Downloaded 16 times




![Scene models at time t
• Human model
– Laser scanner provide a static mesh with embedded
skeleton of each performer
[*]
• 5,000 vertices of meshes
• k-th performer’s Skeleton with
31 degrees of freedom: C tk
GND (r=3m)
• Ground plane model (fixed)
– Center of Environment
– Planar mesh with circular boundary
• Camera extrinsic parameters of i-th Kinect
– Translation, rotation: L tk
7
[*] F. Remondino: “3-D reconstruction of static human body shape from image sequence,” CVIU, Vol.93, No.1. pp.65-85](https://image.slidesharecdn.com/nakazawaeccvintrover1-121208205029-phpapp02/75/Paper-introduction-Performance-Capture-of-Interacting-Characters-with-Handheld-Kinects-7-2048.jpg)

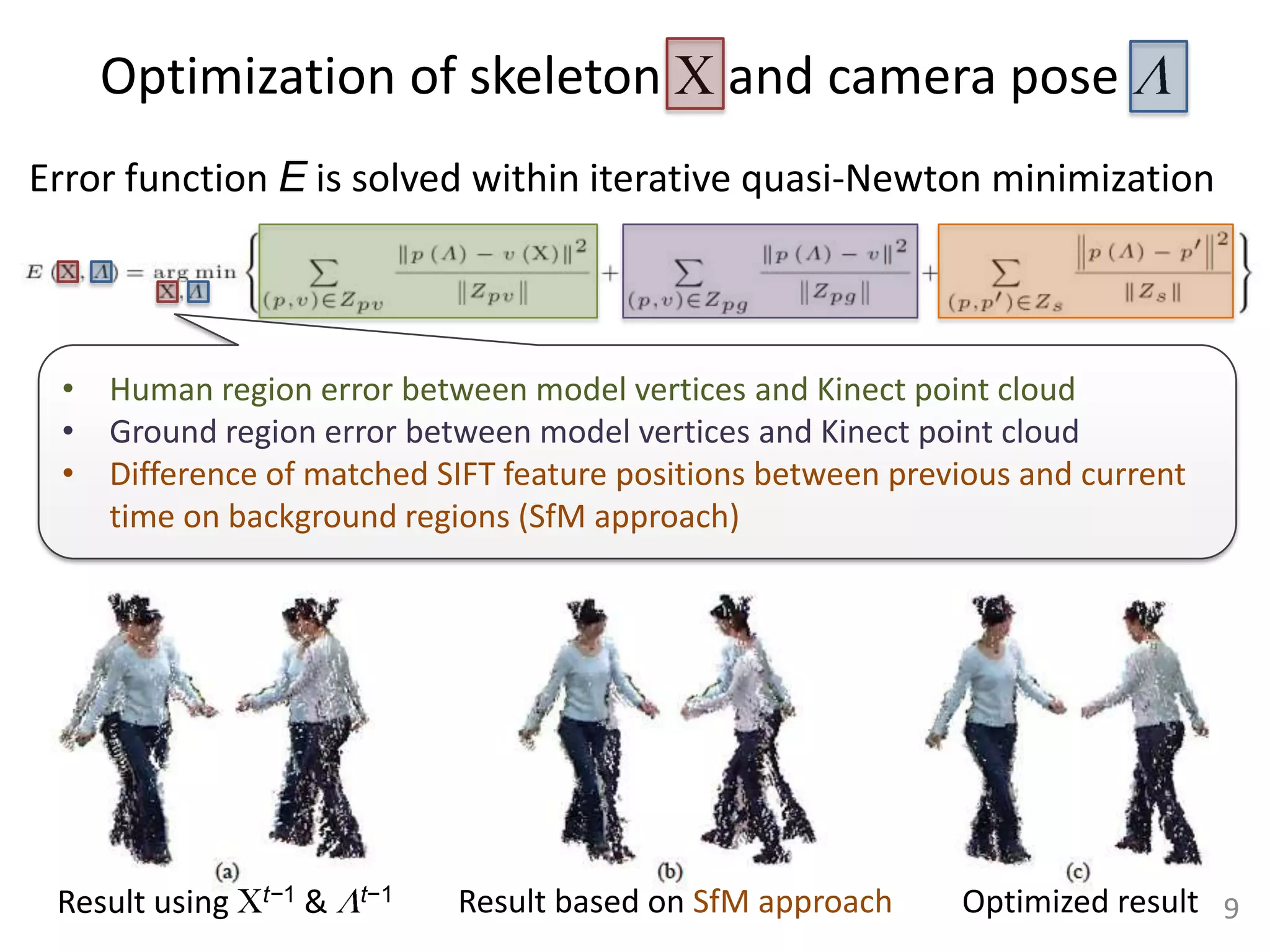





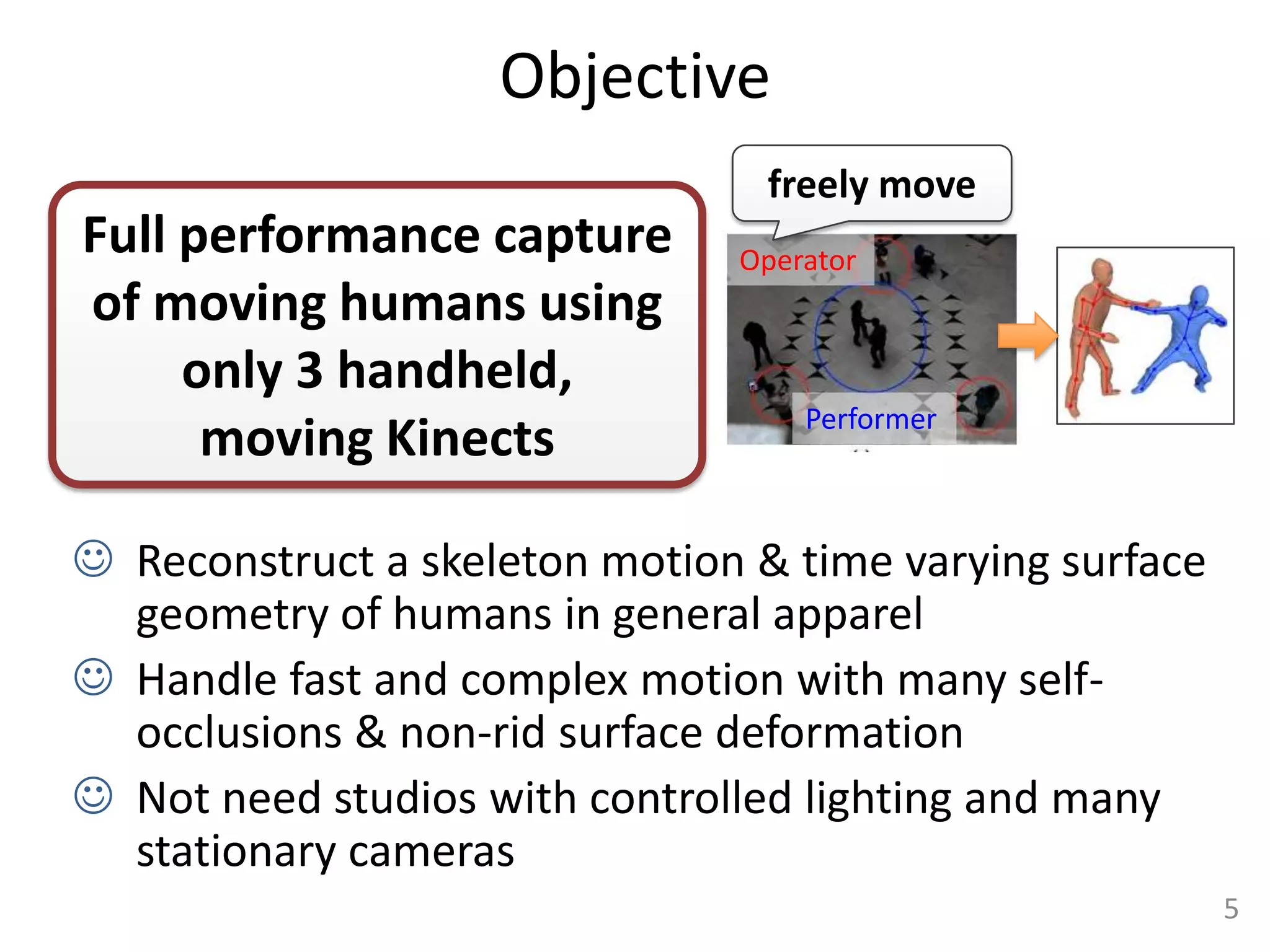
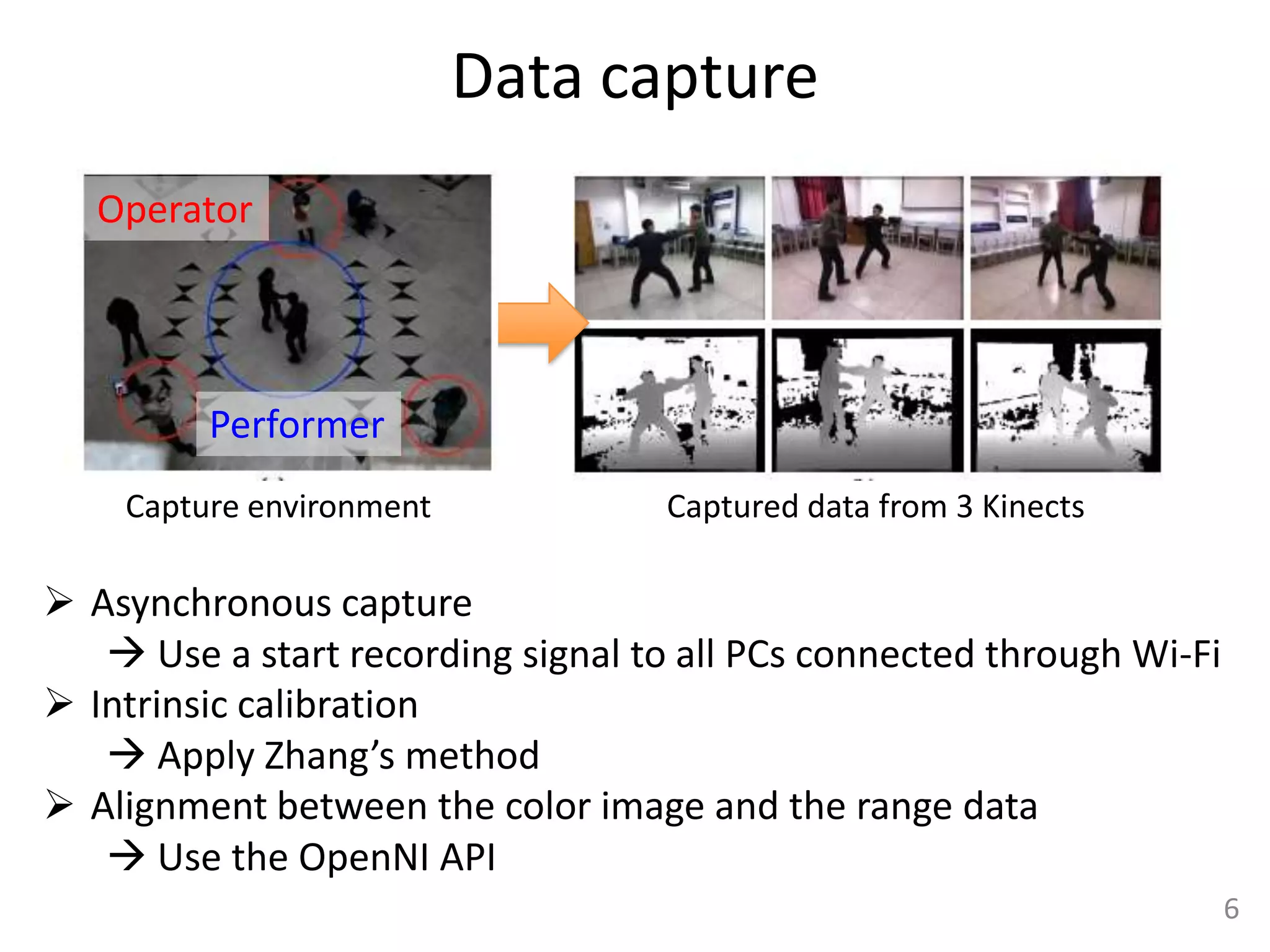
This document summarizes a paper that presents a method for capturing full performance of interacting characters using only 3 handheld Kinect sensors. The method reconstructs a skeleton motion and time-varying surface geometry of humans from the asynchronous and uncalibrated Kinect sensor data. It matches geometric data from the Kinects to a human body model and optimizes the skeleton poses and camera parameters. Non-rigid deformations of the human surface are estimated through Laplacian deformation. The method is shown to capture complex motions with self-occlusions better than traditional multi-camera motion capture systems.











![[Mmlab seminar 2016] deep learning for human pose estimation](https://cdn.slidesharecdn.com/ss_thumbnails/mucdgsomrcs8cgkh9gsp-signature-54f17826ed7e29e13653ed835b10fabd79d8e26ac84412798c7e96ef7d109006-poli-160811023645-thumbnail.jpg?width=640&height=640&fit=bounds)






















































