Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
DaeMyung Kang
36,838 views
Webservice cache strategy
Technology
◦
Read more
172
Save
Share
Embed
Embed presentation
Download
Downloaded 213 times
1
/ 125
2
/ 125
3
/ 125
4
/ 125
5
/ 125
6
/ 125
7
/ 125
8
/ 125
9
/ 125
10
/ 125
11
/ 125
12
/ 125
13
/ 125
14
/ 125
15
/ 125
16
/ 125
17
/ 125
18
/ 125
19
/ 125
20
/ 125
21
/ 125
22
/ 125
23
/ 125
24
/ 125
25
/ 125
26
/ 125
27
/ 125
28
/ 125
29
/ 125
30
/ 125
31
/ 125
32
/ 125
33
/ 125
34
/ 125
35
/ 125
36
/ 125
37
/ 125
38
/ 125
39
/ 125
40
/ 125
41
/ 125
42
/ 125
43
/ 125
44
/ 125
45
/ 125
46
/ 125
47
/ 125
48
/ 125
49
/ 125
50
/ 125
51
/ 125
52
/ 125
53
/ 125
54
/ 125
55
/ 125
56
/ 125
57
/ 125
58
/ 125
59
/ 125
60
/ 125
61
/ 125
62
/ 125
63
/ 125
64
/ 125
65
/ 125
66
/ 125
67
/ 125
68
/ 125
69
/ 125
70
/ 125
71
/ 125
72
/ 125
73
/ 125
74
/ 125
75
/ 125
76
/ 125
77
/ 125
78
/ 125
79
/ 125
80
/ 125
81
/ 125
82
/ 125
83
/ 125
84
/ 125
85
/ 125
86
/ 125
87
/ 125
88
/ 125
89
/ 125
90
/ 125
91
/ 125
92
/ 125
93
/ 125
94
/ 125
95
/ 125
96
/ 125
97
/ 125
98
/ 125
99
/ 125
100
/ 125
101
/ 125
102
/ 125
103
/ 125
104
/ 125
105
/ 125
106
/ 125
107
/ 125
108
/ 125
109
/ 125
110
/ 125
111
/ 125
112
/ 125
113
/ 125
114
/ 125
115
/ 125
116
/ 125
117
/ 125
118
/ 125
119
/ 125
120
/ 125
121
/ 125
122
/ 125
123
/ 125
124
/ 125
125
/ 125
More Related Content
PDF
Elastic webservice
by
DaeMyung Kang
PDF
Internet Scale Service Arichitecture
by
DaeMyung Kang
PDF
Data Engineering 101
by
DaeMyung Kang
PDF
Scalable webservice
by
DaeMyung Kang
PDF
안정적인 서비스 운영 2014.03
by
Changyol BAEK
PDF
Massive service basic
by
DaeMyung Kang
PDF
Optane DC Persistent Memory(DCPMM) 성능 테스트
by
SANG WON PARK
PDF
AWS CLOUD 2018- Amazon Aurora 신규 서비스 알아보기 (최유정 솔루션즈 아키텍트)
by
Amazon Web Services Korea
Elastic webservice
by
DaeMyung Kang
Internet Scale Service Arichitecture
by
DaeMyung Kang
Data Engineering 101
by
DaeMyung Kang
Scalable webservice
by
DaeMyung Kang
안정적인 서비스 운영 2014.03
by
Changyol BAEK
Massive service basic
by
DaeMyung Kang
Optane DC Persistent Memory(DCPMM) 성능 테스트
by
SANG WON PARK
AWS CLOUD 2018- Amazon Aurora 신규 서비스 알아보기 (최유정 솔루션즈 아키텍트)
by
Amazon Web Services Korea
What's hot
PDF
webservice scaling for newbie
by
DaeMyung Kang
PDF
Apache kafka 모니터링을 위한 Metrics 이해 및 최적화 방안
by
SANG WON PARK
PDF
Understanding of Apache kafka metrics for monitoring
by
SANG WON PARK
PDF
Apache kafka performance(throughput) - without data loss and guaranteeing dat...
