Image Hosting Application
Architecture
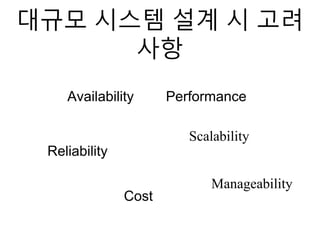
•저장될 이미지의 개수에 제한이 없다. 따라서 저장공간
의 확장성에 대해서도 고려해야 한다
• 이미지 보기나 다운로드를 요청할 때 응답 시간이 빨라
야 한다.
• 사용자가 이미지를 업로드하고 난 후, 해당 이미지는
항상 시스템에 저장되어 있어야 한다. (데이터에 대한
신뢰성)
• 시스템을 운용하기 쉬워야 한다(관리성)
• 이미지 호스팅 서비스 자체의 이익율이 높지 않기 때문
에, 시스템은 비용 효율적으로 운용될 필요가 있다.
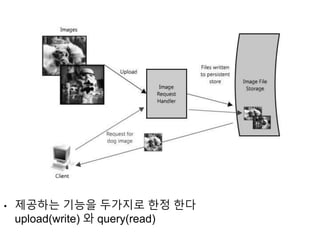
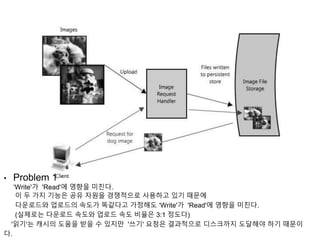
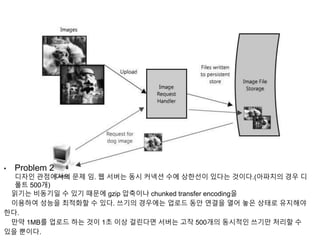
• Problem 1
‘Write'가'Read'에 영향을 미친다.
이 두 가지 기능은 공유 자원을 경쟁적으로 사용하고 있기 때문에
다운로드와 업로드의 속도가 똑같다고 가정해도 ‘Write'가 'Read'에 영향을 미친다.
(실제로는 다운로드 속도와 업로드 속도 비율은 3:1 정도다)
'읽기'는 캐시의 도움을 받을 수 있지만 '쓰기' 요청은 결과적으로 디스크까지 도달해야 하기 때문이
다.
10.
• Problem 2
디자인관점에서의 문제 임. 웹 서버는 동시 커넥션 수에 상한선이 있다는 것이다.(아파치의 경우 디
폴트 500개)
읽기는 비동기일 수 있기 때문에 gzip 압축이나 chunked transfer encoding을
이용하여 성능을 최적화할 수 있다. 쓰기의 경우에는 업로드 동안 연결을 열어 놓은 상태로 유지해야
한다.
만약 1MB를 업로드 하는 것이 1초 이상 걸린다면 서버는 고작 500개의 동시적인 쓰기만 처리할 수
있을 뿐이다.
11.
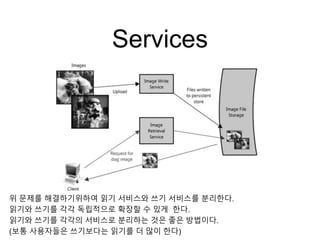
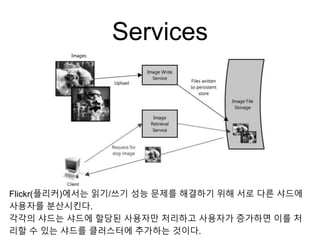
Services
위 문제를 해결하기위하여읽기 서비스와 쓰기 서비스를 분리한다.
읽기와 쓰기를 각각 독립적으로 확장할 수 있게 한다.
읽기와 쓰기를 각각의 서비스로 분리하는 것은 좋은 방법이다.
(보통 사용자들은 쓰기보다는 읽기를 더 많이 한다)
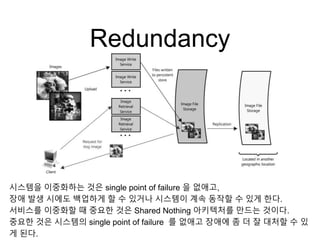
Redundancy
시스템을 이중화하는 것은single point of failure 을 없애고,
장애 발생 시에도 백업하게 할 수 있거나 시스템이 계속 동작할 수 있게 한다.
서비스를 이중화할 때 중요한 것은 Shared Nothing 아키텍처를 만드는 것이다.
