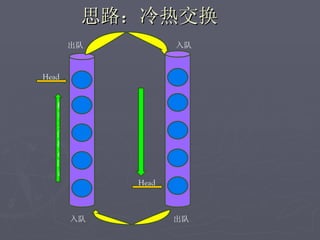
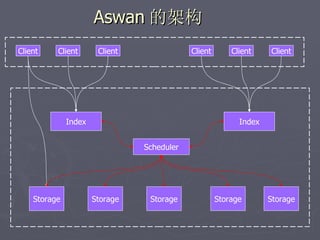
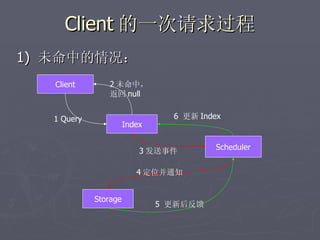
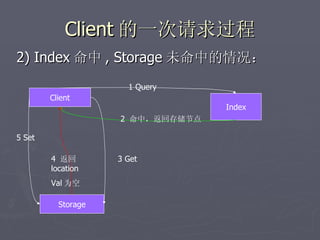
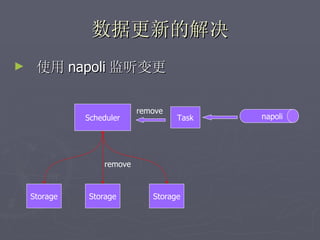
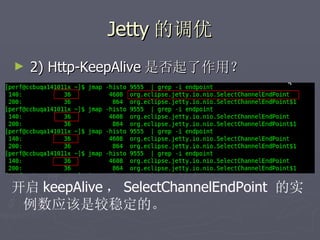
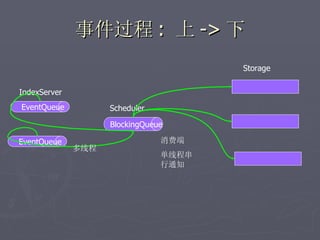
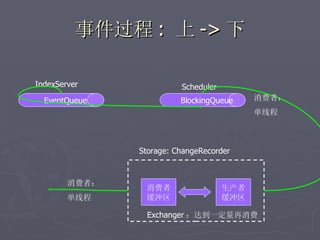
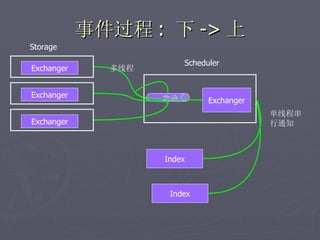
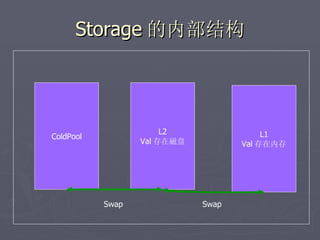
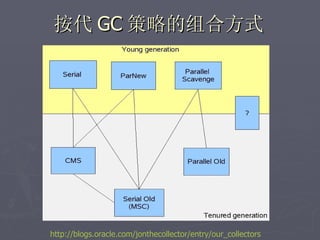
文档讨论了阿斯旺平台的访问统计、架构设计及存储结构,强调大数据量和离散性问题,对缓存和数据存储的解决方案进行了深入分析。介绍了事件过程、通讯框架的选择、性能调优和垃圾回收策略,并提及分布式系统中的一些技术,如gossip协议和paxos算法。最后总结了架构的缺陷及改进方向,提出了简化版热点缓存的设计思路。