Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Yahoo!デベロッパーネットワーク
1,823 views
「ヤフー音声検索アプリにおけるキーワードスポッティングの実装」#yjdsw4
http://yahoo-ds-event.connpass.com/event/24511/
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 15 times
1
/ 13
2
/ 13
3
/ 13
4
/ 13
5
/ 13
6
/ 13
7
/ 13
8
/ 13
9
/ 13
10
/ 13
11
/ 13
12
/ 13
13
/ 13
More Related Content
PDF
いろんなバンディットアルゴリズムを理解しよう
by
Tomoki Yoshida
PDF
Deep Counterfactual Regret Minimization
by
Kenshi Abe
PDF
Overview of tree algorithms from decision tree to xgboost
by
Takami Sato
PDF
全力解説!Transformer
by
Arithmer Inc.
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PPTX
backbone としての timm 入門
by
Takuji Tahara
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Optunaを使ったHuman-in-the-loop最適化の紹介 - 2023/04/27 W&B 東京ミートアップ #3
by
Preferred Networks
いろんなバンディットアルゴリズムを理解しよう
by
Tomoki Yoshida
Deep Counterfactual Regret Minimization
by
Kenshi Abe
Overview of tree algorithms from decision tree to xgboost
by
Takami Sato
全力解説!Transformer
by
Arithmer Inc.
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
backbone としての timm 入門
by
Takuji Tahara
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
Optunaを使ったHuman-in-the-loop最適化の紹介 - 2023/04/27 W&B 東京ミートアップ #3
by
Preferred Networks
What's hot
PDF
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
PPTX
エンジニアのための機械学習の基礎
by
Daiyu Hatakeyama
PDF
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
PDF
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PDF
はじめてのKrylov部分空間法
by
tmaehara
PDF
Deeplearning輪読会
by
正志 坪坂
PDF
線形識別モデル
by
貴之 八木
PDF
BERT+XLNet+RoBERTa
by
禎晃 山崎
PDF
HiPPO/S4解説
by
Morpho, Inc.
PPTX
劣モジュラ最適化と機械学習 3章
by
Hakky St
PDF
技術者が知るべき Gröbner 基底
by
Hiromi Ishii
PPTX
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
by
Yusuke Iwasawa
PDF
ディープラーニングを用いた物体認識とその周辺 ~現状と課題~ (Revised on 18 July, 2018)
by
Masakazu Iwamura
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PDF
Devsumi 2018summer
by
Harada Kei
PDF
AbemaTVにおける推薦システム
by
cyberagent
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
PDF
多人数不完全情報ゲームにおけるAI ~ポーカーと麻雀を例として~
by
Kenshi Abe
PDF
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
エンジニアのための機械学習の基礎
by
Daiyu Hatakeyama
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
はじめてのKrylov部分空間法
by
tmaehara
Deeplearning輪読会
by
正志 坪坂
線形識別モデル
by
貴之 八木
BERT+XLNet+RoBERTa
by
禎晃 山崎
HiPPO/S4解説
by
Morpho, Inc.