중요한 것은 시스템의 single point of failure 를 없애고 장애에 좀 더 잘 대처할 수 있
게 된다.
16.
Problem !!!!!!!!
하나의 서버에서감당할 수 없는 많은 데이터가 있을 수
있다.
또는 연산을 위해 많은 컴퓨팅 자원이 필요하게 되어 성
능이 떨어지게 되는 경우가 있을 수 있다.
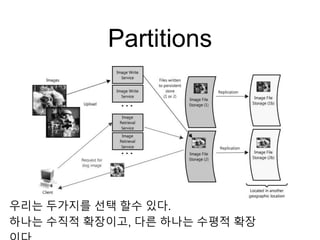
Partitions
- To scalevertically
각각의 서버에 더 많은 자원을 추가하는 것을 말한다.
많은 데이터를 처리하기 위해 서버에 하드 디스크나 더 빠른 CPU나 큰 용량의 메모리를
추가 하는 게 이에 해당한다. 즉, 수직적 확장은 각 자원의 처리 능력을 향상시키는 것을
말한다.
- To scale horizontally
데이터가 많을 경우에는 부분 데이터를 저장할 수 있는 노드를 추가하는 것이다.
수평적 확장의 장점을 모두 취하기 위해서는 시스템 아키텍처의 고유한 설계
원칙들을 따라야 한다.
수평적 확장을 하는 가장 보편적인 방법은 서비스를 파티션이나 샤드 단위
로
분할하는 것이다
19.
Problem !!!!!!!!
- datalocality (데이터 로컬리티)
연산하려는 데이터가 가까이 위치해 있을 수록 시스템의 성능은 향상된다.
따라서 필요한 데이터를 여러 서버에 분산시키는 것은 로컬에 있지 않을 수
있는 데이터를 얻기 위해 비용이 높은 네트워크를 이용한 읽기가 발생할 수
있어 잠재적인 성능 문제가 발생할 수 있다.
- inconsistency (비정합성)
공유된 자원으로부터 읽기와 쓰기를 하는 서로 다른 서비스가 있다고 가정할때.
어떠한 데이터가 업데이트되려 할 때, 읽기 요청이 업데이트 요청보다 먼저 발생했다면 해
당 데이터는 비정합성 상태가 된다.
예를 들어 어떤 클라이언트가 어떤 이미지 이름을 Dog에서 Gizmo로 바꾸는 업데이트 요청
을 보냈고,
동시에 다른 클라이언트가 해당 이미지를 읽고 있다면 경합조건이 발생한다.
20.
fault tolerance and
monitoringreference
• http://katemats.com/distributed-systems-basics-
handling-failure-fault-tolerance-and-monitoring/
LAMP stack
applications
간단한 형태의웹 애플리케이션을 많은 사용자가 사용하게 되면 두 가지 기술적
인 문제에
직면하게 된다.
1. 애플리케이션 서버에 대한 데이터 액세스를 확장성 있게 하는 것이고,
2. 데이터베이스에 대한 데이터 액세스를 확장성 있게 하는 것이다.
23.
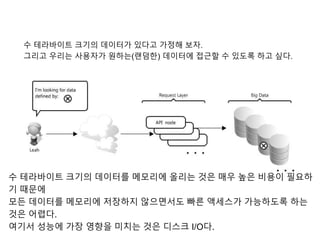
수 테라바이트 크기의데이터가 있다고 가정해 보자.
그리고 우리는 사용자가 원하는(랜덤한) 데이터에 접근할 수 있도록 하고 싶다.
수 테라바이트 크기의 데이터를 메모리에 올리는 것은 매우 높은 비용이 필요하
기 때문에
모든 데이터를 메모리에 저장하지 않으면서도 빠른 액세스가 가능하도록 하는
것은 어렵다.
여기서 성능에 가장 영향을 미치는 것은 디스크 I/O다.
24.
그러나 쉽게 하기위한 다양한 방법이 있다.
- Caches (Global Cache, Distributed Cache)
- Proxies
- Indexes
- Load Balancers
GOALS
25.
Caches ?
최근에 요청받은데이터는 다시 요청받을 확률이 높다는 지역성의 원리
(locality of reference)에 기반한 방법이다.
캐시란 매우 짧은 시간 동안 유지되는 메모리와 같은 것이다.
