Downloaded 22 times





















![Kernel CFS Bug (Kubernetes Issue #874)
[ 3960.004144] BUG: unable to handle kernel NULL pointer dereference at 0000000000000080
[ 3960.008059] IP: [<ffffffff810b332f>] pick_next_task_fair+0x30f/0x4a0
[ 3960.008059] PGD 6e7bd7067 PUD 72813c067 PMD 0
[ 3960.008059] Oops: 0000 [#1] SMP
[ 3960.008059] Modules linked in: xt_statistic(E) xt_nat(E) ......
[ 3960.008059] CPU: 4 PID: 10158 Comm: mysql_tzinfo_to Tainted: G E 4.4.41-k8s #1
[ 3960.008059] Hardware name: Xen HVM domU, BIOS 4.2.amazon 11/11/2016
[ 3960.008059] task: ffff8807578fae00 ti: ffff88075f028000 task.ti: ffff88075f028000
[ 3960.008059] RIP: 0010:[<ffffffff810b332f>] [<ffffffff810b332f>] pick_next_task_fair+0x30f/0x4a0
[ 3960.008059] RSP: 0018:ffff88075f02be38 EFLAGS: 00010046
[ 3960.008059] RAX: 0000000000000000 RBX: ffff8807250ff400 RCX: 0000000000000000
[ 3960.008059] RDX: ffff88078fc95e30 RSI: 0000000000000000 RDI: ffff8807250ff400
[ 3960.008059] RBP: 0000000000000000 R08: 0000000000000000 R09: ffff88076bc13700
[ 3960.008059] R10: 0000000000001cf7 R11: ffffea001c98a100 R12: 0000000000015dc0
[ 3960.008059] R13: 0000000000000000 R14: ffff88078fc95dc0 R15: 0000000000000004
[ 3960.008059] FS: 00007fa34b7f6740(0000) GS:ffff88078fc80000(0000) knlGS:0000000000000000
[ 3960.008059] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 3960.008059] CR2: 0000000000000080 CR3: 000000067762d000 CR4: 00000000001406e0
[ 3960.008059] Stack:
[ 3960.008059] ffff8807578fae00 0000000000001000 0000000200000000 0000000000015dc0
[ 3960.008059] ffff88078fc95e30 00007fa34b7fc000 000000005ef04228 ffff88078fc95dc0
[ 3960.008059] ffff8807578fae00 0000000000015dc0 0000000000000000 ffff8807578fb2a0
[ 3960.008059] Call Trace:
[ 3960.008059] [<ffffffff8159cd1f>] ? __schedule+0xdf/0x960
[ 3960.008059] [<ffffffff8159d5d1>] ? schedule+0x31/0x80
[ 3960.008059] [<ffffffff810031cb>] ? exit_to_usermode_loop+0x6b/0xc0
[ 3960.008059] [<ffffffff81003bcf>] ? syscall_return_slowpath+0x8f/0x110
[ 3960.008059] [<ffffffff815a1518>] ? int_ret_from_sys_call+0x25/0x8f
[ 3960.008059] Code: c6 44 24 17 00 eb ......
[ 3960.008059] RIP [<ffffffff810b332f>] pick_next_task_fair+0x30f/0x4a0
[ 3960.008059] RSP <ffff88075f02be38>
[ 3960.008059] CR2: 0000000000000080
[ 3960.008059] ---[ end trace e1b9f0775b83e8e3 ]---
[ 3960.008059] Kernel panic - not syncing: Fatal exception](https://image.slidesharecdn.com/webcastx-makingkubernetesproductionready-170721180732/85/Webcast-Making-kubernetes-production-ready-25-320.jpg)





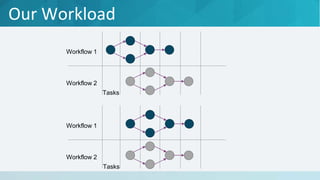
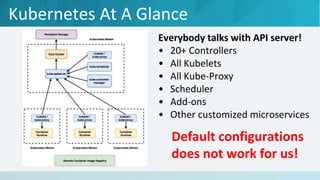
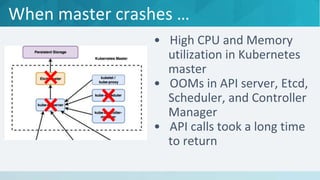
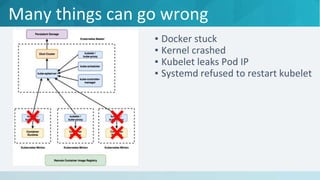
The document discusses strategies to make Kubernetes production-ready, focusing on the challenges of managing high pod churn and ensuring stability under load. It emphasizes the need for specific configurations and resource management to avoid crashes and maintain performance, particularly for the Kubernetes master and minion nodes. The document concludes by stating that Kubernetes can be stable and production-ready when properly managed.









![[Spark Summit 2017 NA] Apache Spark on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkonkubernetespublic1-170929072840-thumbnail.jpg?width=640&height=640&fit=bounds)



!["[WORKSHOP] K8S for developers", Denis Romanuk](https://cdn.slidesharecdn.com/ss_thumbnails/k8sfordevs-210906100414-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)

![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)














