Downloaded 35 times



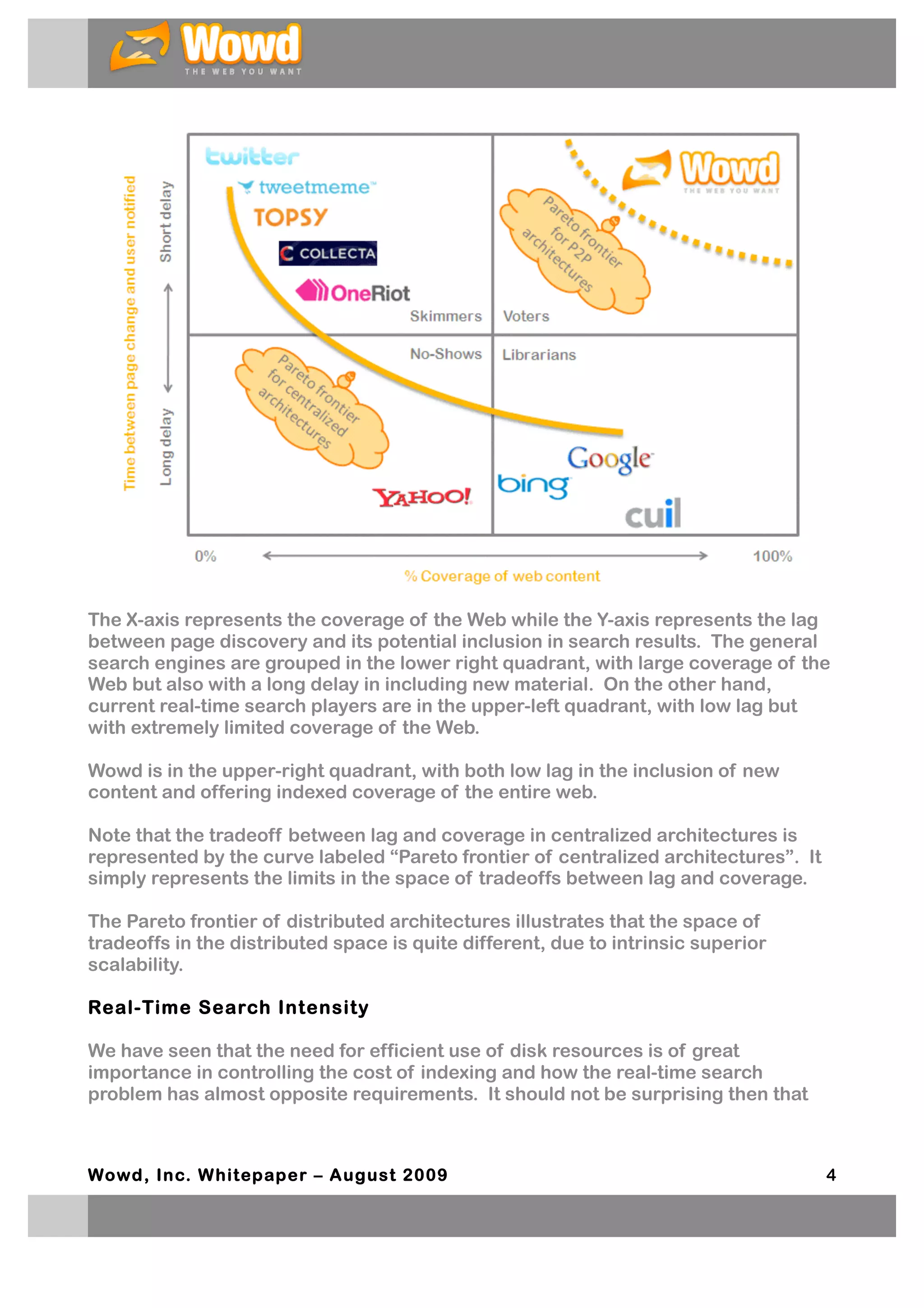




The document discusses the evolution and challenges of real-time search, highlighting the limitations of traditional search engines in delivering timely and comprehensive results. It emphasizes the need for new indexing architectures capable of scaling to the entire web while maintaining quality and freshness in search results. The proposed solution by Wowd focuses on integrating real-time search with general search functionalities, preserving older results alongside new content for enhanced user experience.


![Hadoop explained [e book]](https://cdn.slidesharecdn.com/ss_thumbnails/hadoopexplainedebook-150709174359-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


















