劣モジュラ最適化と機械学習 3章
by
Hakky St
技術者が知るべき Gröbner 基底
by
Hiromi Ishii
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
by
Yusuke Iwasawa
ディープラーニングを用いた物体認識とその周辺 ~現状と課題~ (Revised on 18 July, 2018)
by
Masakazu Iwamura
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
Devsumi 2018summer
by
Harada Kei
AbemaTVにおける推薦システム
by
cyberagent
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
多人数不完全情報ゲームにおけるAI ~ポーカーと麻雀を例として~
by
Kenshi Abe
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
Viewers also liked
PDF
「Abuse対策を10年続けた結果」#yjdsw4
by
Yahoo!デベロッパーネットワーク
PDF
「変化と戦うロガー開発(iOS_App_Extensions編)」#yjdsw4
by
Yahoo!デベロッパーネットワーク
PDF
「Data Infrastructure at Scale 」#yjdsw4
by
Yahoo!デベロッパーネットワーク
PDF
「これはヤフオク!に機械学習を導入する男たちの戦いの物語である」#yjdsw4
by
Yahoo!デベロッパーネットワーク
PDF
ヤフー音声認識のご紹介#yjdsw1
by
Yahoo!デベロッパーネットワーク
PDF
「なぜビッグデータが選挙の予測を可能にするのか」#yjdsw4
by
Yahoo!デベロッパーネットワーク
PDF
「YDNの広告のCTRをオンライン学習で予測してみた」#yjdsw4
by
Yahoo!デベロッパーネットワーク
PDF
大規模HDFS & ErasureCoding#yjdsw3
by
Yahoo!デベロッパーネットワーク
PDF
ヤフーの次世代パイプラインについて#yjdsw3
by
Yahoo!デベロッパーネットワーク
PDF
ヤフーのRDBと最新のMySQLの検証結果#yjdsw3
by
Yahoo!デベロッパーネットワーク
PDF
Yahoo! JAPAN IDの裏側#yjdsw3
by
Yahoo!デベロッパーネットワーク
PDF
分散システム処理モデルの課題および展望#yjdsw3
by
Yahoo!デベロッパーネットワーク
PDF
Hadoop Summit 2016 San Jose ストリーム処理関連の報告 #streamctjp
by
Yahoo!デベロッパーネットワーク
PDF
Influxdb ver0.9.5#yjdsw3
by
Yahoo!デベロッパーネットワーク
PDF
Ambari運用ツラたん #ambarimeetup
by
Yahoo!デベロッパーネットワーク
PDF
Yahoo! JAPAN の Ambari 活用事例 #ambarimeetup
by
Yahoo!デベロッパーネットワーク
PDF
Yahoo! JAPAN の Ambari 活用事例 #yjdsnight
by
Yahoo!デベロッパーネットワーク
PDF
セキュアにユーザ行動情報を取得するための取り組み #yjdsnight
by
Yahoo!デベロッパーネットワーク
PDF
可視化までのとある方法 #yjdsnight
by
Yahoo!デベロッパーネットワーク
PDF
Kafka 0.10.0 アップデート、プロダクション100ノードでやってみた #yjdsnight
by
Yahoo!デベロッパーネットワーク
「Abuse対策を10年続けた結果」#yjdsw4
by
Yahoo!デベロッパーネットワーク
「変化と戦うロガー開発(iOS_App_Extensions編)」#yjdsw4
by
Yahoo!デベロッパーネットワーク
「Data Infrastructure at Scale 」#yjdsw4
by
Yahoo!デベロッパーネットワーク
「これはヤフオク!に機械学習を導入する男たちの戦いの物語である」#yjdsw4
by
Yahoo!デベロッパーネットワーク
ヤフー音声認識のご紹介#yjdsw1
by
Yahoo!デベロッパーネットワーク
「なぜビッグデータが選挙の予測を可能にするのか」#yjdsw4
by
Yahoo!デベロッパーネットワーク
「YDNの広告のCTRをオンライン学習で予測してみた」#yjdsw4
by
Yahoo!デベロッパーネットワーク
大規模HDFS & ErasureCoding#yjdsw3
by
Yahoo!デベロッパーネットワーク
ヤフーの次世代パイプラインについて#yjdsw3
by
Yahoo!デベロッパーネットワーク
ヤフーのRDBと最新のMySQLの検証結果#yjdsw3
by
Yahoo!デベロッパーネットワーク
Yahoo! JAPAN IDの裏側#yjdsw3
