Downloaded 609 times
























![MemSQL
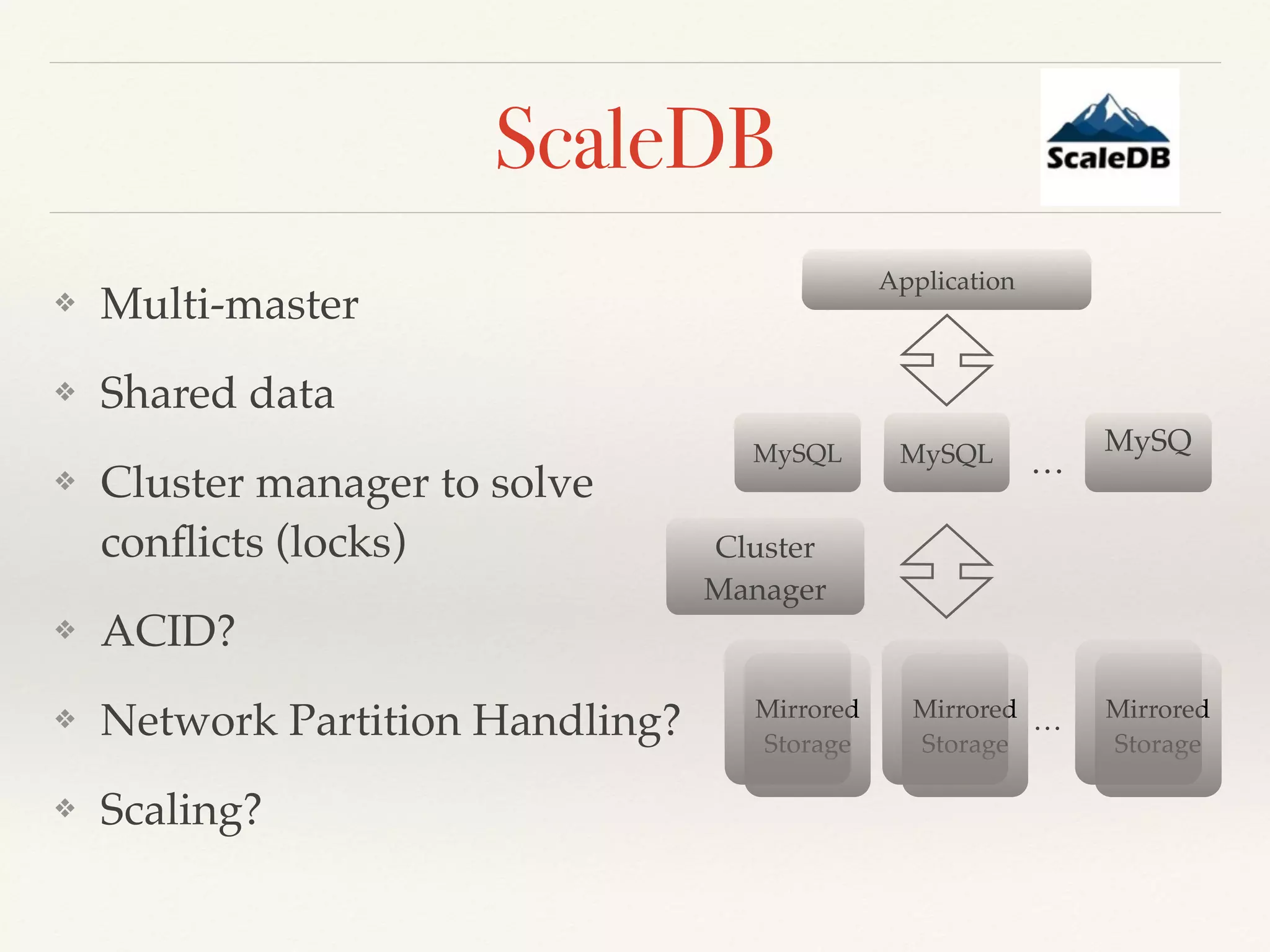
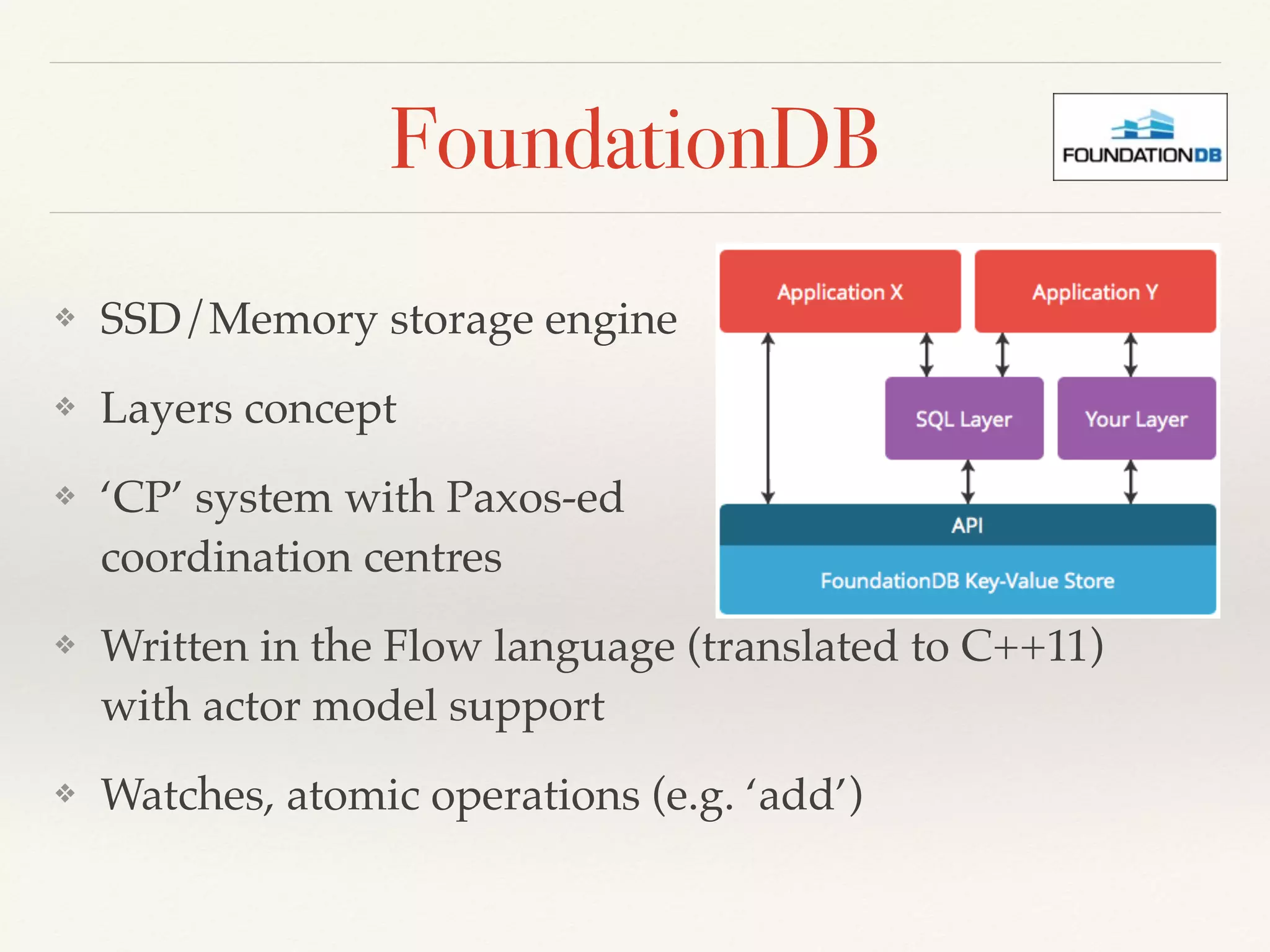
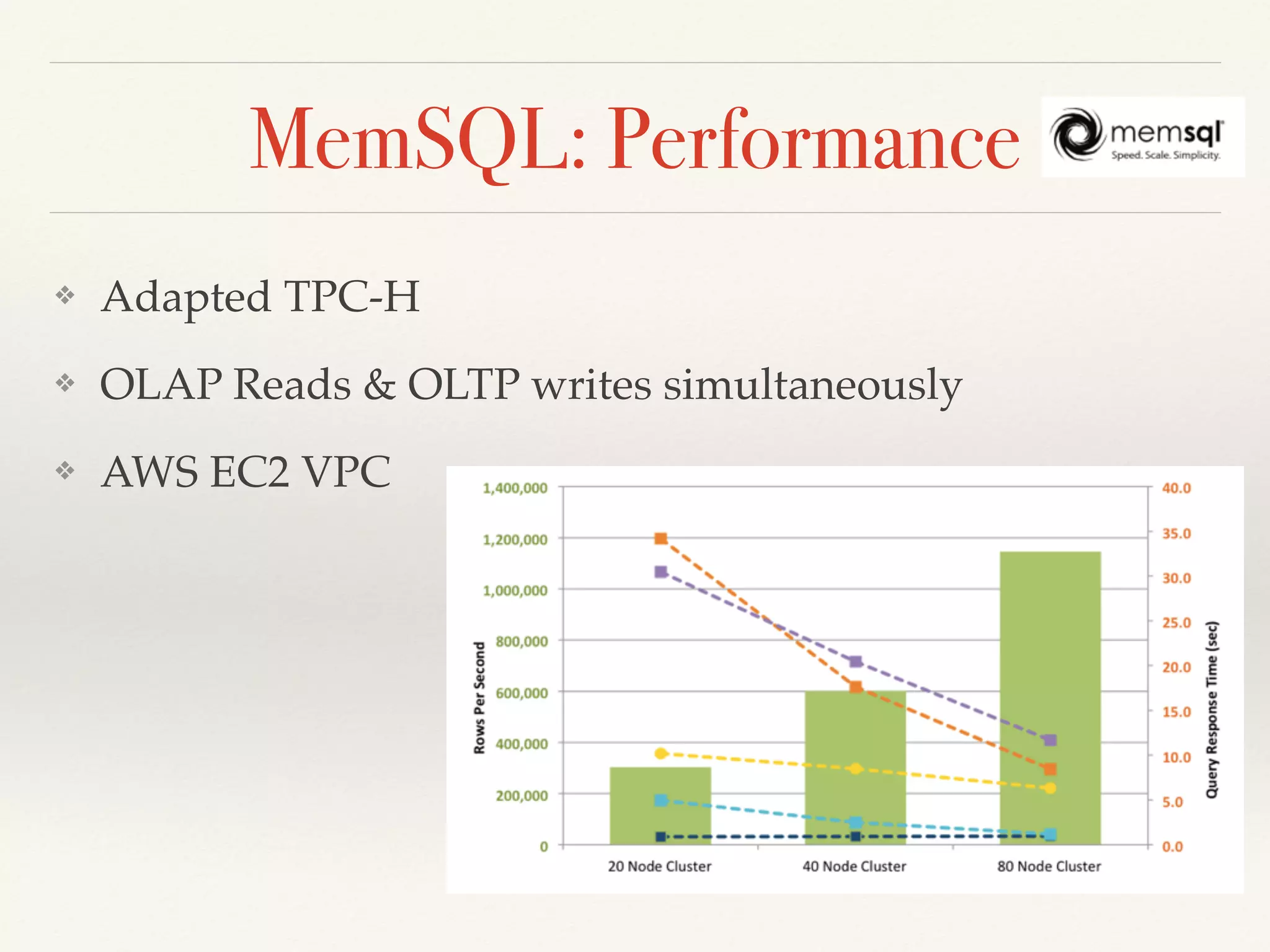
❖ In-Memory Storage for OLTP
❖ Column-oriented Storage for OLAP
