





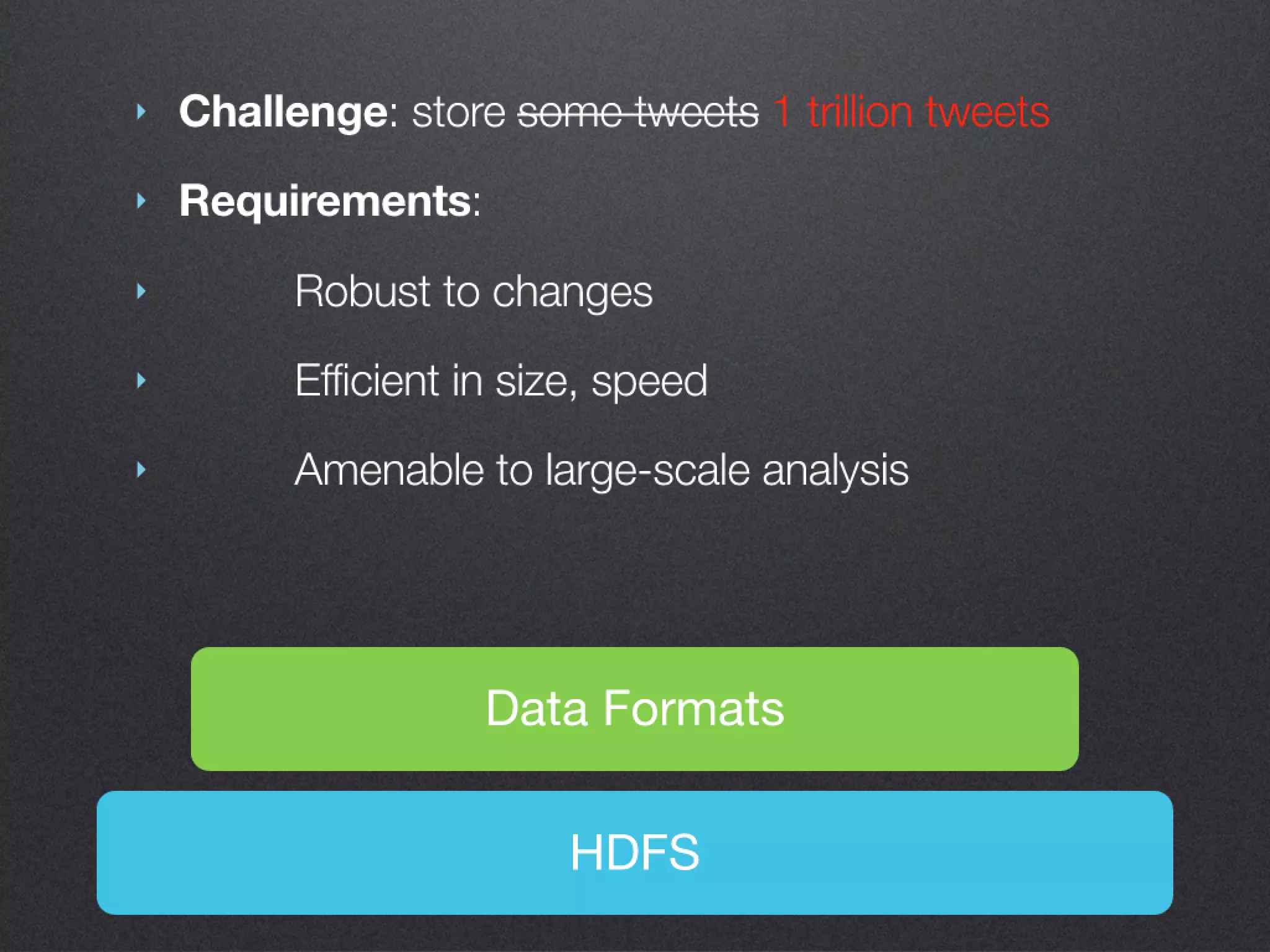

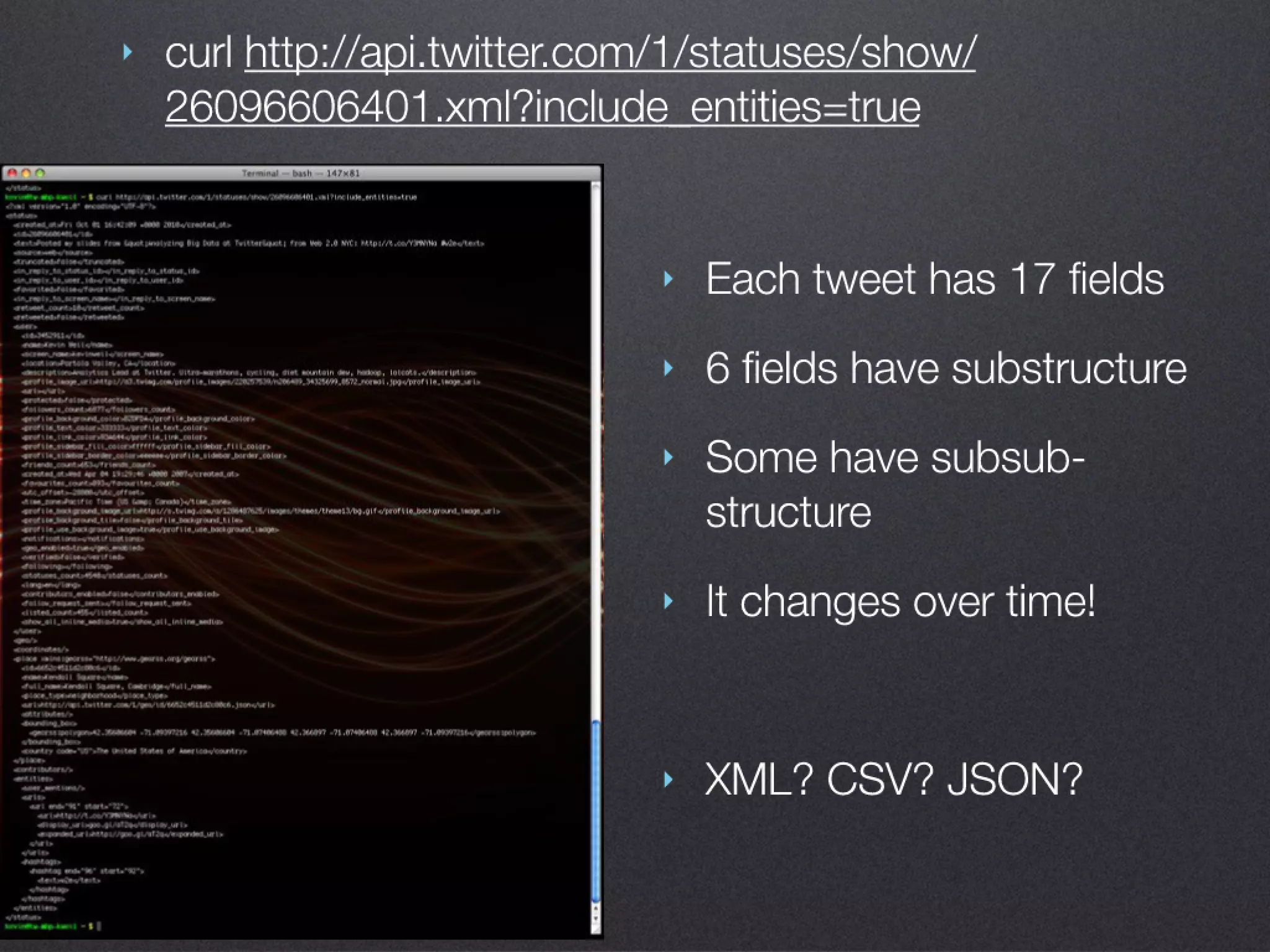











