Download as PDF, PPTX


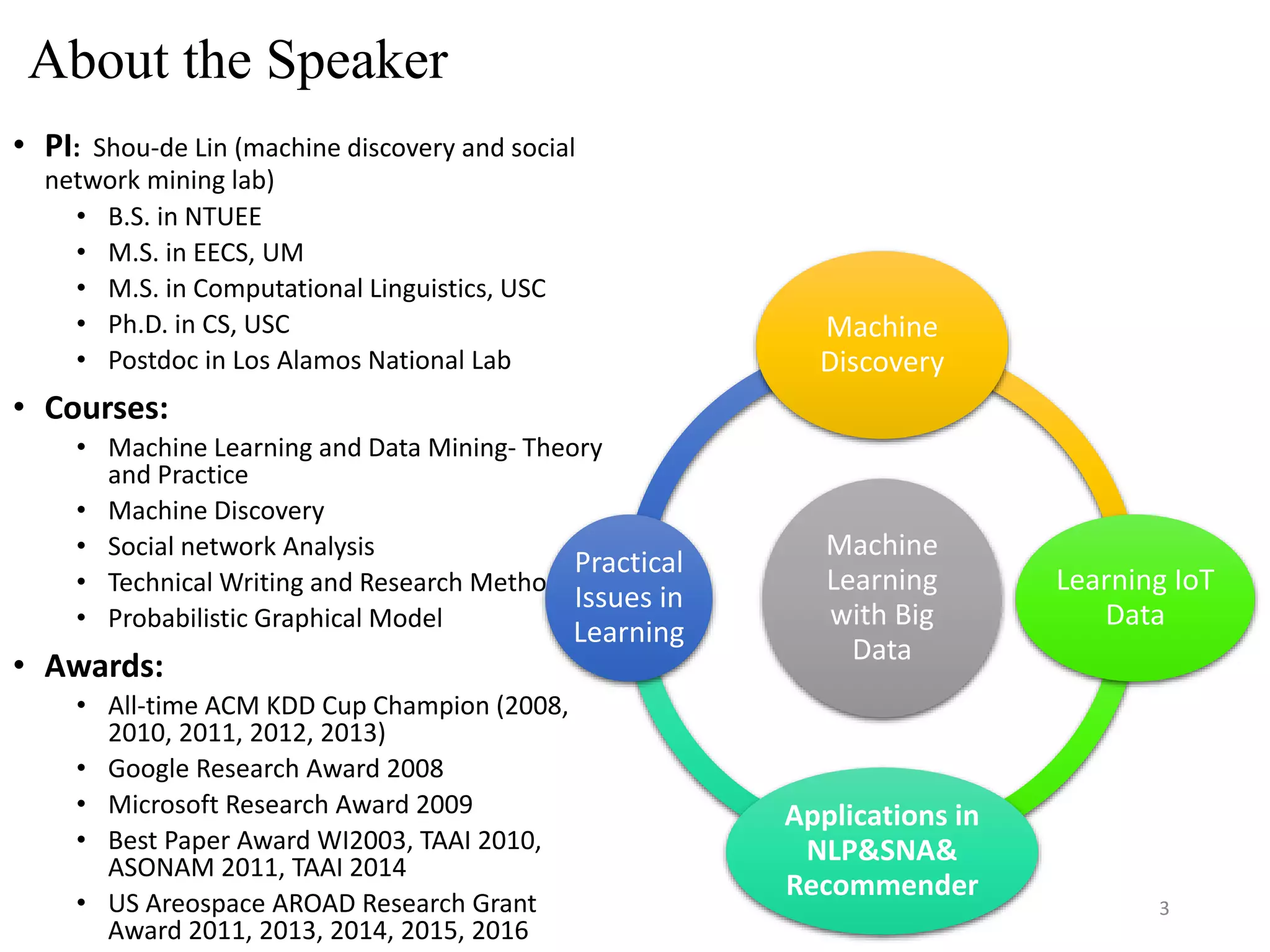










































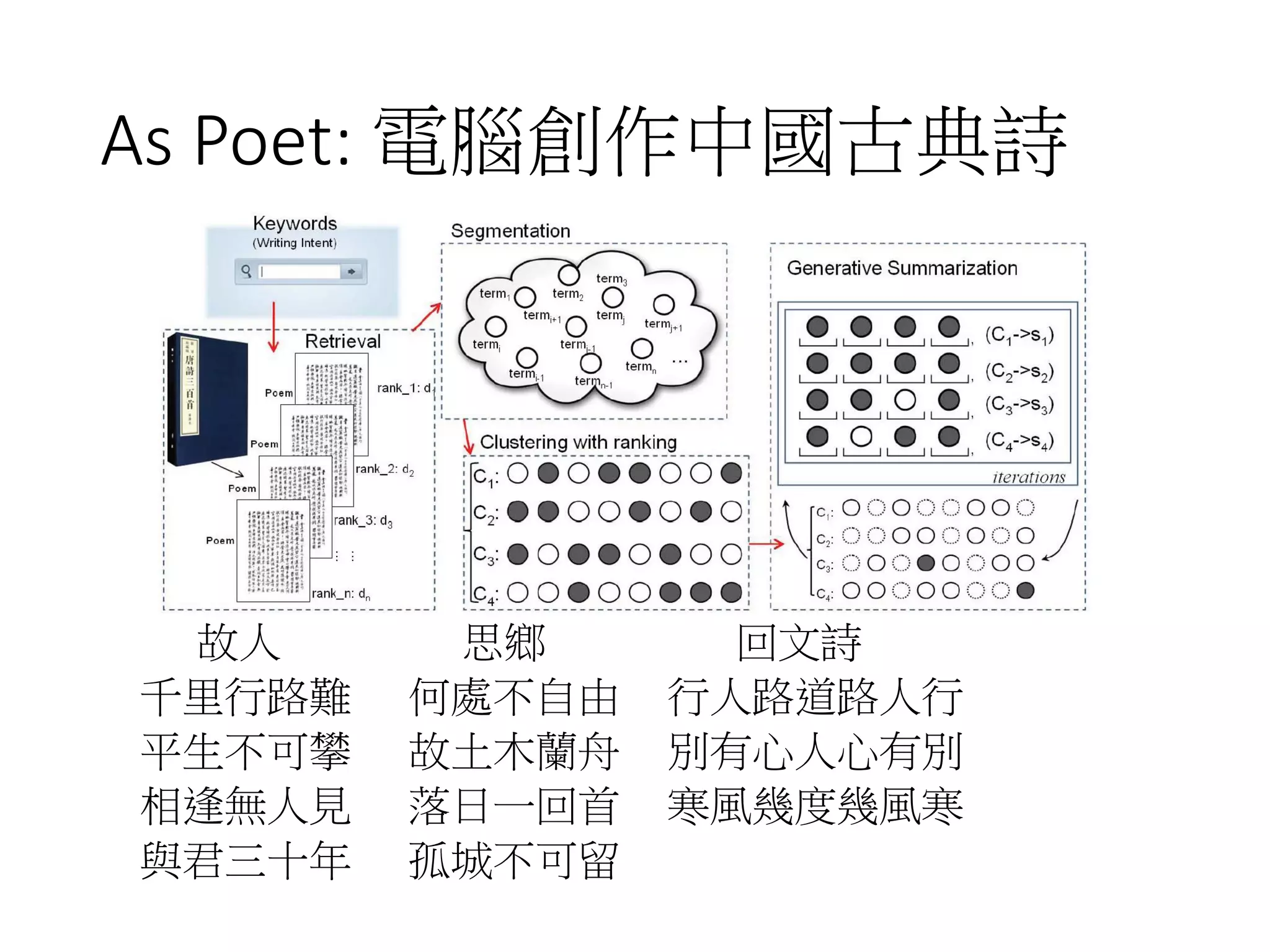
























![Semi-supervised Learning
• Only a small
portion of data
are annotated
(usually due to
high annotation
cost)
• Leverage the
unlabeled data
for better
performance
16
[Zhu2008]](https://image.slidesharecdn.com/md-161124235136/75/DSC-x-TAAI-2016-71-2048.jpg)










