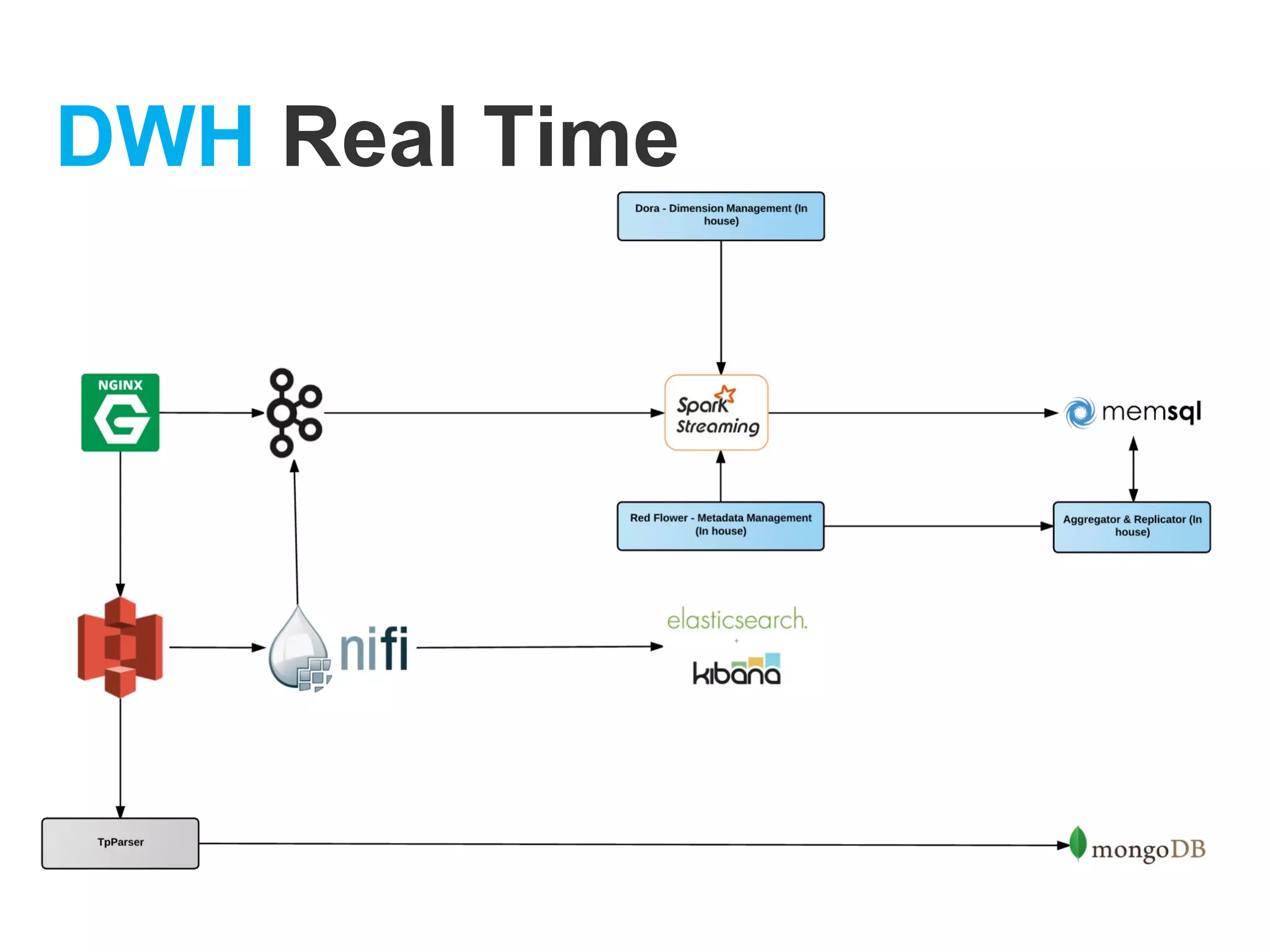
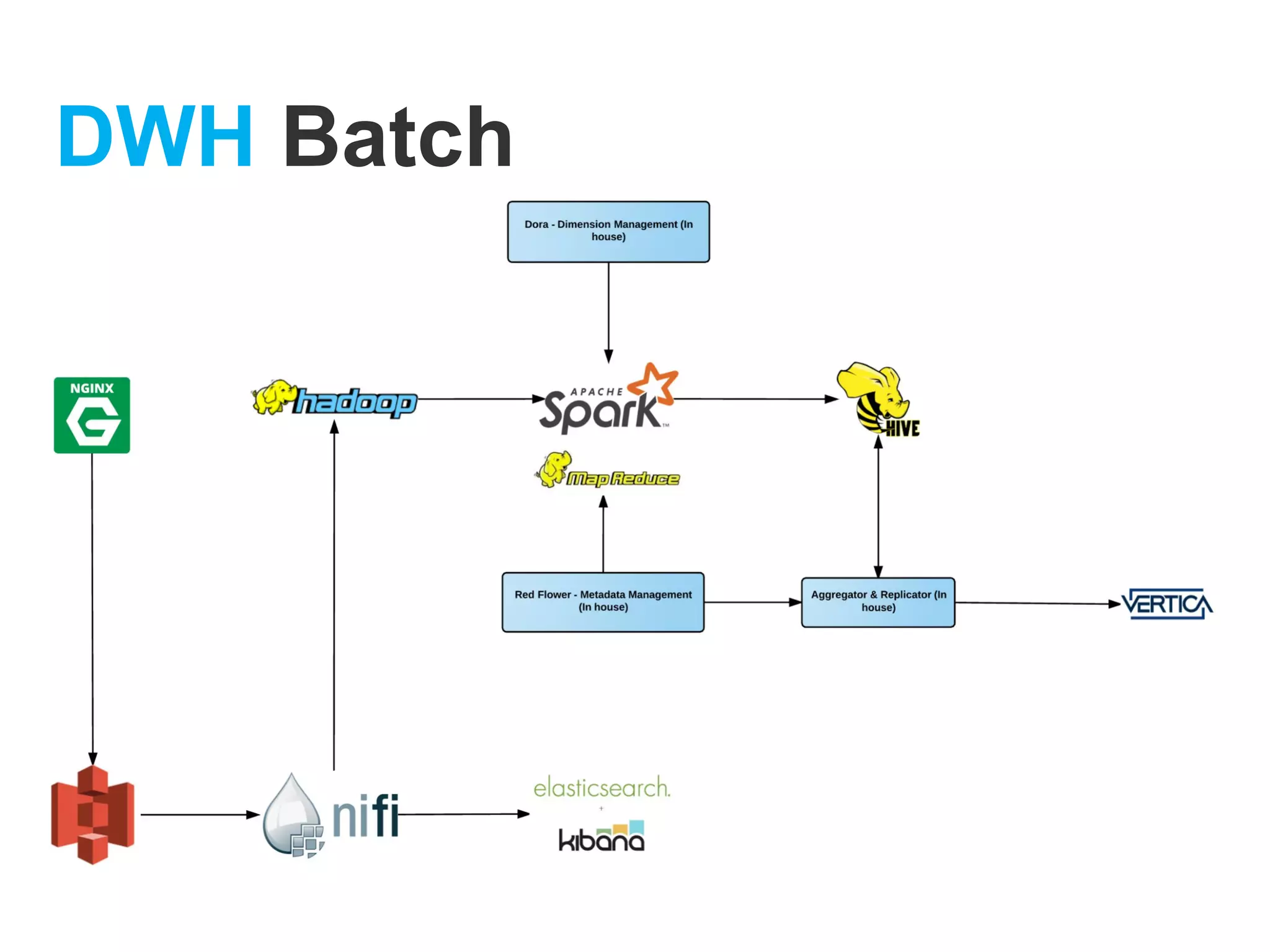
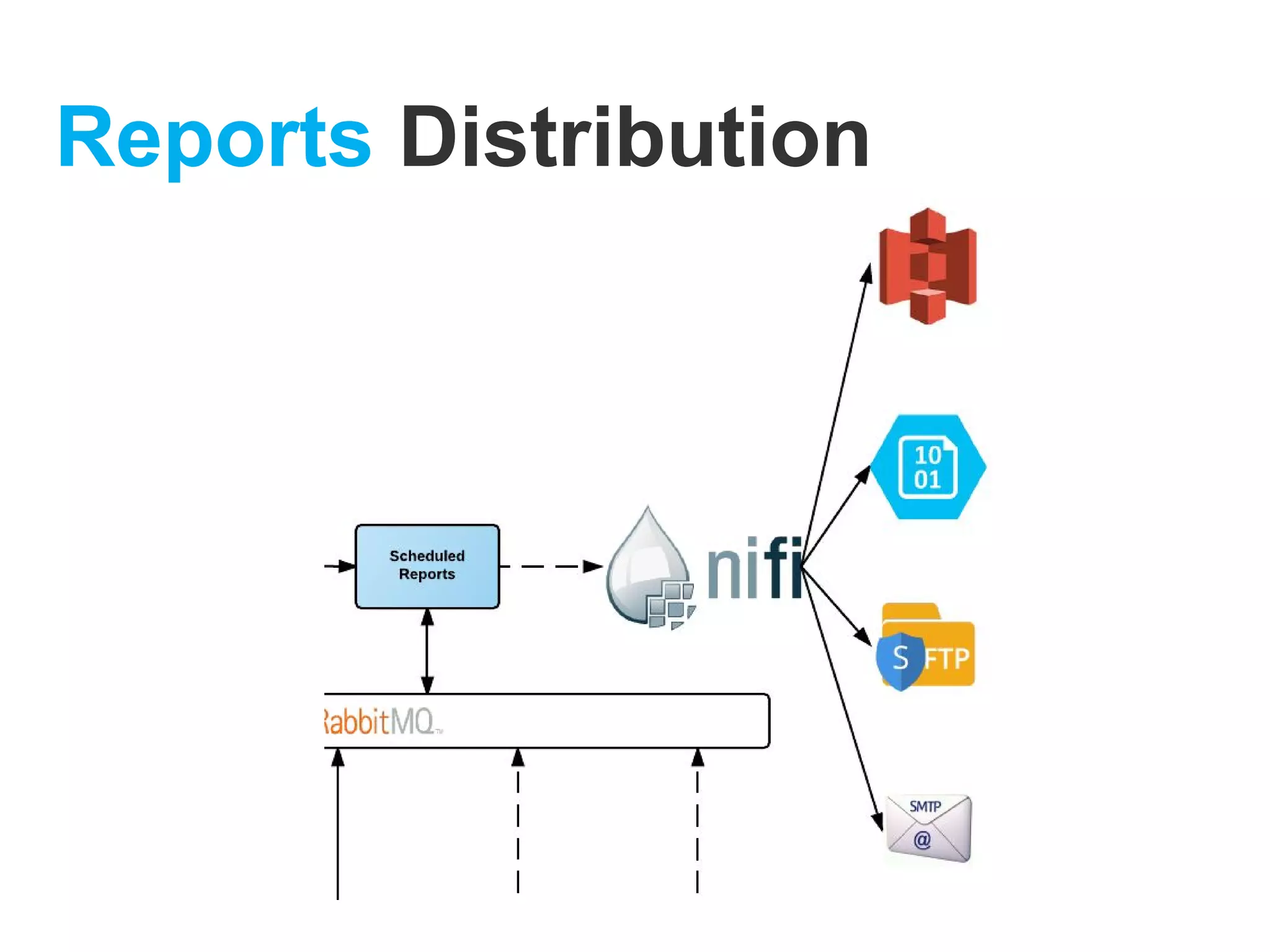
The document provides an overview of Apache NiFi, detailing its architecture, components, and functionalities for data ingestion and distribution. It highlights features such as flow files, processors, and data provenance capabilities, as well as a use case