❖ Compiled Query Execution Plans (+cache)
❖ Local ACID transactions (no global txs for distributed)
❖ Lock-free, MVCC
❖ Fault tolerance, automatic replication,
redundancy (=2 by default)
❖ [Almost] no penalty for replica creation](https://image.slidesharecdn.com/newsql-2015-150213024325-conversion-gate01/75/NewSQL-overview-Feb-2015-44-2048.jpg)


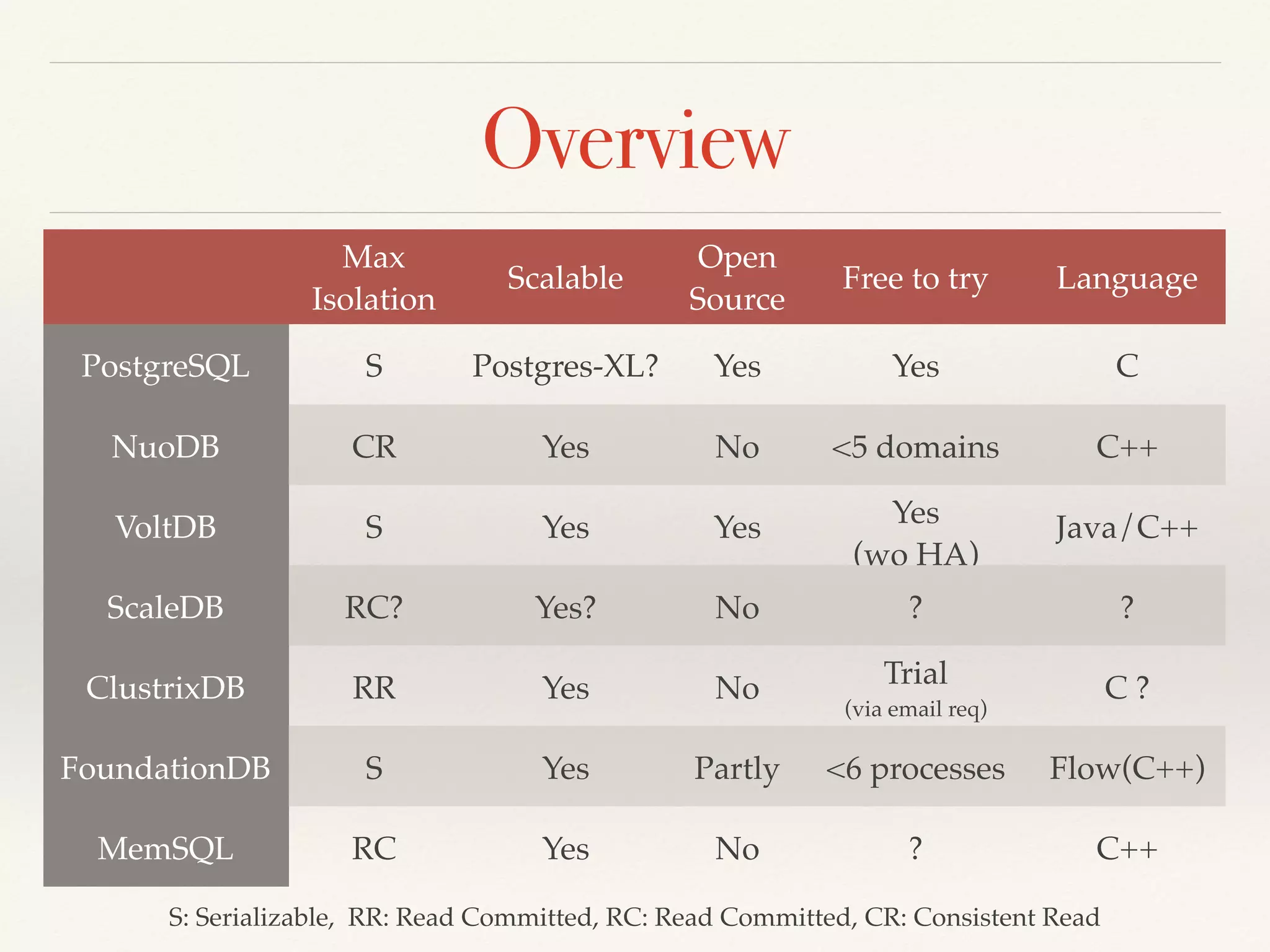










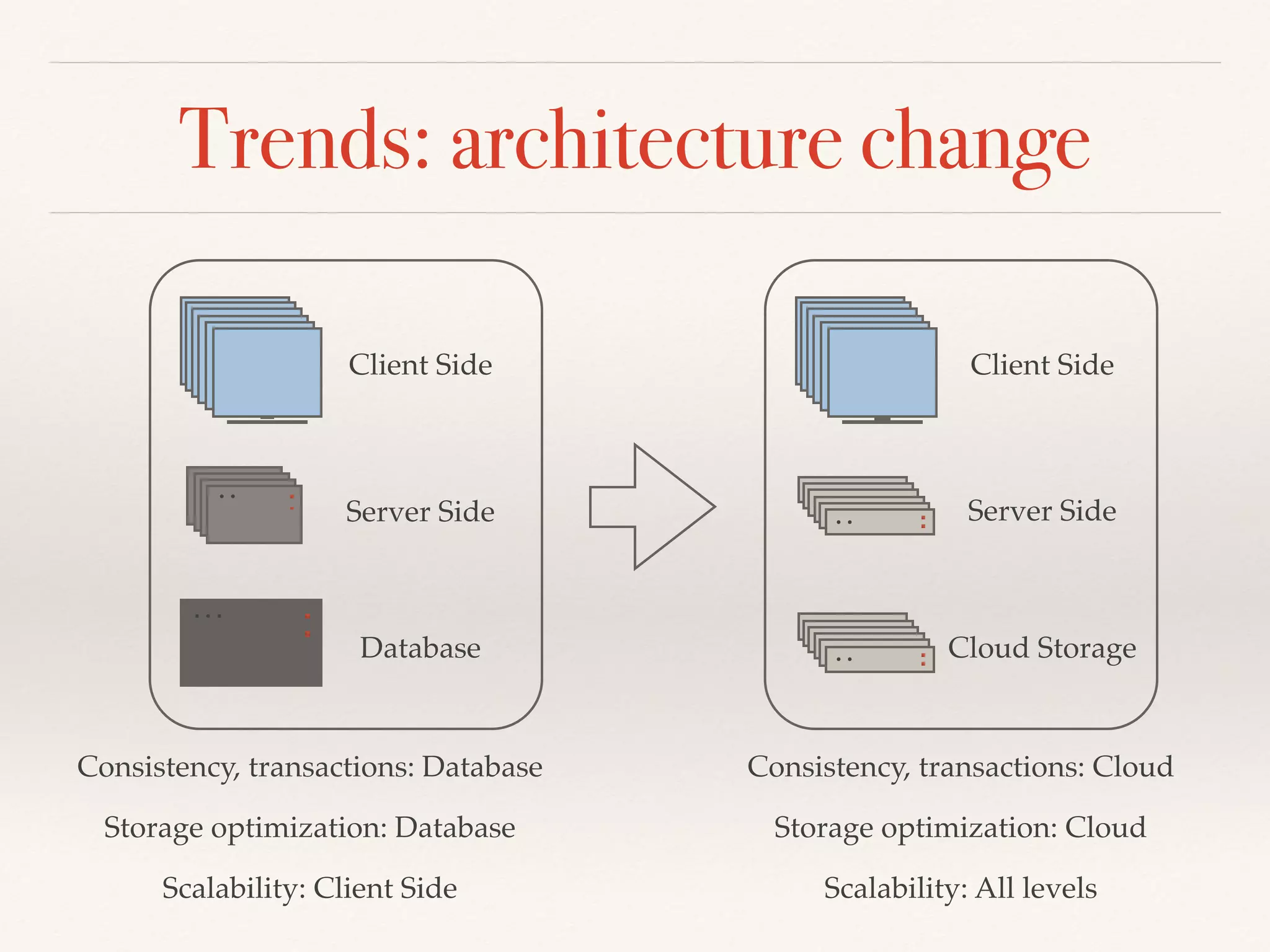
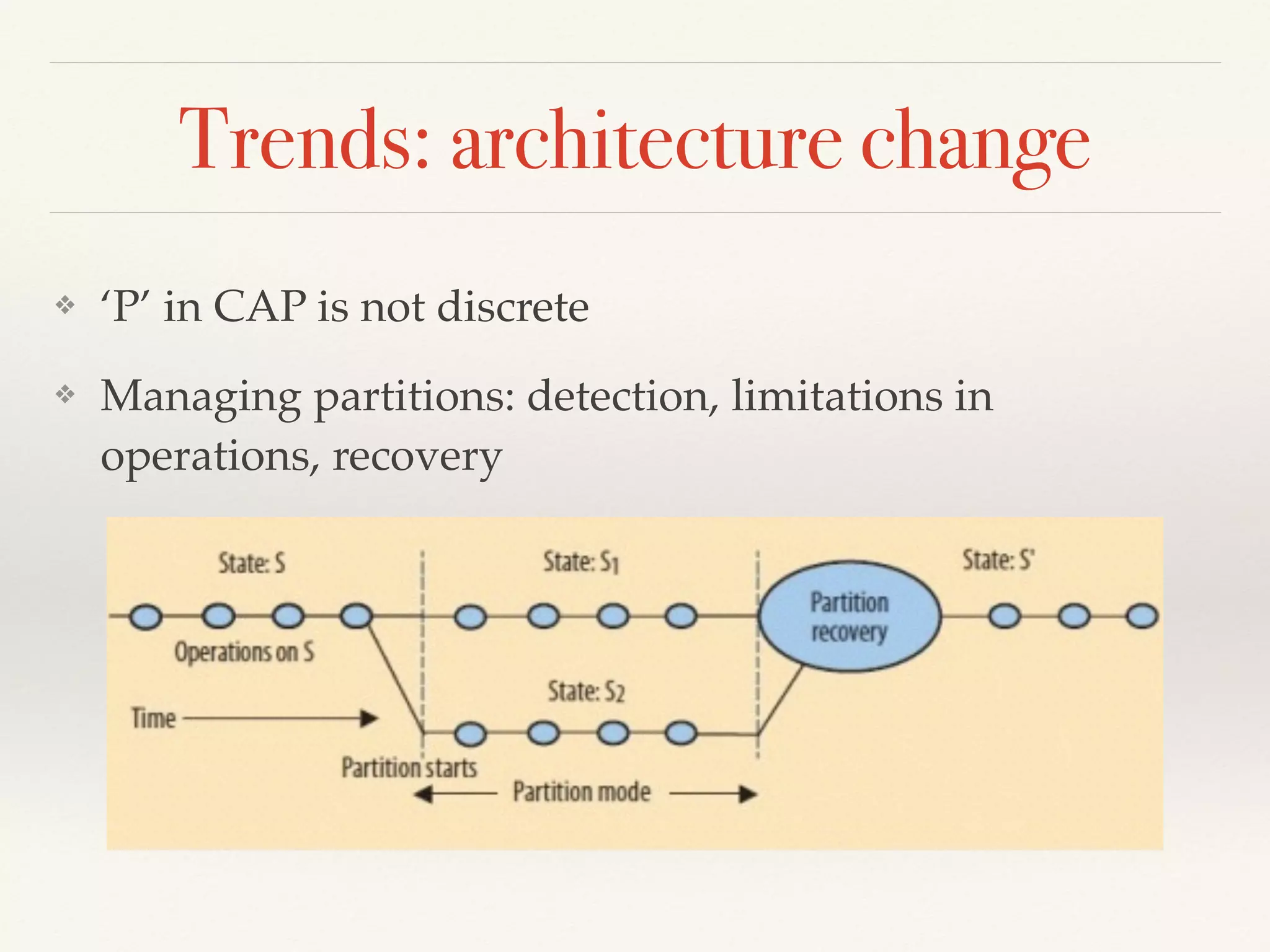
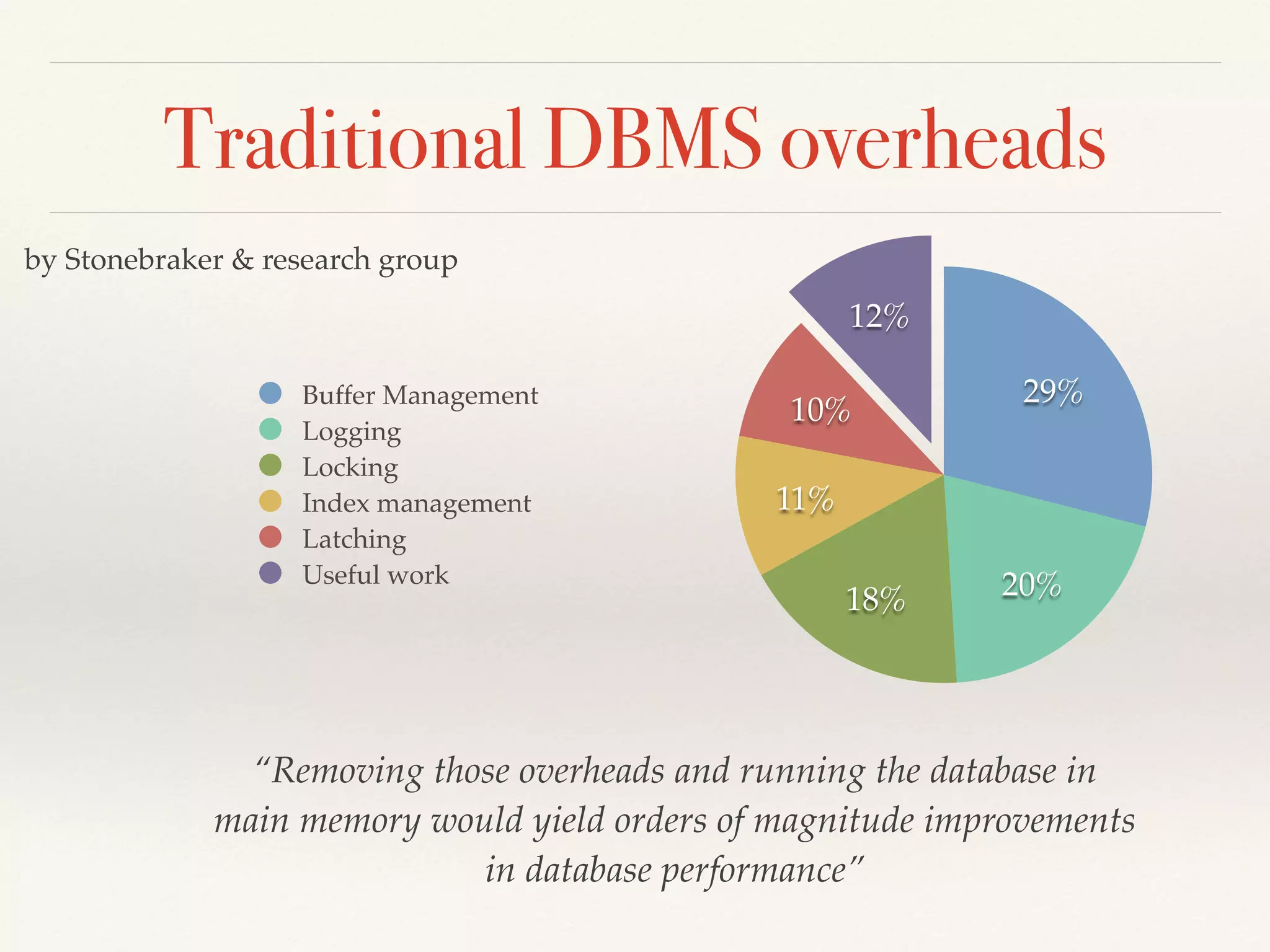