by
SANG WON PARK
PDF
파이어베이스 네이버 밋업발표
by
NAVER D2
PDF
Redis edu 5
by
DaeMyung Kang
PDF
게임 서비스를 위한 AWS상의 고성능 SQL 데이터베이스 구성 (이정훈 솔루션즈 아키텍트, AWS) :: Gaming on AWS 2018
by
Amazon Web Services Korea
PPTX
Hanghae99 FinalProject Moyeora!
by
Young Woo Lee
PDF
Cloud dw benchmark using tpd-ds( Snowflake vs Redshift vs EMR Hive )
by
SANG WON PARK
PDF
20140806 AWS Meister BlackBelt - Amazon Redshift (Korean)
by
Amazon Web Services Korea
PDF
Amazon Aurora Deep Dive (김기완) - AWS DB Day
by
Amazon Web Services Korea
PDF
카프카(kafka) 성능 테스트 환경 구축 (JMeter, ELK)
by
Hyunmin Lee
PDF
[124]네이버에서 사용되는 여러가지 Data Platform, 그리고 MongoDB
by
NAVER D2
PDF
비디가 제시하는 AWS Migration 주요 factor - BD 홍성준 이사:: AWS Cloud Track 1 Intro
by
Amazon Web Services Korea
PDF
How to build massive service for advance
by
DaeMyung Kang
PDF
[Gaming on AWS] AWS와 함께 한 쿠키런 서버 Re-architecting 사례 - 데브시스터즈
by
Amazon Web Services Korea
PDF
Apache kafka performance(latency)_benchmark_v0.3
by
SANG WON PARK
PDF
아마존 클라우드와 함께한 1개월, 쿠키런 사례중심 (KGC 2013)
by
Brian Hong
PDF
Cloudera Impala 1.0
by
Minwoo Kim
PPTX
0222 사내세미나_오정민 스프링인액션
by
DataUs
webservice scaling for newbie
by
DaeMyung Kang
Apache kafka 모니터링을 위한 Metrics 이해 및 최적화 방안
by
SANG WON PARK
Understanding of Apache kafka metrics for monitoring
by
SANG WON PARK
Apache kafka performance(throughput) - without data loss and guaranteeing dat...
by
SANG WON PARK
파이어베이스 네이버 밋업발표
by
NAVER D2
Redis edu 5
by
DaeMyung Kang
게임 서비스를 위한 AWS상의 고성능 SQL 데이터베이스 구성 (이정훈 솔루션즈 아키텍트, AWS) :: Gaming on AWS 2018
by
Amazon Web Services Korea
Hanghae99 FinalProject Moyeora!
by
Young Woo Lee
Cloud dw benchmark using tpd-ds( Snowflake vs Redshift vs EMR Hive )
by
SANG WON PARK
20140806 AWS Meister BlackBelt - Amazon Redshift (Korean)
by
Amazon Web Services Korea
Amazon Aurora Deep Dive (김기완) - AWS DB Day
by
Amazon Web Services Korea
카프카(kafka) 성능 테스트 환경 구축 (JMeter, ELK)
by
Hyunmin Lee
[124]네이버에서 사용되는 여러가지 Data Platform, 그리고 MongoDB
by
NAVER D2
비디가 제시하는 AWS Migration 주요 factor - BD 홍성준 이사:: AWS Cloud Track 1 Intro
by
Amazon Web Services Korea
How to build massive service for advance
by
DaeMyung Kang
[Gaming on AWS] AWS와 함께 한 쿠키런 서버 Re-architecting 사례 - 데브시스터즈
by
Amazon Web Services Korea
Apache kafka performance(latency)_benchmark_v0.3
by
SANG WON PARK
아마존 클라우드와 함께한 1개월, 쿠키런 사례중심 (KGC 2013)
by
Brian Hong
Cloudera Impala 1.0
by
Minwoo Kim
0222 사내세미나_오정민 스프링인액션
by
DataUs
Viewers also liked
PDF
Redis begins
by
DaeMyung Kang
PDF
Redis edu 4
by
DaeMyung Kang
PDF