demonstrating its scalability and efficiency in processing large volumes of data. The content emphasizes the usability and extensibility of NiFi in real-time data management scenarios.
History & Facts
Createdby : NSA
Incubating : 2014
Available : 2015
Main contributors: Hortonworks
Current Stable Version : 1.1.1
Delivery Guarantees : at least once
Out of Order Processing : no
Windowing : no
Back-pressure : yes
Latency : configurable
Resource Management : native
API : REST (GUI)
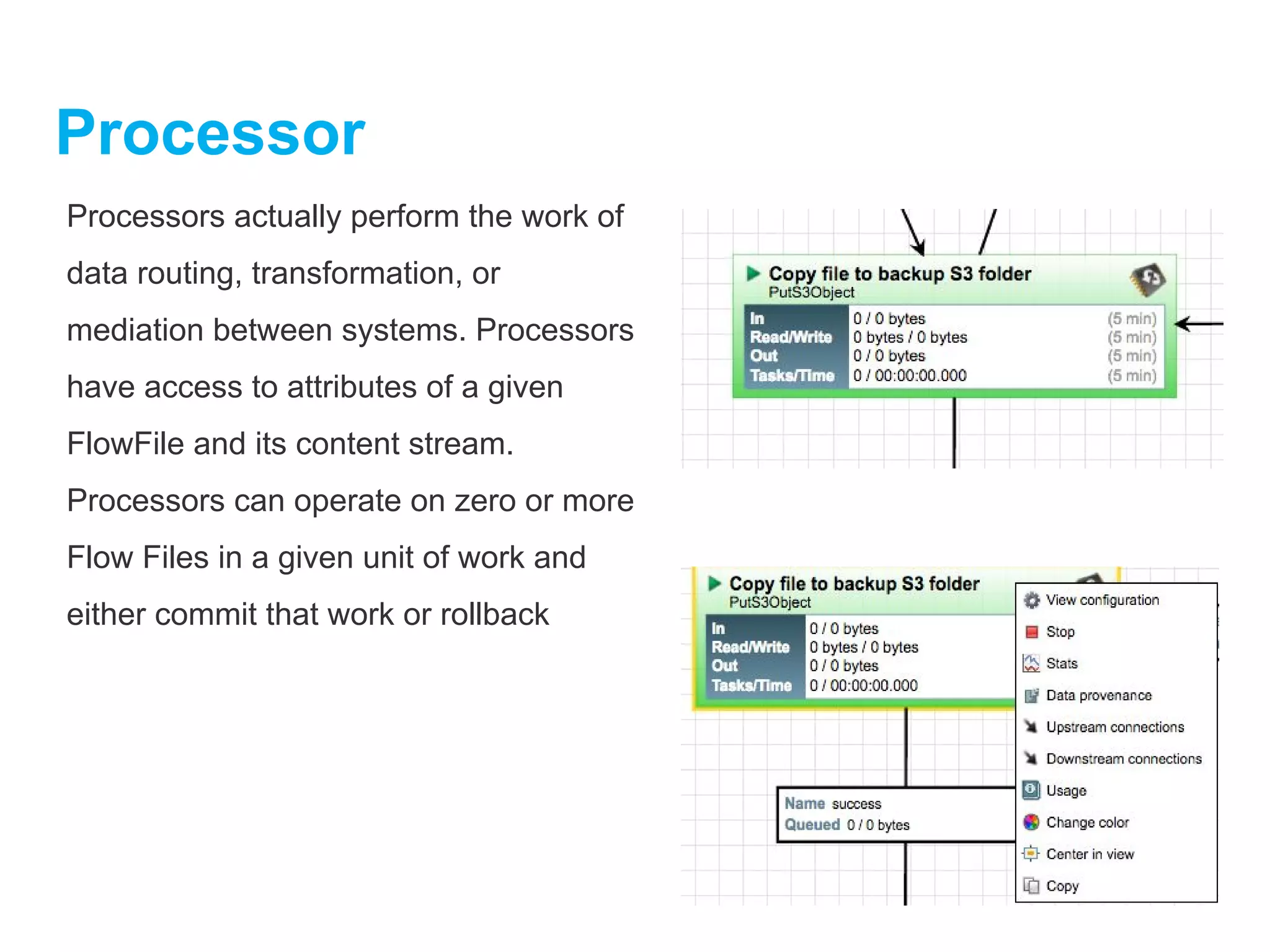
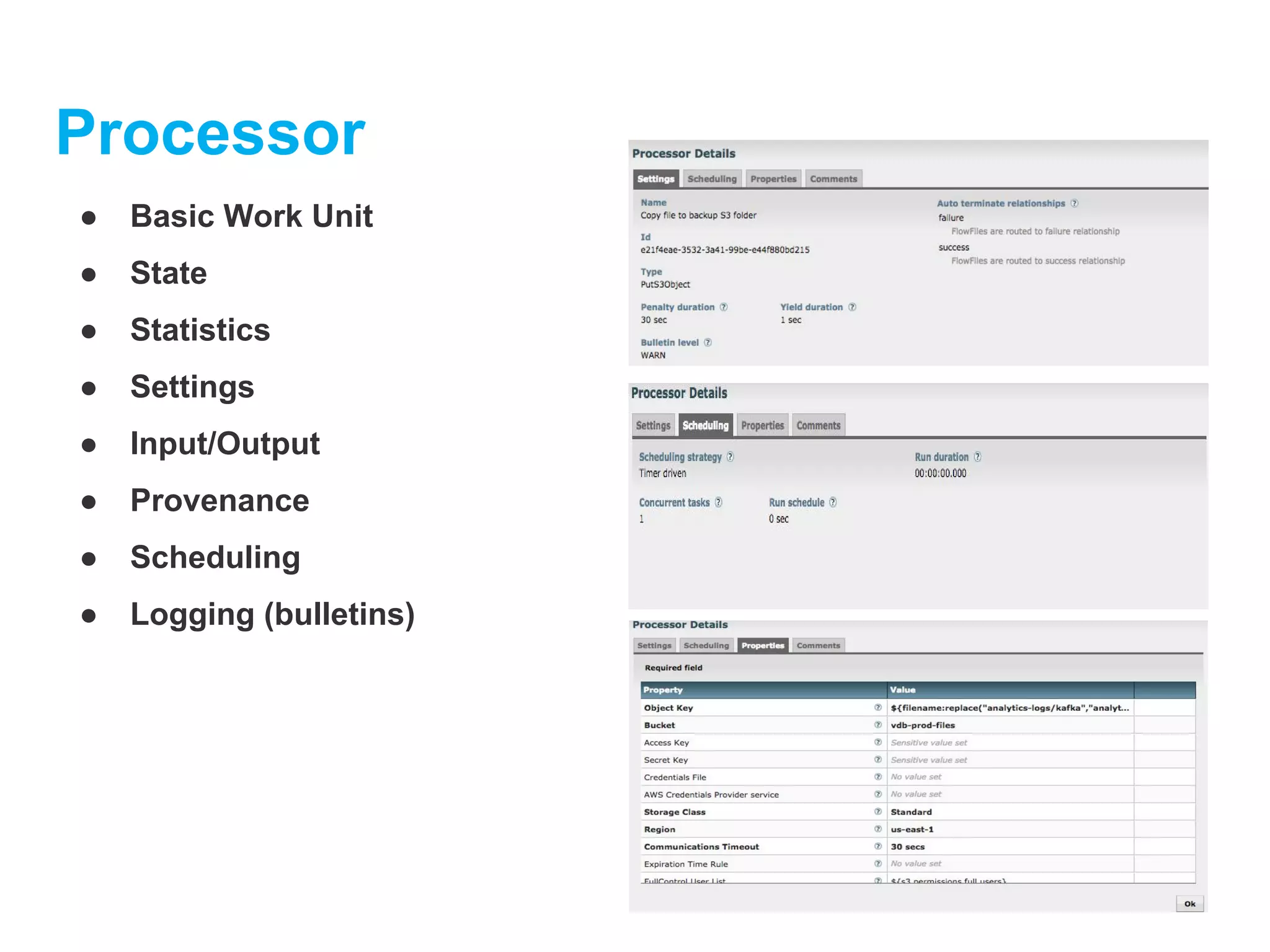
Processor
Processors actually performthe work of
data routing, transformation, or
mediation between systems. Processors
have access to attributes of a given
FlowFile and its content stream.
