Downloaded 107 times








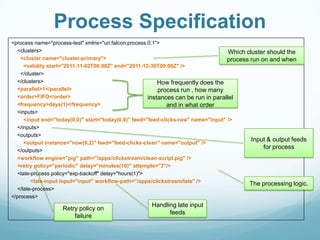

![Retry Policies
Each Process can define retry policy
<process name="[process name]">
...
<retry policy=[retry policy] delay=[retry delay]attempts=[attempts]/>
<retry policy="backoff" delay="minutes(10)" attempts="3"/>
...
</process>
Policies include:
backoff
exp-backoff](https://image.slidesharecdn.com/falcon-hadoop-summit-europe-2014-140410151143-phpapp02/85/Apache-Falcon-at-Hadoop-Summit-Europe-2014-14-320.jpg)



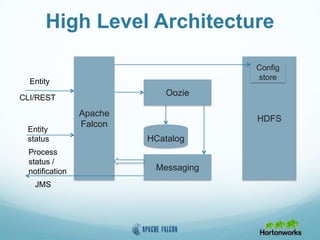
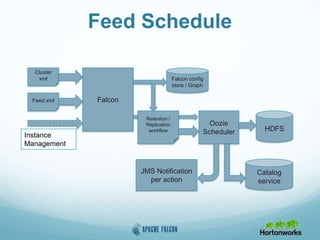
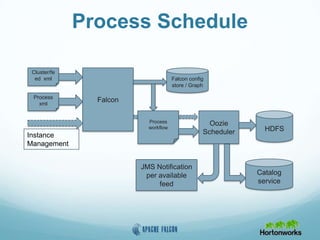
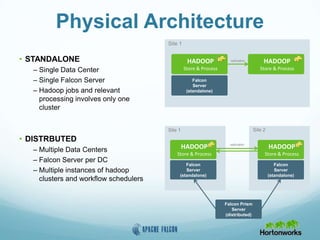




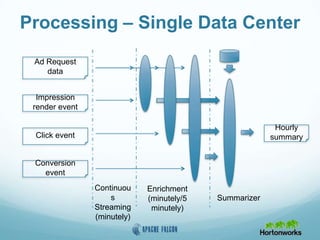
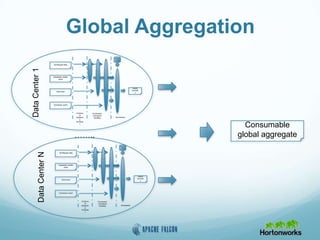

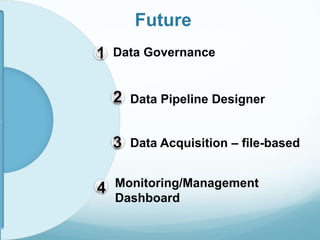
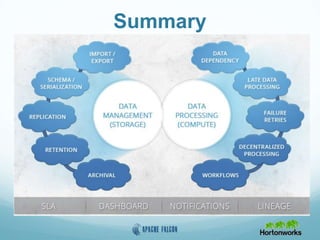


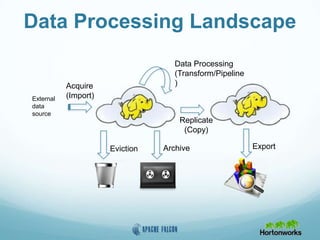
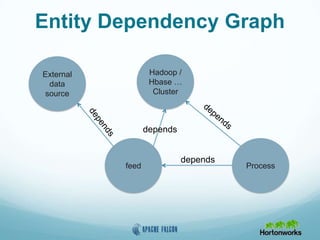
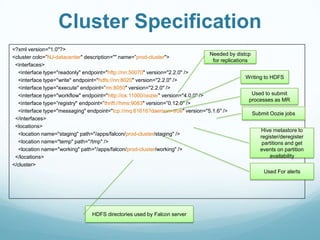
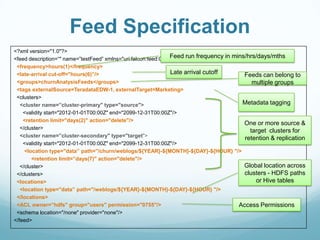
This document provides an overview of Apache Falcon, a data management platform on Hadoop. It describes Falcon's capabilities for orchestrating data pipelines across multiple Hadoop clusters through a declarative model. Key points include: - Falcon allows holistic declaration of data flows, including feeds, processes, dependencies, and late data handling policies. - It uses Oozie workflows to schedule and execute data pipelines across clusters based on the declared model. - Falcon supports features like replication, retention, scheduling, and data governance. - Case studies demonstrate how Falcon can orchestrate multi-cluster failover and distributed processing across data centers.














![Discover.hdp2.2.h base.final[2]](https://cdn.slidesharecdn.com/ss_thumbnails/discover-141218155001-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



















































