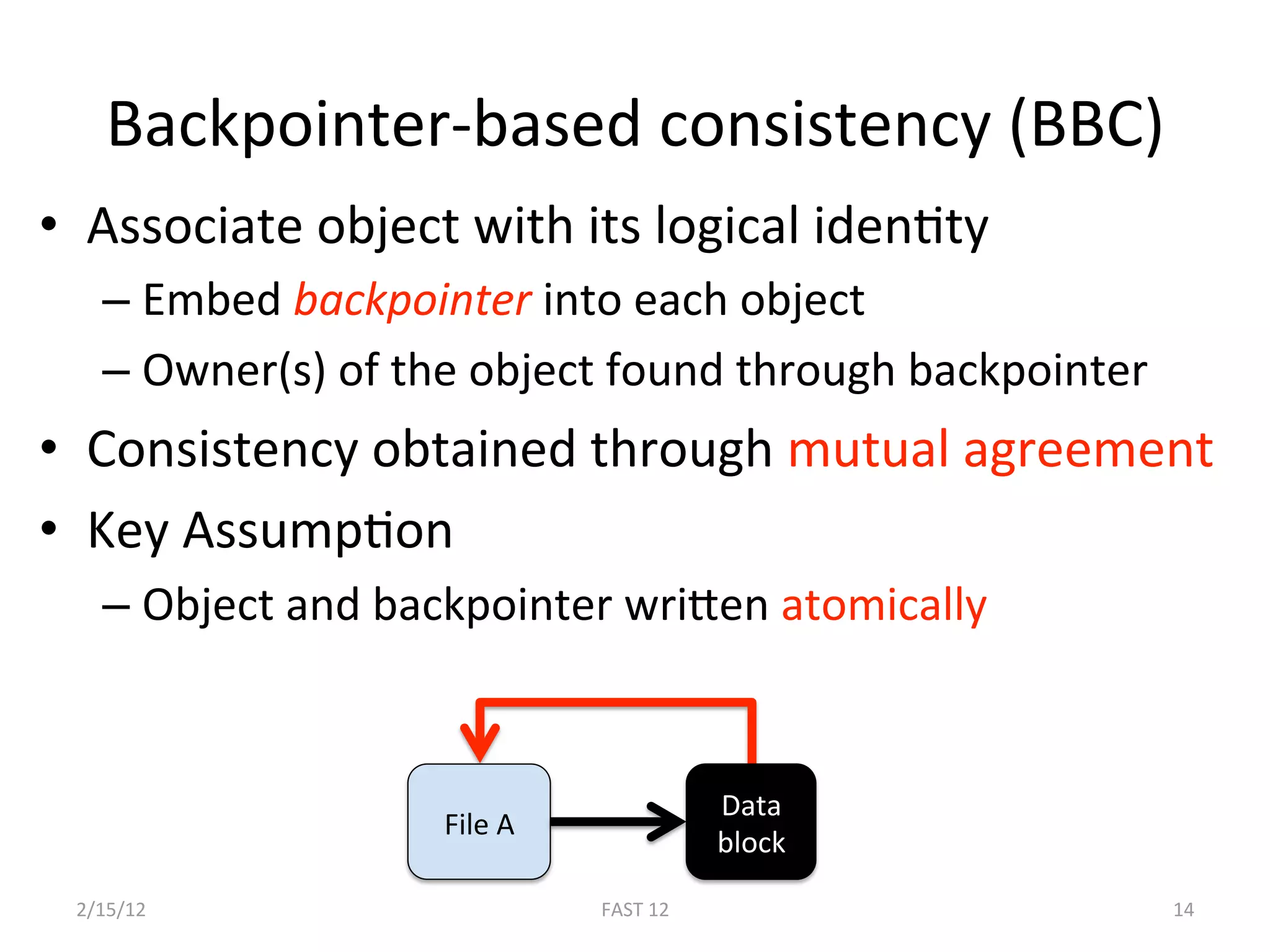
![Formal Model of BBC
• Extended a formal model for file systems with
backpointers [Sivathanu05]
• Defined the level of consistency provided by BBC
– Data consistency
• Proved that a file system with backpointers
provides data consistency
2/15/12 FAST 12 17](https://image.slidesharecdn.com/nofs-fast12-121104201550-phpapp02/75/Consistency-Without-Ordering-17-2048.jpg)