Processors can operate on zero or more
Flow Files in a given unit of work and
either commit that work or rollback
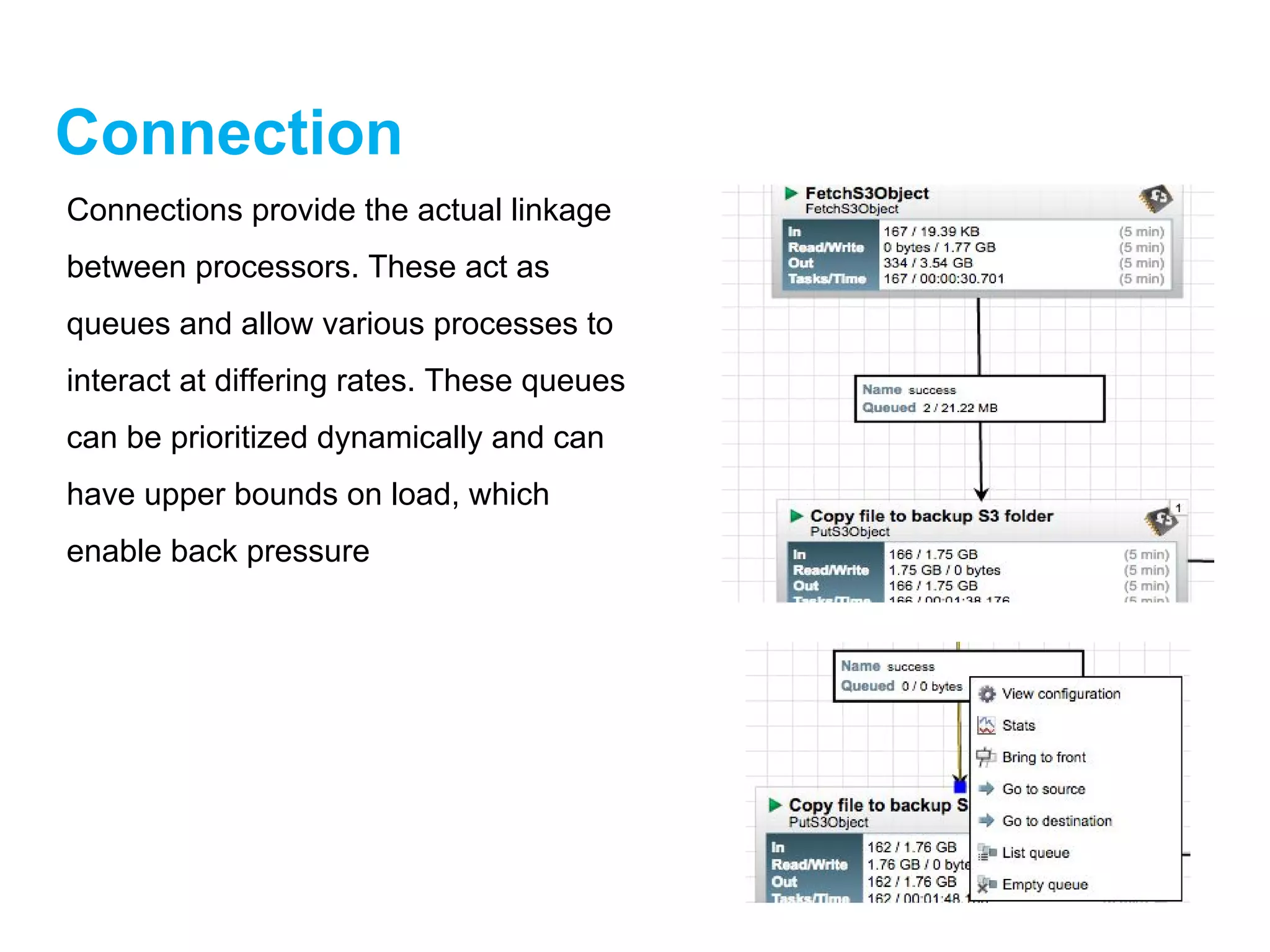
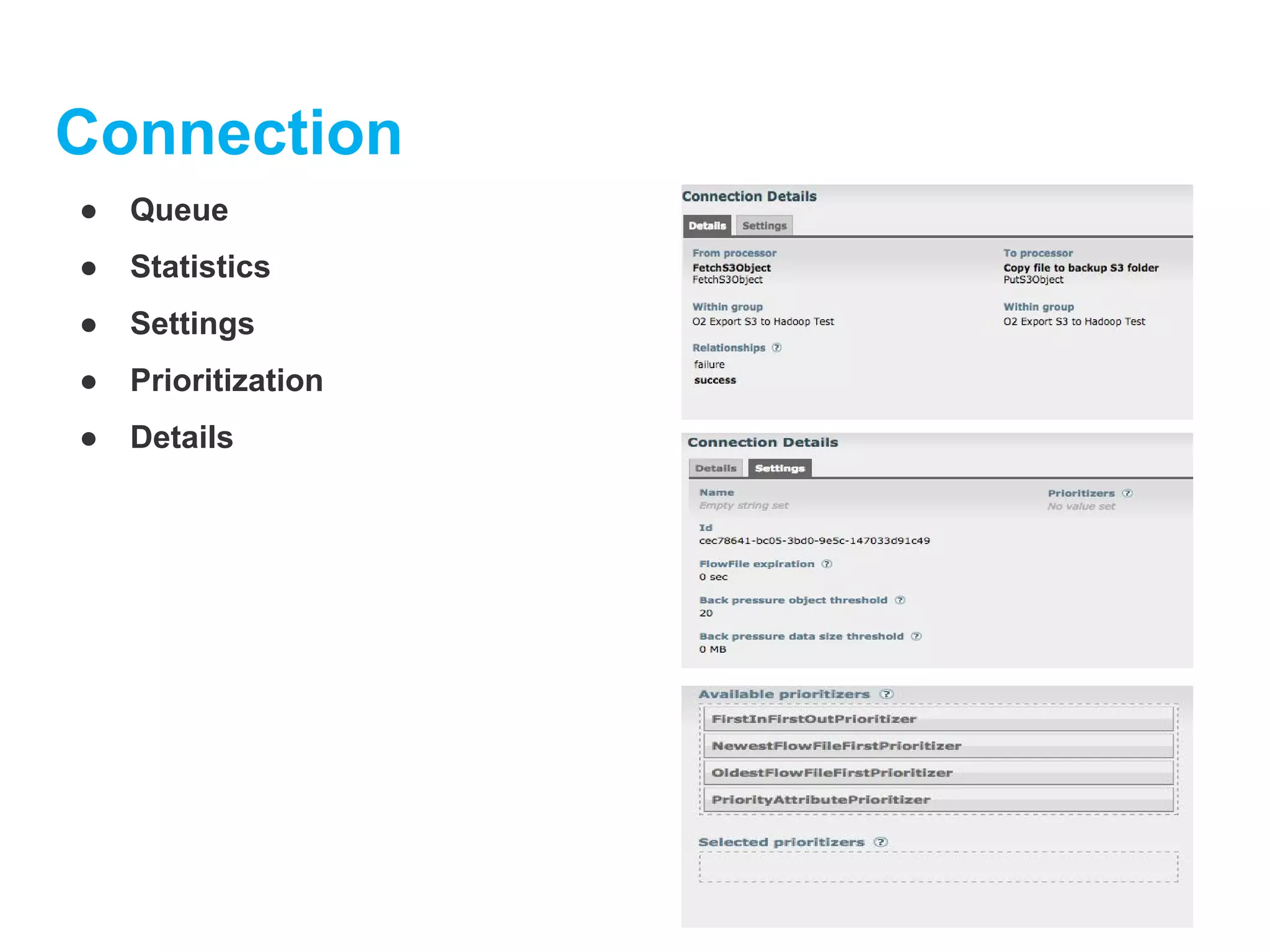
Connection
Connections provide theactual linkage
between processors. These act as
queues and allow various processes to
interact at differing rates. These queues
can be prioritized dynamically and can
have upper bounds on load, which
enable back pressure
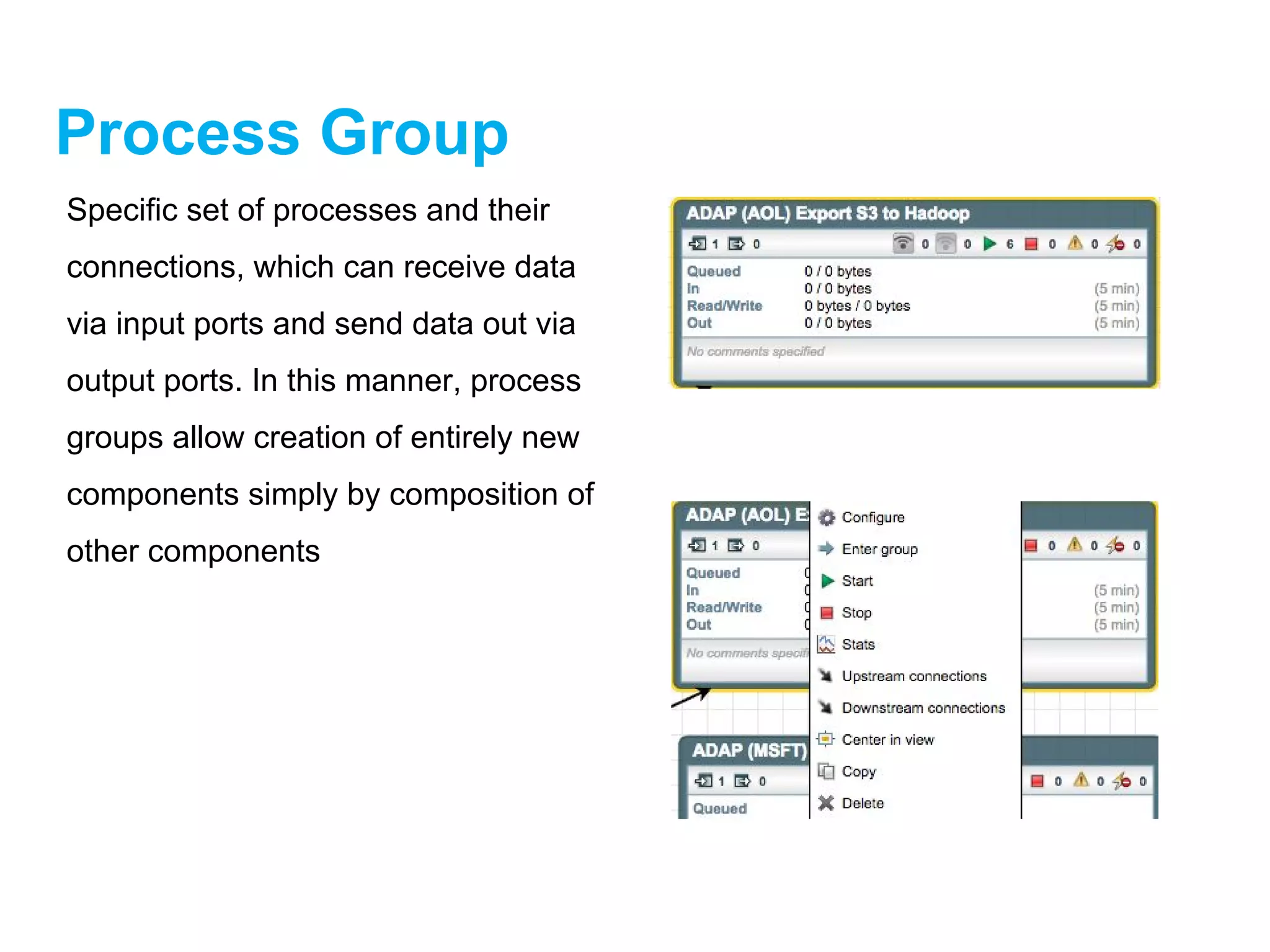
Process Group
Specific setof processes and their
connections, which can receive data
via input ports and send data out via
output ports. In this manner, process
groups allow creation of entirely new
components simply by composition of
other components
14.
Templates
Templates tend tobe highly pattern oriented and while there are often many