by
Yahoo!デベロッパーネットワーク
分散システム処理モデルの課題および展望#yjdsw3
by
Yahoo!デベロッパーネットワーク
Hadoop Summit 2016 San Jose ストリーム処理関連の報告 #streamctjp
by
Yahoo!デベロッパーネットワーク
Influxdb ver0.9.5#yjdsw3
by
Yahoo!デベロッパーネットワーク
Ambari運用ツラたん #ambarimeetup
by
Yahoo!デベロッパーネットワーク
Yahoo! JAPAN の Ambari 活用事例 #ambarimeetup
by
Yahoo!デベロッパーネットワーク
Yahoo! JAPAN の Ambari 活用事例 #yjdsnight
by
Yahoo!デベロッパーネットワーク
セキュアにユーザ行動情報を取得するための取り組み #yjdsnight
by
Yahoo!デベロッパーネットワーク
可視化までのとある方法 #yjdsnight
by
Yahoo!デベロッパーネットワーク
Kafka 0.10.0 アップデート、プロダクション100ノードでやってみた #yjdsnight
by
Yahoo!デベロッパーネットワーク
More from Yahoo!デベロッパーネットワーク
PDF
ゼロから始める転移学習
by
Yahoo!デベロッパーネットワーク
PDF
継続的なモデルモニタリングを実現するKubernetes Operator
by
Yahoo!デベロッパーネットワーク
PDF
ヤフーでは開発迅速性と品質のバランスをどう取ってるか
by
Yahoo!デベロッパーネットワーク
PDF
オンプレML基盤on Kubernetes パネルディスカッション
by
Yahoo!デベロッパーネットワーク
PDF
LakeTahoe
by
Yahoo!デベロッパーネットワーク
PDF
オンプレML基盤on Kubernetes 〜Yahoo! JAPAN AIPF〜
by
Yahoo!デベロッパーネットワーク
PDF
Persistent-memory-native Database High-availability Feature
by
Yahoo!デベロッパーネットワーク
PDF
データの価値を最大化させるためのデザイン~データビジュアライゼーションの方法~ #devsumi 17-E-2
by
Yahoo!デベロッパーネットワーク
PDF
eコマースと実店舗の相互利益を目指したデザイン #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
ヤフーを支えるセキュリティ ~サイバー攻撃を防ぐエンジニアの仕事とは~ #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
Yahoo! JAPANのIaaSを支えるKubernetesクラスタ、アップデート自動化への挑戦 #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
ビッグデータから人々のムードを捉える #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
サイエンス領域におけるMLOpsの取り組み #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
ヤフーのAIプラットフォーム紹介 ~AIテックカンパニーを支えるデータ基盤~ #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
Yahoo! JAPAN Tech Conference 2022 Day2 Keynote #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
新技術を使った次世代の商品の見せ方 ~ヤフオク!のマルチビュー機能~ #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
PC版Yahoo!メールリニューアル ~サービスのUI/UX統合と改善プロセス~ #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
モブデザインによる多職種チームのコミュニケーション改善 #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
「新しいおうち探し」のためのAIアシスト検索 #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
ユーザーの地域を考慮した検索入力補助機能の改善の試み #yjtc
by
Yahoo!デベロッパーネットワーク
ゼロから始める転移学習
by
Yahoo!デベロッパーネットワーク
継続的なモデルモニタリングを実現するKubernetes Operator
by
Yahoo!デベロッパーネットワーク
ヤフーでは開発迅速性と品質のバランスをどう取ってるか
by
Yahoo!デベロッパーネットワーク
