Download as PDF, PPTX














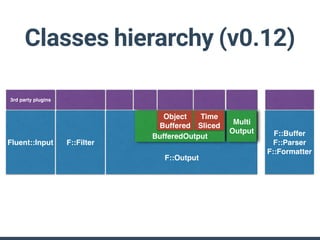



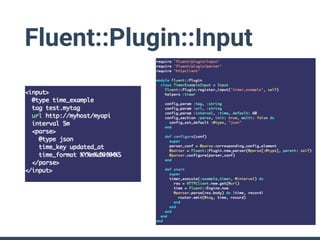






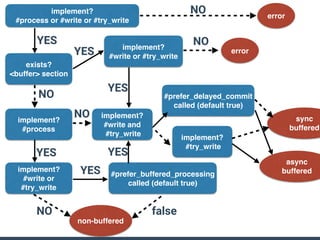

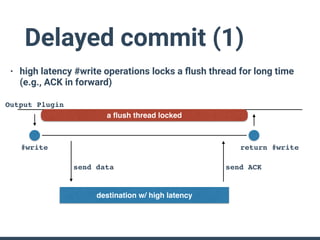
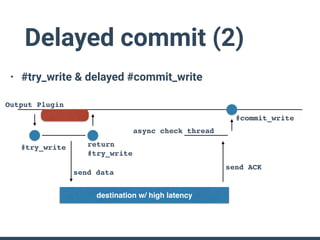










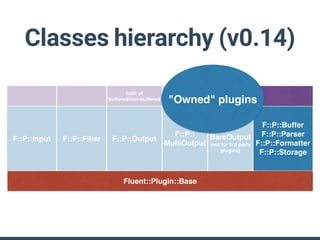

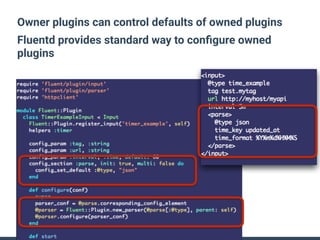





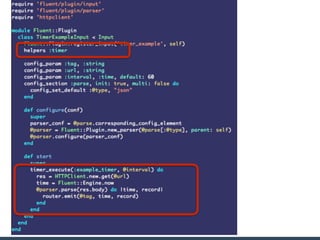










The document summarizes the new plugin API in Fluentd v0.14. Key points include: - The v0.12 plugin API was fragmented and difficult to write tests for. The v0.14 API provides a unified architecture. - The main plugin classes are Input, Filter, Output, Buffer, and plugins must subclass Fluent::Plugin::Base. - The Output plugin supports both buffered and non-buffered processing. Buffering can be configured by tags, time, or custom fields. - "Owned" plugins like Buffer are instantiated by primary plugins and can access owner resources. Storage is a new owned plugin for persistent storage. - New test drivers emulate plugin


































































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)






