Haskell文法紹介
f x =x + 1 -- 関数定義
f = ¥x -> x + 1 -- ラムダ式(関数リテラル)
(1, “hoge”) -- タプル
[1, 2, 3] -- リスト
f (a, b) = a+b -- タプルを引数にとる関数
f a b = a+b -- 2引数関数
f n = if n<0 then –n else n -- 条件分岐
f x = let y = x+1 in y*y -- ローカル変数
f x = g x + h x (x+1) -- 関数適用
1ページに収めるのは無理がありましたね…
Haskellのリスト
• リスト例
a = [] -- 空リスト
b = 1 : (2 : (3 : [])))
c = 1 : 2 : 3 : [] --上の略記
d = [1, 2, 3] --上の略記
e = 5 : d -- [5, 1, 2, 3]
f = head d -- 1
g = tail d -- [2, 3]
36.
リストと再帰
• リストの処理が再帰で自然に書ける
doubleList [] = []
doubleList (x:xs) = (x*2) : doubleList xs
incrementList [] = []
incrementList (x:xs) = (x+1) : incrementList xs
sum [] = 0
sum (x:xs) = x + sum xs
似た処理
→抽象化できない?
product [] = 1
product (x:xs) = x * reverse xs
37.
map
• リストの変換を高階関数を用いて抽象化
–関数を引数としてとる関数
map f [] = []
map f (x:xs) = f x : map f xs
doubleList ls = map (¥x -> x * 2) ls
incrementList ls = map (¥x -> x +1) ls
38.
fold
• リストの畳込み
fold f v [] = v
fold f v (x:xs) = f x (fold f v xs)
sum ls = fold (¥x y -> x+y) 0 ls
1 : (2 : (3 : []))) 1 + (2 + (3 + 0)))
product ls = fold (¥x y -> x*y) 1 ls
1 : (2 : (3 : []))) 1 * (2 * (3 * 1)))
39.
filter
• 条件を満たす要素のみ取り出す
filter p [] = []
filter p (x:xs) =
if p x then x : filter p xs
else filter p xs
filter isEven [1, 2, 3, 4, 5]
=> [2, 4]
filter isPrime [1, 2, 3, 4, 5]
=> [2, 3, 5]
遅延評価の利点(1)
• 正格評価ではエラーになるものでも、遅延評
価ではエラーにならないケースがある
– 遅延評価の方が正しく動くプログラムの範囲が
大きい
fst (a, b) = a fst (a, b) =
let c = a/b in
fst (123, 1/0) if b==0
=> 123 then -1
else c
fst (1, 0)
=> -1
例:フィボナッチ数列
• フィボナッチ数列が無限に入ったリスト
fibs=
1 : 1 : zipWith (¥x y -> x+y) fibs (tail fib)
zipWith f (x:xs) (y:ys) = f x y : zipWith f xs ys
fibs: 1 1 2 3 5 8 13 21 …
tail fibs: 1 2 3 5 8 13 21 …
47.
例:ソート、最小要素
• 必要な要素だけソートされる
–最小k要素なども自明な実装で尐ない計算量
sort [] = []
sort (x:xs) =
let a = filter (¥v -> v<x) xs in
