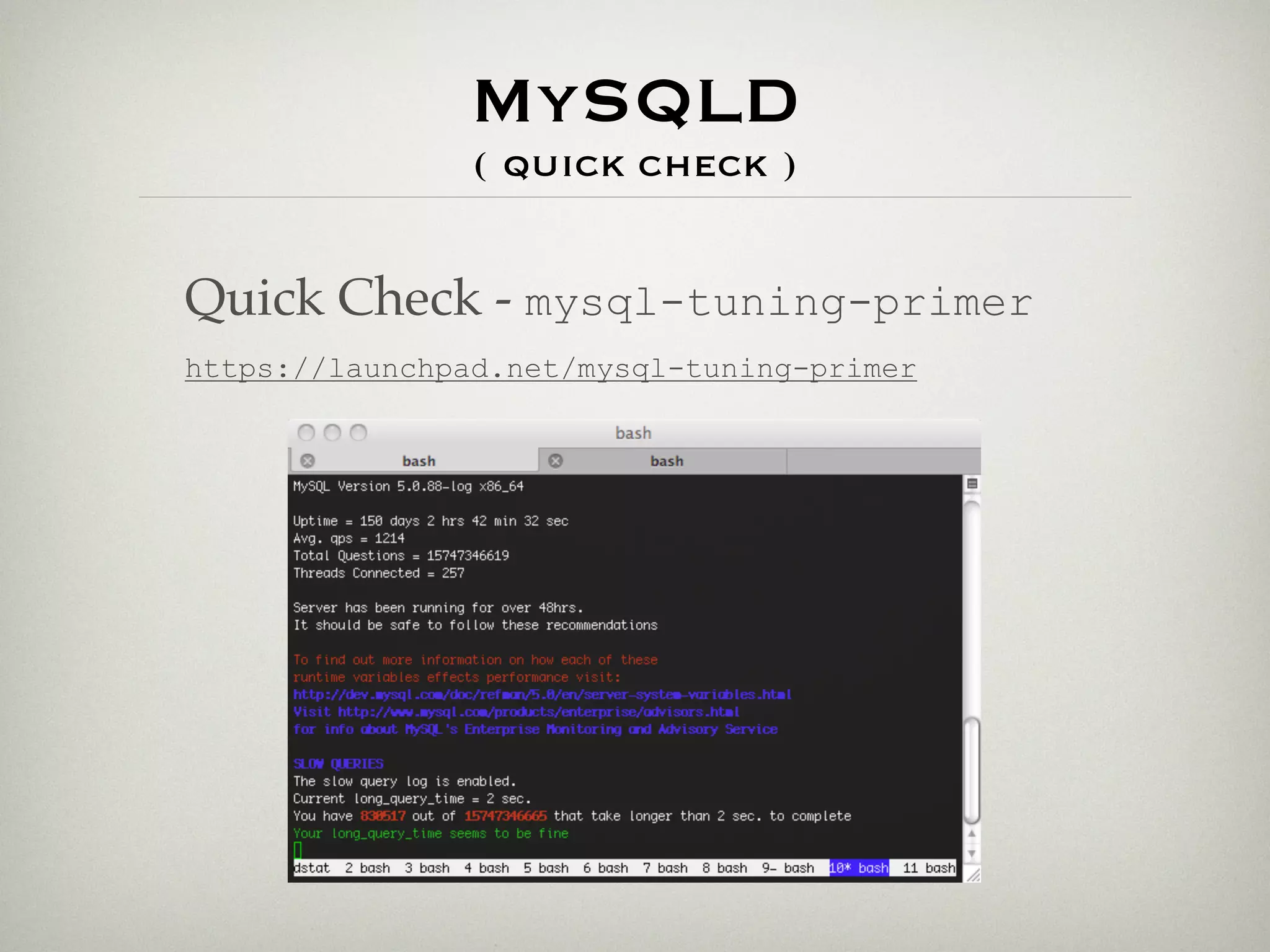
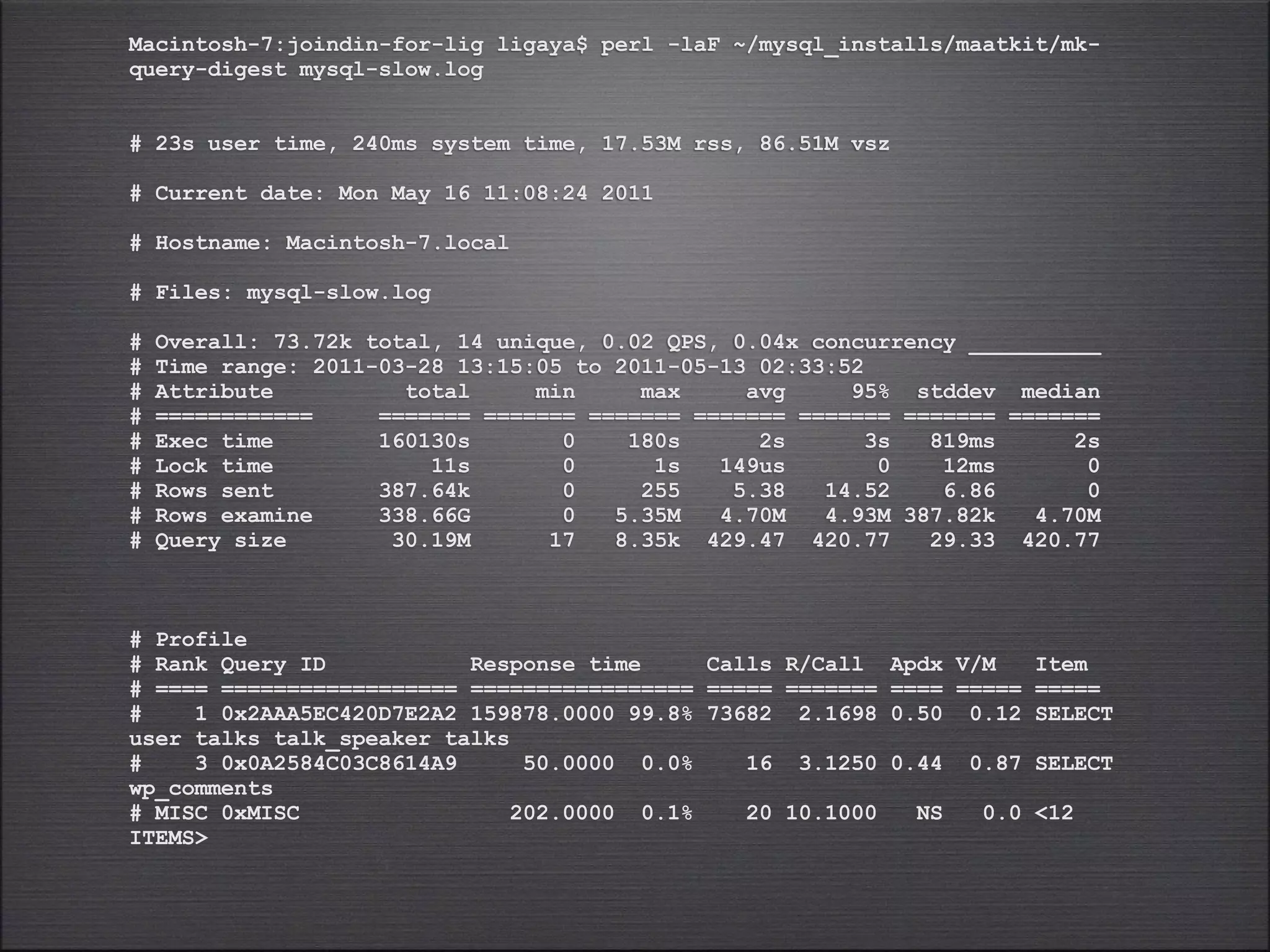
The slow query log aggregates queries that took longer than a threshold to run and examines more than a minimum number of rows. Tools like mk-query-digest and mysqldumpslow can analyze the slow query log to provide summaries of the longest running queries, number of calls, and other metrics to help identify optimization opportunities. The top query in this example was a SELECT statement joining multiple tables that accounted for over 99% of the total execution time recorded in the log.


