オンプレML基盤on Kubernetes パネルディスカッション
by
Yahoo!デベロッパーネットワーク
LakeTahoe
by
Yahoo!デベロッパーネットワーク
オンプレML基盤on Kubernetes 〜Yahoo! JAPAN AIPF〜
by
Yahoo!デベロッパーネットワーク
Persistent-memory-native Database High-availability Feature
by
Yahoo!デベロッパーネットワーク
データの価値を最大化させるためのデザイン~データビジュアライゼーションの方法~ #devsumi 17-E-2
by
Yahoo!デベロッパーネットワーク
eコマースと実店舗の相互利益を目指したデザイン #yjtc
by
Yahoo!デベロッパーネットワーク
ヤフーを支えるセキュリティ ~サイバー攻撃を防ぐエンジニアの仕事とは~ #yjtc
by
Yahoo!デベロッパーネットワーク
Yahoo! JAPANのIaaSを支えるKubernetesクラスタ、アップデート自動化への挑戦 #yjtc
by
Yahoo!デベロッパーネットワーク
ビッグデータから人々のムードを捉える #yjtc
by
Yahoo!デベロッパーネットワーク
サイエンス領域におけるMLOpsの取り組み #yjtc
by
Yahoo!デベロッパーネットワーク
ヤフーのAIプラットフォーム紹介 ~AIテックカンパニーを支えるデータ基盤~ #yjtc
by
Yahoo!デベロッパーネットワーク
Yahoo! JAPAN Tech Conference 2022 Day2 Keynote #yjtc
by
Yahoo!デベロッパーネットワーク
新技術を使った次世代の商品の見せ方 ~ヤフオク!のマルチビュー機能~ #yjtc
by
Yahoo!デベロッパーネットワーク
PC版Yahoo!メールリニューアル ~サービスのUI/UX統合と改善プロセス~ #yjtc
by
Yahoo!デベロッパーネットワーク
モブデザインによる多職種チームのコミュニケーション改善 #yjtc
by
Yahoo!デベロッパーネットワーク
「新しいおうち探し」のためのAIアシスト検索 #yjtc
by
Yahoo!デベロッパーネットワーク
ユーザーの地域を考慮した検索入力補助機能の改善の試み #yjtc
by
Yahoo!デベロッパーネットワーク
「ヤフー音声検索アプリにおけるキーワードスポッティングの実装」#yjdsw4
1.
ヤフー音声検索アプリにおける Keyword Spottingの実装 2016.01.30 ヤフー株式会社 データ&サイエンスソリューション統括本部 サイエンス本部 三宅 純平 1 【大阪】Yahoo!
JAPAN データ&サイエンスワークショップ
2.
自己紹介 • 三宅 純平 –
奈良県出身 – C/C++, Python, Perl, (hadoop使う時だけJava) – 音声認識アルゴリズム、言語モデル、単語分割、機械学習、サーバ開発 – フットサル、マラソン • 経歴 2 2009年4月 ヤフー新卒入社。自然言語処理技術の開発。 (読み獲得、レコメンド、クエリセグメンテーション、Hadoop) 2011年1月~現在 ・音声認識PJの正式発足と共にチーム異動し、音声認識開発に従事 ・Yahoo! JAPAN研究所とサイエンス本部の共同開発PJ
3.
2013.08より自社開発の音声認識エンジン。 「Yahoo! JAPAN」「音声アシスト」アプリなど19のアプリ・ウィジェットに導入(2016/1/24現在) YJVOICE ヤフー日本語音声認識 Andorid iOS
4.
• DNNベースの音声認識に切り替え(2015.05.19) 音声区間検出と音響モデルの2カ所にDNNを実装 雑音環境下において大幅精度改善 大規模な音声データで大規模なNNを学習 • 音声検索アプリにKeyword
Spotting機能の追加(2015.09.25) 所謂「OK,Google」「Hey,Siri」の機能 カーナビ、IoT、ディスプレイがない端末のハンズフリー操作に有効 クライアント側で常時、音声認識が起動 • ソフトバンクさんよりリリースの「こえ文字トーク」アプリに YJVOICEが採用(2015.12.18) ヤフー日本語音声認識 YJVOICEについて 最近のヤフー音声認識のリリース 出典:GTC Japan 2015 ヤフー研究員 磯氏の講演より おんせー けんさく
5.
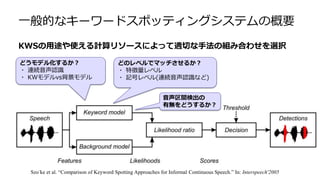
一般的なキーワードスポッティングシステムの概要 Szo ̈ke et
al. “Comparison of Keyword Spotting Approaches for Informal Continuous Speech.” In: Interspeech'2005 どのレベルでマッチさせるか? ・ 特徴量レベル ・ 記号レベル(連続音声認識など) 音声区間検出の 有無をどうするか? どうモデル化するか? ・ 連続音声認識 ・ KWモデルvs背景モデル KWSの用途や使える計算リソースによって適切な手法の組み合わせを選択
6.