Redis edu 2
by
DaeMyung Kang
PDF
Redis edu 1
by
DaeMyung Kang
PDF
Redis edu 3
by
DaeMyung Kang
PDF
카카오스토리 웹팀의 코드리뷰 경험
by
Ohgyun Ahn
PDF
Scala dreaded underscore
by
RUDDER
PPTX
알고리즘2
by
Byeongsu Kang
PPTX
Aws summit 2017 사내전파교육
by
Byeongsu Kang
PPTX
알고리즘 문제해결전략 #1
by
Byeongsu Kang
PPTX
코딩소림사 Rx java
by
Byeongsu Kang
PPTX
Exception log practical_coding_guide, 예외와 로그 코딩 실용 가이드
by
도형 임
PPTX
멸종하는 공룡이 되지 않으려면
by
Byeongsu Kang
PPTX
예외처리가이드
by
도형 임
PDF
텐서플로우 설치도 했고 튜토리얼도 봤고 기초 예제도 짜봤다면 TensorFlow KR Meetup 2016
by
Taehoon Kim
PDF
지적 대화를 위한 깊고 넓은 딥러닝 PyCon APAC 2016
by
Taehoon Kim
PDF
딥러닝과 강화 학습으로 나보다 잘하는 쿠키런 AI 구현하기 DEVIEW 2016
by
Taehoon Kim
PDF
알아두면 쓸데있는 신기한 강화학습 NAVER 2017
by
Taehoon Kim
PDF
책 읽어주는 딥러닝: 배우 유인나가 해리포터를 읽어준다면 DEVIEW 2017
by
Taehoon Kim
Redis begins
by
DaeMyung Kang
Redis edu 4
by
DaeMyung Kang
Redis edu 2
by
DaeMyung Kang
Redis edu 1
by
DaeMyung Kang
Redis edu 3
by
DaeMyung Kang
카카오스토리 웹팀의 코드리뷰 경험
by
Ohgyun Ahn
Scala dreaded underscore
by
RUDDER
알고리즘2
by
Byeongsu Kang
Aws summit 2017 사내전파교육
by
Byeongsu Kang
알고리즘 문제해결전략 #1
by
Byeongsu Kang
코딩소림사 Rx java
by
Byeongsu Kang
Exception log practical_coding_guide, 예외와 로그 코딩 실용 가이드
by
도형 임
멸종하는 공룡이 되지 않으려면
by
Byeongsu Kang
예외처리가이드
by
도형 임
텐서플로우 설치도 했고 튜토리얼도 봤고 기초 예제도 짜봤다면 TensorFlow KR Meetup 2016
by
Taehoon Kim
지적 대화를 위한 깊고 넓은 딥러닝 PyCon APAC 2016
by
Taehoon Kim
딥러닝과 강화 학습으로 나보다 잘하는 쿠키런 AI 구현하기 DEVIEW 2016
by
Taehoon Kim
알아두면 쓸데있는 신기한 강화학습 NAVER 2017
by
Taehoon Kim
책 읽어주는 딥러닝: 배우 유인나가 해리포터를 읽어준다면 DEVIEW 2017
by
Taehoon Kim
Similar to Webservice cache strategy
PDF
확장가능한 웹 아키텍쳐 구축 방안
by
IMQA
PPTX
Scalable web architecture and distributed systems
by
eva
PPTX
Scalable web architecture and distributed systems
by
현종 김
PDF
효과적인 NoSQL (Elasticahe / DynamoDB) 디자인 및 활용 방안 (최유정 & 최홍식, AWS 솔루션즈 아키텍트) :: ...
by
Amazon Web Services Korea
PPTX
분산저장시스템 개발에 대한 12가지 이야기
by
NAVER D2
PPTX
Soscon2017 오픈소스를 활용한 마이크로 서비스의 캐시 전략
by
Kris Jeong
PPT
091106kofpublic 091108170852-phpapp02 (번역본)
by
Taegil Heo
PDF
Tdc2013 선배들에게 배우는 server scalability
by
흥배 최
PPTX
Introduction to scalability
by
polabear
PDF
대규모 서비스를 가능하게 하는 기술
by
Hyungseok Shim
PPT
Mem cached
by
ghkangduria
PDF
Memcached의 확장성 개선
by
NAVER D2
PDF
안정적인 서비스 운영 2013.08
by
Changyol BAEK
PDF
AWS Innovate: Best Practices for Migrating to Amazon DynamoDB - Sangpil Kim
by
Amazon Web Services Korea
PDF
대규모 데이터 처리 입문
by
Choonghyun Yang
PPTX
No sql 이해 및 활용 공개용
by
YOUNGGYU CHUN
PPTX
[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.
