Download as PDF, PPTX





























The document is an overview of data science concepts and methodologies, emphasizing the role of data scientists in solving business problems through a blend of programming, mathematics, and analytical skills. It covers various techniques in data analysis, including pattern mining, machine learning, and significance testing, as well as the importance of model complexity and ensemble learning for improving predictions. The document also touches on challenges in categorizing data and the evolution of methods such as online learning and Bayesian approaches.
Introduction to the concept of Data Science is presented by Niko Vuokko at Jyväskylä Summer School.
Data Science combines various methodologies such as databases, machine learning, and data visualization for business optimization.
A data scientist's role includes converting business problems into technical targets, developing solutions, and communicating results.
Focus on pattern mining and data analysis, emphasizing unsupervised learning for discovering interesting phenomena.
Examples of interesting data patterns involve shopping behavior, network trends, and data structures like eigens.
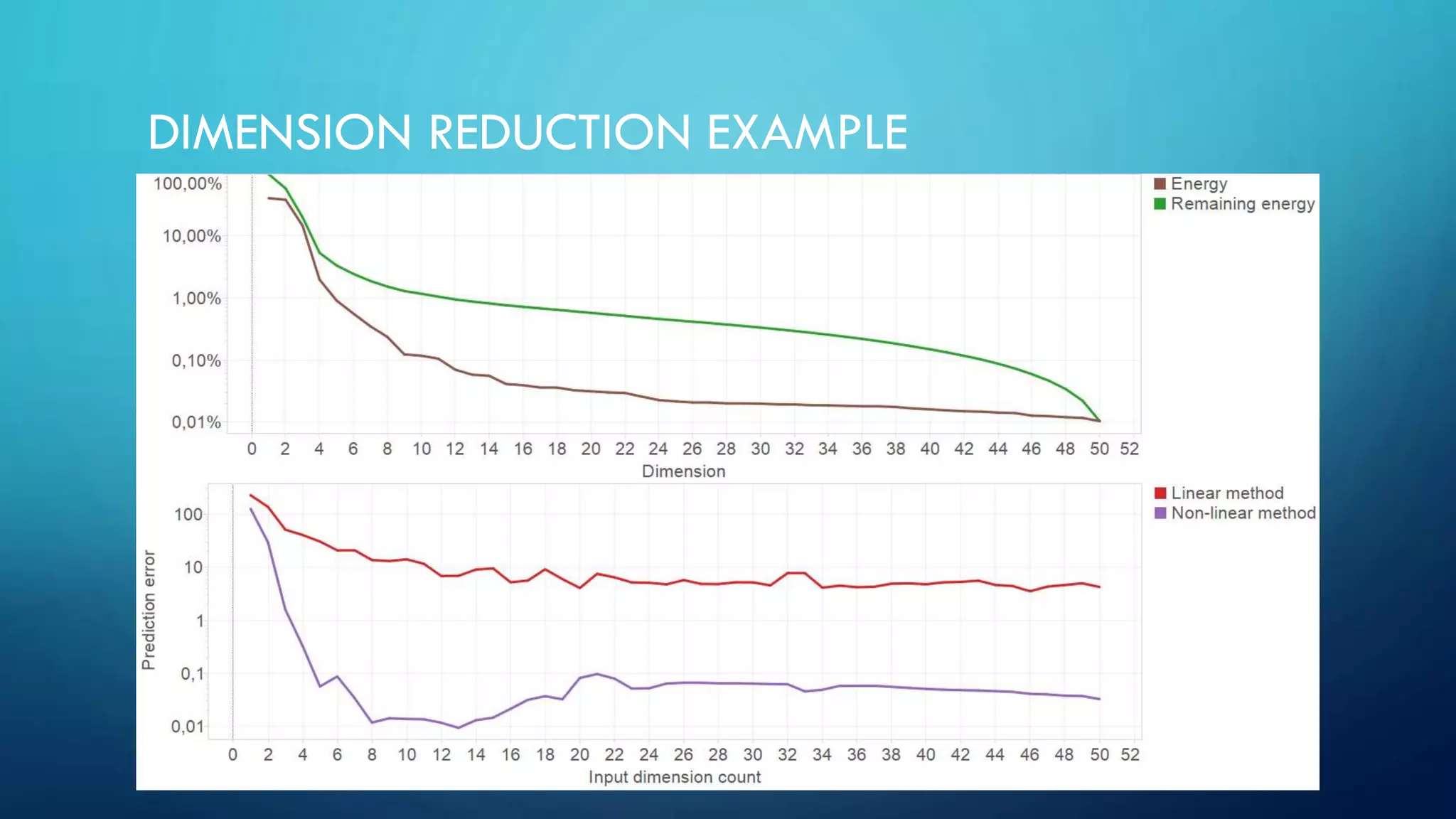
Techniques for dimension reduction are discussed, focusing on retaining essential dimensions and removing noise.