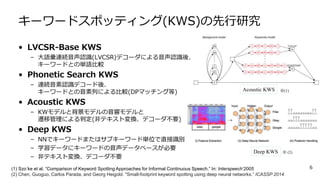
キーワードスポッティング(KWS)の先行研究 • LVCSR-Base KWS –
大語彙連続音声認識(LVCSR)デコーダによる音声認識後、 キーワードとの単語比較 • Phonetic Search KWS – 連続音素認識デコード後、 キーワードとの音素列による比較(DPマッチング等) • Acoustic KWS – KWモデルと背景モデルの音響モデルと 遷移管理による判定(非テキスト変換、デコーダ不要) • Deep KWS – NNでキーワードまたはサブキーワード単位で直接識別 – 学習データにキーワードの音声データベースが必要 – 非テキスト変換、デコーダ不要 6(1) Szo ̈ke et al. “Comparison of Keyword Spotting Approaches for Informal Continuous Speech.” In: Interspeech‘2005 (2) Chen, Guoguo, Carlos Parada, and Georg Heigold. "Small-footprint keyword spotting using deep neural networks.” ICASSP 2014 Acoustic KWS Deep KWS ※(1) ※ (2)
7.
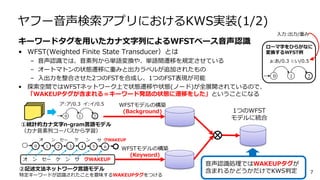
ヤフー音声検索アプリにおけるKWS実装(1/2) キーワードタグを用いたカナ文字列によるWFSTベース音声認識 • WFST(Weighted Finite
State Transducer)とは – 音声認識では、音素列から単語変換や、単語間遷移を規定させている – オートマトンの状態遷移に重みと出力ラベルが追加されたもの – 入出力を整合させた2つのFSTを合成し、1つのFST表現が可能 • 探索空間ではWFSTネットワーク上で状態遷移や状態(ノード)が全展開されているので、 「WAKEUPタグが含まれる=キーワード発話の状態に遷移をした」ということになる 7 WFSTモデルの構築 (Background) オ ン セー ケ ン サ クWAKEUP ②記述文法ネットワーク言語モデル 特定キーワードが認識されたことを意味するWAKEUPタグをつける ①統計的カナ文字n-gram言語モデル (カナ音素列コーパスから学習) WFSTモデルの構築 (Keyword) 1つのWFST モデルに統合 音声認識処理ではWAKEUPタグが 含まれるかどうかだけでKWS判定 a:あ/0.3 i:い/0.5 ローマ字をひらがなに 変換するWFST例 0 1 2 入力:出力/重み オ ン ンセー ケ クWAKEUP ア:ア/0.3 イ:イ/0.5 0 1 2 サ 0 1 2 3 4 5 6
8.
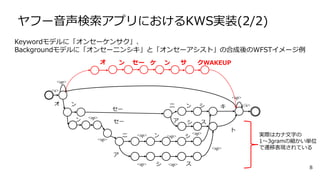
8 <s> オ ン セー ン <sp> セー <sp> <sp>
<sp> <sp> <sp> <sp><sp> ニ ン シ ア シ ス ニ ン シ ア シ ス キ ト <sp> </s> <sp> オ セー ンン ケ サ クWAKEUP ヤフー音声検索アプリにおけるKWS実装(2/2) Keywordモデルに「オンセーケンサク」、 Backgroundモデルに「オンセーニンシキ」と「オンセーアシスト」の合成後のWFSTイメージ例 実際はカナ文字の 1〜3gramの細かい単位 で遷移表現されている
9.