by
NAVER D2
PDF
Server
by
DaeMyung Kang
PDF
Redis 2017
by
DaeMyung Kang
PDF
Redis
by
DaeMyung Kang
확장가능한 웹 아키텍쳐 구축 방안
by
IMQA
Scalable web architecture and distributed systems
by
eva
Scalable web architecture and distributed systems
by
현종 김
효과적인 NoSQL (Elasticahe / DynamoDB) 디자인 및 활용 방안 (최유정 & 최홍식, AWS 솔루션즈 아키텍트) :: ...
by
Amazon Web Services Korea
분산저장시스템 개발에 대한 12가지 이야기
by
NAVER D2
Soscon2017 오픈소스를 활용한 마이크로 서비스의 캐시 전략
by
Kris Jeong
091106kofpublic 091108170852-phpapp02 (번역본)
by
Taegil Heo
Tdc2013 선배들에게 배우는 server scalability
by
흥배 최
Introduction to scalability
by
polabear
대규모 서비스를 가능하게 하는 기술
by
Hyungseok Shim
Mem cached
by
ghkangduria
Memcached의 확장성 개선
by
NAVER D2
안정적인 서비스 운영 2013.08
by
Changyol BAEK
AWS Innovate: Best Practices for Migrating to Amazon DynamoDB - Sangpil Kim
by
Amazon Web Services Korea
대규모 데이터 처리 입문
by
Choonghyun Yang
No sql 이해 및 활용 공개용
by
YOUNGGYU CHUN
[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.
by
NAVER D2
Server
by
DaeMyung Kang
Redis 2017
by
DaeMyung Kang
Redis
by
DaeMyung Kang
More from DaeMyung Kang
PPTX
Count min sketch
by
DaeMyung Kang
PDF
Ansible
by
DaeMyung Kang
PDF
Why GUID is needed
by
DaeMyung Kang
PDF
How to use redis well
by
DaeMyung Kang
PPTX
The easiest consistent hashing
by
DaeMyung Kang
PDF
How to name a cache key
by
DaeMyung Kang
PDF
Integration between Filebeat and logstash
by
DaeMyung Kang
PDF
How To Become Better Engineer
by
DaeMyung Kang
PPTX
Kafka timestamp offset_final
by
DaeMyung Kang
PPTX
Kafka timestamp offset
by
DaeMyung Kang
PPTX
Data pipeline and data lake
by
DaeMyung Kang
PDF
Redis acl
by
DaeMyung Kang
PDF
Coffee store
by
DaeMyung Kang
PDF
Number system
by
DaeMyung Kang
PDF
Bloomfilter
by
DaeMyung Kang
PDF
Redis From 2.8 to 4.x(unstable)
by
DaeMyung Kang
PDF
Redis From 2.8 to 4.x
by
DaeMyung Kang
PDF
Soma search
by
DaeMyung Kang
PDF
Using spark data frame for sql
by
DaeMyung Kang
PPTX
How to study
by
DaeMyung Kang
Count min sketch
by
DaeMyung Kang
Ansible
by
DaeMyung Kang
Why GUID is needed
by
DaeMyung Kang
How to use redis well
by
DaeMyung Kang
The easiest consistent hashing
by
DaeMyung Kang
How to name a cache key
by
DaeMyung Kang
Integration between Filebeat and logstash
by
DaeMyung Kang
How To Become Better Engineer
by
DaeMyung Kang
Kafka timestamp offset_final
by
DaeMyung Kang
Kafka timestamp offset
by
DaeMyung Kang
Data pipeline and data lake
by
DaeMyung Kang
Redis acl
by
DaeMyung Kang
Coffee store
by
DaeMyung Kang
Number system
by
DaeMyung Kang
Bloomfilter
by
DaeMyung Kang
Redis From 2.8 to 4.x(unstable)
by
DaeMyung Kang
Redis From 2.8 to 4.x
by
DaeMyung Kang
Soma search
by
DaeMyung Kang
Using spark data frame for sql
by
DaeMyung Kang
How to study
by
DaeMyung Kang
Webservice cache strategy
1.