![Transfer Learning
• Example: the knowledge for
recognizing an airplane may
be helpful for recognizing a
bird.
• Improving a learning task via incorporating
knowledge from learning tasks in other domains with
different feature space and data distribution.
• Reduces expensive data-labeling efforts
[Pan & Yang 2010]
2016/11/24 27
• Approach categories:
(1) Instance-transfer
(2) Feature-representation-transfer
(3) Parameter-transfer
(4) Relational-knowledge-transfer](https://image.slidesharecdn.com/md-161124235136/75/DSC-x-TAAI-2016-82-2048.jpg)





























































































![Ranking of Recommendations
• Discounted cumulative gain (DCG)
• 𝐷𝐶𝐺 =
1
|𝑈| 𝑢 𝑖∈𝑈 𝑗=1
𝐿 𝑅 𝑖,𝑗
max{1,log2 𝑗}
• There are 𝐿 items in the ranked list
• 𝑈: User set
• Spearman’s rank correlation: For 𝑛 items
• 𝜌 = 1 −
6 𝑖=1
𝑛
𝑥 𝑖−𝑦 𝑖
2
𝑛3−𝑛
• 1 ≤ 𝑥𝑖 ≤ 𝑛: Predicted rank of item 𝑖
• 1 ≤ 𝑦𝑖 ≤ 𝑛: True rank of item 𝑖
• Kendall’s tau: For all 𝑛
2
pairs of items (𝑖, 𝑗)
• 𝜏 =
𝑐−𝑑
𝑛
2
, in range [−1,1]
• There are 𝑐 concordant pairs
• 𝑥𝑖 > 𝑥𝑗, 𝑦𝑖 > 𝑦𝑗 or 𝑥𝑖 < 𝑥𝑗, 𝑦𝑖 < 𝑦𝑗
• There are 𝑑 discordant pairs
• 𝑥𝑖 > 𝑥𝑗, 𝑦𝑖 < 𝑦𝑗 or 𝑥𝑖 < 𝑥𝑗, 𝑦𝑖 > 𝑦𝑗
70TAAI 16 Tutorial, Shou-de Lin](https://image.slidesharecdn.com/md-161124235136/75/DSC-x-TAAI-2016-176-2048.jpg)





































This document presents a comprehensive overview of artificial intelligence (AI), its historical developments, current applications, and future directions, specifically focusing on machine learning and recommendation systems. It discusses the evolution of AI from its theoretical foundations to practical uses across various domains including IoT, natural language processing, and e-commerce. The speaker, Professor Shou-de Lin, highlights significant milestones in AI, competitions that drive research, and potential future breakthroughs in machine discovery and human-computer interaction.


![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[系列活動] 一日搞懂生成式對抗網路](https://cdn.slidesharecdn.com/ss_thumbnails/gan-170813004356-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/merged-161217165734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 文字探勘者的入門心法](https://cdn.slidesharecdn.com/ss_thumbnails/textmininghandout-170320140215-170327095320-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 無所不在的自然語言處理—基礎概念、技術與工具介紹](https://cdn.slidesharecdn.com/ss_thumbnails/nlptutorial-0828-170830062001-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 機器學習速遊](https://cdn.slidesharecdn.com/ss_thumbnails/mltourhandout-170310083857-thumbnail.jpg?width=640&height=640&fit=bounds)