캐시는 아키텍처의 모든 단계에 위치할 수 있지만, 프런트엔드와 가까운 곳에
위치하는
경우가 많다. 왜냐하면 보통 캐시는 서비스의 백 엔드까지 가는 시간적인 비
용을 줄이기 위해서 사용하는 경우가 많기 때문이다.
26.
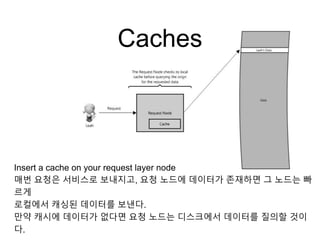
Caches
Insert a cacheon your request layer node
매번 요청은 서비스로 보내지고, 요청 노드에 데이터가 존재하면 그 노드는 빠
르게
로컬에서 캐싱된 데이터를 보낸다.
만약 캐시에 데이터가 없다면 요청 노드는 디스크에서 데이터를 질의할 것이
다.
27.
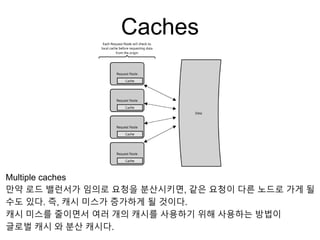
Caches
Multiple caches
만약 로드밸런서가 임의로 요청을 분산시키면, 같은 요청이 다른 노드로 가게 될
수도 있다. 즉, 캐시 미스가 증가하게 될 것이다.
캐시 미스를 줄이면서 여러 개의 캐시를 사용하기 위해 사용하는 방법이
글로벌 캐시 와 분산 캐시다.
28.
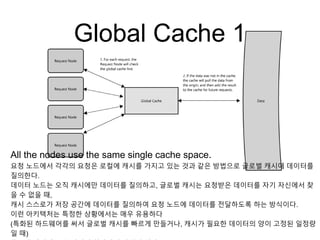
Global Cache 1
Allthe nodes use the same single cache space.
요청 노드에서 각각의 요청은 로컬에 캐시를 가지고 있는 것과 같은 방법으로 글로벌 캐시에 데이터를
질의한다.
데이터 노드는 오직 캐시에만 데이터를 질의하고, 글로벌 캐시는 요청받은 데이터를 자기 자신에서 찾
을 수 없을 때,
캐시 스스로가 저장 공간에 데이터를 질의하여 요청 노드에 데이터를 전달하도록 하는 방식이다.
이런 아키텍처는 특정한 상황에서는 매우 유용하다
(특화된 하드웨어를 써서 글로벌 캐시를 빠르게 만들거나, 캐시가 필요한 데이터의 양이 고정된 일정량
일 때)
29.
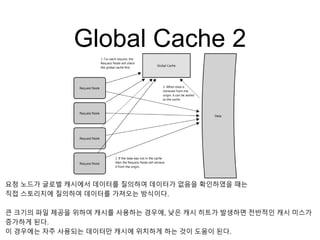
Global Cache 2
요청노드가 글로벌 캐시에서 데이터를 질의하여 데이터가 없음을 확인하였을 때는
직접 스토리지에 질의하여 데이터를 가져오는 방식이다.
큰 크기의 파일 제공을 위하여 캐시를 사용하는 경우에, 낮은 캐시 히트가 발생하면 전반적인 캐시 미스가
증가하게 된다.
이 경우에는 자주 사용되는 데이터만 캐시에 위치하게 하는 것이 도움이 된다.
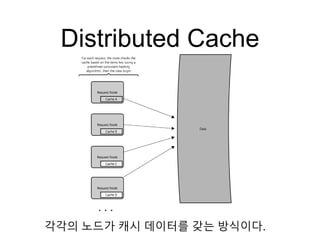
Distributed Cache
• 일반적으로분산 캐시는 consistent hashing 함수를 사
용한다.
• 해시 함수를 이용해 데이터 위치 파악 할 수 있다.
• 각각의 노드는 각각의 조그마한 캐시를 가지고 있다
• 요청이 들어오면 원본 저장 공간으로 요청을 보내기 전
에 다른 노드에 요청을 보낸다.
분산 캐시의 이런 점 때문에 요청 풀에 노드를 추가하면
전체 캐시 크기를 증가시킬 수 있다.
32.
Distributed Cache
• 분산캐시의 단점
장애가 발생한 노드를 처리하는 방법이 필요하다.
다른 노드에 여러 개의 복제본을 가지는 방법으로 해결
하기도
한다.
