Downloaded 285 times






















![Configuring Heartbeat with puppet
heartbeat::hacf {"clustername":
hosts => ["host-a","host-b"],
hb_nic => ["bond0"],
hostip1 => ["10.0.128.11"],
hostip2 => ["10.0.128.12"],
ping => ["10.0.128.4"],
}
heartbeat::authkeys {"ClusterName":
password => “ClusterName ",
}
http://github.com/jtimberman/puppet/tree/master/heartbeat/](https://image.slidesharecdn.com/pacemaker-110418162217-phpapp01/75/Linux-HA-with-Pacemaker-26-2048.jpg)















![Checking the Cluster
State
crm_mon -1
============
Last updated: Wed Nov 4 16:44:26 2009
Stack: Heartbeat
Current DC: xms-1 (c2c581f8-4edc-1de0-a959-91d246ac80f5) - partition with quorum
Version: 1.0.5-462f1569a43740667daf7b0f6b521742e9eb8fa7
2 Nodes configured, unknown expected votes
2 Resources configured.
============
Online: [ xms-1 xms-2 ]
Resource Group: svc_mysql
d_mysql (ocf::ntc:mysql): Started xms-1
ip_mysql (ocf::heartbeat:IPaddr2): Started xms-1
Resource Group: svc_XMS
d_XMS (ocf::ntc:XMS): Started xms-2
ip_XMS (ocf::heartbeat:IPaddr2): Started xms-2
ip_XMS_public (ocf::heartbeat:IPaddr2): Started xms-2](https://image.slidesharecdn.com/pacemaker-110418162217-phpapp01/75/Linux-HA-with-Pacemaker-42-2048.jpg)
![Stopping a resource
crm resource stop svc_XMS
crm_mon -1
============
Last updated: Wed Nov 4 16:56:05 2009
Stack: Heartbeat
Current DC: xms-1 (c2c581f8-4edc-1de0-a959-91d246ac80f5) - partition with quorum
Version: 1.0.5-462f1569a43740667daf7b0f6b521742e9eb8fa7
2 Nodes configured, unknown expected votes
2 Resources configured.
============
Online: [ xms-1 xms-2 ]
Resource Group: svc_mysql
d_mysql (ocf::ntc:mysql): Started xms-1
ip_mysql (ocf::heartbeat:IPaddr2): Started xms-1](https://image.slidesharecdn.com/pacemaker-110418162217-phpapp01/75/Linux-HA-with-Pacemaker-43-2048.jpg)
![Starting a resource
crm resource start svc_XMS
crm_mon -1
============
Last updated: Wed Nov 4 17:04:56 2009
Stack: Heartbeat
Current DC: xms-1 (c2c581f8-4edc-1de0-a959-91d246ac80f5) - partition with quorum
Version: 1.0.5-462f1569a43740667daf7b0f6b521742e9eb8fa7
2 Nodes configured, unknown expected votes
2 Resources configured.
============
Online: [ xms-1 xms-2 ]
Resource Group: svc_mysql
d_mysql (ocf::ntc:mysql): Started xms-1
ip_mysql (ocf::heartbeat:IPaddr2): Started xms-1
Resource Group: svc_XMS](https://image.slidesharecdn.com/pacemaker-110418162217-phpapp01/75/Linux-HA-with-Pacemaker-44-2048.jpg)

![Moving a resource
[xpoll-root@XMS-1 ~]# crm resource migrate svc_XMS xms-1
[xpoll-root@XMS-1 ~]# crm_mon -1
Last updated: Wed Nov 4 17:32:50 2009
Stack: Heartbeat
Current DC: xms-1 (c2c581f8-4edc-1de0-a959-91d246ac80f5) - partition with quorum
Version: 1.0.5-462f1569a43740667daf7b0f6b521742e9eb8fa7
2 Nodes configured, unknown expected votes
2 Resources configured.
Online: [ xms-1 xms-2 ]
Resource Group: svc_mysql
d_mysql (ocf::ntc:mysql): Started xms-1
ip_mysql (ocf::heartbeat:IPaddr2): Started xms-1
Resource Group: svc_XMS
d_XMS (ocf::ntc:XMS): Started xms-1
ip_XMS (ocf::heartbeat:IPaddr2): Started xms-1
ip_XMS_public (ocf::heartbeat:IPaddr2): Started xms-1](https://image.slidesharecdn.com/pacemaker-110418162217-phpapp01/75/Linux-HA-with-Pacemaker-46-2048.jpg)


![Resource not running
[menos-val3-root@mrs-a ~]# crm
crm(live)# resource
crm(live)resource# show
Resource Group: svc-MRS
d_MRS (ocf::ntc:tomcat) Stopped
ip_MRS_svc (ocf::heartbeat:IPaddr2) Stopped
ip_MRS_usr (ocf::heartbeat:IPaddr2) Stopped](https://image.slidesharecdn.com/pacemaker-110418162217-phpapp01/75/Linux-HA-with-Pacemaker-49-2048.jpg)
![Resource Failcount
[menos-val3-root@mrs-a ~]# crm
crm(live)# resource
crm(live)resource# failcount d_MRS show mrs-a
scope=status name=fail-count-d_MRS value=1
crm(live)resource# failcount d_MRS delete mrs-a
crm(live)resource# failcount d_MRS show mrs-a
scope=status name=fail-count-d_MRS value=0](https://image.slidesharecdn.com/pacemaker-110418162217-phpapp01/75/Linux-HA-with-Pacemaker-50-2048.jpg)
![Resource Failcount
[menos-val3-root@mrs-a ~]# crm
crm(live)# resource
crm(live)resource# failcount d_MRS show mrs-a
scope=status name=fail-count-d_MRS value=1
crm(live)resource# failcount d_MRS delete mrs-a
crm(live)resource# failcount d_MRS show mrs-a
scope=status name=fail-count-d_MRS value=0](https://image.slidesharecdn.com/pacemaker-110418162217-phpapp01/75/Linux-HA-with-Pacemaker-51-2048.jpg)
![Resource Failcount
[menos-val3-root@mrs-a ~]# crm
crm(live)# resource
crm(live)resource# failcount d_MRS show mrs-a
scope=status name=fail-count-d_MRS value=1
crm(live)resource# failcount d_MRS delete mrs-a
crm(live)resource# failcount d_MRS show mrs-a
scope=status name=fail-count-d_MRS value=0](https://image.slidesharecdn.com/pacemaker-110418162217-phpapp01/75/Linux-HA-with-Pacemaker-52-2048.jpg)