![[系列活動] 智慧城市中的時空大數據應用](https://cdn.slidesharecdn.com/ss_thumbnails/dscstbigdata1060211-170211004152-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 一天搞懂對話機器人](https://cdn.slidesharecdn.com/ss_thumbnails/onedaybot0422-170421235605-170422003351-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 手把手教你R語言資料分析實務](https://cdn.slidesharecdn.com/ss_thumbnails/stepbystepr20170114-170113030702-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 使用 R 語言建立自己的演算法交易事業](https://cdn.slidesharecdn.com/ss_thumbnails/rtradingbusiness-170115010649-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 手把手的深度學習實務](https://cdn.slidesharecdn.com/ss_thumbnails/slidesharestepbystepdl-161213072731-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] Python爬蟲實戰](https://cdn.slidesharecdn.com/ss_thumbnails/python-170809083644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] Python 程式語言起步走](https://cdn.slidesharecdn.com/ss_thumbnails/python20170812-170808043244-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] Machine Learning 機器學習課程](https://cdn.slidesharecdn.com/ss_thumbnails/ml4ds02122017-170212005829-thumbnail.jpg?width=640&height=640&fit=bounds)





![[系列活動] Data exploration with modern R](https://cdn.slidesharecdn.com/ss_thumbnails/dataexplorationwithmodernr1221-161219044516-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[台灣人工智慧學校] 人工智慧技術發展與應用](https://cdn.slidesharecdn.com/ss_thumbnails/version5-final-190319060225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 從經濟學看人工智慧產業應用](https://cdn.slidesharecdn.com/ss_thumbnails/1-the-application-of-ai-industry-from-economics-190108064940-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 工業 4.0 與智慧製造的發展趨勢與挑戰](https://cdn.slidesharecdn.com/ss_thumbnails/20190316jyh-horngchou-190315170336-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 深度學習與Kaggle實戰](https://cdn.slidesharecdn.com/ss_thumbnails/20181206003-181210031001-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 台北總校第三期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/tp3closingsw-190126030359-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台中分校] 第一期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/sw-ppt-181217031715-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 工業4.0潛力新應用! 多模式對話機器人](https://cdn.slidesharecdn.com/ss_thumbnails/20181206004-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] 智慧製造成真! 產線導入AI的致勝關鍵](https://cdn.slidesharecdn.com/ss_thumbnails/thu-hsu-190116063619-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2018 台灣人工智慧學校校友年會] 啟動物聯網新關鍵 - 未來由你「喚」醒 / 沈品勳](https://cdn.slidesharecdn.com/ss_thumbnails/20181117shengfn-181130083931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 開創台灣產業智慧轉型的新契機](https://cdn.slidesharecdn.com/ss_thumbnails/aiotforaiabytedchangho-190227081005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] 2019 台灣數位轉型 與產業升級趨勢觀察](https://cdn.slidesharecdn.com/ss_thumbnails/to-sheng-190116063620-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] Bridging AI to Precision Agriculture through IoT](https://cdn.slidesharecdn.com/ss_thumbnails/hc-2nd-openingai-school-181206104858-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 2019 台灣數位轉型與產業升級趨勢觀察](https://cdn.slidesharecdn.com/ss_thumbnails/20181206-001-181210031002-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] AI 引爆新工業革命,智慧機械首都台中轉型論壇](https://cdn.slidesharecdn.com/ss_thumbnails/aia-chen-190116063635-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] AI整合是重點! 竹科的關鍵轉型思維](https://cdn.slidesharecdn.com/ss_thumbnails/20181206002-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/openingsw-190315170512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 台中分校第二期開學典禮 - 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/tc2-opening1-compressed-190107034100-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 開創台灣產業智慧轉型的新契機](https://cdn.slidesharecdn.com/ss_thumbnails/aiinhealthcare-20190216victoria-v6-190227081004-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] 產業經驗分享: 如何用最少的訓練樣本,得到最好的深度學習影像分析結果,減少一半人力,提升一倍品質 / 李明達](https://cdn.slidesharecdn.com/ss_thumbnails/lee-181130104127-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