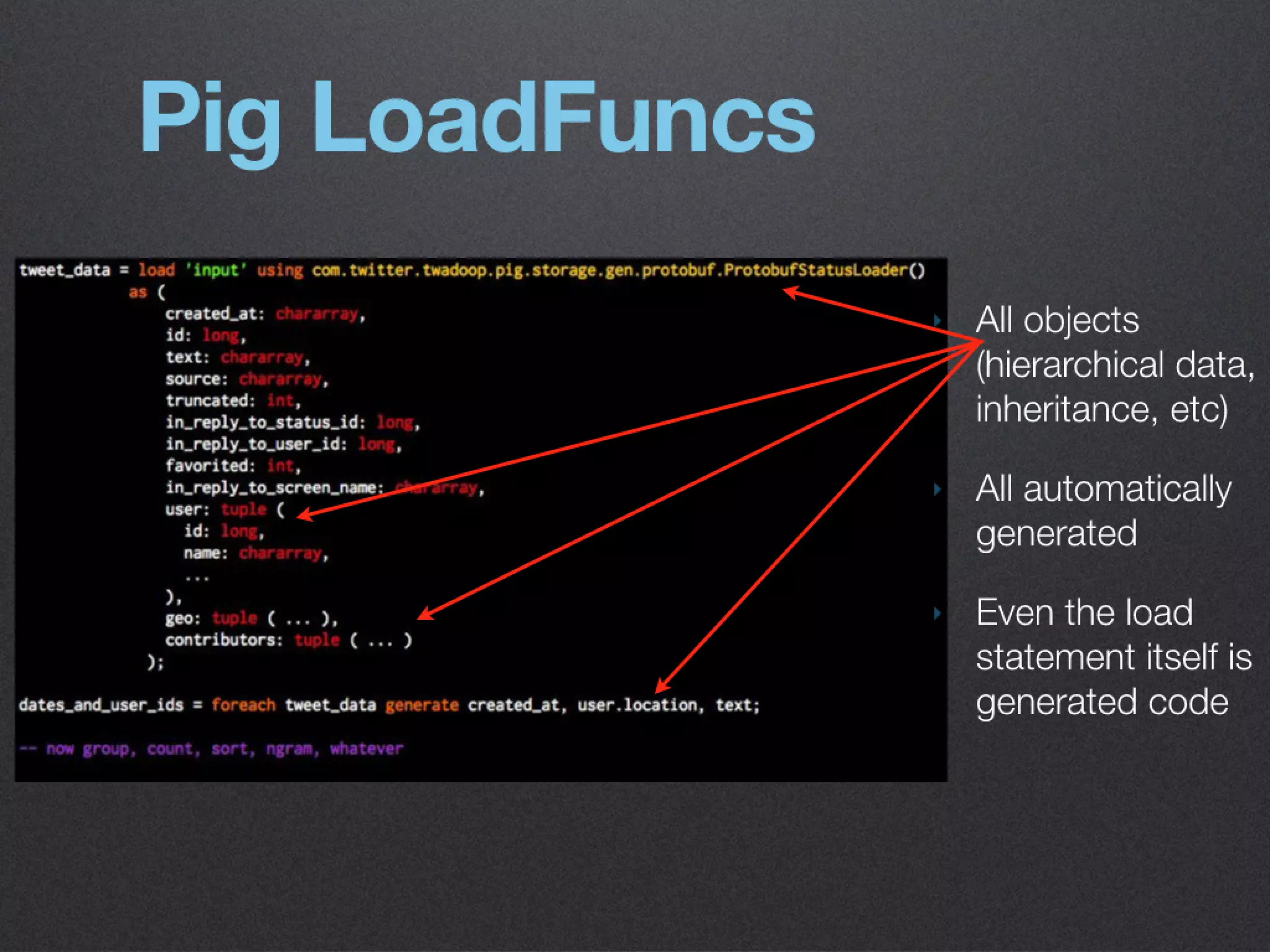










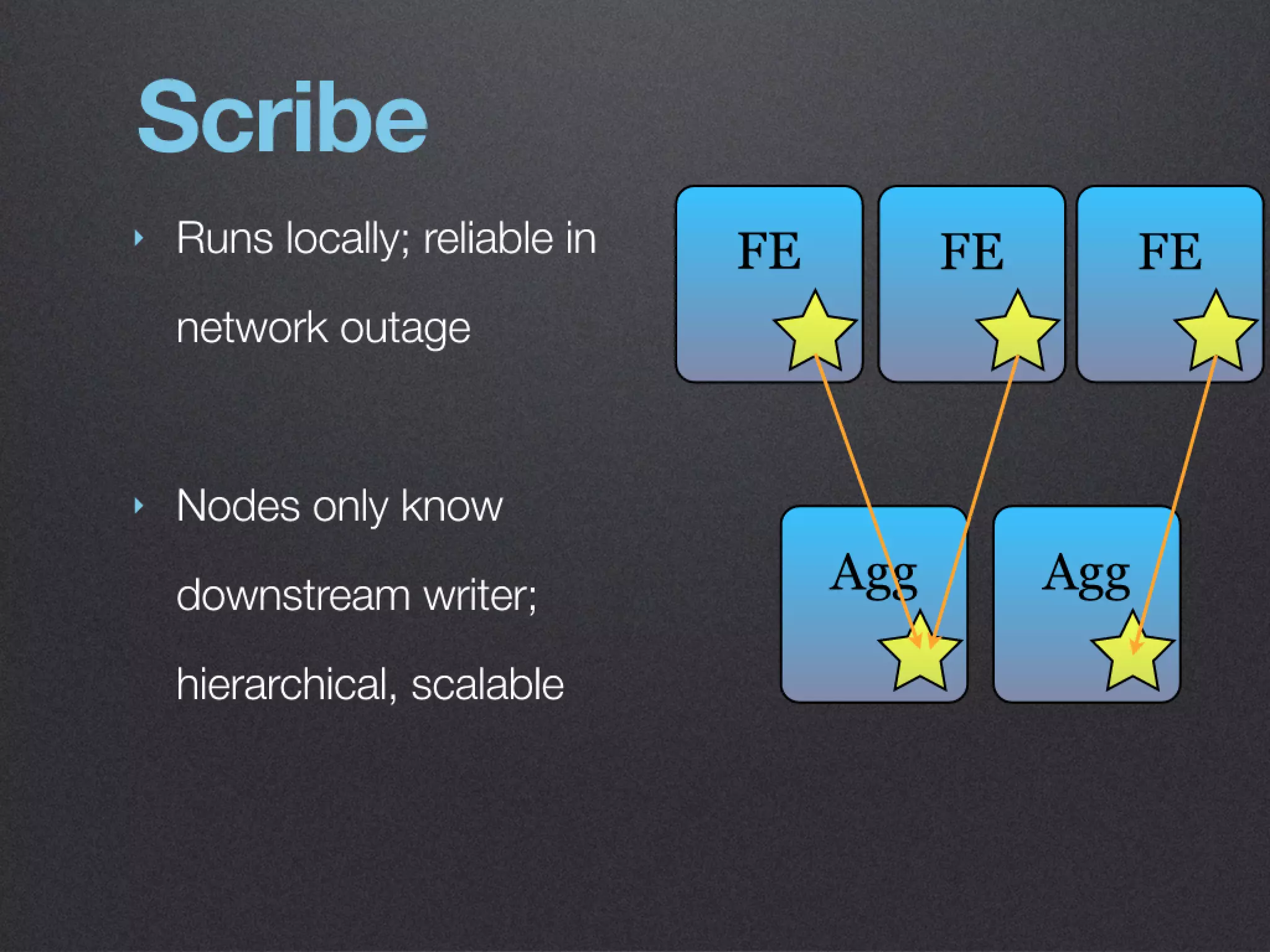
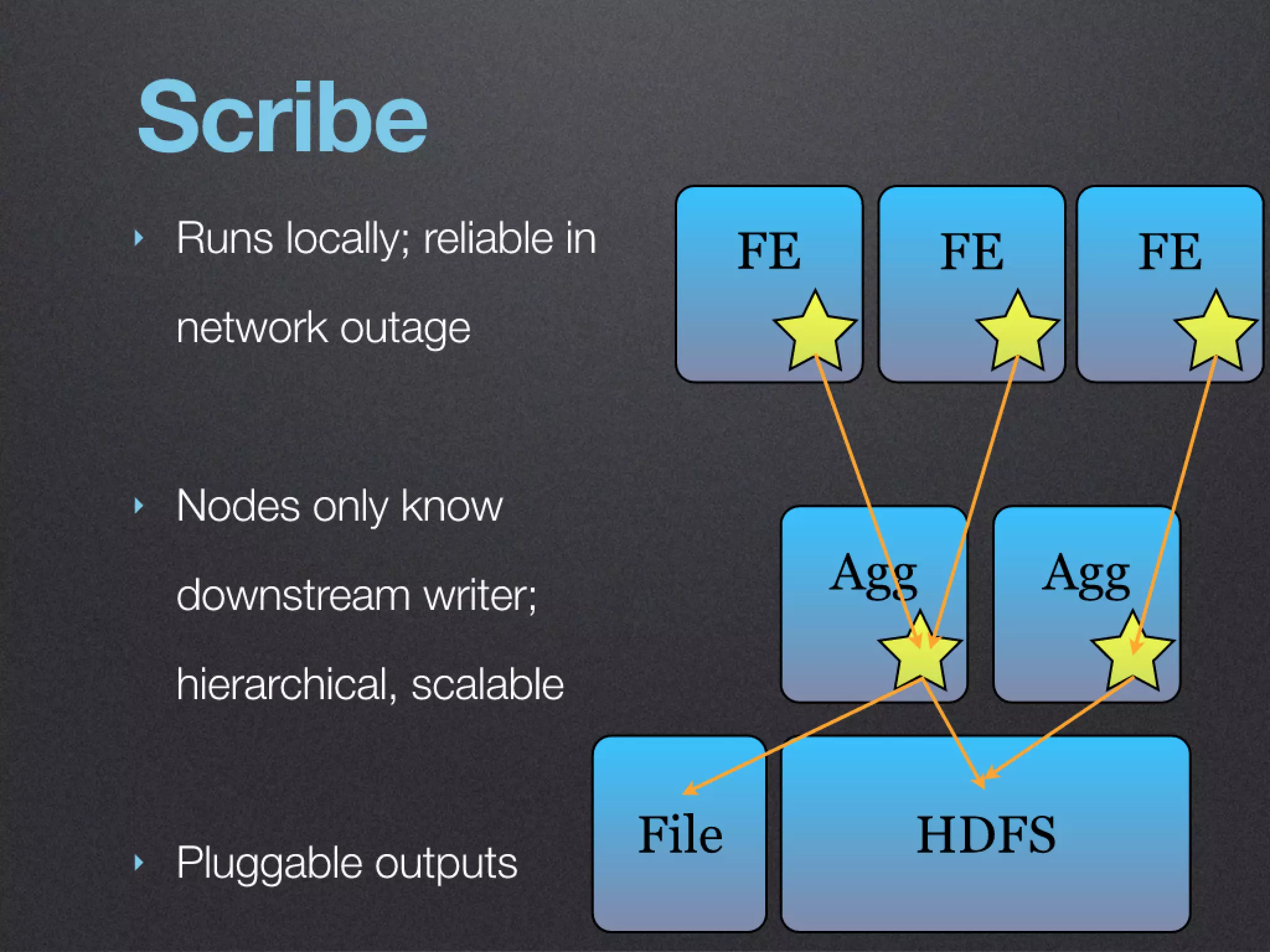

