Downloaded 39 times















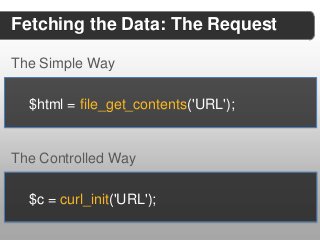
![//set up list of stop words and the final found stopped list
$common_words = array('a', ..., 'zero');
$searched_words = array();
//extract list of keywords with number of occurrences
foreach($mod_content as $word) {
$word = trim($word);
if(strlen($word) > 2 && !in_array($word, $common_words)){
$searched_words[$word]++;
}
}
arsort($searched_words, SORT_NUMERIC);](https://image.slidesharecdn.com/2013febconfoointerestdiscovery2-130226144844-phpapp02/85/Building-an-Identity-Extraction-Engine-20-320.jpg?cb=1362497069)
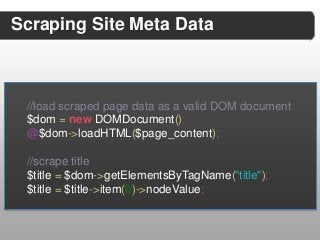
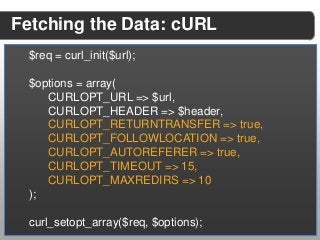
![//loop through all found meta tags
$metas = $dom->getElementsByTagName("meta");
for ($i = 0; $i < $metas->length; $i++){
$meta = $metas->item($i);
if($meta->getAttribute("property")){
if ($meta->getAttribute("property") == "og:description"){
$dataReturn["description"] = $meta->getAttribute("content");
}
} else {
if($meta->getAttribute("name") == "description"){
$dataReturn["description"] = $meta->getAttribute("content");
} else if($meta->getAttribute("name") == "keywords”){
$dataReturn[”keywords"] = $meta->getAttribute("content");
}
}
}](https://image.slidesharecdn.com/2013febconfoointerestdiscovery2-130226144844-phpapp02/85/Building-an-Identity-Extraction-Engine-22-320.jpg?cb=1362497069)


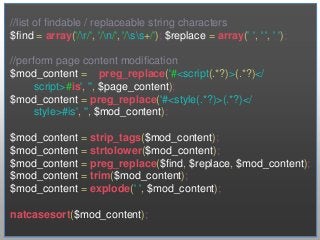
![Weighting Important Tags
//our keyword weights
$weights = array("keywords" => "3.0",
"meta" => "2.0",
"header1" => "1.5",
"header2" => "1.2");
//add modifier here
if(strlen($word) > 2 && !in_array($word, $common_words)){
$searched_words[$word]++;
}](https://image.slidesharecdn.com/2013febconfoointerestdiscovery2-130226144844-phpapp02/85/Building-an-Identity-Extraction-Engine-25-320.jpg?cb=1362497069)



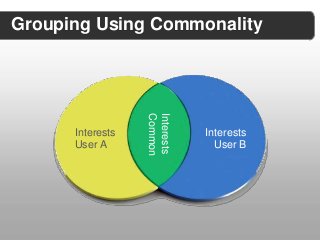


When it comes to building customized experiences for your users, the biggest key is in understanding who those users are and what they're interested in. The largest problem with the traditional method for doing this, which is through a profile system, is that this is all user-curated content, meaning that the user has the ability to enter in whatever they want and be whoever they want. While this gives people the opportunity to portray themselves how they wish to the outside world, it is an unreliable identity source because it's based on perceived identity. In this session we will take a practical look into constructing an identity entity extraction engine, using PHP, from web sources. This will deliver us a highly personalized, automated identity mechanism to be able to drive customized experiences to users based on their derived personalities. We will explore concepts such as: - Building a categorization profile of interests for users using web sources that the user interacts with. - Using weighting mechanisms, like the Open Graph Protocol, to drive higher levels of entity relevance. - Creating personality overlays between multiple users to surface new content sources. - Dealing with users who are unknown to you by combining identity data capturing with HTML5 storage mechanisms.







































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)