different ways to solve a problem, it helps greatly to be able to share those
best practices. Templates allow subject matter experts to build and publish
their flow designs and for others to benefit and collaborate on them
● XML Based
● Reusable unit
● Versioning (versioning with Git)
15.
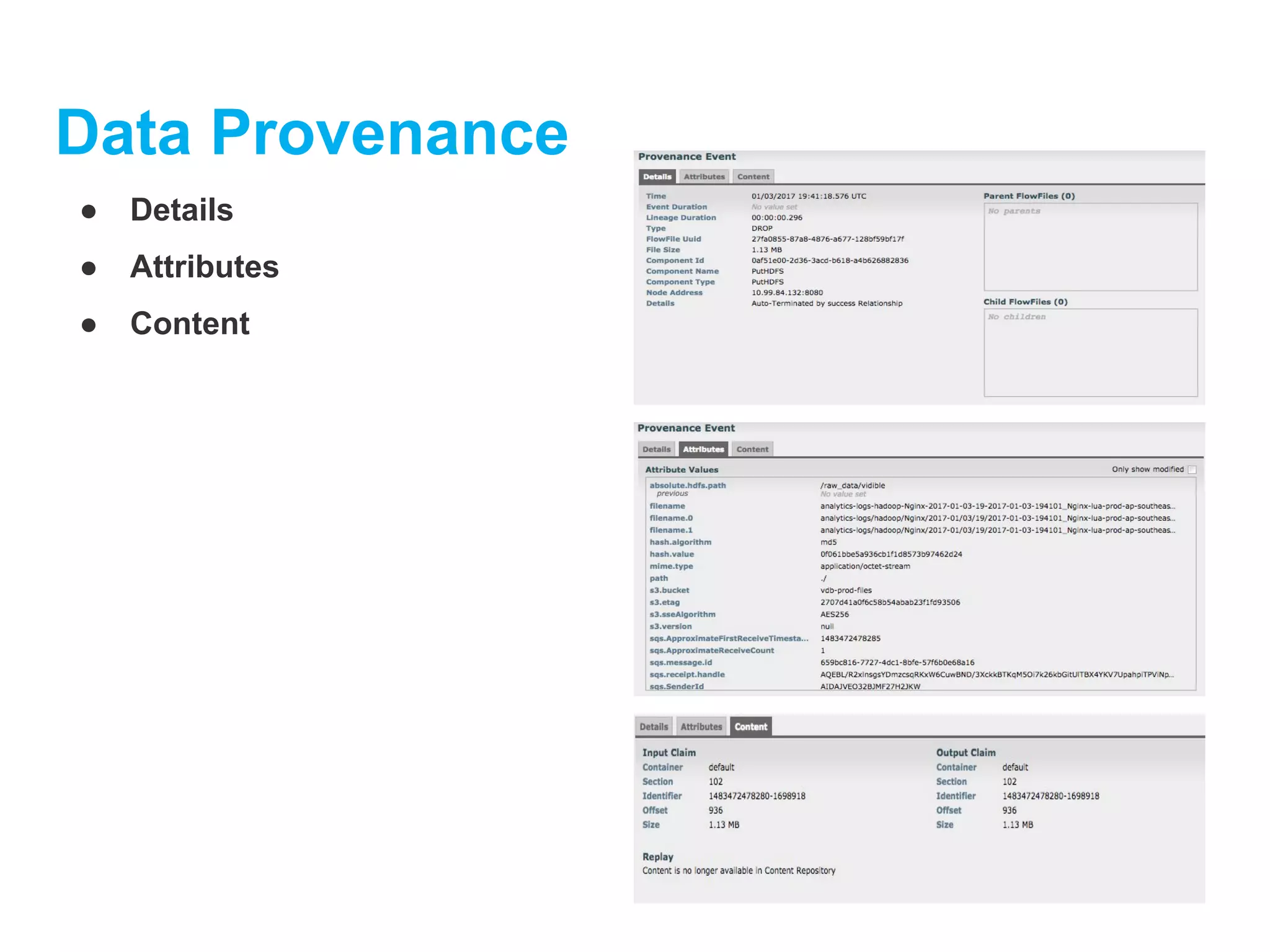
Data Provenance
NiFi automaticallyrecords, indexes, and makes available
provenance data as objects flow through the system even
across fan-in, fan-out, transformations, and more. This
information becomes extremely critical in supporting
compliance, troubleshooting, optimization, and other scenarios
Controller Service
Controller Serviceallows
developers to share functionality
and state across the JVM in a
clean and consistent manner
● No scheduling
● No connections
● Used by Processors,
Reporting Tasks, and other
Controller Services
18.