• 캐시의 장점
올바르게만 구현되어 있다면 시스템을 더욱 빠르게 만들
수 있다
캐시를 이용해 더욱 더 많은 요청을 이전보다 더 빠르게
처리하게 할 수도 있다.
그러나 캐시 시스템에는 값 비싼 메모리와 같은 추가적
인 저장 공간을 유지하기 위한 비용 문제가 항상 따른다.
Proxies
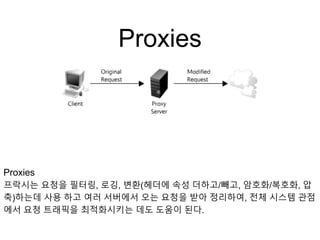
Proxies
프락시는 요청을 필터링,로깅, 변환(헤더에 속성 더하고/빼고, 암호화/복호화, 압
축)하는데 사용 하고 여러 서버에서 오는 요청을 받아 정리하여, 전체 시스템 관점
에서 요청 트래픽을 최적화시키는 데도 도움이 된다.
36.
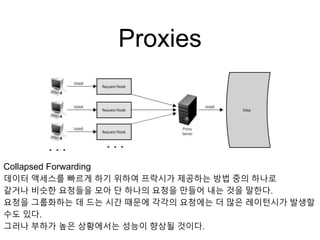
Proxies
Collapsed Forwarding
데이터 액세스를빠르게 하기 위하여 프락시가 제공하는 방법 중의 하나로
같거나 비슷한 요청들을 모아 단 하나의 요청을 만들어 내는 것을 말한다.
요청을 그룹화하는 데 드는 시간 때문에 각각의 요청에는 더 많은 레이턴시가 발생할
수도 있다.
그러나 부하가 높은 상황에서는 성능이 향상될 것이다.
37.
Proxies
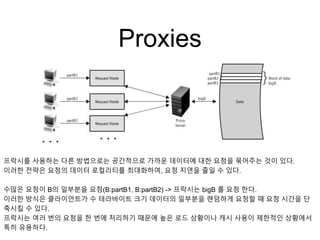
프락시를 사용하는 다른방법으로는 공간적으로 가까운 데이터에 대한 요청을 묶어주는 것이 있다.
이러한 전략은 요청의 데이터 로컬리티를 최대화하여, 요청 지연을 줄일 수 있다.
수많은 요청이 B의 일부분을 요청(B:partB1, B:partB2) -> 프락시는 bigB 를 요청 한다.
이러한 방식은 클라이언트가 수 테라바이트 크기 데이터의 일부분을 랜덤하게 요청할 때 요청 시간을 단
축시킬 수 있다.
프락시는 여러 번의 요청을 한 번에 처리하기 때문에 높은 로드 상황이나 캐시 사용이 제한적인 상황에서
특히 유용하다.
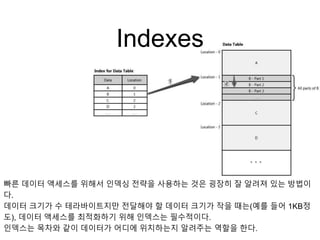
Indexes
빠른 데이터 액세스를위해서 인덱싱 전략을 사용하는 것은 굉장히 잘 알려져 있는 방법이
다.
데이터 크기가 수 테라바이트지만 전달해야 할 데이터 크기가 작을 때는(예를 들어 1KB정
도), 데이터 액세스를 최적화하기 위해 인덱스는 필수적이다.
인덱스는 목차와 같이 데이터가 어디에 위치하는지 알려주는 역할을 한다.
40.
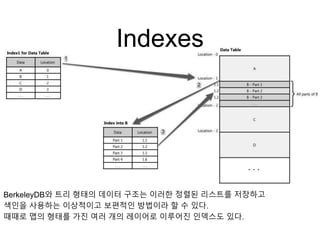
Indexes
BerkeleyDB와 트리 형태의데이터 구조는 이러한 정렬된 리스트를 저장하고
색인을 사용하는 이상적이고 보편적인 방법이라 할 수 있다.
때때로 맵의 형태를 가진 여러 개의 레이어로 이루어진 인덱스도 있다.
41.
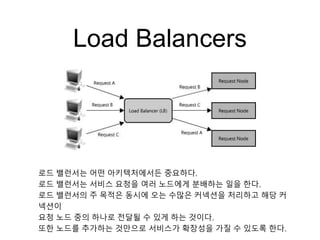
Load Balancers
로드 밸런서는어떤 아키텍처에서든 중요하다.