Blind source separation identifies latent factors in datasets; applications include climate change and missile guidance.
Significance testing highlights the need for correct data modeling; correlation does not imply causality.
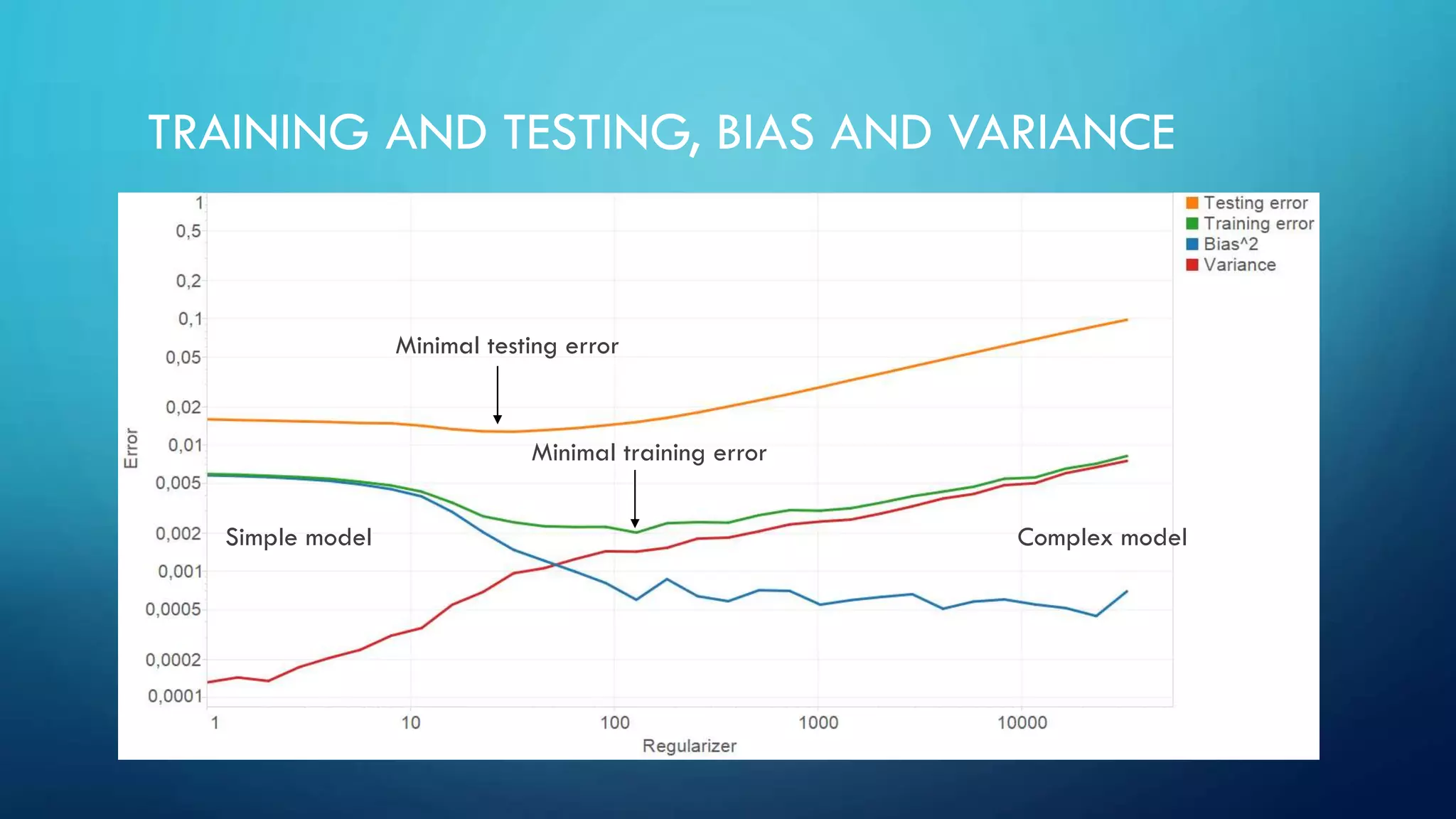
Basics of machine learning emphasize supervised, semi-supervised learning, model training, and understanding bias and variance. Model evaluation uses training and testing datasets; bias-variance trade-off is essential for performance improvement.
Kernel trick, ensemble learning methods illustrate the blending of multiple models for enhanced performance.
Randomized and online learning focus on improving model generalization; Bayesian methods offer prior parameter insights.
Final thoughts on the expertise required in data science and a recap of the content presented.
















![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

































