![MySQLD
( in depth 2/11 )
Values with out timeframe are
meaningless.
10:21:08 rderoo@mysql09:mysql [1169]> SHOW GLOBAL STATUS LIKE 'Uptime';
+---------------+----------+
| Variable_name | Value |
+---------------+----------+
| Uptime | 12973903 |
+---------------+----------+
1 row in set (0.00 sec)
That’s about 150 days. :)](https://image.slidesharecdn.com/tutorial-110526063714-phpapp01/75/DPC-Tutorial-37-2048.jpg)

![MySQLD
( in depth 4/11 )
Temporary Tables:
How big?
17:54:33 rderoo@mysql09:event [1185]> SHOW GLOBAL VARIABLES LIKE '%_table_size';
+---------------------+----------+
| Variable_name | Value |
+---------------------+----------+
| max_heap_table_size | 67108864 |
| tmp_table_size | 67108864 |
+---------------------+----------+
2 rows in set (0.00 sec)
How many?
17:55:09 rderoo@mysql09:event [1186]> SHOW GLOBAL STATUS LIKE '%_tmp%tables';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| Created_tmp_disk_tables | 156 |
| Created_tmp_tables | 278190736 |
+-------------------------+-----------+
2 rows in set (0.00 sec)](https://image.slidesharecdn.com/tutorial-110526063714-phpapp01/75/DPC-Tutorial-39-2048.jpg)

![MySQLD
( in depth 6/11 )
open_table_cache
| Open_tables | 4094 |
| Opened_tables | 12639 |
| Uptime | 12980297 |
• This yields a rate of ~85 table opens per day, a bit high...
20:52:22 rderoo@mysql09:mysql [1190]> SHOW GLOBAL VARIABLES LIKE 'table_cache';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| table_cache | 4096 |
+---------------+-------+
• Increasing the table_cache would be advisable.](https://image.slidesharecdn.com/tutorial-110526063714-phpapp01/75/DPC-Tutorial-41-2048.jpg)














![/usr/sbin/mysqld, Version: 5.0.67-0ubuntu6.1-log ((Ubuntu)). started with:
Tcp port: 3306 Unix socket: /var/run/mysqld/mysqld.sock
Time Id Command Argument
# Time: 110328 13:15:05
# User@Host: homer[homer] @ localhost []
# Query_time: 3 Lock_time: 0 Rows_sent: 0 Rows_examined: 4452238
use confs;
select
distinct u.ID as user_id,
t.event_id,
u.username,
u.full_name
from
user u,
talks t,
talk_speaker ts
where
u.ID <> 6198 and
u.ID = ts.speaker_id and
t.ID = ts.talk_id and
t.event_id in (
select
distinct t.event_id
from
talk_speaker ts,
talks t
where
ts.speaker_id = 6198 and
t.ID = ts.talk_id
)
order by rand()
limit 15;](https://image.slidesharecdn.com/tutorial-110526063714-phpapp01/75/DPC-Tutorial-56-2048.jpg)



![Count: 1 Time=180.00s (180s) Lock=0.00s (0s) Rows=1.0 (1), XXXXX[xxxxx]@localhost
SELECT SLEEP(N)
Count: 16 Time=3.12s (50s) Lock=0.00s (0s) Rows=0.9 (14), XXXXX[xxxxx]@localhost
SELECT comment_date_gmt FROM wp_comments WHERE comment_author_IP = 'S' OR
comment_author_email = 'S' ORDER BY comment_date DESC LIMIT N
Count: 5 Time=2.80s (14s) Lock=0.00s (0s) Rows=0.0 (0), XXXXX[xxxxx]@localhost
SELECT comment_ID FROM wp_comments WHERE comment_post_ID = 'S' AND ( comment_author
= 'S' OR comment_author_email = 'S' ) AND comment_content = 'S' LIMIT N
Count: 73682 Time=2.17s (159867s) Lock=0.00s (11s) Rows=5.4 (396223),
XXXXX[xxxxx]@localhost
select
distinct u.ID as user_id,
t.event_id,
u.username,
u.full_name
from
user u,
talks t,
talk_speaker ts
where
u.ID <> N and
u.ID = ts.speaker_id and
t.ID = ts.talk_id and
t.event_id in (
select
distinct t.event_id
from
talk_speaker ts,
talks t
where
ts.speaker_id = N and
t.ID = ts.talk_id
)
order by rand()
limit N](https://image.slidesharecdn.com/tutorial-110526063714-phpapp01/75/DPC-Tutorial-61-2048.jpg)

![EXPLAIN Basics
• Syntax: EXPLAIN [EXTENDED]
SELECT select_options
• Displays information from the
optimizer about the query execution
plan
• Works only with SELECT statements](https://image.slidesharecdn.com/tutorial-110526063714-phpapp01/75/DPC-Tutorial-64-2048.jpg)







































































































