











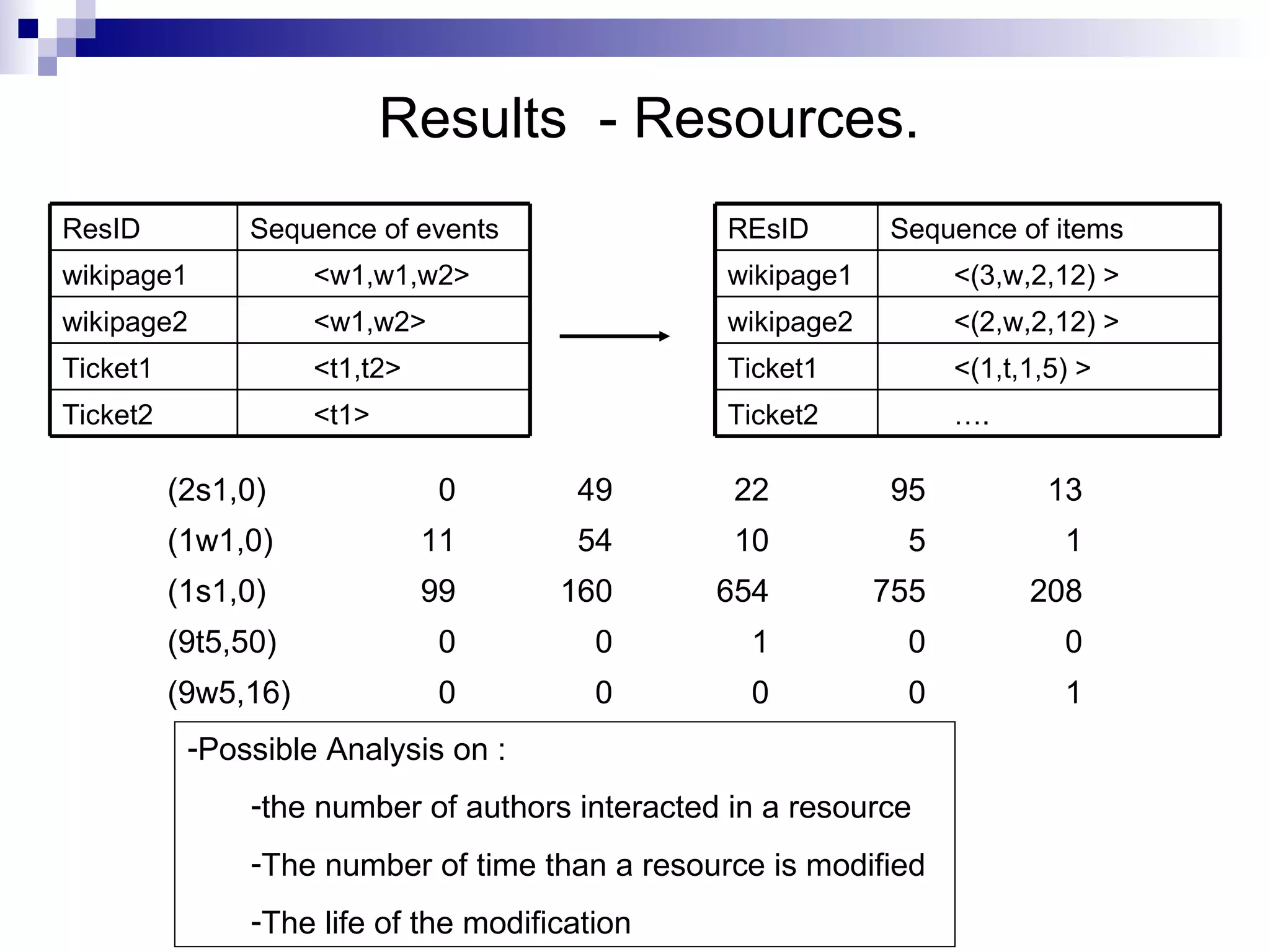
![Generation of the list of sequences Cutting by activity: Ideal situation : each event should be linked to an activity. Not yet Timeout cutting: Create a new activity if [ti, ti+1]> α with ti the time of the event i (i.e the events are considered as independant each other) Example: cutting seq at some points: [t2, t3]> α , [t6, t7]> α , [t8, t9]> α Results: 4 activities extracted Cutting by resource: A sequence for each resource <s,t> 4 <t,t> 3 <t,s,s,w> 2 <w,w> 1 Sequence ActivityID <t> Ticket2 <t,t> Ticket1 <w,w,w> wikiPage2 <w> wikiPage1 Sequence ResID](https://image.slidesharecdn.com/talk-3830-16177/75/Team-activity-analysis-visualization-16-2048.jpg)




The document describes an activity analysis and visualization project with the following objectives: 1. Build a system to support groups in learning how to work more effectively through visualizing collaboration data logs. 2. Develop different types of visualizations like activity radars and interaction networks to provide insights into participation, interactions, and timelines of events. 3. Apply data mining techniques to find frequent patterns and sequences of events that characterize aspects of teamwork.











































































