


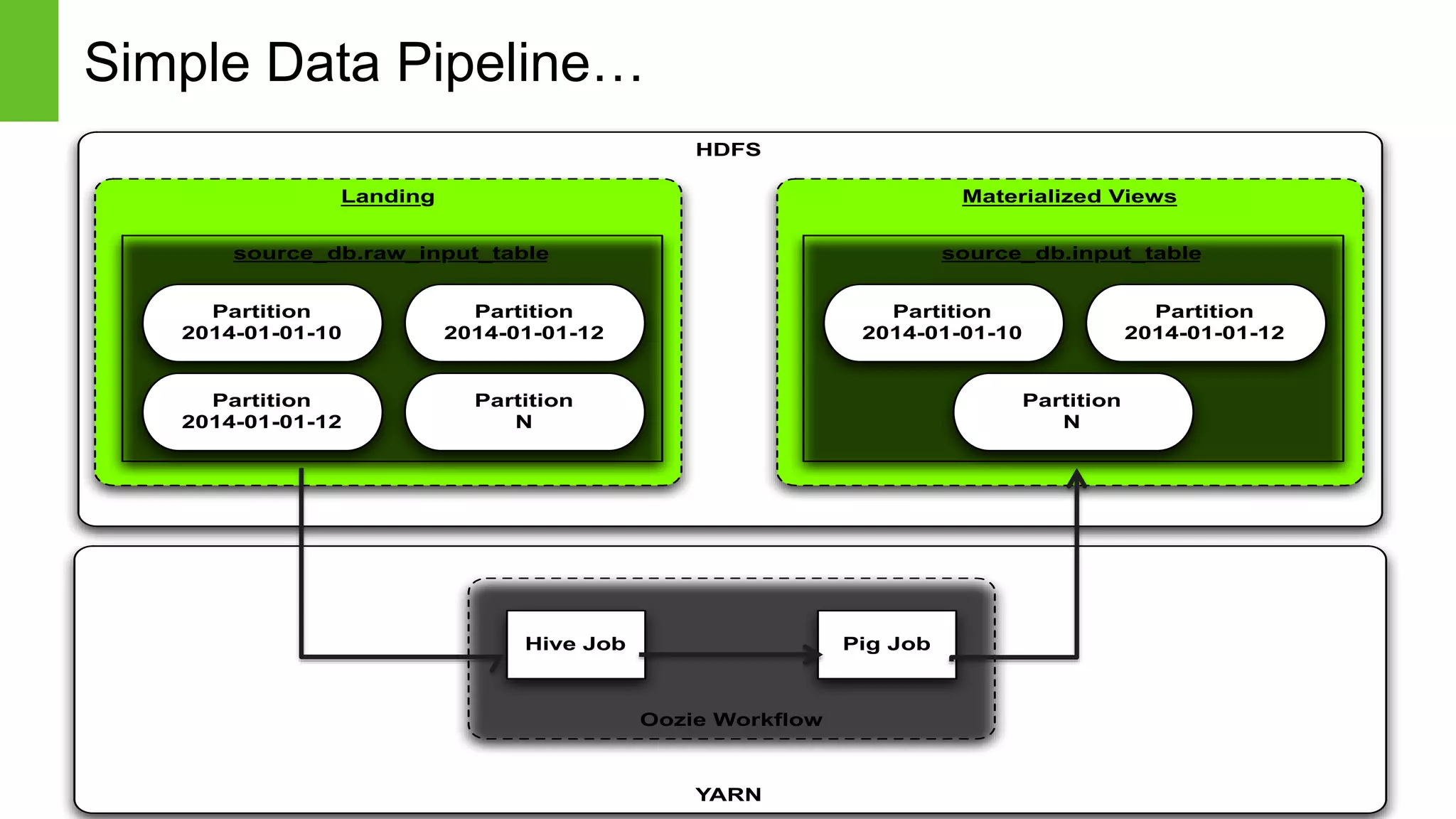
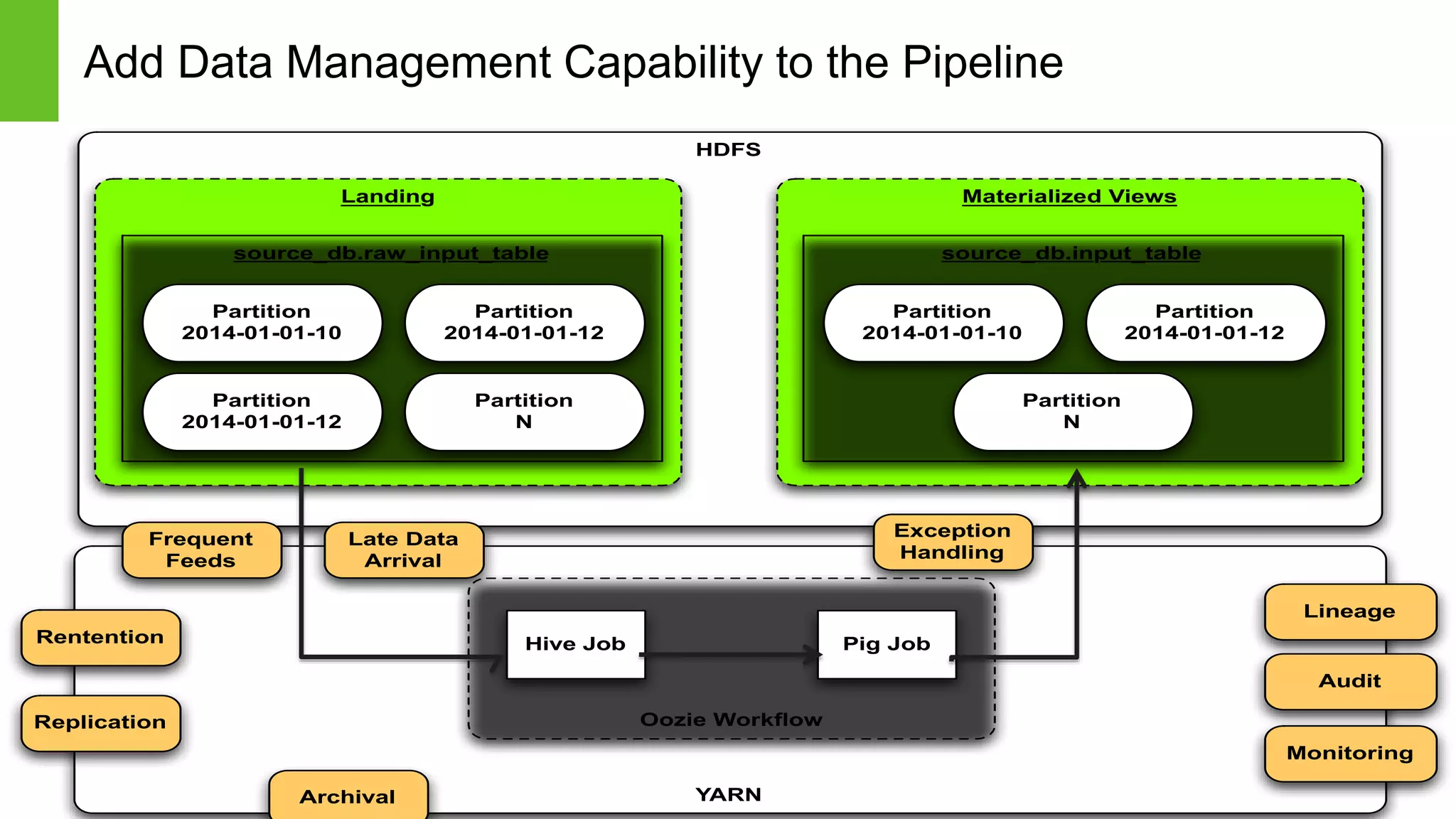
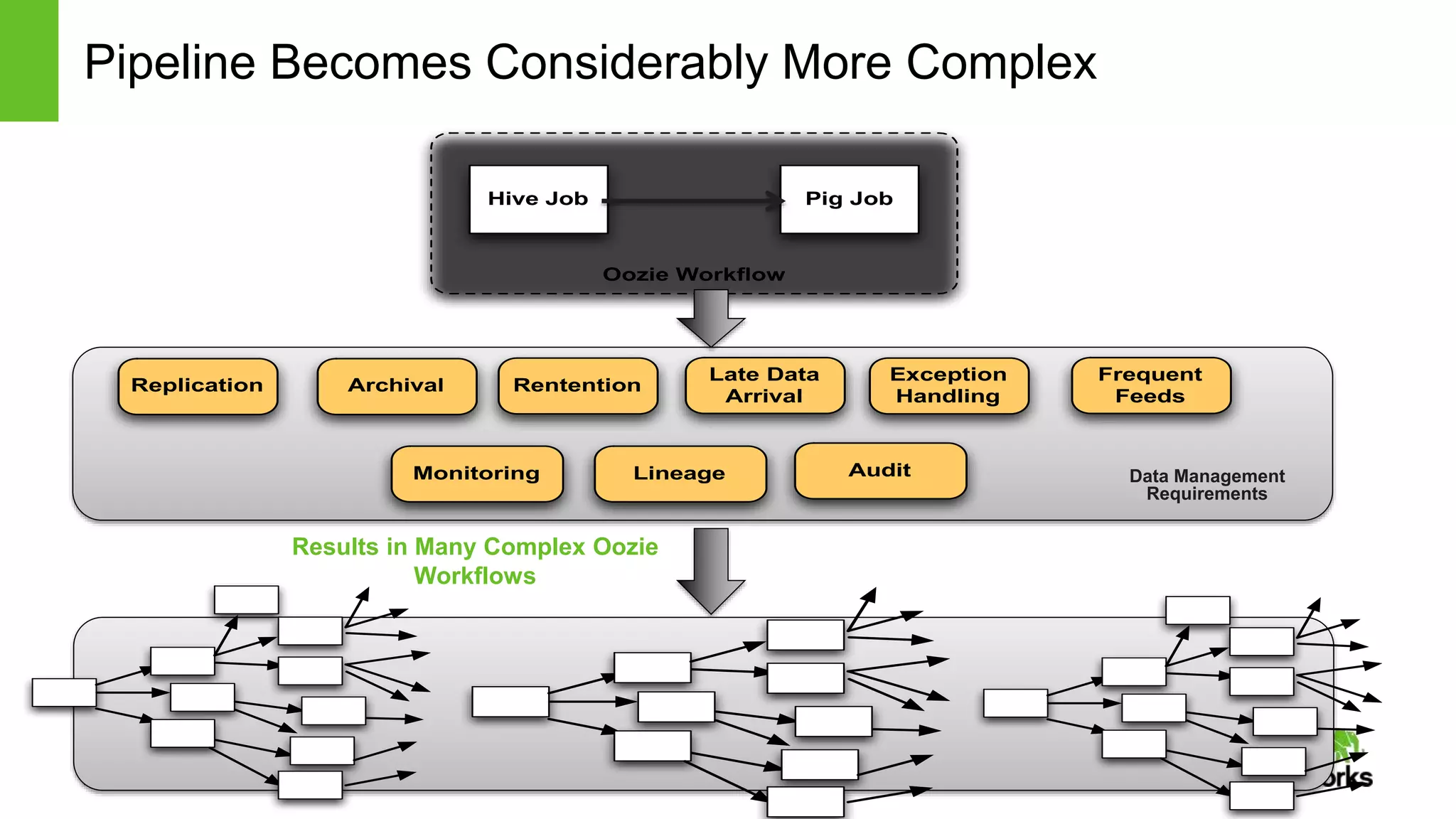


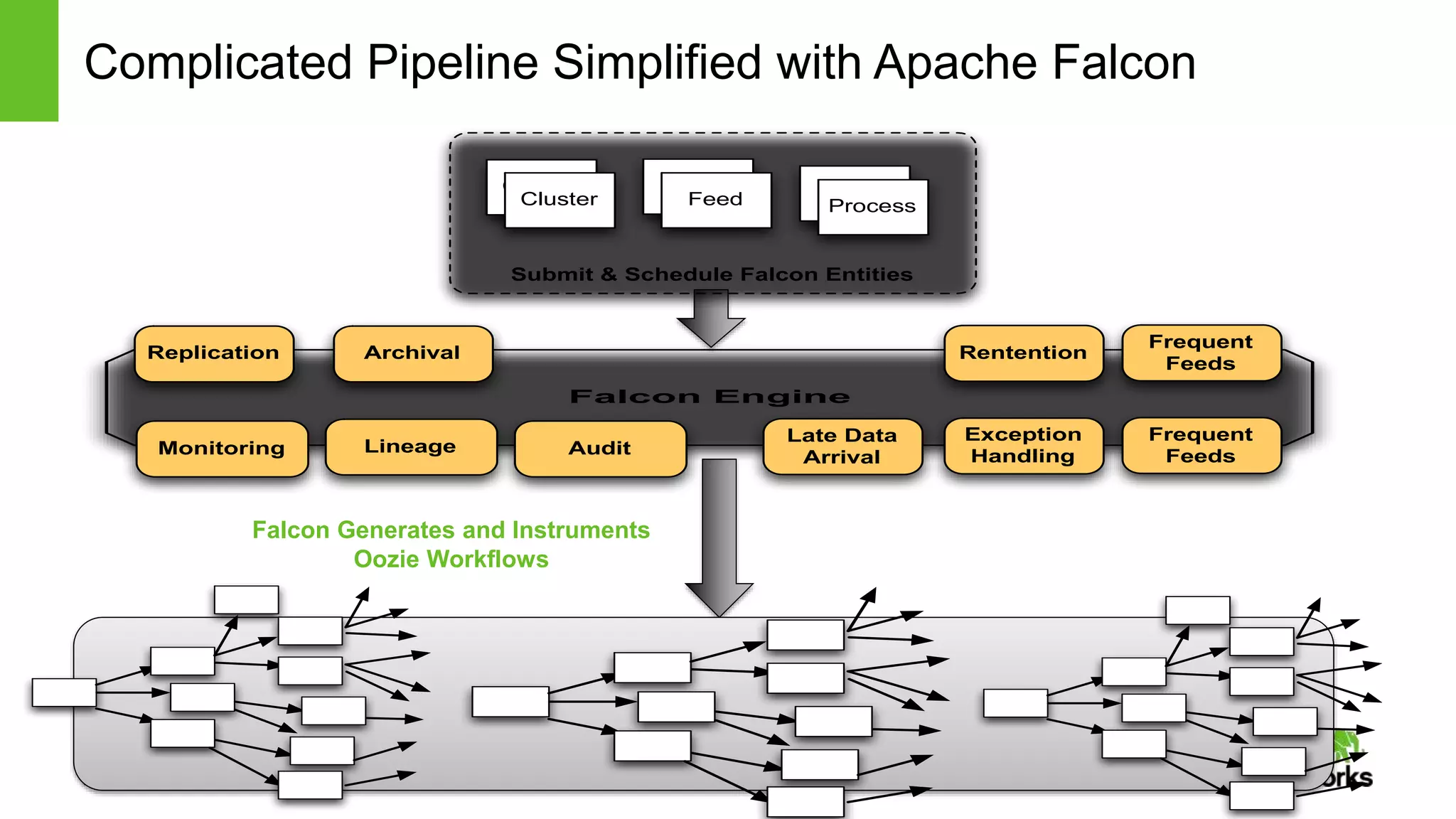
