Downloaded 108 times







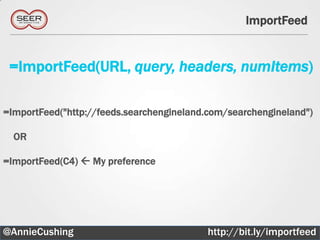
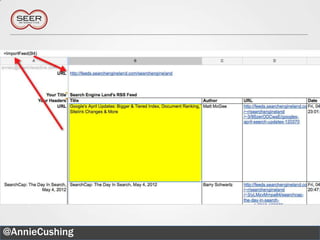



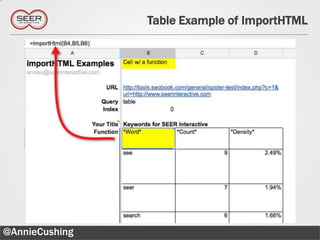
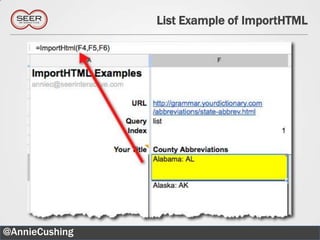








![Simple Explanation of XPath
KEY CHARACTERS
/: Starts at the root
//: Starts wherever
@: Selects attributes
[]: Answers the question “Which one?”
[*]: All
@AnnieCushing 23](https://image.slidesharecdn.com/mozcationinphilly05-10-12-120509111210-phpapp01/85/Web-Scraping-for-Code-ophobes-23-320.jpg)

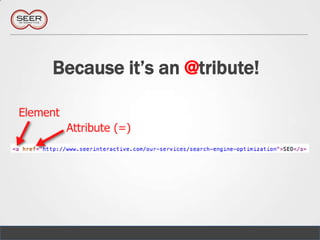


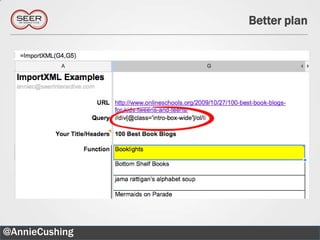

![Can even be in the middle of the XPath
//div[@class=„main‟]//blockquote[2]
@AnnieCushing 36](https://image.slidesharecdn.com/mozcationinphilly05-10-12-120509111210-phpapp01/85/Web-Scraping-for-Code-ophobes-36-320.jpg)
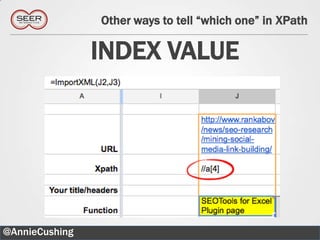
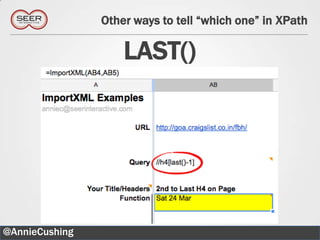


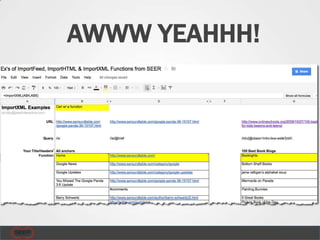



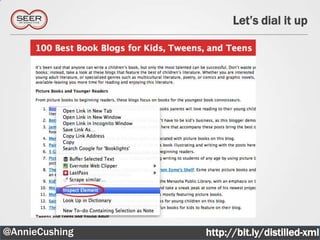
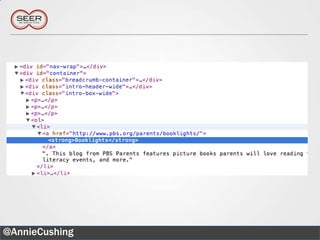
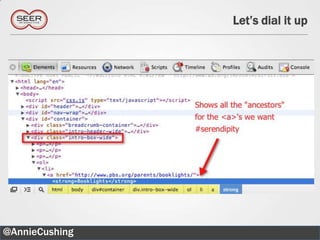
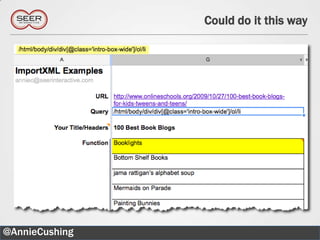
The document provides an introductory guide to web scraping using Google Docs, highlighting three main functions: IMPORTFEED, IMPORTHTML, and IMPORTXML. It includes explanations of XPath for selecting nodes in XML documents, along with practical examples of how to structure these queries. The text also offers various applications for web scraping, along with resources for further exploration.






















































