Downloaded 12 times

















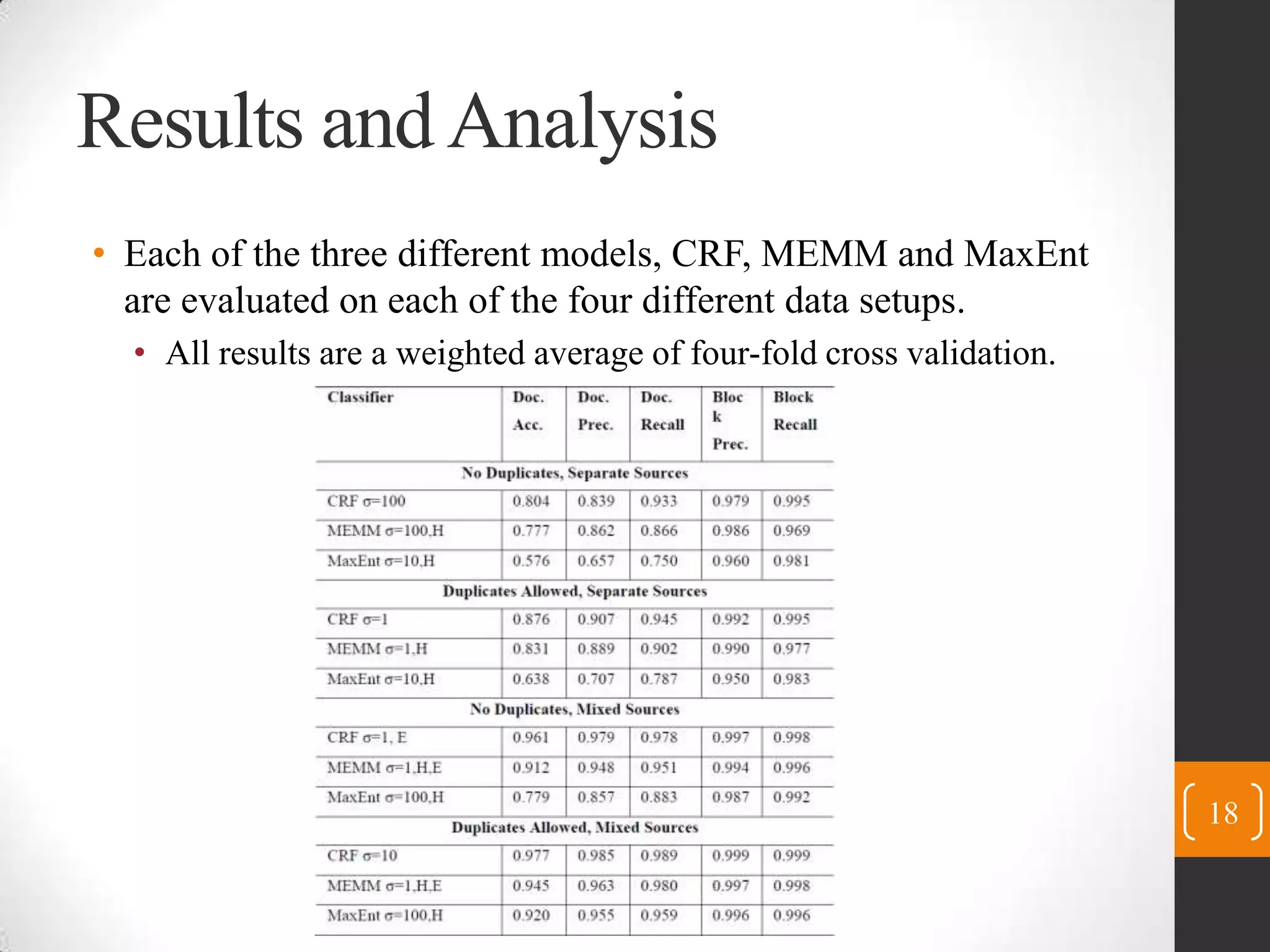
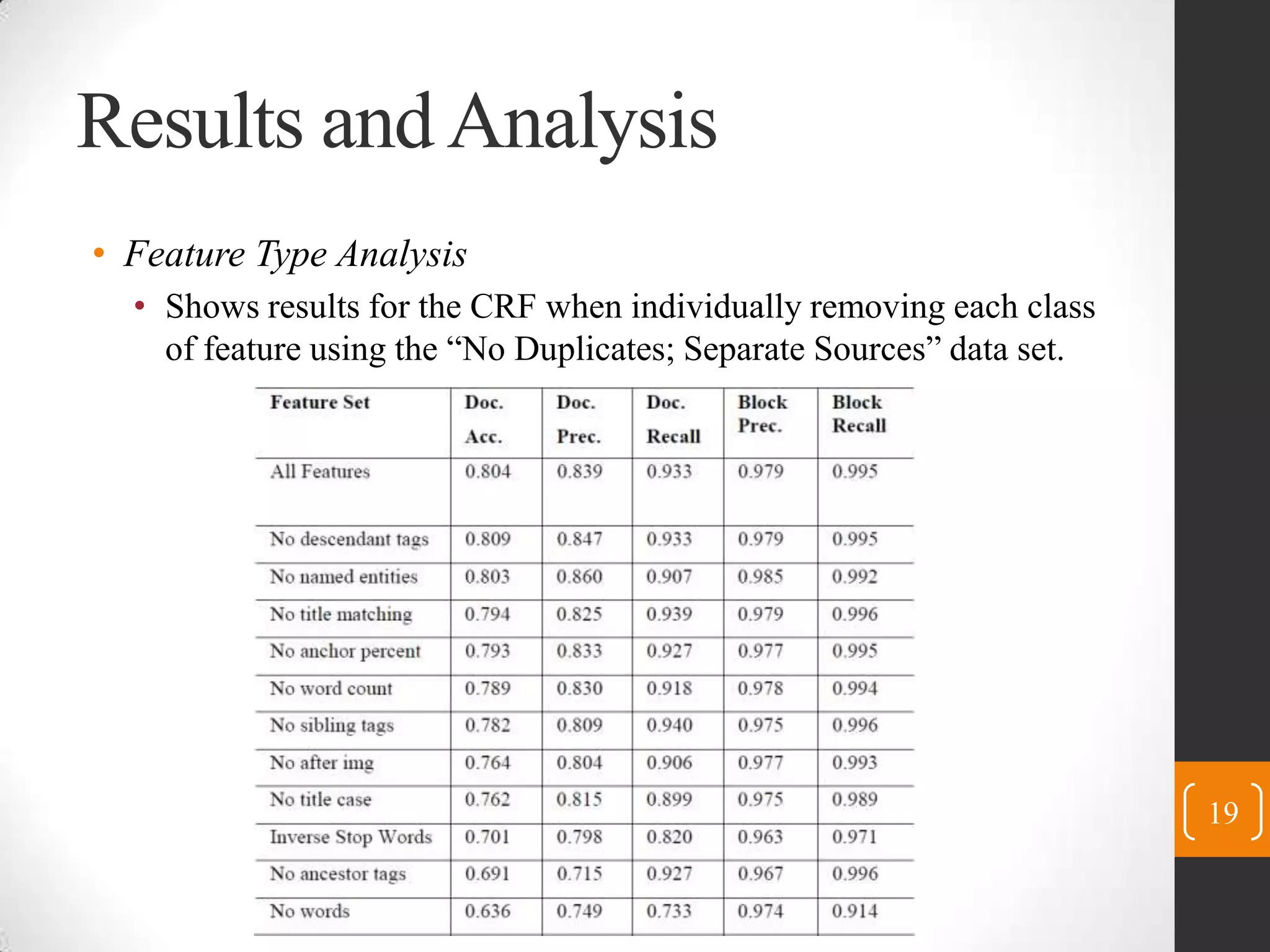

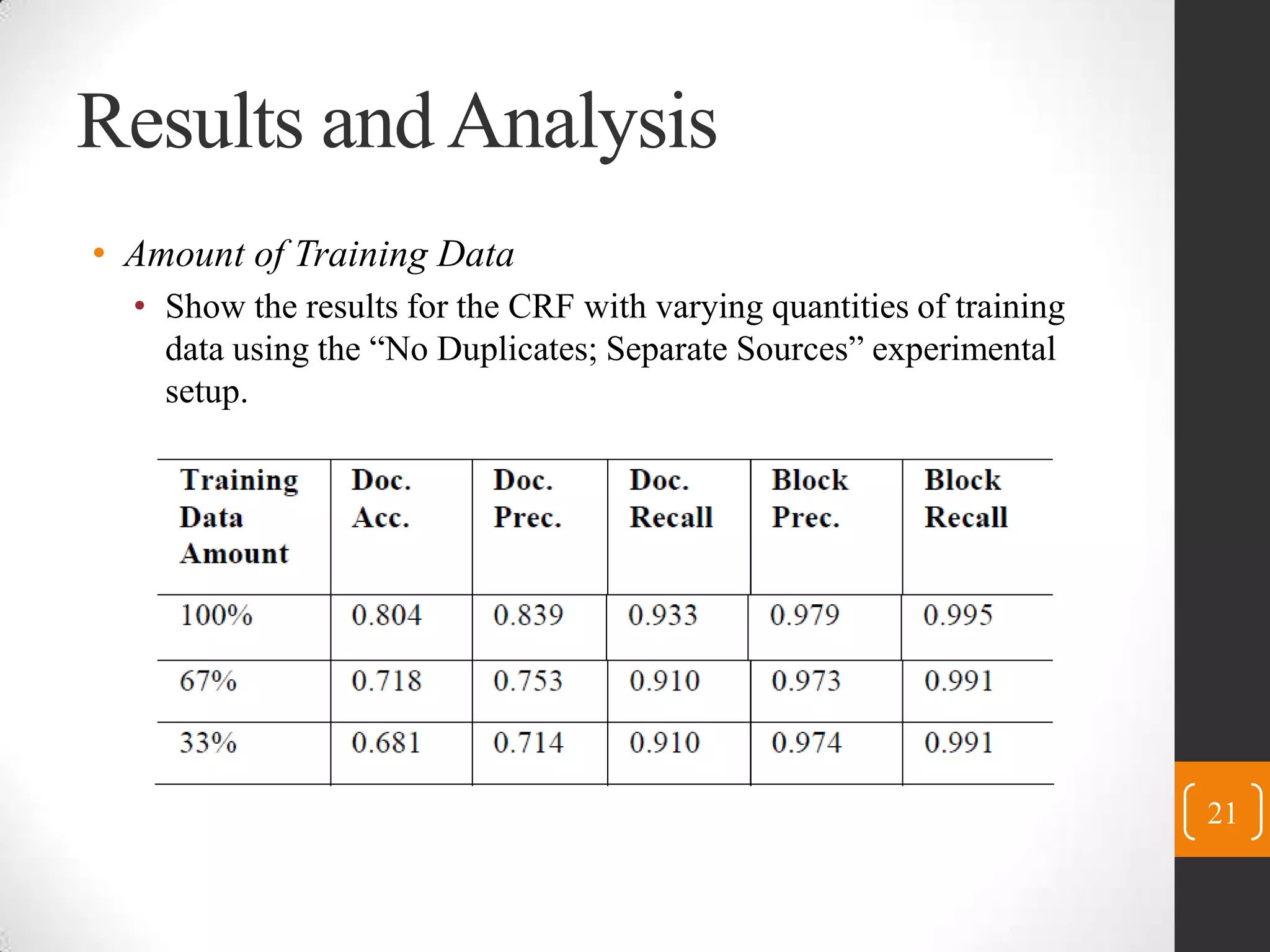



This paper presents three statistical models - Conditional Random Fields (CRF), Maximum Entropy Classifiers (MaxEnt), and Maximum Entropy Markov Models (MEMM) - for identifying content blocks in web pages. The models label blocks of web pages as either content or not content. Experimental results on 1620 documents from 27 news sites show that CRF performs best, accurately labeling over 99.5% of content blocks. Feature analysis found that block text features were most important. Future work will apply these techniques to additional data sources and languages.












































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)