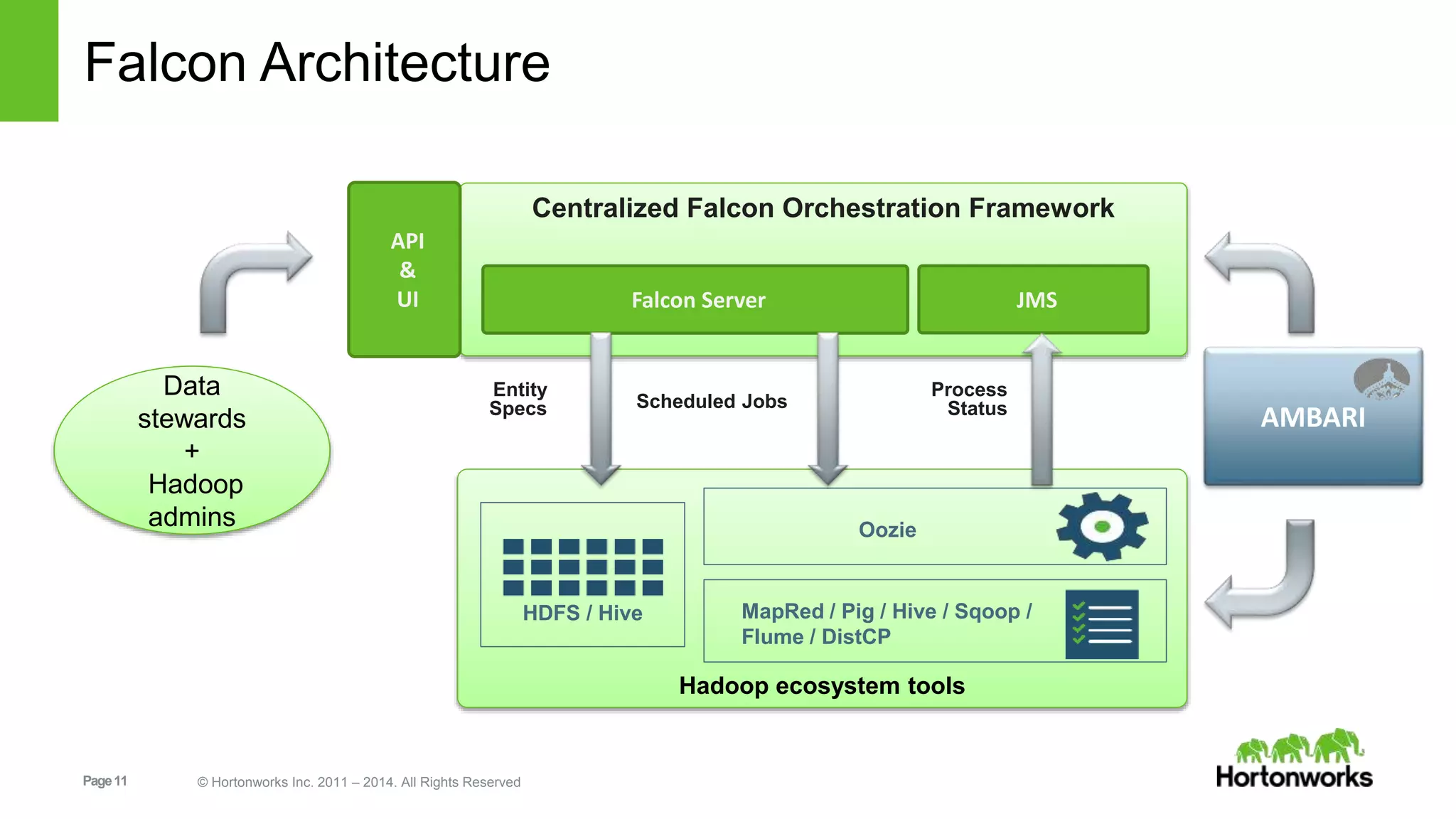
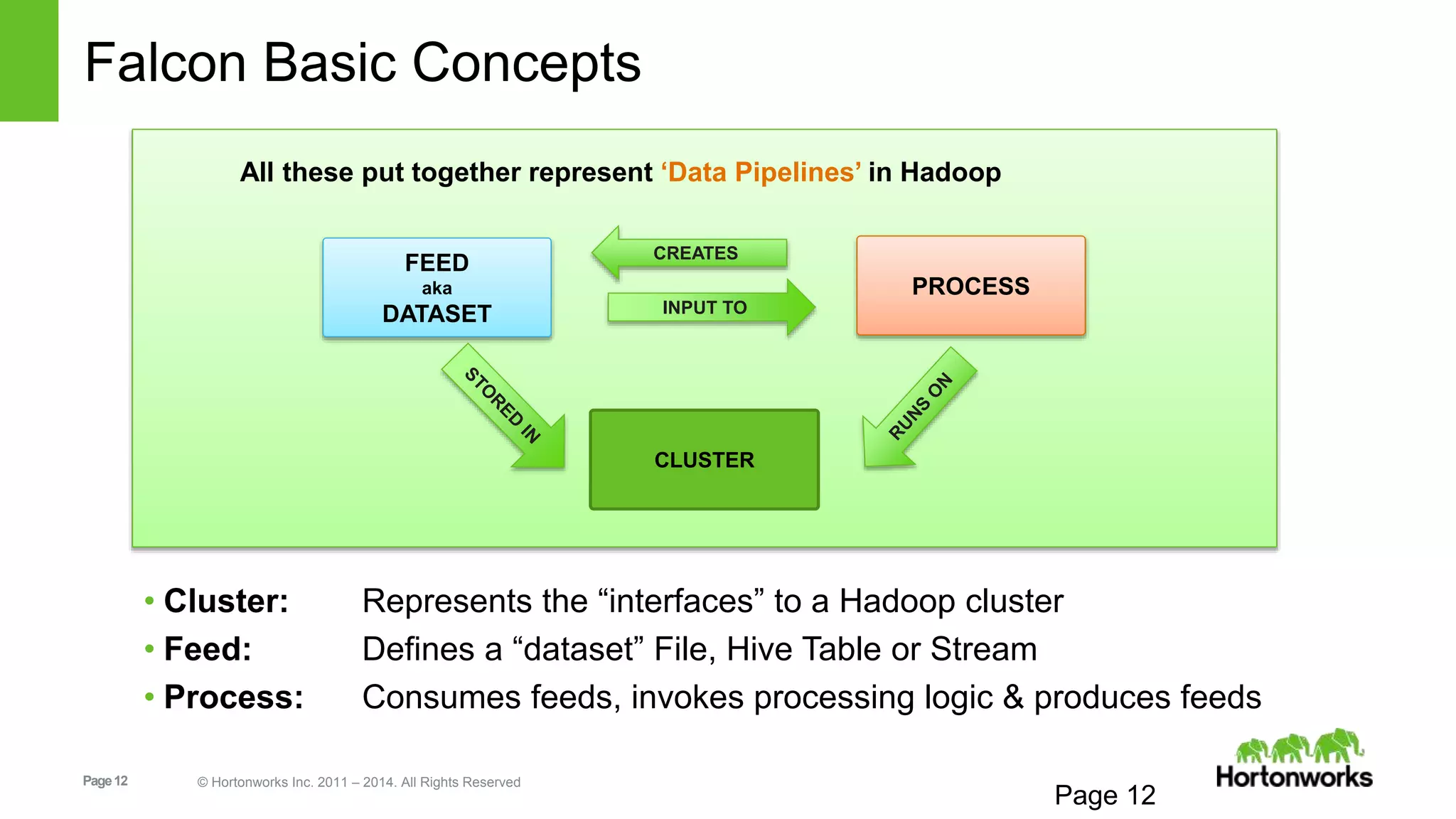

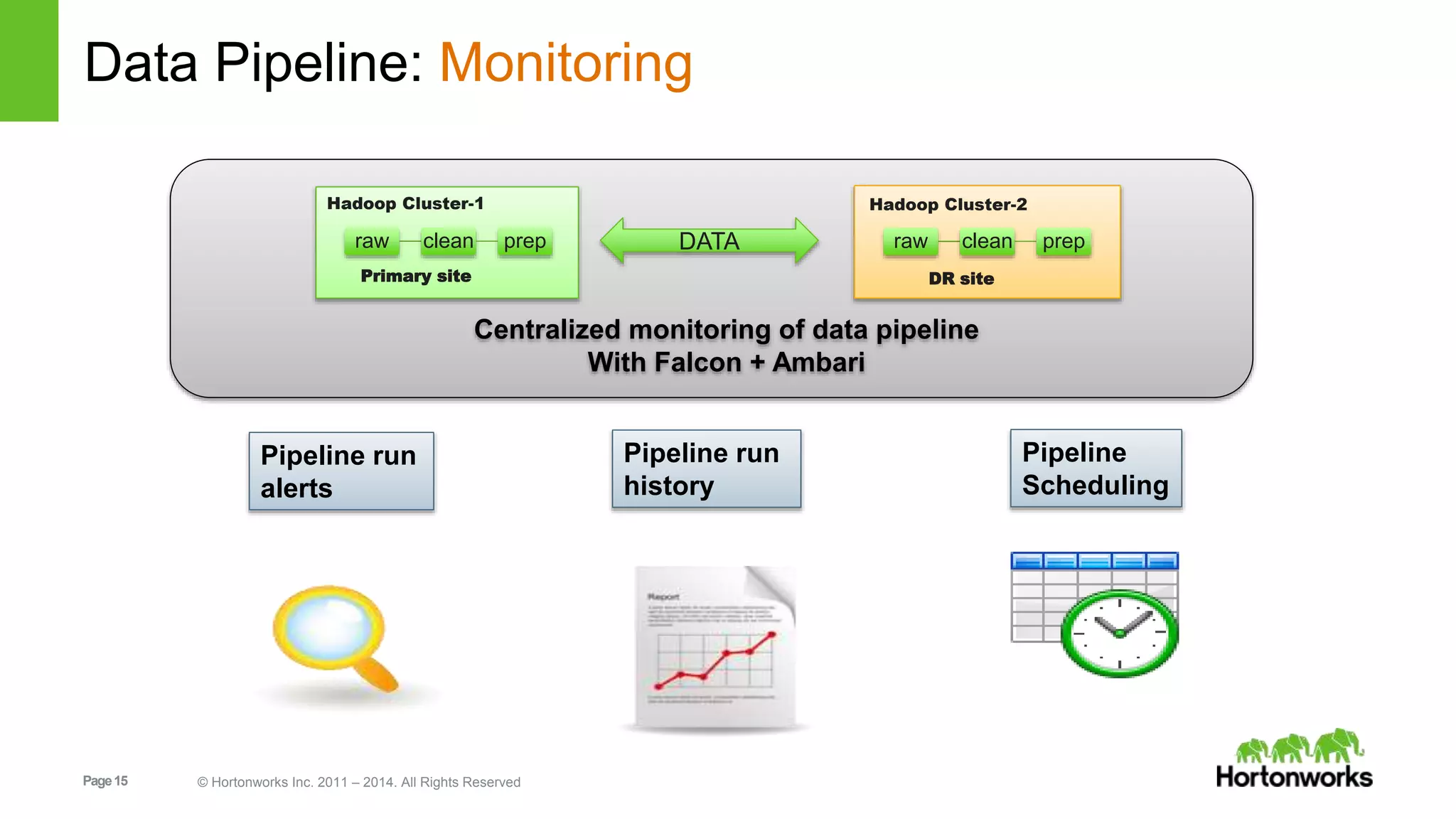
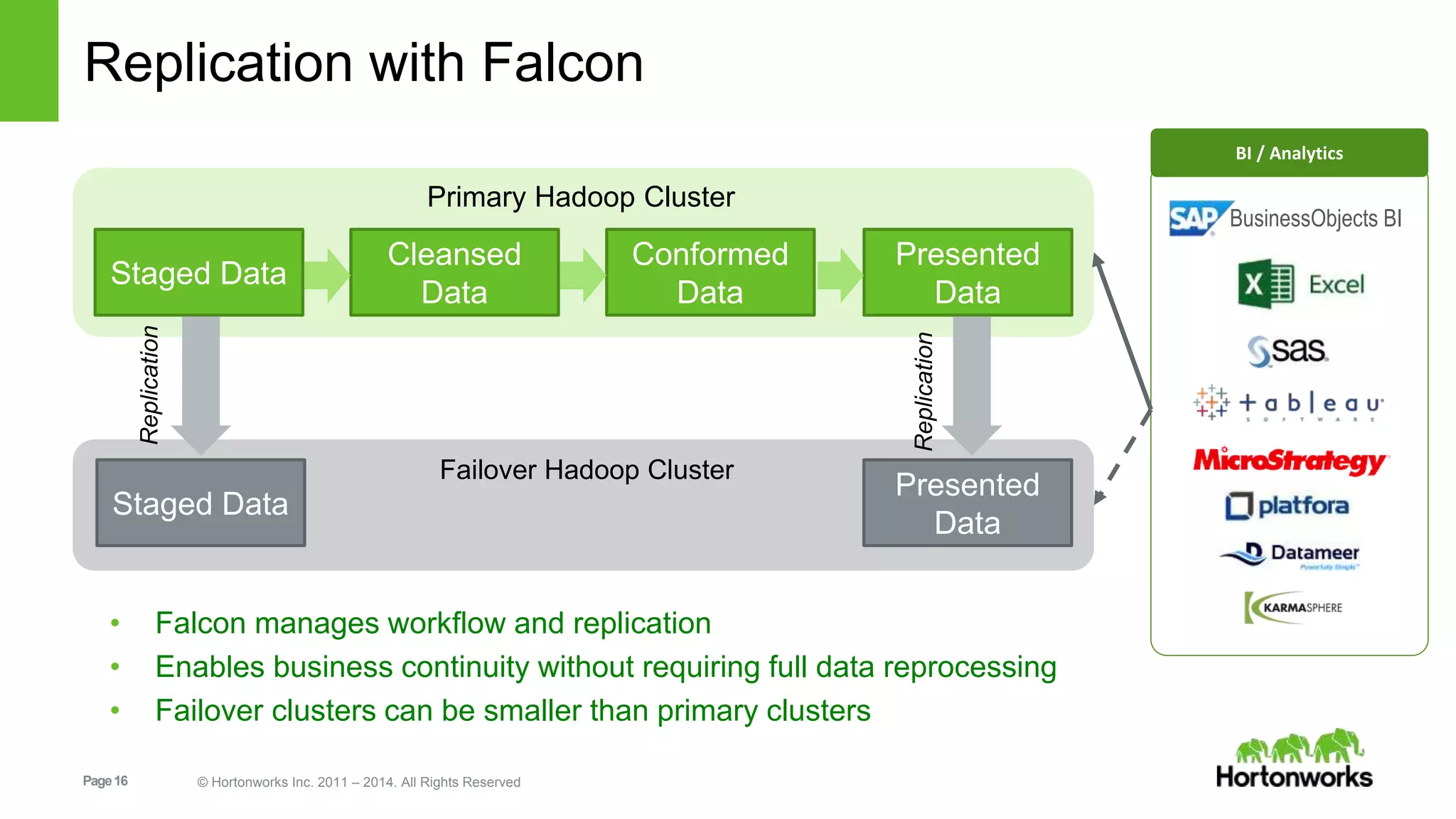