let b = filter (¥v -> v>=x) xs in
sort a ++ [x] ++ sort b
let a = [3,1,4,2,5]
sort a => [1,2,3,4,5]
head (sort a) => 1
take 3 (sort a) => [1,2,3]
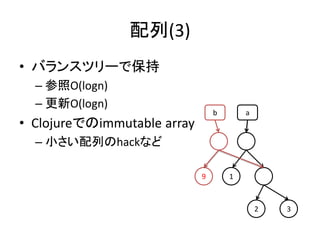
一意型を用いる方法(2)
• 2回参照されてはいけない
–世界は保存されないしロールバックもされない
二回参照
main :: *World -> *World
main w1 =
let (w2, line1) = getLine w1 in
let (w3, line2) = getLine w1 in
let w4 = putStr w3 (line1++line2) in
w4
52.
遅延ストリームを用いた方法
• プログラム=入力例→出力列への関数
• 入力は遅延リスト
– 入力が揃った時点で生成される
• 概念は分かりやすい
– しかしプログラムとしては扱い難い
main :: [Request] -> [Response]
main reqs =
process reqs
process (Input line : rest) =
Output line : process rest
例:銀行アプリ
• 預け入れ・引き出しができる銀行クラス
–これだけだと何の問題もないけど…
class Bank{
int balance;
synchronized public void deposit(int amount){
balance += amount;
}
synchronized public boolean withdraw(int amount){
if (balance >= amount){
balance -= amount;
return true;
}
return false;
}
}
88.
例(2)
• 銀行Aから銀行Bに送金したい
public void send(Bank a, Bank b, int amount){
if (a->withdraw(amount))
b->deposit(amount);
}
• これはダメ
– 送金はアトミックに行われる必要がある
– aから引き出した瞬間の状態が他のスレッドに見
える可能性がある
89.
例(3)
• ロックを取ってみる
public void send(Bank a, Bank b, int amount){
synchronized(a){
synchronized(b){
if (a->withdraw(amount))
b->deposit(amount);
}
}
}
• これでもダメ! Bank a, b;
– デッドロックするかも
send(a, b); // thread-1
– bのロックは要らない場合も send(b, a); // thread-2
90.
例(4)
• 処理が必要とするロックをすべて確認して、
決まった順序でロックをとらなければならない
public void send(Bank a, Bank b, int amount){
Bank la = a<b?a:b;
Bank lb = a<b?b:a;
synchronized(la){
synchronized(lb){
if (a->withdraw(amount))
b->deposit(amount);
}
}
}
STMの組み合わせ
• 自由に組み合わせが可能
–atomicで囲うだけ
– メモリ操作がトランザクションとして実行されるだ
けなので
public void send(Bank a, Bank b, int amount){
atomic{
if (a->withdraw(amount))
b->deposit(amount);
}
}
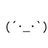




