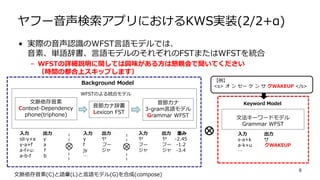
ヤフー音声検索アプリにおけるKWS実装(2/2+α) • 実際の音声認識のWFST言語モデルでは、 音素、単語辞書、言語モデルのそれぞれのFSTまたはWFSTを統合 – WFSTの詳細説明に関しては興味がある方は懇親会で聞いてください (時間の都合上スキップします) 9 文脈依存音素(C)と語彙(L)と言語モデル(G)を合成(compose) 文脈依存音素 Context-Dependency phone(triphone) 音節カナ辞書 Lexicon
FST 音節カナ 3-gram言語モデル Grammar WFST 入力 出力 sil-y+a y y-a+f a a-f+u: f a-b-f b 入力 出力 y ヤ f フー jy ジャ … 入力 出力 重み ヤ ヤ -2.45 フー フー -1.2 ジャ ジャ -3.4 Background Model WFSTのよる統合モデル 入力 出力 s-a+k サ a-k+u クWAKEUP … 文法キーワードモデル Grammar WFST Keyword Model 【例】 <s> オ ン セー ケ ン サ クWAKEUP </s>
10.
スマホアプリ搭載への実用化にむけて(1/2) 10 • メモリ使用量・速度(計算量)・SDKファイルサイズ・認識性能など、 各々トレードオフ関係を考慮しつつ、実用レベルに落とし込みが必要 • 参考情報 メモリ使用量
• AndroidのJava Heap Size制限が256MB • 某アプリでは既に170MB使用 (音声認識部はC/C++のライブラリなのでJavaメモリ領域は未使用) 配布SDKの ファイルサイズ • 音声認識ライブラリ • 辞書・言語モデル・音響モデル • アプリによっては音声合成も搭載 ※アプリストアで特にファイルサイズ上限はない 速度・精度 • モデルサイズと認識精度のトレードオフ • 音声認識の探索幅(ビーム幅)の調整 • 現状は、音声区間検出(VAD)と音響モデル(AM)にDNNではなく パワーベースVADとGMM+HMM AMを採用
11.
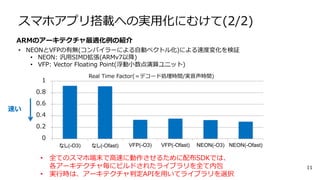
スマホアプリ搭載への実用化にむけて(2/2) 11 ARMのアーキテクチャ最適化例の紹介 • NEONとVFPの有無(コンパイラーによる自動ベクトル化)による速度変化を検証 • NEON:
汎用SIMD拡張(ARMv7以降) • VFP: Vector Floating Point(浮動小数点演算ユニット) 0 0.2 0.4 0.6 0.8 1 なし(-O3) なし(-Ofast) VFP(-O3) VFP(-Ofast) NEON(-O3) NEON(-Ofast) 速い Real Time Factor(=デコード処理時間/実音声時間) • 全てのスマホ端末で高速に動作させるために配布SDKでは、 各アーキテクチャ毎にビルドされたライブラリを全て内包 • 実行時は、アーキテクチャ判定APIを用いてライブラリを選択
12.
まとめ • ヤフー音声検索アプリのKWS実装の紹介 • 応答高速化/精度改善へ向けて -
逐次的認識とWAKEUPタグの前方移動による早期確定 - DNNやLSTMを利用したデコード処理が不要な方法の検証 • 演算量が課題 - 高速なBLASライブラリ導入 - 固定小数点化 - 行列圧縮 12
13.
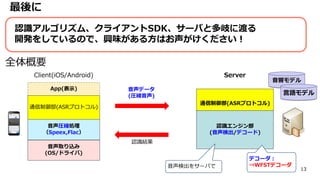
13 最後に 全体概要 通信制御部(ASRプロトコル) 認識エンジン部 (音声検出/デコード) App(表示) クライアント 通信制御部(ASRプロトコル) 音声圧縮処理 (Speex,Flac) 音声取り込み (OS/ドライバ) 音声データ (圧縮音声) 音声検出をサーバで デコーダ: ⇒WFSTデコーダ 認識結果 認識アルゴリズム、クライアントSDK、サーバと多岐に渡る 開発をしているので、興味がある方はお声がけください! Client(iOS/Android) Server 音響モデル 言語モデル
Download


























![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)









