로드 밸런서는 서비스 요청을 여러 노드에게 분배하는 일을 한다.
로드 밸런서의 주 목적은 동시에 오는 수많은 커넥션을 처리하고 해당 커
넥션이
요청 노드 중의 하나로 전달될 수 있게 하는 것이다.
또한 노드를 추가하는 것만으로 서비스가 확장성을 가질 수 있도록 한다.
42.
Open Source Load
Balancers
로드밸런서에서 서비스 요청을 처리하는 방법에는 다양한 알고리즘이 있다.
( 랜덤, 라운드 로빈, CPU나 메모리 사용률 등과 같은 특정 범주에 따라 노드를 선택하는 등의 방법이 있다)
로드 밸런서는 소프트웨어로 구현될 수도 있고 하드웨어 제품이 될 수도 있다.
43.
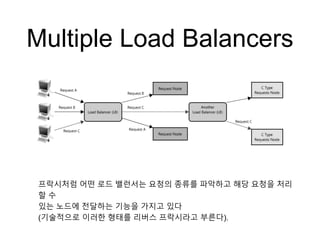
Multiple Load Balancers
프락시처럼어떤 로드 밸런서는 요청의 종류를 파악하고 해당 요청을 처리
할 수
있는 노드에 전달하는 기능을 가지고 있다
(기술적으로 이러한 형태를 리버스 프락시라고 부른다).
44.
Queue
시스템이 확장성 있도록설계하려면 쓰기에 대한 고려 또한 필요하다.
데이터가 여러 곳에 분산된 서버나 인덱스에 쓰여야 하고 당시의 시스템 부하 상태가
높다면 쓰기 연산은 매우 오랜 시간이 걸리게 된다.
이럴 때 시스템의 성능과 가용성을 얻기 위해서 사용하는 보편적인 방법은 큐를 사용하
는 것이다.
45.
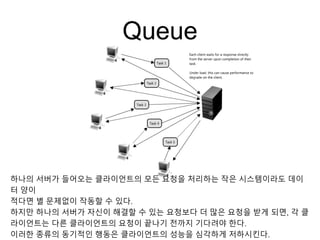
Queue
하나의 서버가 들어오는클라이언트의 모든 요청을 처리하는 작은 시스템이라도 데이
터 양이
적다면 별 문제없이 작동할 수 있다.
하지만 하나의 서버가 자신이 해결할 수 있는 요청보다 더 많은 요청을 받게 되면, 각 클
라이언트는 다른 클라이언트의 요청이 끝나기 전까지 기다려야 한다.
이러한 종류의 동기적인 행동은 클라이언트의 성능을 심각하게 저하시킨다.
46.
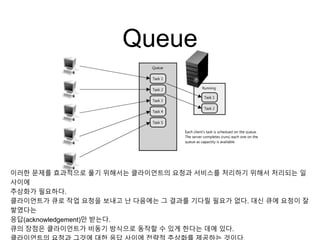
Queue
이러한 문제를 효과적으로풀기 위해서는 클라이언트의 요청과 서비스를 처리하기 위해서 처리되는 일
사이에
추상화가 필요하다.
클라이언트가 큐로 작업 요청을 보내고 난 다음에는 그 결과를 기다릴 필요가 없다. 대신 큐에 요청이 잘
쌓였다는
응답(acknowledgement)만 받는다.
큐의 장점은 클라이언트가 비동기 방식으로 동작할 수 있게 한다는 데에 있다.
#4 가용성(Availability): 웹 사이트의 가용성은 많은 회사의 명성과 기능에 절대적으로 중요한 것이다.
분산 시스템에서 높은 가용성을 얻기 위해, 중요한 컴포넌트의 이중화와 실패가 발생했을 경우에 대한 빠른 복구 방법,
문제가 발생할 때 일부만으로 동작할 수 있게 해 전면 장애가 발생하지 않게 하는 구성(graceful degradation)에 대한 고려가 필요하다.
성능(Performance): 대부분의 웹 사이트에서 성능은 매우 중요한 고려사항이다.
결과적으로 빠른 응답 시간과 낮은 레이턴시를 위해서 최적화된 시스템을 만드는 것은 중요하다.
신뢰성(Reliability): 항상 똑같은 요청에는 똑같은 결과를 제공해야 한다. (정합성)
시스템이 항상 정상적으로 동작해야 한다는 말이다.