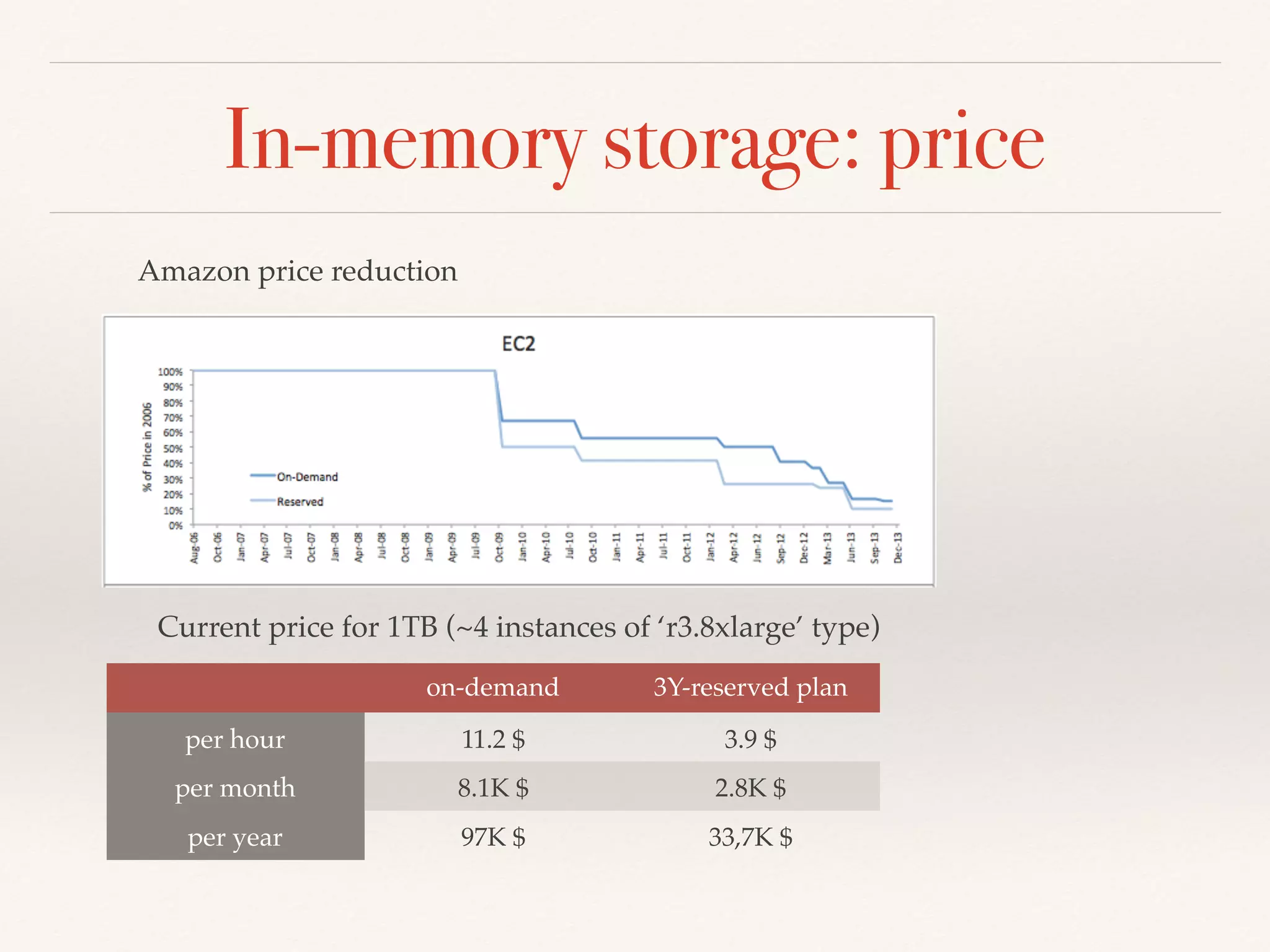
The document presents an overview of NewSQL databases, discussing their evolution from traditional SQL and NoSQL systems, and emphasizing their scalability and support for ACID transactions. It outlines various NewSQL implementations and their distinguishing features, highlighting trends in database architecture, performance, and storage optimization. Additionally, it addresses challenges in cross-sharding transactions and provides benchmarks for performance evaluation.













![[오픈소스컨설팅] Open Stack Ceph, Neutron, HA, Multi-Region](https://cdn.slidesharecdn.com/ss_thumbnails/openstackoscv0-160718105826-thumbnail.jpg?width=640&height=640&fit=bounds)



![[OpenInfra Days Korea 2018] Day 1 - T4-7: "Ceph 스토리지, PaaS로 서비스 운영하기"](https://cdn.slidesharecdn.com/ss_thumbnails/47openinfradaykorea2018hyun-ha-180705032301-thumbnail.jpg?width=640&height=640&fit=bounds)




![[MeetUp][1st] 오리뎅이의_쿠버네티스_네트워킹](https://cdn.slidesharecdn.com/ss_thumbnails/3-191024235922-thumbnail.jpg?width=640&height=640&fit=bounds)

![[OpenStack] 공개 소프트웨어 오픈스택 입문 & 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/opensource-skimmingopenstackwithkoreausergroup-180824144737-thumbnail.jpg?width=640&height=640&fit=bounds)

















































