Download to read offline


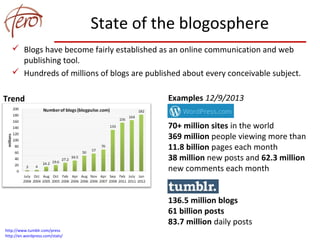
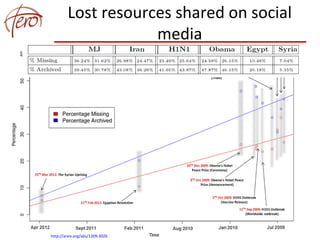


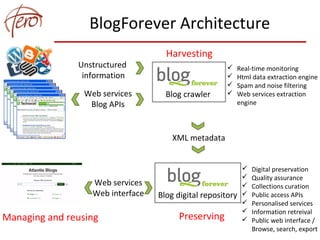


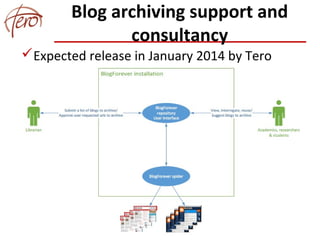
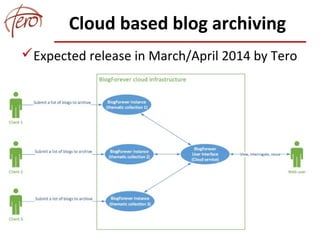
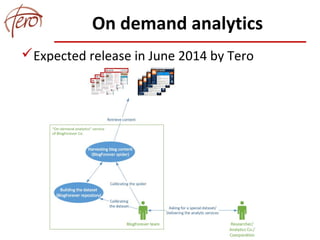


This document discusses blog archiving and the BlogForever project. It notes that hundreds of millions of blogs exist but many are being lost over time as websites disappear. The BlogForever project aims to harvest, preserve, manage and reuse blog content and resources through the development of a blog archiving system. This system crawls blogs, extracts content and metadata, and stores this information in a digital repository to ensure long-term access. The goals are to structure archived content to increase its utility and provide added value services like analytics. The system is being adopted by universities, libraries and researchers to archive collections of blogs.















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)






