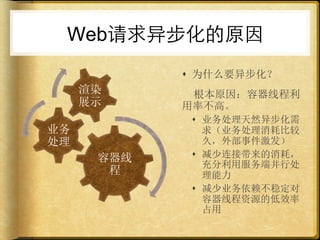
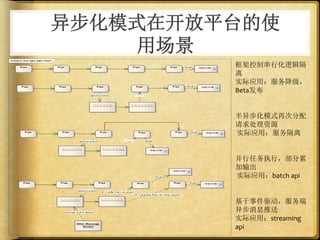
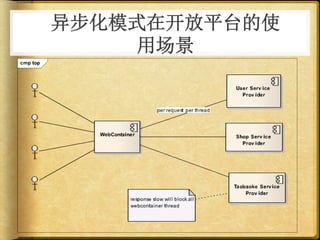
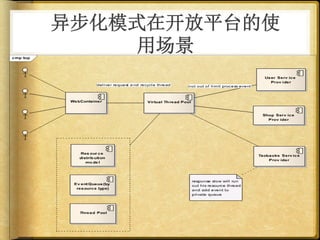
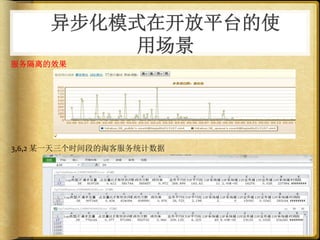
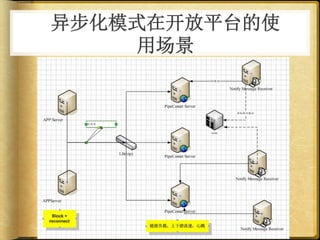
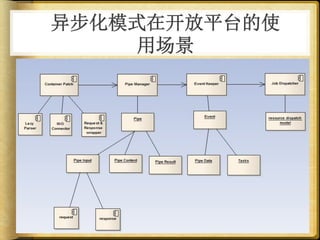
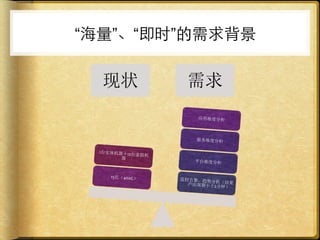
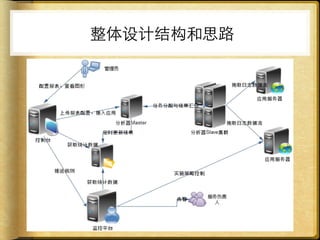
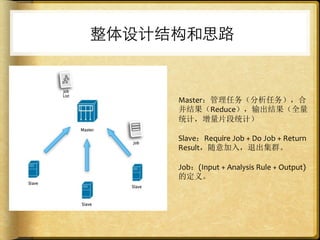
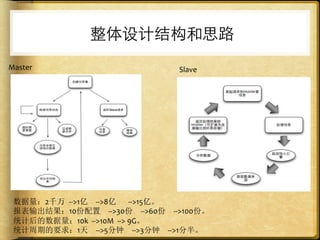
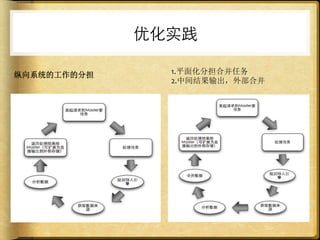
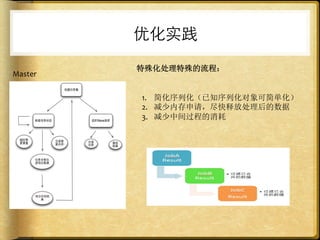
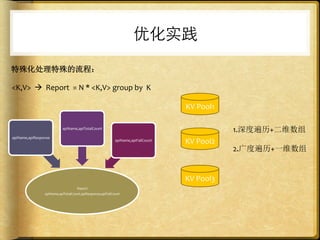
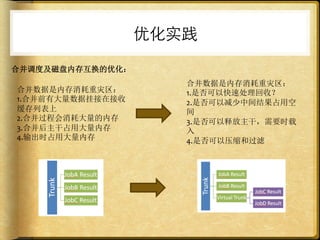
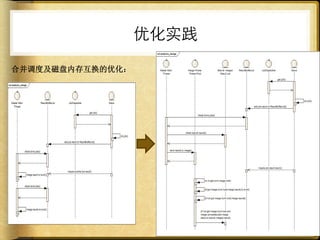
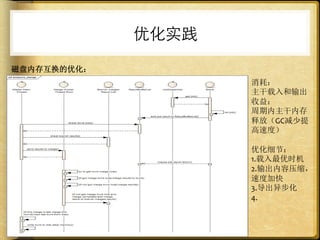
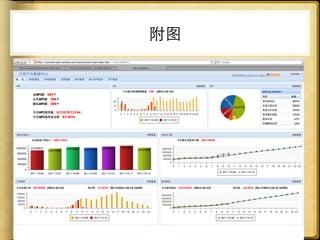
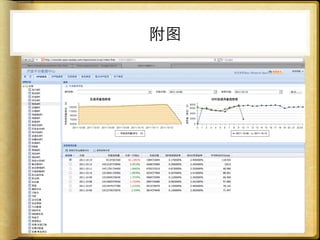
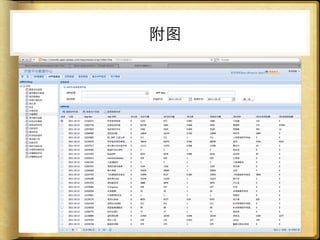
文档讨论了 web 请求异步化处理的原因与实践,强调了其在开放平台中的应用场景及整体设计思路。通过异步化能够有效减少连接消耗和提高资源利用率,同时提供了优化实践以提升处理能力。文中还包括了相关工具和链接以供参考。