데이터가 변하거나 업데이트되고 나면 업데이트된 새로운 데이터를 반환해야 한다.
확장성(Scalability): 대규모의 분산 시스템에서라면 규모 자체는 확장성에서 고려해야 할 하나의 측면에 불과하다.
중요한 것은 더 많은 부하를 처리할 수 있도록 처리량을 증가시키기 위해 필요한 노력이다.
관리성(Manageability): 쉽게 운용할 수 있는 시스템을 설계하는 것은 또 다른 중요한 고려 사항이다.
시스템의 관리성이란 운용(유지와 업데이트)의 확장성과 같은 말이다.
관리성이 좋아지려면 문제 발생 시 분석이 용이해야 하며 문제를 이해하기 쉬워야 한다.
그리고 업데이트와 수정, 시스템 운용 자체가 쉬워야 한다
비용(Cost): 비용은 중요한 요소다시스템을 배포하고 관리하는 비용 또한 중요하게 고려해야 한다.
이러한 비용에는 시스템이 빌드하는 데 걸리는 시간, 시스템을 실행시키는 데 드는 운용 노력의 양,
모든 고려해야 할 사항에 대해서 필요한 교육 비용까지 포함된다. 즉 비용은 시스템 소유에 필요한 모든 비용이다.
#6 모든 대규모 웹 애플리케이션에 필요한 핵심 사항인 '서비스들', '이중화', '분할', '예외 처리'를 다룬다.
이러한 사항 각각에 대해서는 앞에서 고려한 사항에 기반한 선택과 합의가 필요하다.
#13 확장성 있는 시스템을 설계할 때 각각의 명확한 인터페이스를 기반으로 기능별로 나누어 생각하는 것은 좋은 방법이다. 이러한 방식으로 설계하는 시스템을 SOA(Service-Oriented Architecture)라고 부른다. SOA에서는 명확하게 기능별로 서비스를 구성한다. 그리고 각각의 서비스는 다른 서비스와 상호 작용을 위해 다른 서비스에서 공개하는 API 형태인 추상화된 인터페이스를 사용한다.
시스템을 상호 보완적인 서비스로 분할한다는 것은 시스템을 기능 단위로 분리시키는 것을 말한다. 이러한 추상화는 서비스와 서비스가 처한 환경 그리고 서비스와 서비스 사용자 사이의 명확한 관계를 수립하는 데에 도움이 된다. 이러한 명확한 기술은 문제를 분리시키는 데도 도움이 되지만, 각각을 독립적으로 확장시키는 것에도 효과적이다.

































![[오픈소스컨설팅] About Storage Cloud](https://cdn.slidesharecdn.com/ss_thumbnails/dist-140126195610-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












![[오픈소스컨설팅]Glster FS간단소개](https://cdn.slidesharecdn.com/ss_thumbnails/glsterfs-140610201727-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



![3.[d2 오픈세미나]분산시스템 개발 및 교훈 n base arc](https://cdn.slidesharecdn.com/ss_thumbnails/3-140905000012-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[오픈소스컨설팅]이기종 WAS 클러스터링 솔루션- Athena Dolly](https://cdn.slidesharecdn.com/ss_thumbnails/athena-dollyv3-150206074107-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)




![[제14회 JCO 컨퍼런스] 개발자를 위한 서버이중화 by JAVACAFE](https://cdn.slidesharecdn.com/ss_thumbnails/jco14javacafefinal-140223223800-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[EVA] 5. Detection Patterns - Patterns for Fault Tolerant Software](https://cdn.slidesharecdn.com/ss_thumbnails/faulttolerance5-130909120428--thumbnail.jpg?width=640&height=640&fit=bounds)
![[EVA] 4.9 Escalation - Patterns for Fault Tolerant Software](https://cdn.slidesharecdn.com/ss_thumbnails/evaescalation-130908130353--thumbnail.jpg?width=640&height=640&fit=bounds)

![[FTP] 4-10 fault observer](https://cdn.slidesharecdn.com/ss_thumbnails/10faultobserver-130829091620-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[FTP] 4-8 Someone in charge](https://cdn.slidesharecdn.com/ss_thumbnails/someoneincharge-130824081649-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





