Download to read offline




















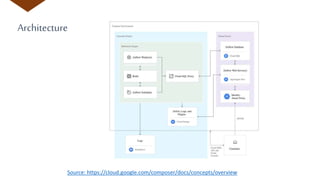










The document discusses the machine learning workflow and modern tools for building, deploying, and monitoring ML models, particularly using Google Cloud services. It emphasizes the importance of defining problems, identifying data sources, and evaluating model fairness throughout the ML process. Additionally, it highlights services like AutoML, AI Platform, and Cloud Composer that facilitate various stages of ML development while maintaining an emphasis on data quality and monitoring practices.




![[AI] ML Operationalization with Microsoft Azure](https://cdn.slidesharecdn.com/ss_thumbnails/wds-mlops-trainer-kyle-akepanidtaworn-v03-190924094657-thumbnail.jpg?width=640&height=640&fit=bounds)

































![[Giovanni Galloro] How to use machine learning on Google Cloud Platform](https://cdn.slidesharecdn.com/ss_thumbnails/mlcapabilitiesongcp-190115085455-thumbnail.jpg?width=640&height=640&fit=bounds)


























![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)