초보자를 위한 웹
서비스 캐시 전략 charsyam@naver.com
2.
Agenda •왜 캐시를
사용해야 하는가? •확장을 위한 캐시 방법
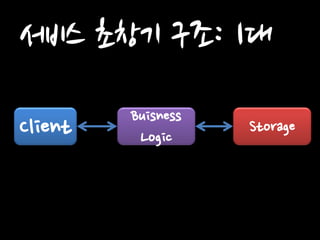
3.
서비스 초창기
4.
목표?
5.
목표? 백만, 천만?
6.
네이버 다니시나요? 그럼
1번, 아니면 2번…
7.
1번. 이걸 들을
필요가… 없습니다. T.T
8.
2번. 일단 출시가
먼저죠.
9.
Client Buisness Logic
Storage 서비스 초창기 구조: 1대
10.
서비스가 잘된다면?
11.
확장이 필요합니다.
12.
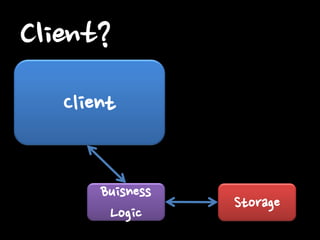
어디가 가장 문제가
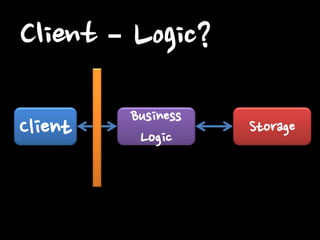
될까요?
13.
Client Buisness Logic
Storage Client?
14.
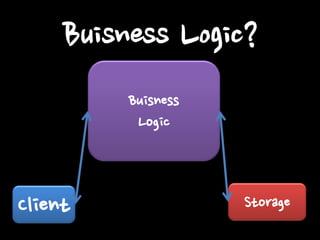
Client Buisness Logic
Storage Buisness Logic?
15.
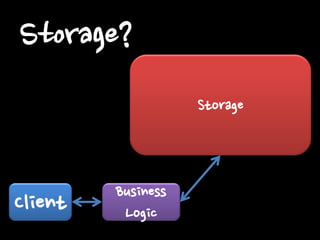
Client Business Logic
Storage Storage?
16.
선택 할 수
있는 방법?
17.
Scale Up VS
Scale Out
18.
Scale Up
19.
Scale Up 성능이
더 좋은 장비로…
20.
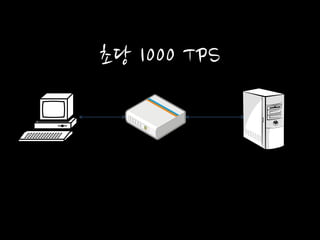
초당 1000 TPS
21.
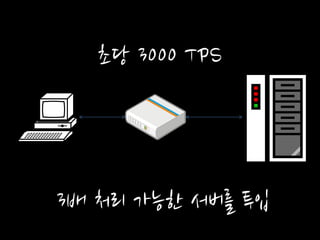
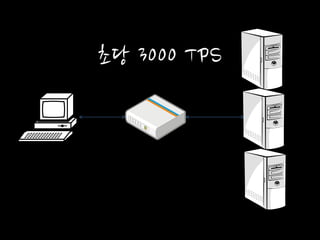
초당 3000 TPS
3배 처리 가능한 서버를 투입
22.
Scale Up CPU
4 -> 24 Mem 4G -> 32G
23.
Scale Out
24.
Scale Out 장비를
더 늘리자.
25.
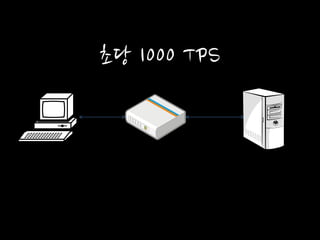
초당 1000 TPS
26.
