Downloaded 369 times













![How can represent a feature/text?
• Vector Space Model(VSM)
• Document d is represented in the VSM as a
vector [wt0 , wt1 , . . .wtn]
where t0, t1, . . . tn is a set of words/features
and wti is the weight/importance of feature ti
Eg:
d→“Polly had a dog and the dog had Polly”
vsm representation
Arun TR
14,S7CS](https://image.slidesharecdn.com/ppt-150827161630-lva1-app6892/85/web-clustering-engines-16-320.jpg)


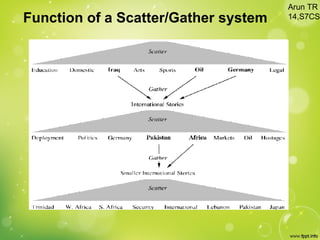



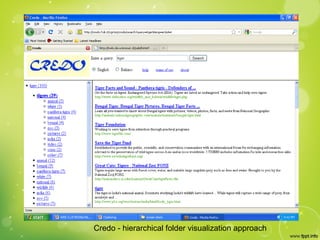







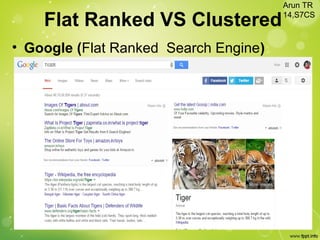
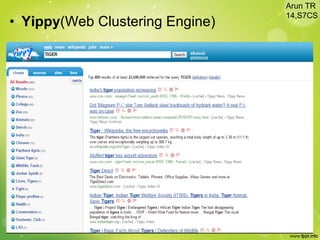
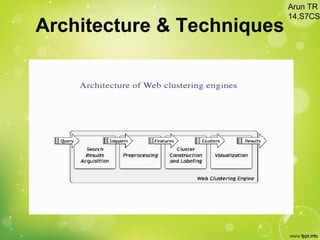
This document discusses web clustering engines, which group search results from a query into meaningful categories to help users better understand the topic. Conventional search engines return a flat list of results, which can include irrelevant items for ambiguous queries. Web clustering engines address this by applying clustering algorithms to search results to dynamically generate labeled categories. They acquire results from other search engines, preprocess the text, extract features, cluster the results using algorithms like agglomerative hierarchical clustering, and visualize the clusters in a hierarchical folder view or graph. This improves search by providing shortcuts to related results and allowing systematic exploration of topics.