Downloaded 10 times



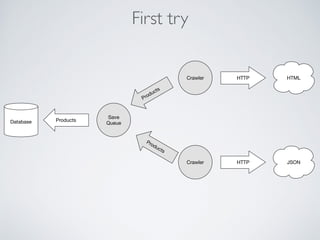
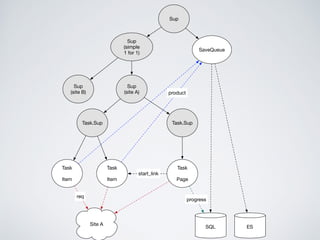

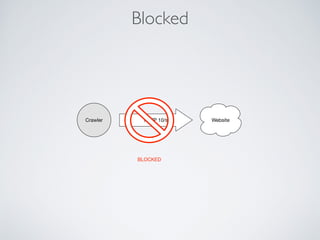
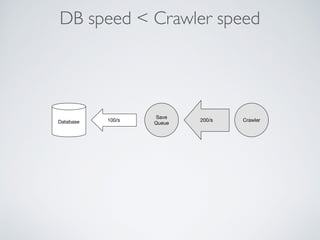
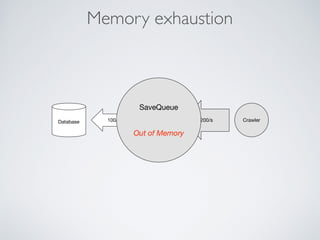

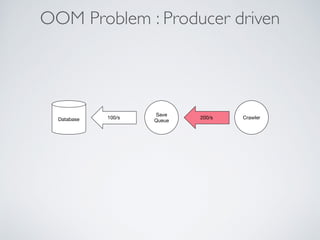
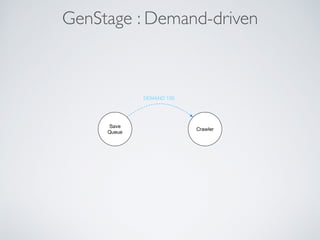
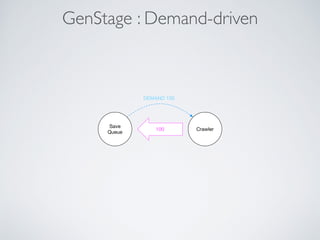
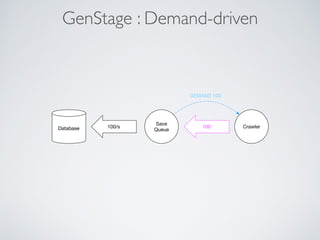
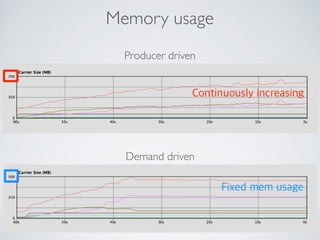
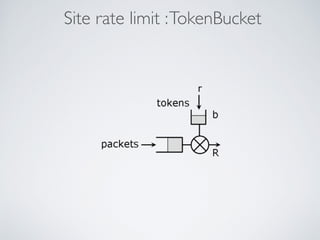
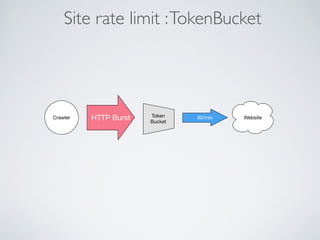

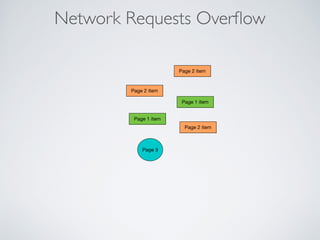



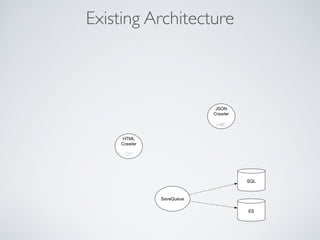
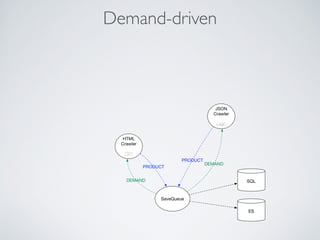
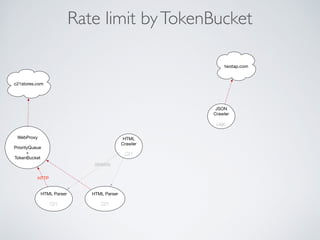

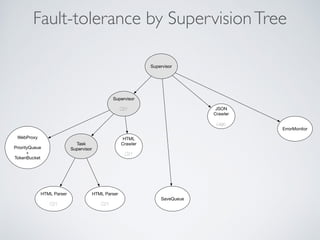
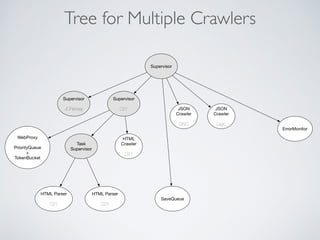
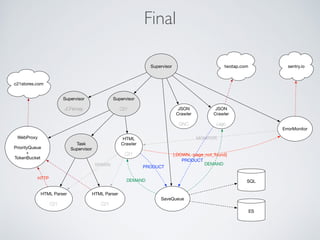







This document summarizes the key steps taken to optimize a web crawler built with Elixir. It describes: 1) Moving from a producer-driven to a demand-driven architecture using GenStage to prevent memory exhaustion from the crawler producing items faster than the database could save them. 2) Adding rate limiting via TokenBucket to avoid exceeding site rate limits when crawling multiple pages concurrently. 3) Using a priority queue and supervision tree to introduce fault tolerance and allow crawling multiple sites in parallel while respecting each site's rate limits.



























![[AWSKRUG&JAWS-UG Meetup #1] 70% Cost Reduction with On-demand resizing](https://cdn.slidesharecdn.com/ss_thumbnails/awsjawsondemandresizing-160526114219-thumbnail.jpg?width=640&height=640&fit=bounds)
















