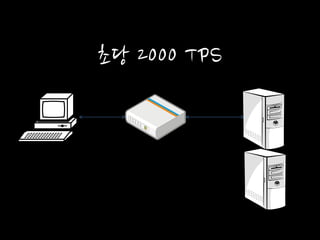
초당 2000 TPS
27.
초당 3000 TPS
28.
일반적으로는 Scale Up
이 더 쉽고 Scale Out 이 비용이 적게 든다.
29.
진실은…
30.
뒤로 가면 다~~~
어렵워요!!!
31.
뭐든지, 달리는 열차의
바퀴를 갈아 끼우는 겁니다.
32.
다시 캐시 얘기로…
33.
캐시를 선택해야 하는
이유.
34.
1. 돈이 부족한데
성능을 더 높여야 할때…
35.
2. 돈은 있지만…
성능을 더 높여야 할때…
36.
Use Case: Login
37.
Use Case: Login
DB에서 읽기 Select * from Users where id=‘charsyam’;
38.
유저 수가 적으면…
39.
충분히 빠릅니다.
40.
그런데 유저 수가
엄청 많으면?
41.
DB도 인덱스 걸면
충분히 빠릅니다.
42.
단 읽기만 한다면…
43.
또, 디스크 읽는
수 가 적을때만
44.
Disk Page 접근
문제
45.
Use Case: Login
읽기에 캐시 적용
46.
Use Case: Login
캐시에서 읽기 Get charsyam
47.
적용 결과…
48.
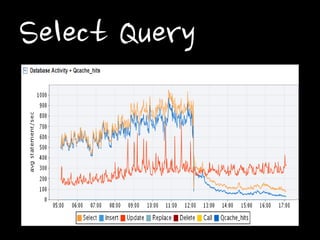
Select Query
49.
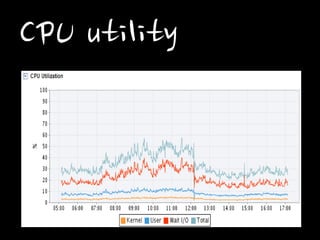
CPU utility
50.
균등한 속도!!! 부하
감소!!!
51.
Use Case: Log
52.
Use Case: Log
Apply Cache For Write
53.
Use Case: Log
Insert DB per one log Insert into clicklogs values(a,b,c);
54.
Use Case: Log
모아서 쓰기…1024개 단위 Insert into clicklogs values(a1,b1,c1), (a2,b2,c2), (a3,b3,c3)
55.
모아 쓰기를 위한
버퍼로 캐시 사용
56.
적용 결과…
57.
10 만건 insert
쓰기 단위 1 1024 속도(초) 16~17 1.4~1.5
58.
캐시를 쓰면 좋다는
건 알겠는데…
59.
그럼 캐시 서버의
확장은?
60.
1대만 쓰기에는…
61.
캐시 역시 데이터…
62.
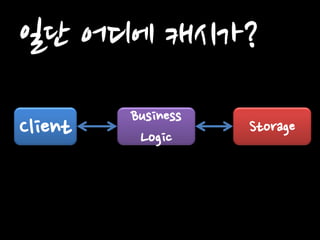
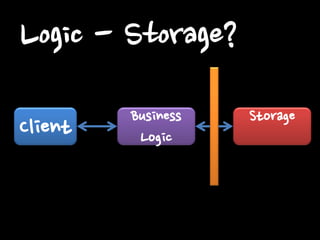
Client Business Logic
Storage 일단 어디에 캐시가?
63.
Client Business Logic
Storage Client – Logic?
64.
Client Business Logic
Storage Logic - Storage?
65.
당연히 보통은 후자가
올바릅니다.
66.
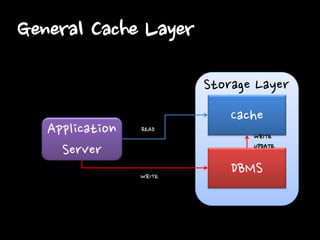
General Cache Layer
Cache DBMS Storage Layer Application Server READ WRITE WRITE UPDATE
67.
그럼 어떤 데이터를
캐시해야 할까요?
68.
당연히 자주 찾을
것 같은 데이터를 캐시해야 합니다.
69.
이런 데이터는 서비스마다
다릅니다.
70.