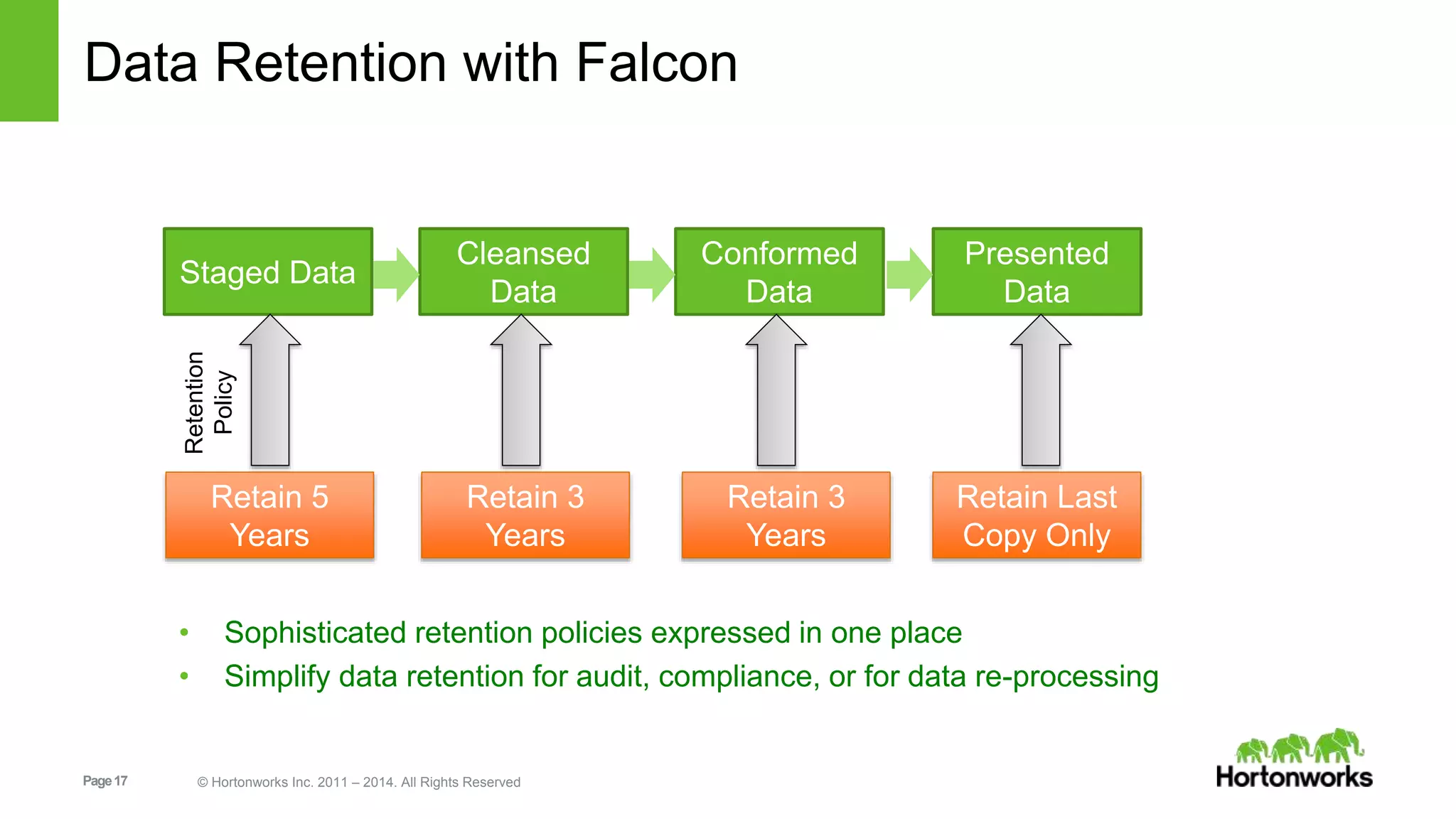



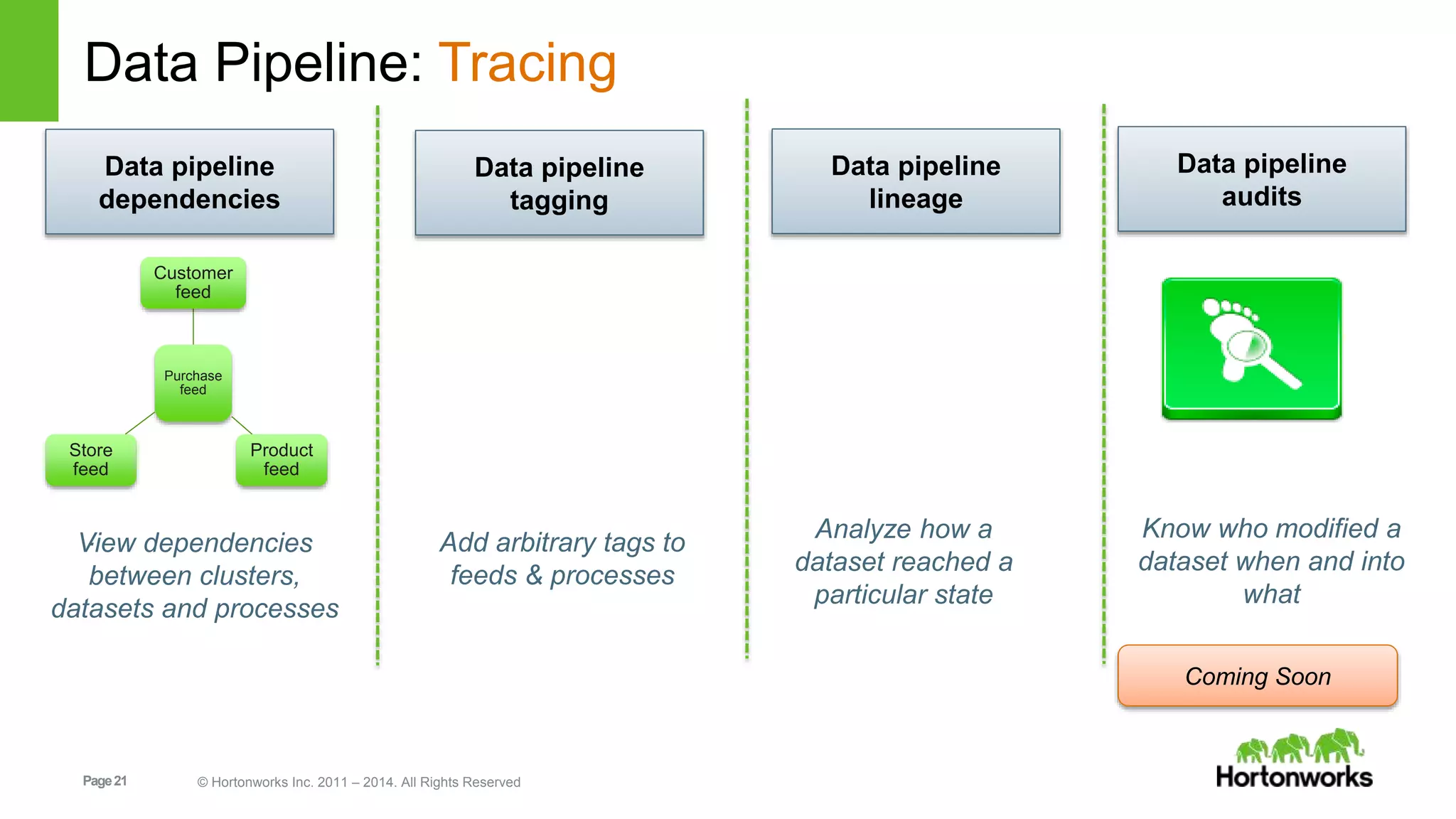

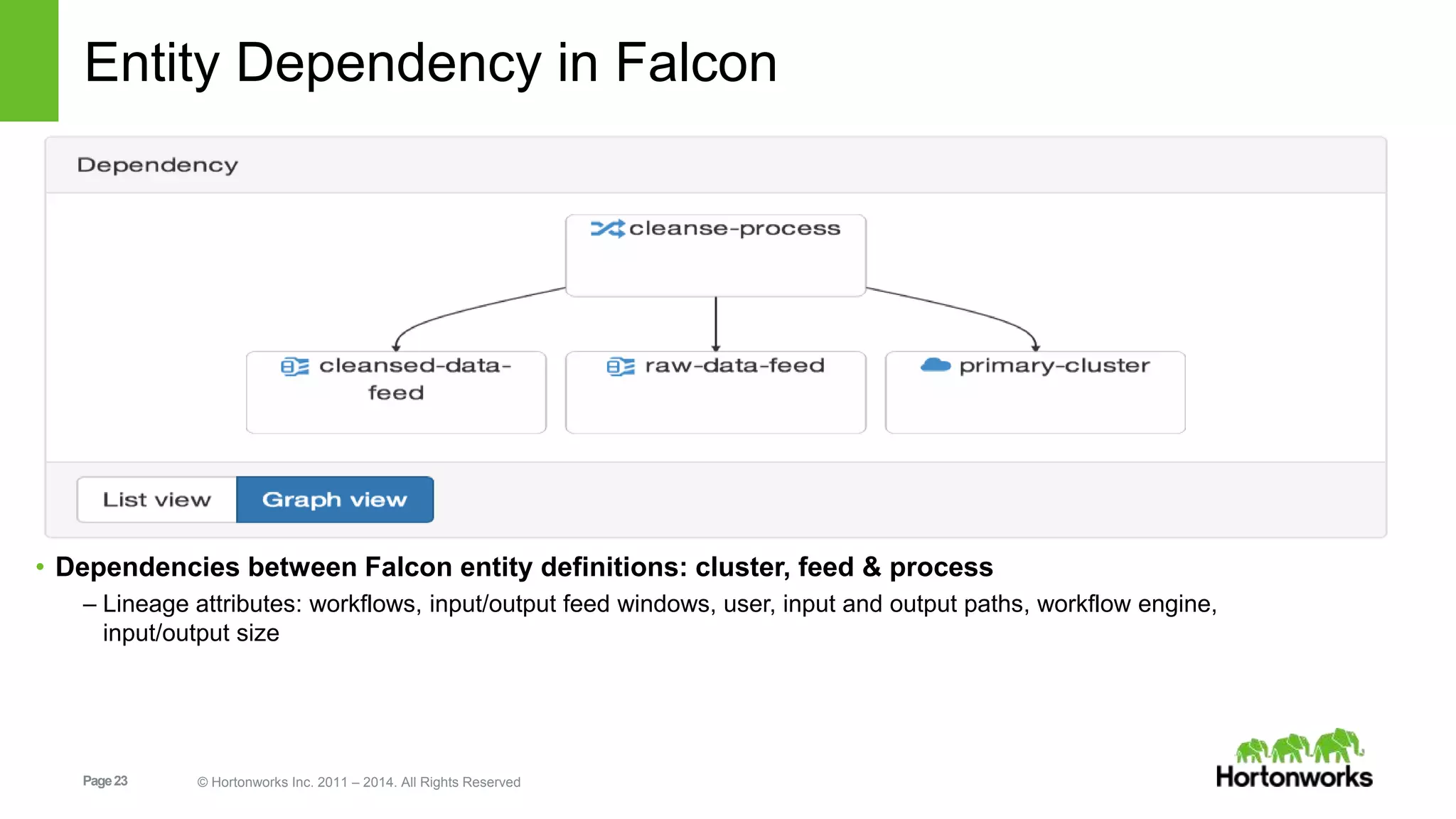
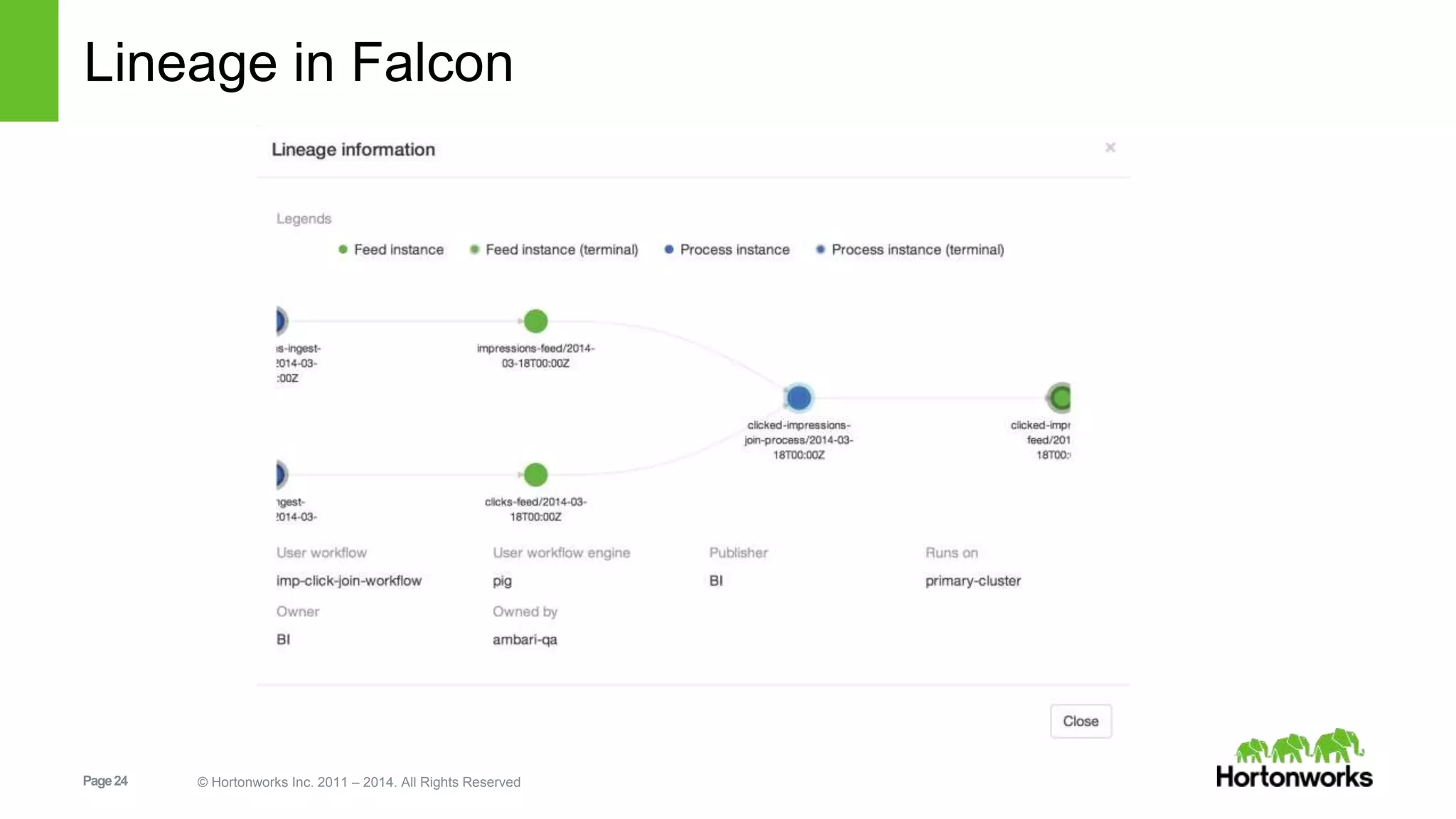