Reporting Tasks
Provides acapability for reporting
status, statistics, metrics, and
monitoring information to external
services
● ElastichSearchProvenanceReporter and DataDogReportingTask
19.
Extensibility
● Ready touse maven template
● Well defined interface for each component
● Classloader Isolation (.nar files)
● Great documentation for developers
20.
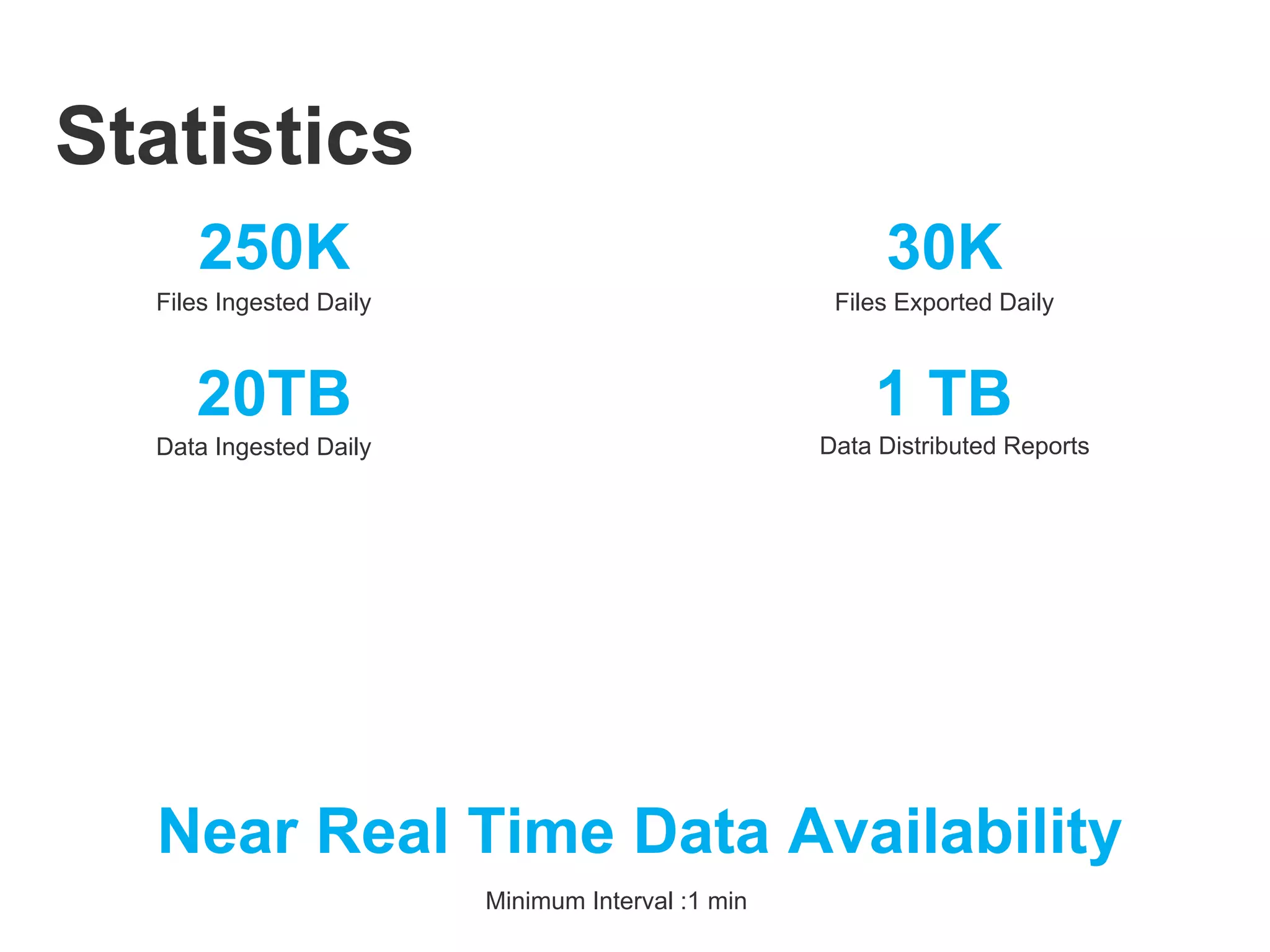
Statistics
● 200+ builtin Processors
● 10+ built Control Services
● 10+ built in Reporting Tasks