페이스북이라면 어떤걸 캐시하고
있을까요?
71.
Login을 위한 유저
정보
72.
첫 화면에 보여줄
피드 몇백개
73.
친구 관계등
74.
이슈는 Scale
75.
유저 로그인 관련
정보
76.
유저 로그인 관련
정보 많아도 대부분 메모리에 올라감.
77.
1k * 10,000,000
78.
1k * 10,000,000
= 10G
79.
그런데 1억명이면?
80.
한 서버당 100G?
81.
한 서버당 100G?
물론 가능함… 돈만 있으면…
82.
그럼 10억명이면?
83.
그럼 10억명이면? 1TB?
84.
캐시의 분배가 필요함
85.
캐시의 분배가 필요함
데이터
86.
결국은 분배 전략…
87.
그냥 한대?
88.
그냥 한대? LRU등으로
자주쓰는 녀석들만… 조금…
89.
여러대면?
90.
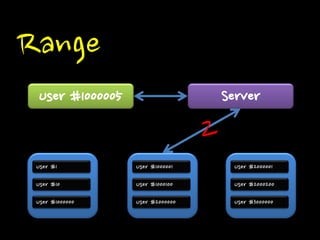
Range
91.
Range 1~백만: 1번
백만1~2백만: 2번
92.
Range Range가 너무
크면 서버별 사용 리소스가 크게 차이날 수 있다.
93.
Range 서버 추가
시에 Range 조절이 없으면 데이터 이동이 없다.
94.
Range User #1
User #10 User #1000000 User #1000001 User #1000100 User #2000000 User #2000001 User #2000200 User #3000000 Server User #1000005 2
95.
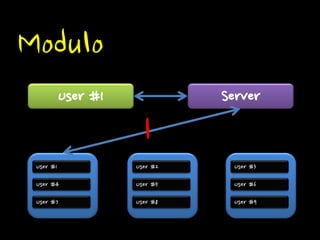
Modulo
96.
Modulo Id %
서버대수 = k
97.
Modulo 서버 대수에
따라서 데이터 이동이 많아짐.
98.
Modulo 가능하면 2배씩
증가하는 게 유리.
99.
Modulo Logical Shard
Physical Shard
100.
Modulo User #1
User #4 User #7 User #2 User #5 User #8 User #3 User #6 User #9 Server User #1 1
101.
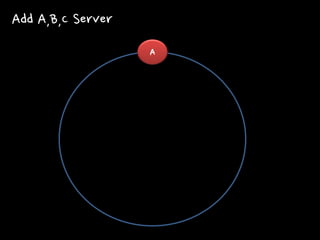
Consistent Hash
102.
Consistent Hash 서버의
추가/제거 시에 1/n 정도의 데이터만 사라진다.
103.
Consistent Hash 다른
방식은 데이터의 서버위치가 고정적이지만, CH는 유동적
104.
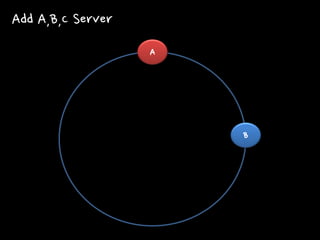
A Add A,B,C
Server
105.
A B Add
A,B,C Server
106.
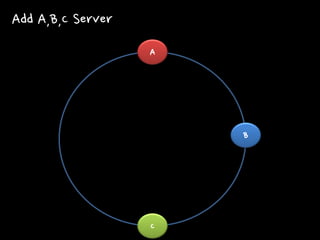
A B C
Add A,B,C Server
107.
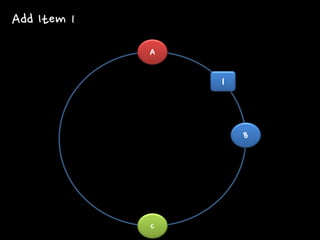
A B C
1 Add Item 1
108.
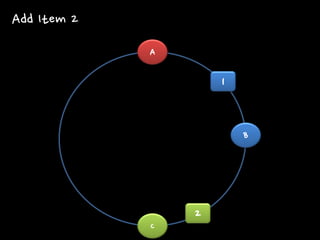
A B C
1 2 Add Item 2
109.