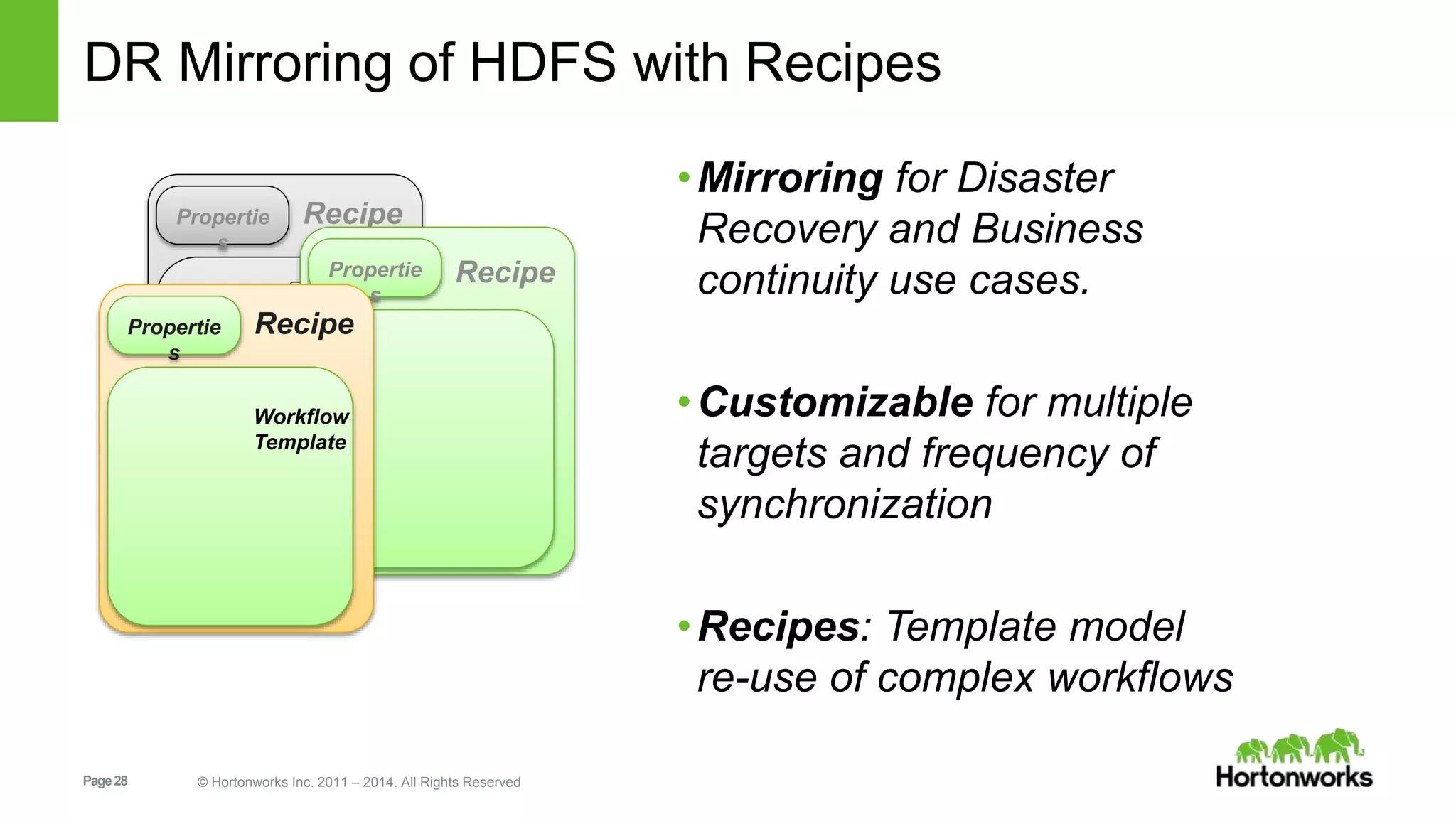
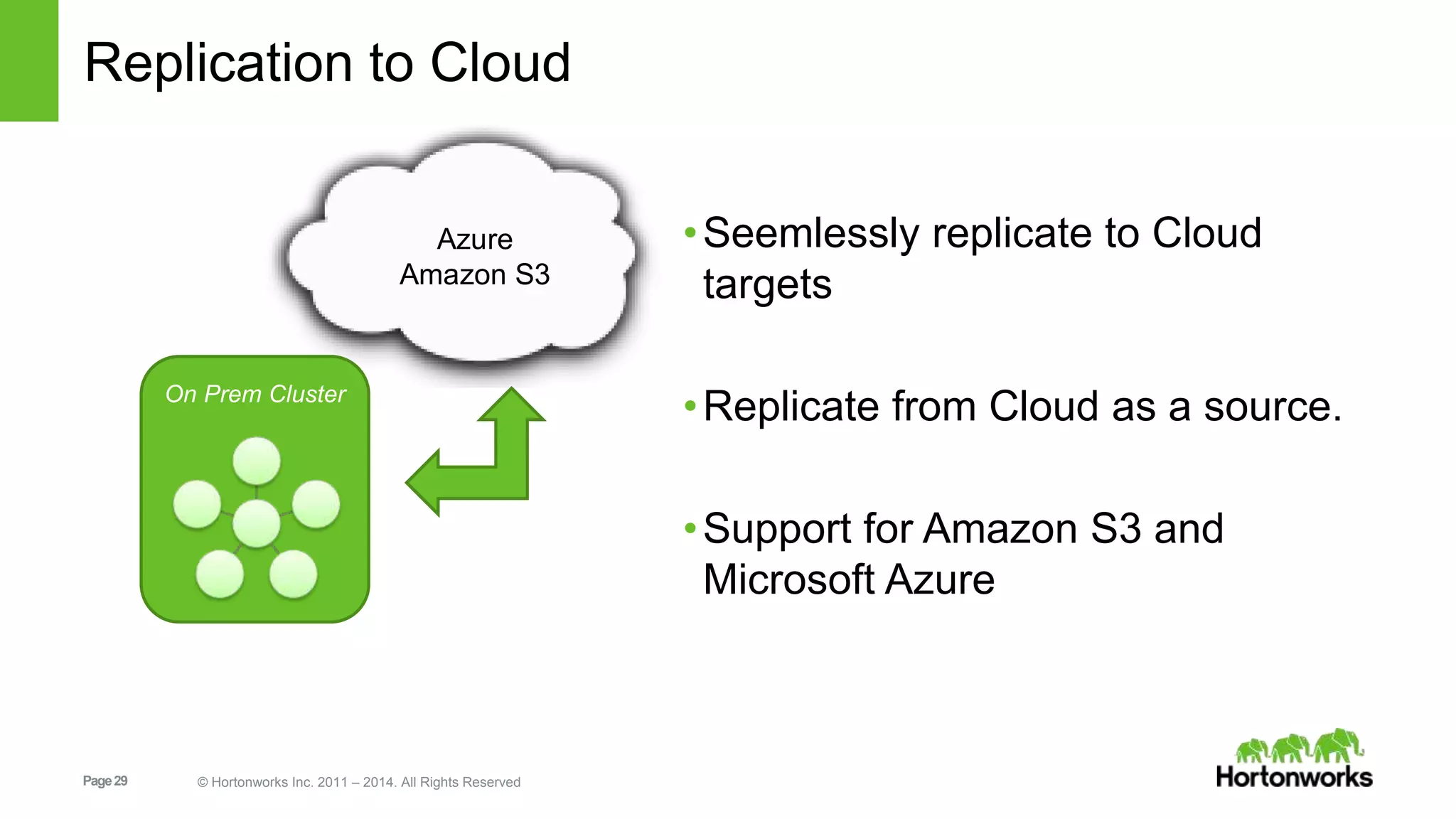
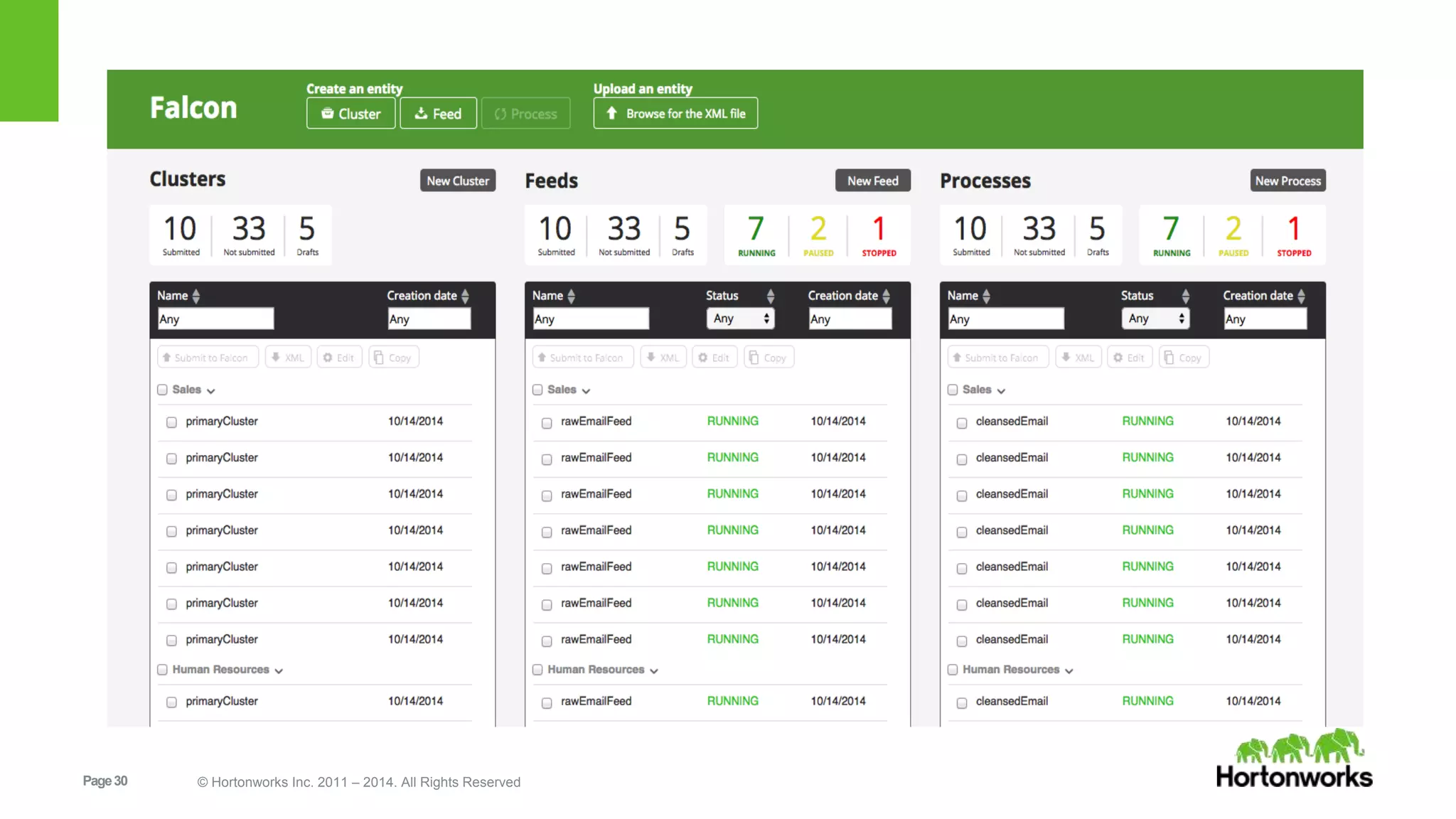
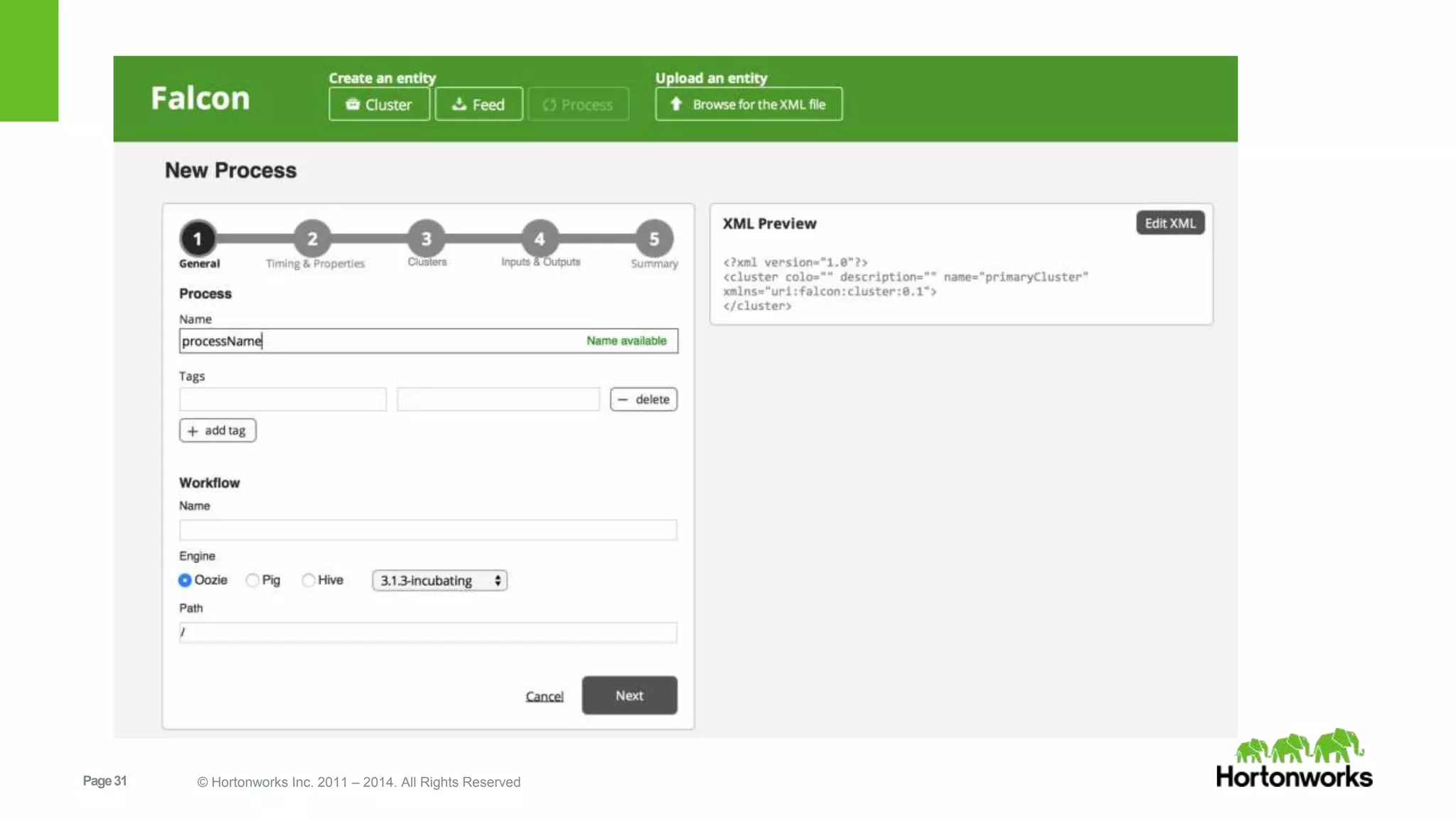