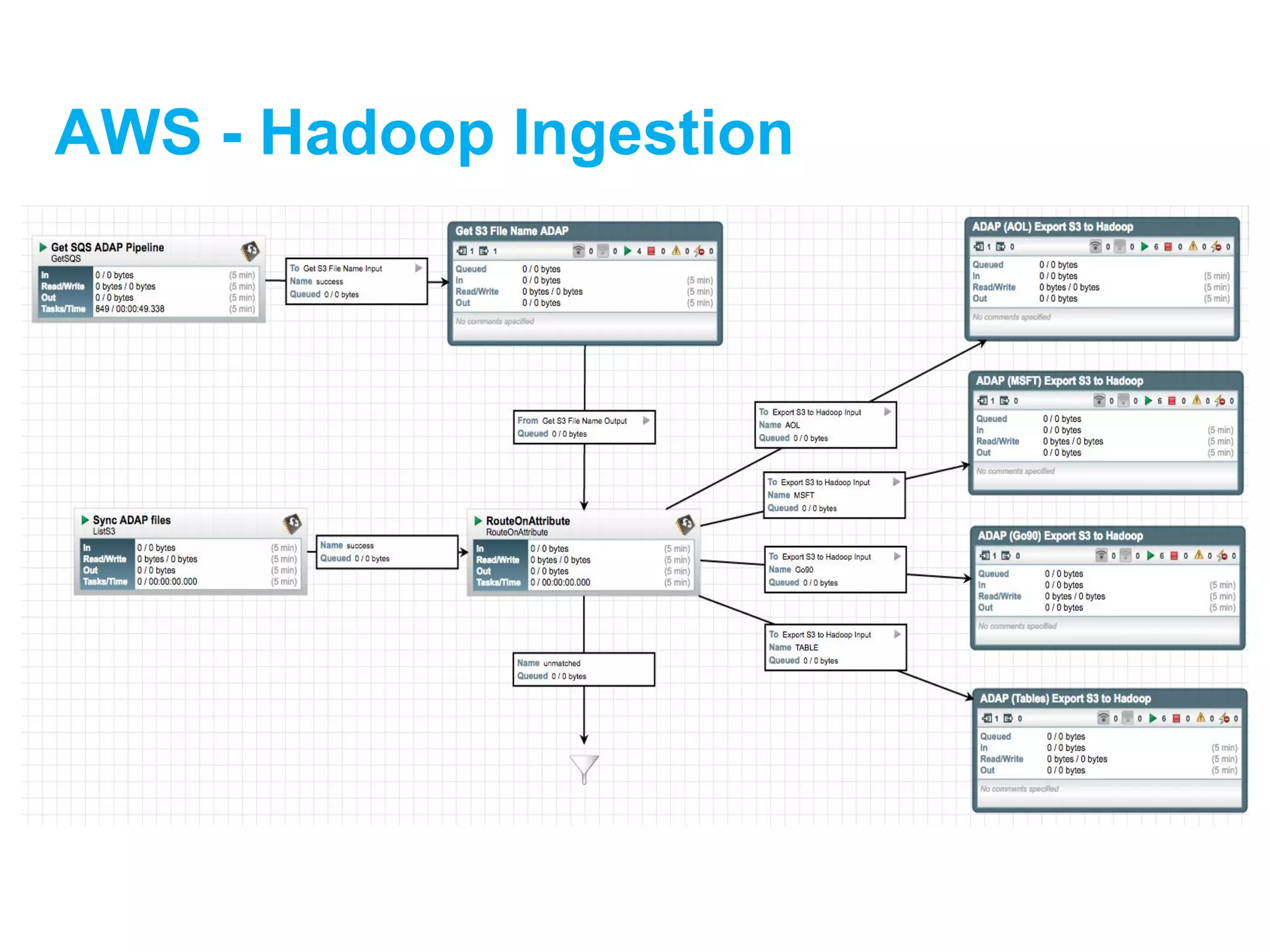
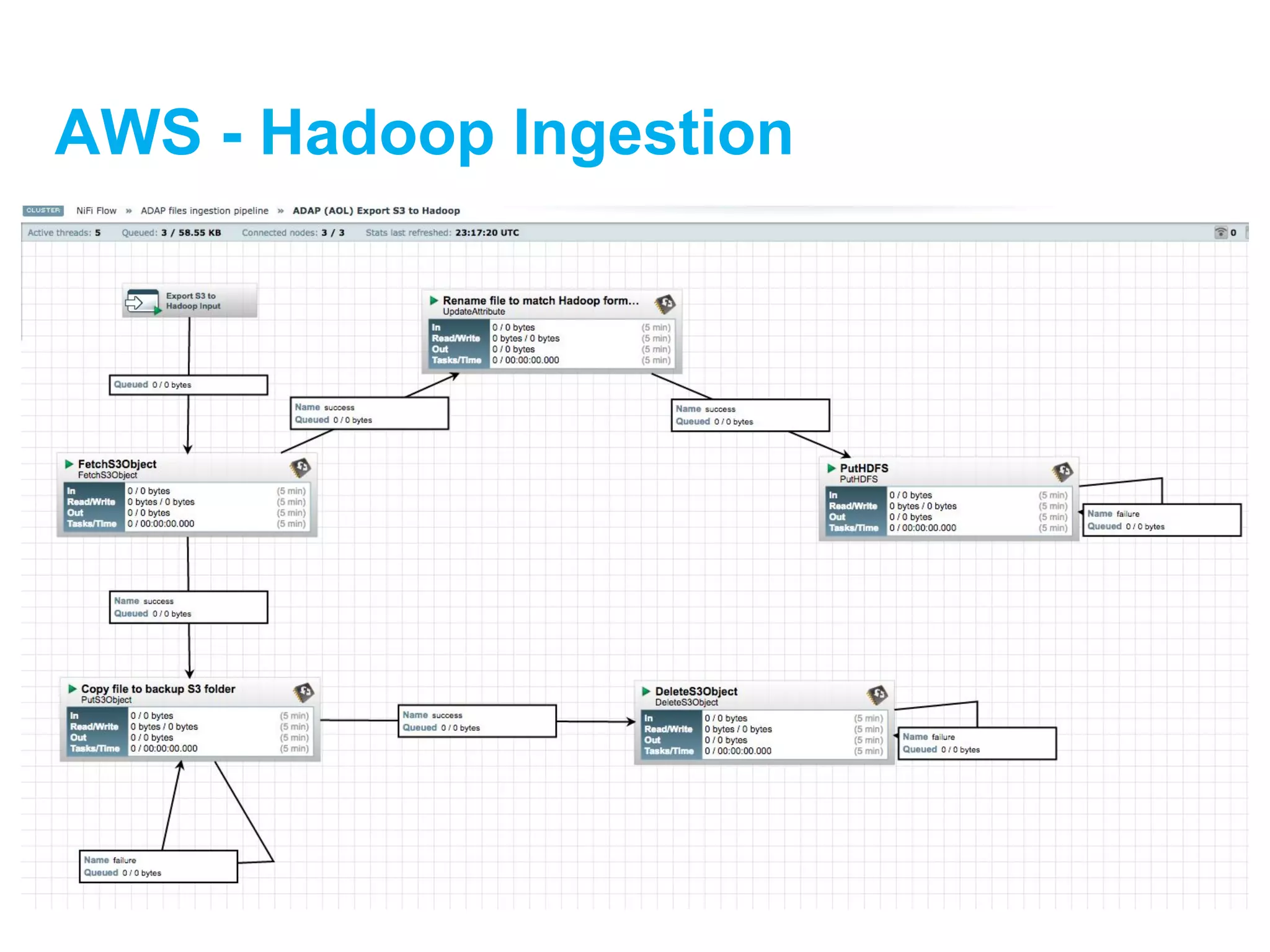
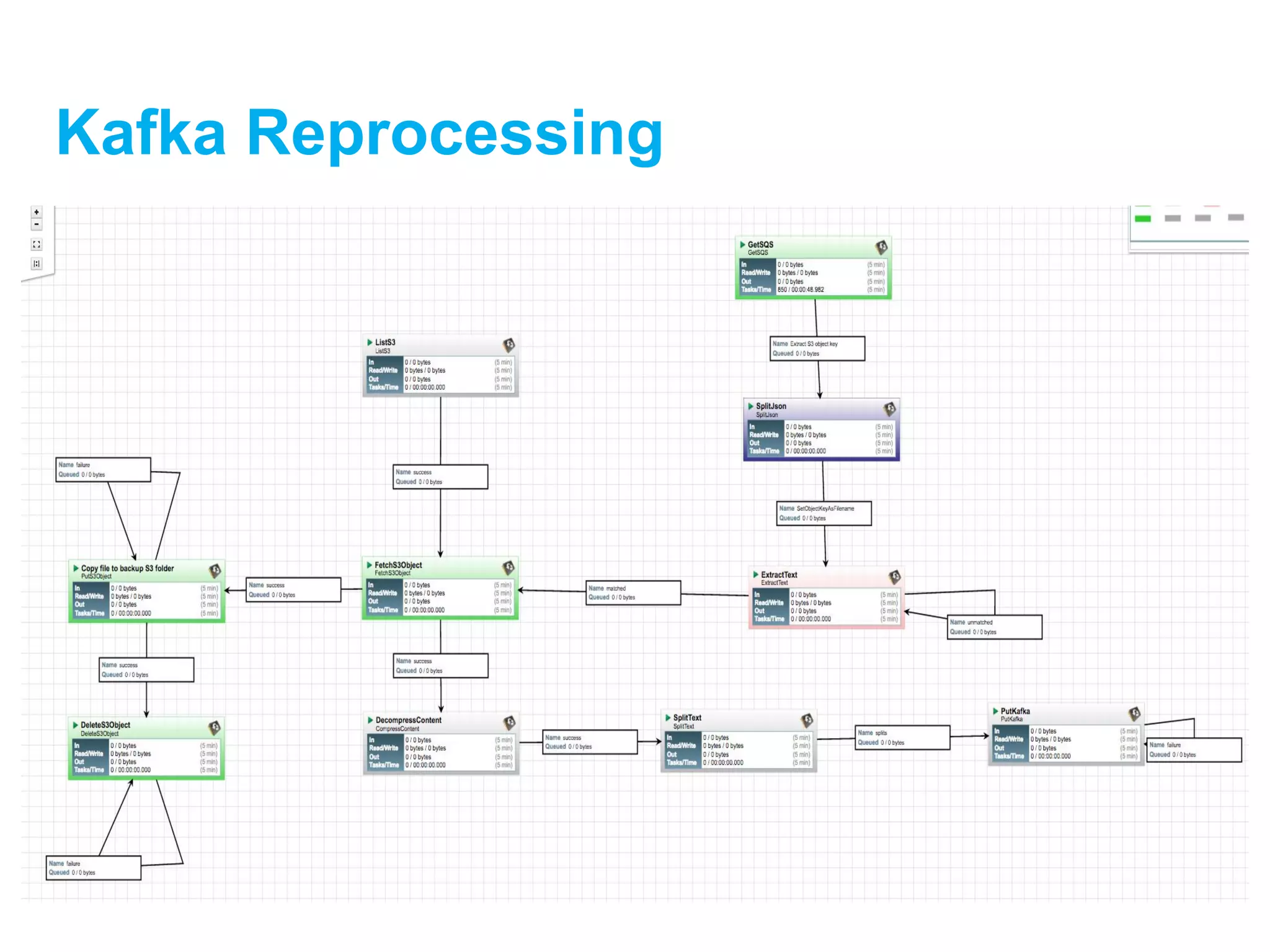
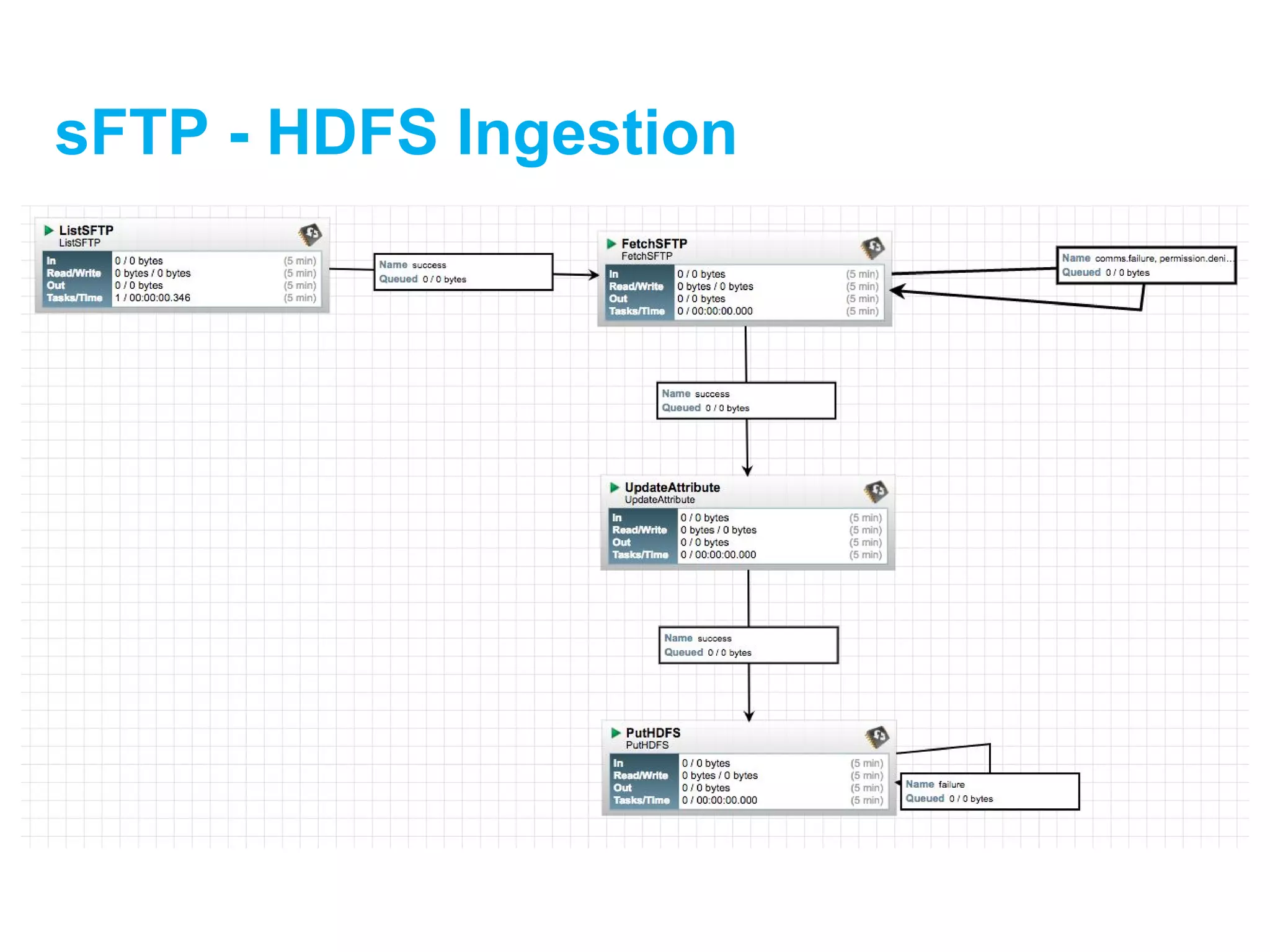





















































![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)