A B C
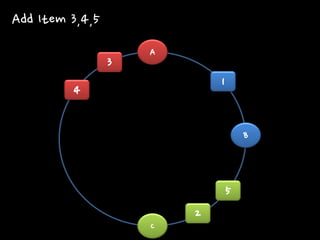
1 2 3 4 5 Add Item 3,4,5
110.
A B C
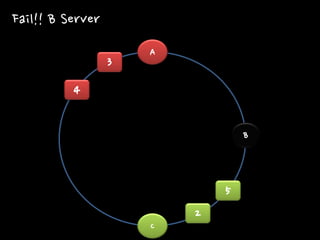
2 3 4 5 Fail!! B Server
111.
A B C
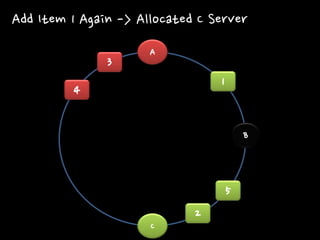
1 2 3 4 5 Add Item 1 Again -> Allocated C Server
112.
A B C
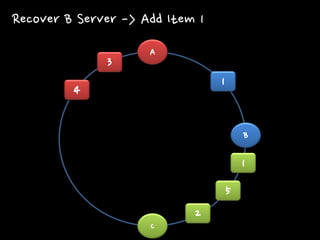
1 2 3 4 5 1 Recover B Server -> Add Item 1
113.
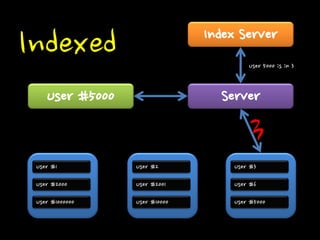
Indexed
114.
Indexed 해당 데이터가
어디 존재하는지 Index 서버가 따로 존재
115.
Indexed 해당 데이터가
어디 존재하는지 Index 서버가 따로 존재
116.
Indexed Index 변경으로
데이터 이동이 자유롭다.
117.
Indexed Index 서버에
대한 관리가 추가로 필요.
118.
Indexed User #1
User #2000 User #1000000 User #2 User #2001 User #10000 User #3 User #6 User #5000 Server User #5000 3 Index Server User 5000 is in 3
119.
다양한 변종도 있을
수 있음.
120.
적합한 방식은 서비스
마다 다름.
121.
서버의 목록은 Zookeeper
등으로 관리하면 좋음
122.
정리하면…
123.
시작할 때는 뭐
하기 어려움.
124.
다만 조금만 고민해도
Technical Debt 을 줄일 수 있음.
125.
Thank you!
Download































































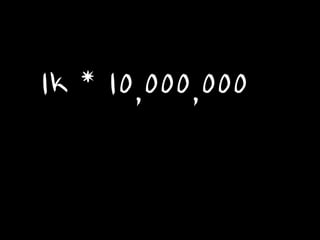
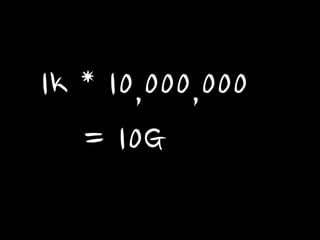























































![[124]네이버에서 사용되는 여러가지 Data Platform, 그리고 MongoDB](https://cdn.slidesharecdn.com/ss_thumbnails/124mongodb-181011042943-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Gaming on AWS] AWS와 함께 한 쿠키런 서버 Re-architecting 사례 - 데브시스터즈](https://cdn.slidesharecdn.com/ss_thumbnails/6-140305055030-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







































![[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.](https://cdn.slidesharecdn.com/ss_thumbnails/35-171016061446-thumbnail.jpg?width=640&height=640&fit=bounds)






