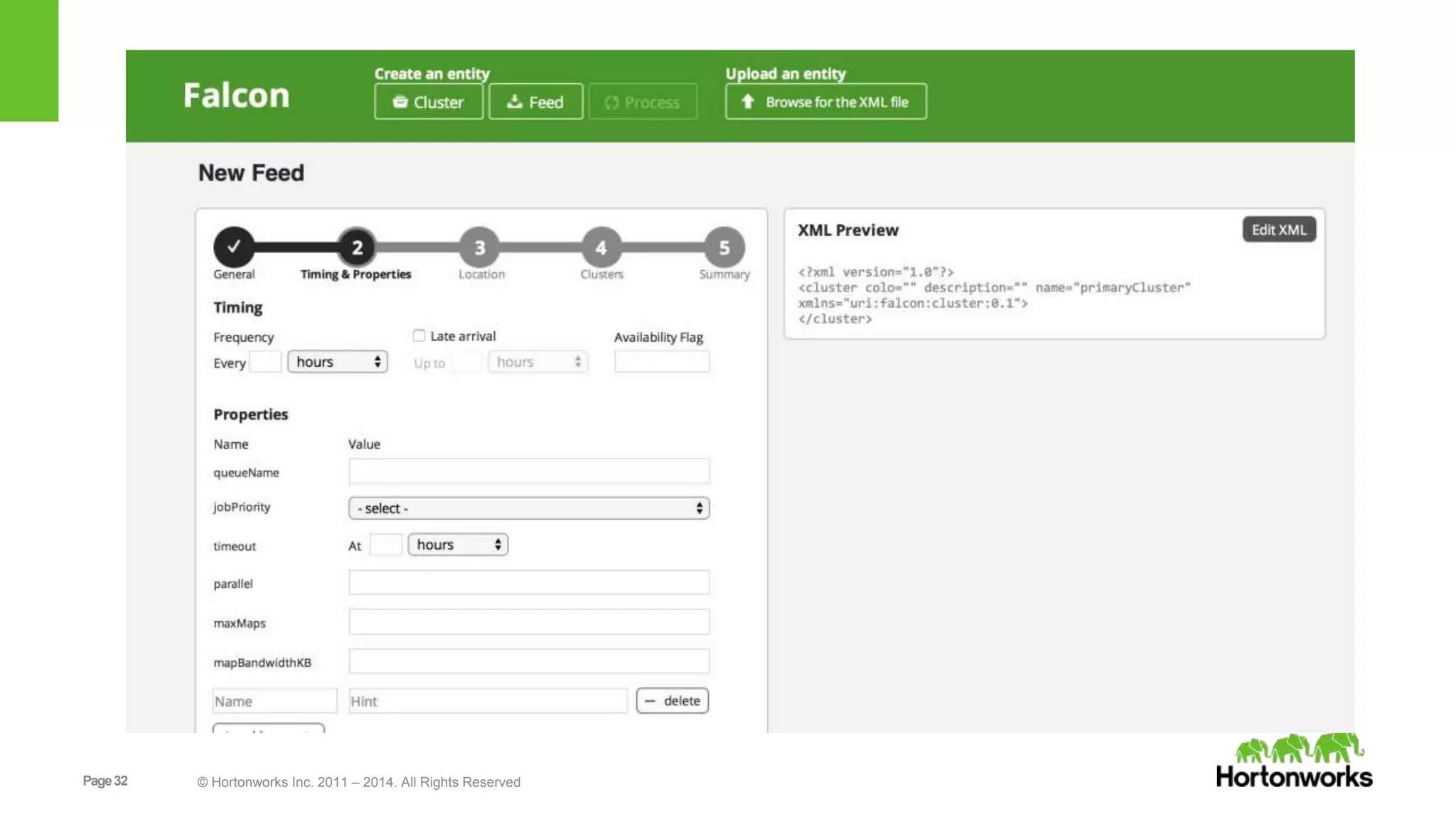
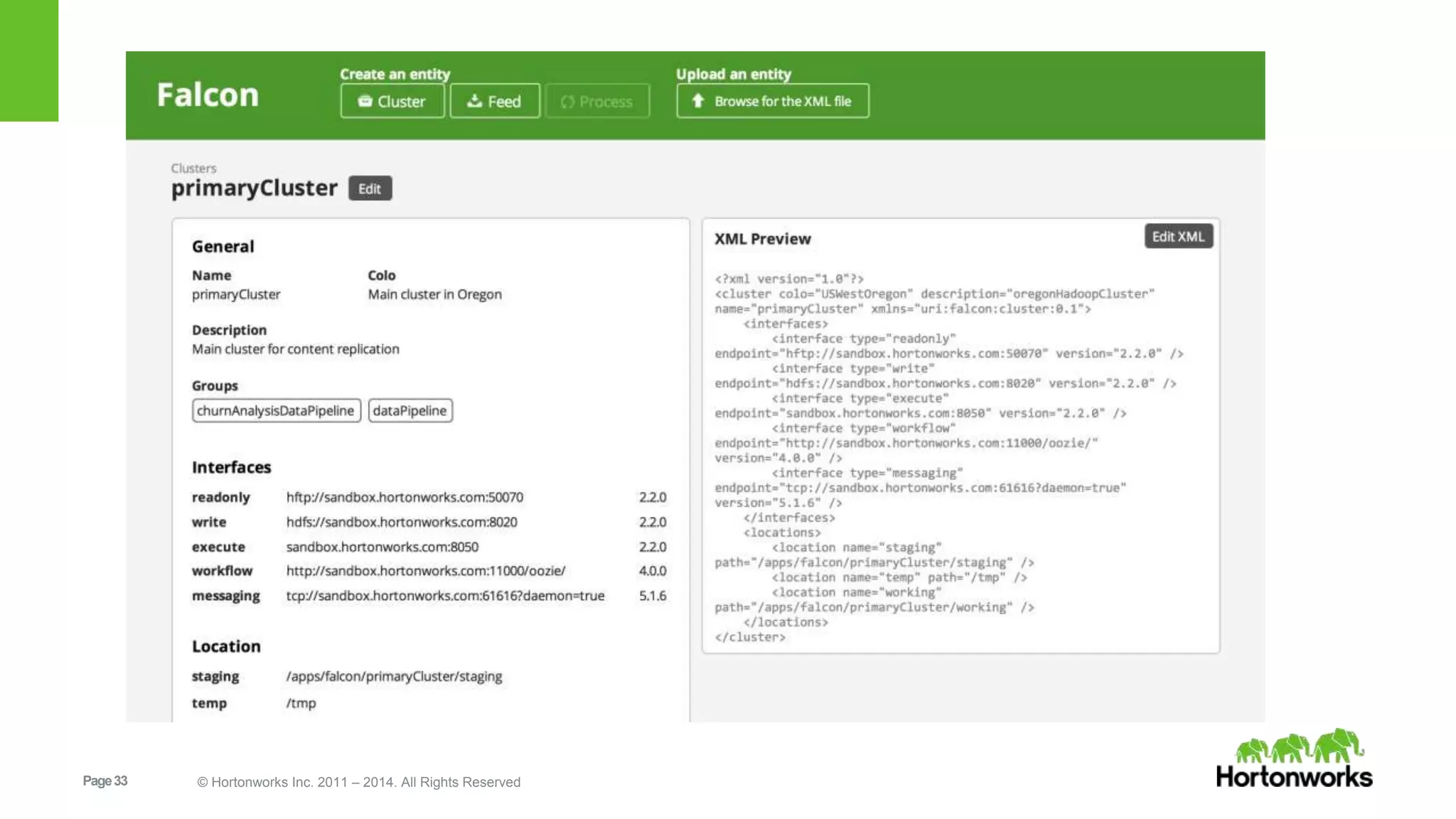
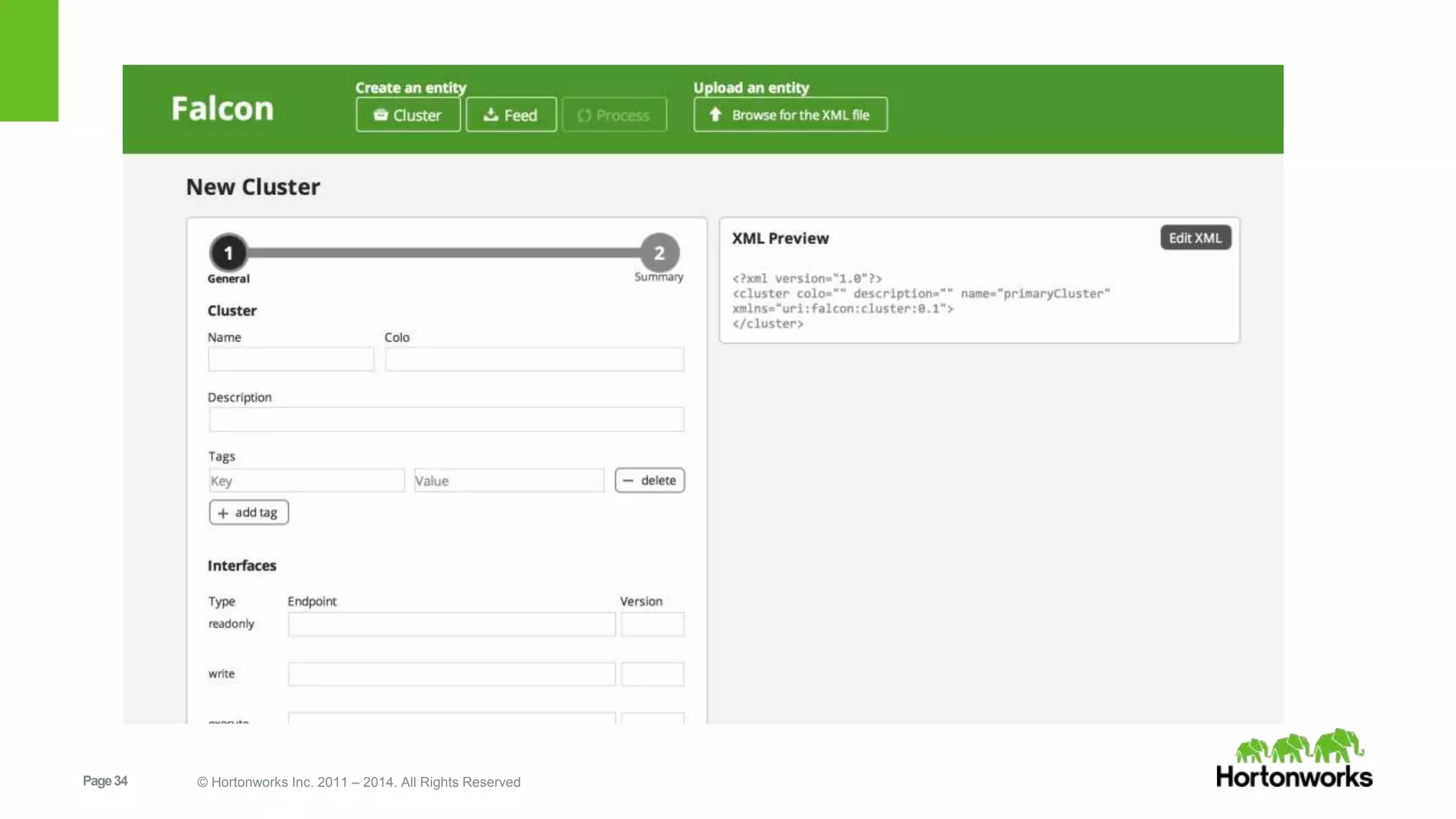
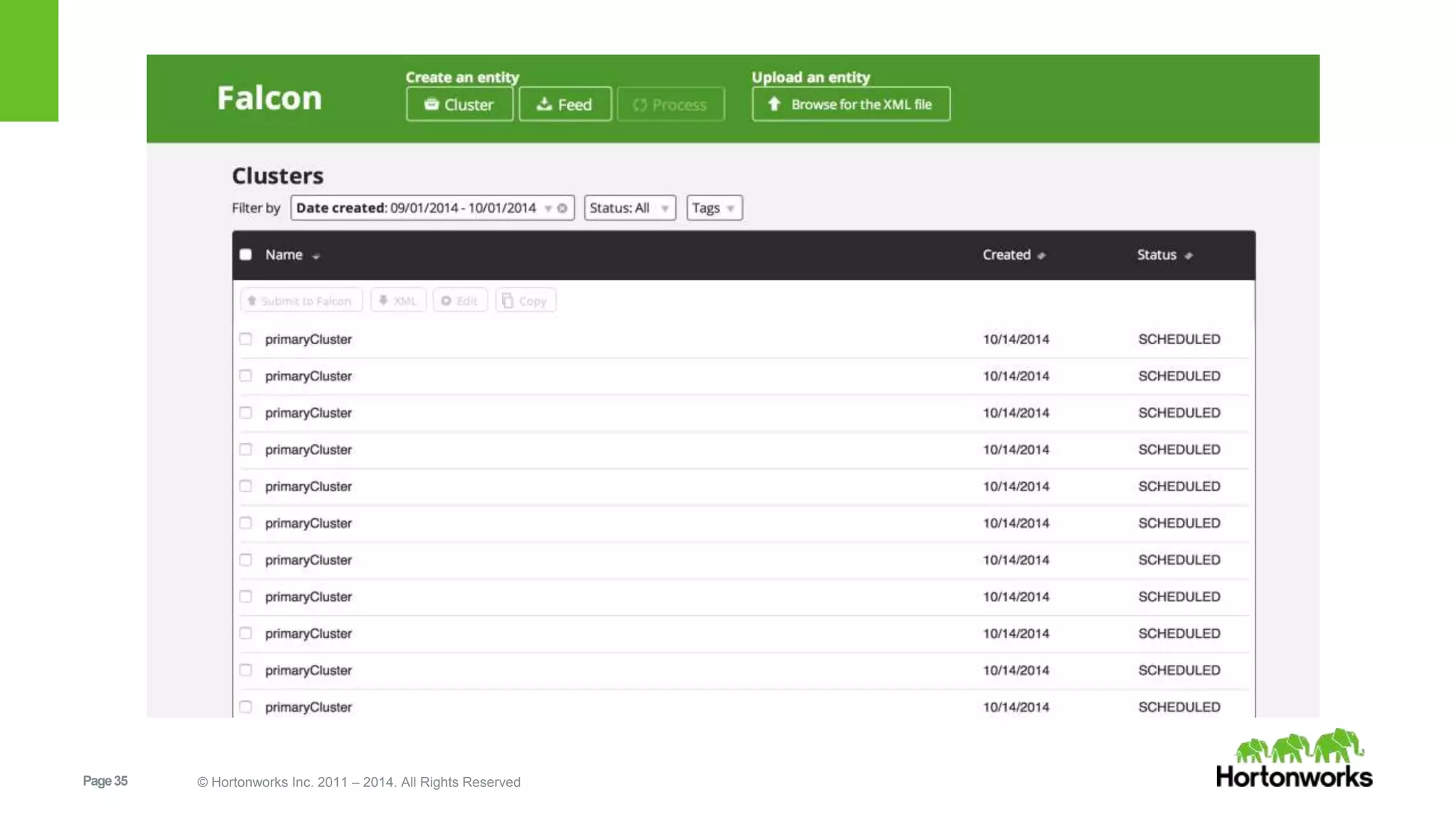


The document provides an overview of Apache Falcon, focusing on its capabilities for managing data pipelines in the Hadoop ecosystem. Key features include centralized lifecycle management, data governance, monitoring, and audit compliance, as well as support for complex data processing and replication. It also discusses Falcon's architecture, basic concepts, and new features for disaster recovery and cloud replication.































































