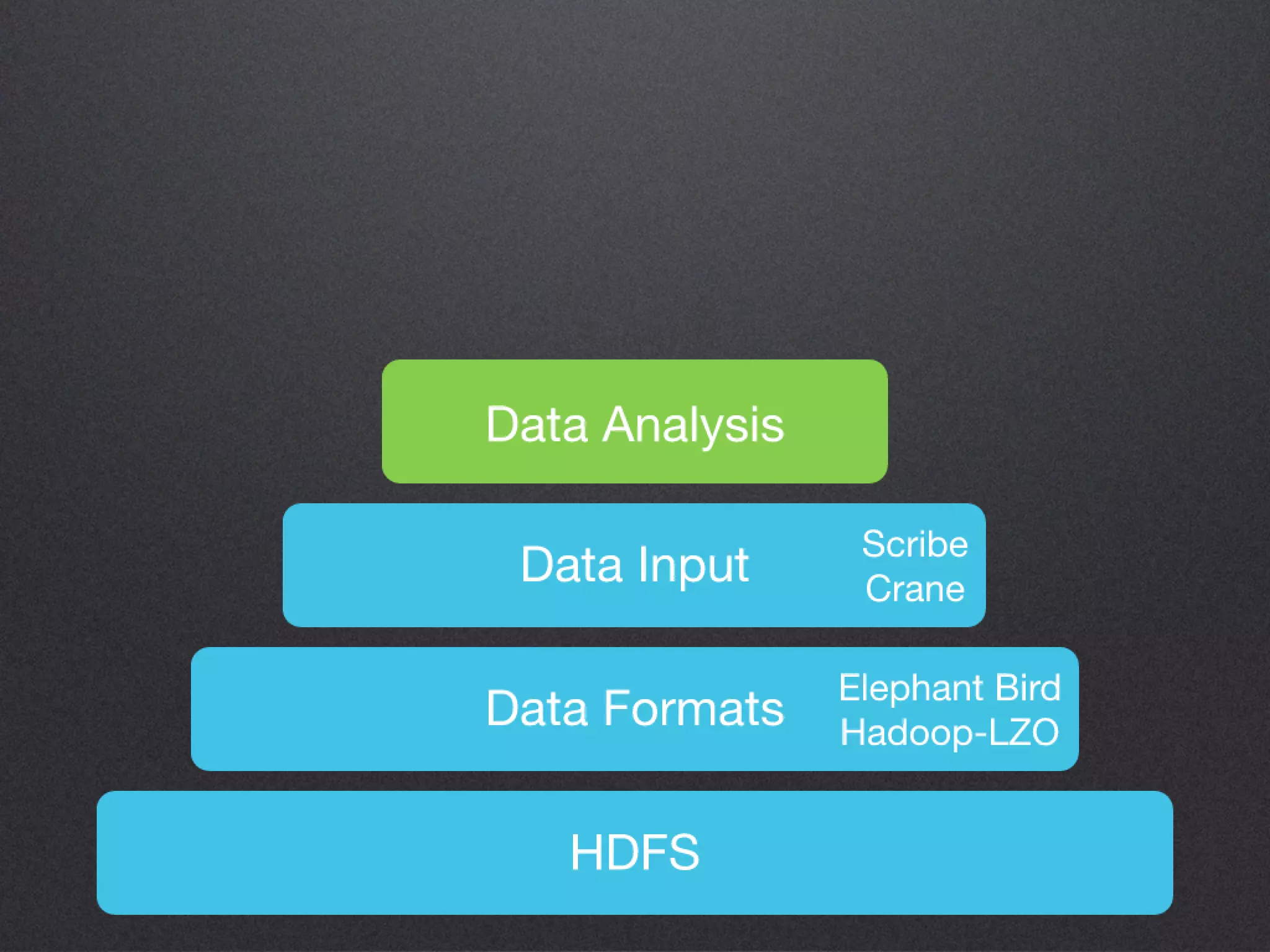









































The document discusses the benefits of exercise for mental health. Regular physical activity can help reduce anxiety and depression and improve mood and cognitive functioning. Exercise causes chemical changes in the brain that may help protect against mental illness and improve symptoms.





















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