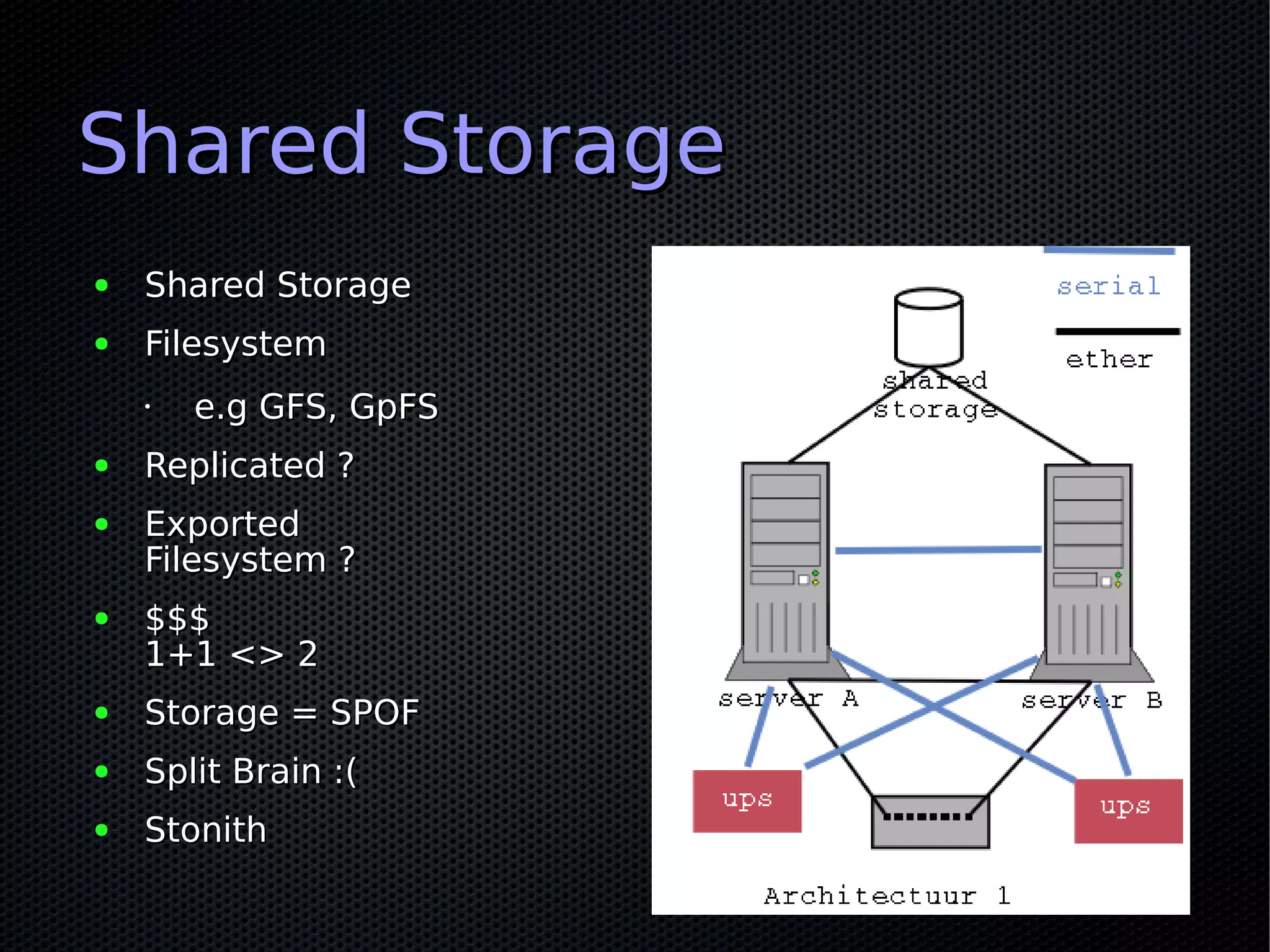
Linux High Availability provides concise summaries of key concepts: - High availability (HA) clustering allows services to take over work from others that go down, through IP and service takeover. It is designed for uptime, not performance or load balancing. - Downtime is expensive for businesses due to lost revenue and customer dissatisfaction. Statistics show significant drops in availability even at 99.9% uprates. - To achieve high availability, systems must be designed with simplicity, failure preparation, and reliability testing in mind. Complexity often undermines reliability. - Myths exist around technologies like virtualization and live migration providing complete high availability solutions. True HA requires eliminating all single points of







































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