![Haskell文法紹介
f x = x + 1 -- 関数定義
f = ¥x -> x + 1 -- ラムダ式(関数リテラル)
(1, “hoge”) -- タプル
[1, 2, 3] -- リスト
f (a, b) = a+b -- タプルを引数にとる関数
f a b = a+b -- 2引数関数
f n = if n<0 then –n else n -- 条件分岐
f x = let y = x+1 in y*y -- ローカル変数
f x = g x + h x (x+1) -- 関数適用
1ページに収めるのは無理がありましたね…](https://image.slidesharecdn.com/random-100328154709-phpapp02/85/slide-21-320.jpg)













![Haskellのリスト
• リスト例
a = [] -- 空リスト
b = 1 : (2 : (3 : [])))
c = 1 : 2 : 3 : [] --上の略記
d = [1, 2, 3] --上の略記
e = 5 : d -- [5, 1, 2, 3]
f = head d -- 1
g = tail d -- [2, 3]](https://image.slidesharecdn.com/random-100328154709-phpapp02/85/slide-35-320.jpg)
![リストと再帰
• リストの処理が再帰で自然に書ける
doubleList [] = []
doubleList (x:xs) = (x*2) : doubleList xs
incrementList [] = []
incrementList (x:xs) = (x+1) : incrementList xs
sum [] = 0
sum (x:xs) = x + sum xs
似た処理
→抽象化できない?
product [] = 1
product (x:xs) = x * reverse xs](https://image.slidesharecdn.com/random-100328154709-phpapp02/85/slide-36-320.jpg)
![map
• リストの変換を高階関数を用いて抽象化
– 関数を引数としてとる関数
map f [] = []
map f (x:xs) = f x : map f xs
doubleList ls = map (¥x -> x * 2) ls
incrementList ls = map (¥x -> x +1) ls](https://image.slidesharecdn.com/random-100328154709-phpapp02/85/slide-37-320.jpg)
![fold
• リストの畳込み
fold f v [] = v
fold f v (x:xs) = f x (fold f v xs)
sum ls = fold (¥x y -> x+y) 0 ls
1 : (2 : (3 : []))) 1 + (2 + (3 + 0)))
product ls = fold (¥x y -> x*y) 1 ls
1 : (2 : (3 : []))) 1 * (2 * (3 * 1)))](https://image.slidesharecdn.com/random-100328154709-phpapp02/85/slide-38-320.jpg)
![filter
• 条件を満たす要素のみ取り出す
filter p [] = []
filter p (x:xs) =
if p x then x : filter p xs
else filter p xs
filter isEven [1, 2, 3, 4, 5]
=> [2, 4]
filter isPrime [1, 2, 3, 4, 5]
=> [2, 3, 5]](https://image.slidesharecdn.com/random-100328154709-phpapp02/85/slide-39-320.jpg)
![応用例
• 100以下の素数の二乗の和を求めよ
fold (+) 0 (map (¥x -> x*x) (filter isPrime [1..100]))
• リストに関するかなりの操作を
この三つの関数の組み合わせで行える
– リスト内包表記というのもある
• Haskell, Pythonなど
sum [ i*i | i <- [1..100], isPrime i]
こう書ける](https://image.slidesharecdn.com/random-100328154709-phpapp02/85/slide-40-320.jpg)




![例:無限リスト
• 無限の長さを持つリストを定義できる
ones = 1 : ones
nums = 1 : map (¥x -> x+1) nums
• 必要な部分だけ取り出せる
take 10 ones
=> [1,1,1,1,1,1,1,1,1,1]
take 10 nums
=> [1,2,3,4,5,6,7,8,9,10]](https://image.slidesharecdn.com/random-100328154709-phpapp02/85/slide-45-320.jpg)

![例:ソート、最小要素
• 必要な要素だけソートされる
– 最小k要素なども自明な実装で尐ない計算量
sort [] = []
sort (x:xs) =
let a = filter (¥v -> v<x) xs in
let b = filter (¥v -> v>=x) xs in
sort a ++ [x] ++ sort b
let a = [3,1,4,2,5]
sort a => [1,2,3,4,5]
head (sort a) => 1
take 3 (sort a) => [1,2,3]](https://image.slidesharecdn.com/random-100328154709-phpapp02/85/slide-47-320.jpg)




![遅延ストリームを用いた方法
• プログラム=入力例→出力列への関数
• 入力は遅延リスト
– 入力が揃った時点で生成される
• 概念は分かりやすい
– しかしプログラムとしては扱い難い
main :: [Request] -> [Response]
main reqs =
process reqs
process (Input line : rest) =
Output line : process rest](https://image.slidesharecdn.com/random-100328154709-phpapp02/85/slide-52-320.jpg)





![永続(Persistent)データ構造
• 更新される際に、変更前の値を常に保持する
データ構造
– immutableなデータ構造の構築に利用できる
• 例えば・・・
– 配列を更新しても、前の配列は残しておかなけれ
ばならない
let a = some array …
let b = a[0] <- 1
print b[0] ; => 1
print a[0] ; => 前の値](https://image.slidesharecdn.com/random-100328154709-phpapp02/85/slide-58-320.jpg)
![リスト
• 最も単純な永続データ構造
• スタックとしても使える
b a
let a = [1, 2]
let b = 9 : a
9 1 2](https://image.slidesharecdn.com/random-100328154709-phpapp02/85/slide-59-320.jpg)























































































![[Basic 12] 関数型言語 / 型理論](https://cdn.slidesharecdn.com/ss_thumbnails/basic-12-180306134428-thumbnail.jpg?width=640&height=640&fit=bounds)







