What is Redis?
What is
sponsored by:
• 全名 REmote DIctionary Server
• Redis is an open source, advanced key-value store. It is often
referred to as a data structure server since keys can
contain strings, hashes, lists, sets and sorted sets.
• key value store? cache? memory database? data structure
server?
13.
优点
• FAST both read and write
• data can dump to disk
• master-slave
• many useful data structure
• Active community/ Antirez
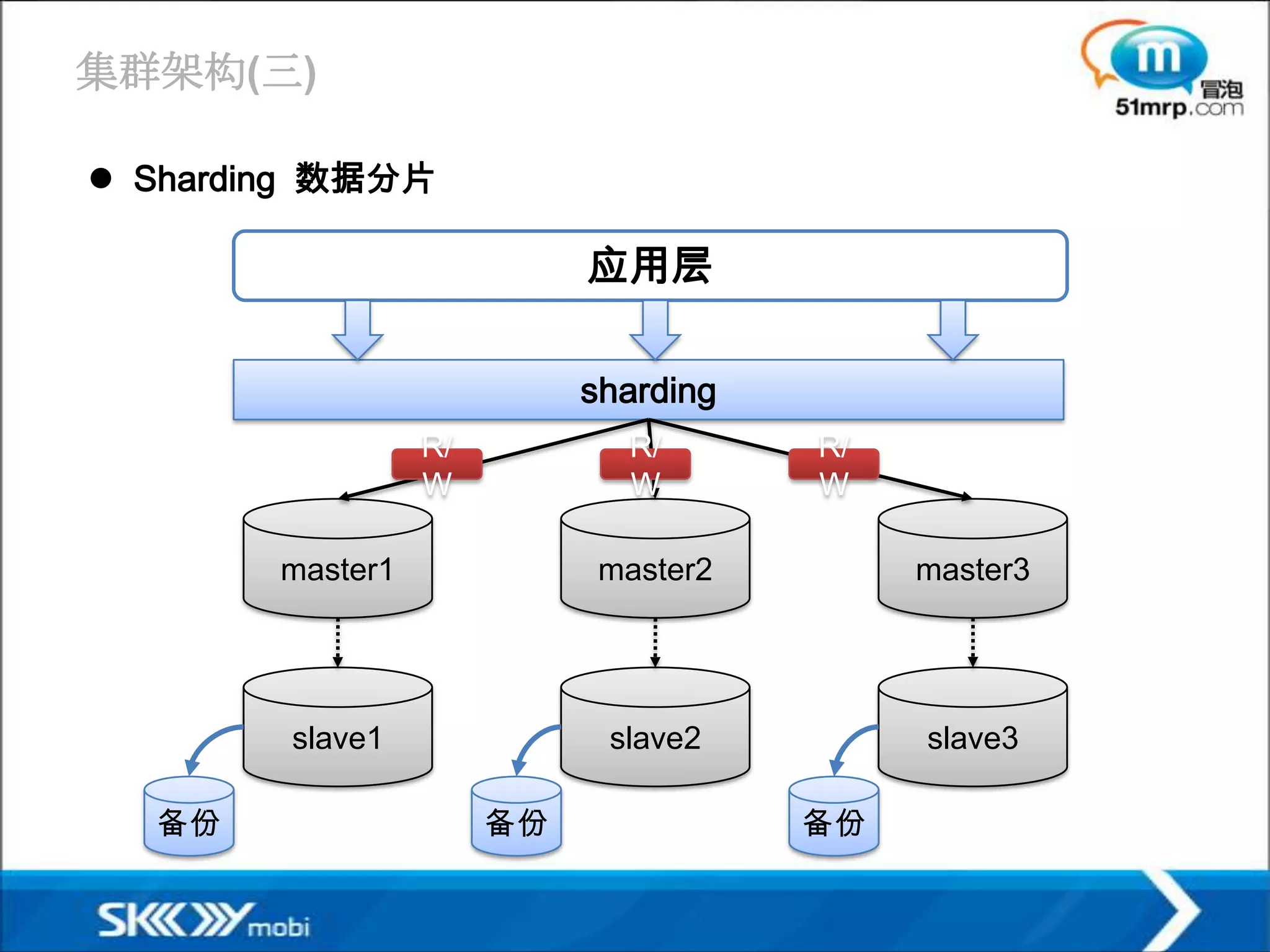
集群架构(三)
Sharding 数据分片
应用层
sharding
R/ R/ R/
W W W
master1 master2 master3
slave1 slave2 slave3
备份 备份 备份
42.
集群架构(四)
•All nodes are directly connected with a
service channel.
•TCP baseport+4000, example 6379 ->
10379.
•Node to Node protocol is binary,optimized
for bandwidth and speed.
•Clients talk to nodes as usually, using ascii
protocol, with minor additions.
•Nodes don't proxy queries.


















![Useful data structure
键(keys) 值(values)
page:index.html <html><head>[...] String
users_logged_in_today { 1, 2, 3, 4, 5 } Sets
latest_post_ids [201, 204, 209,..] List
users_and_scores joe ~ 1.3483 ZSets
bert ~ 93.4
fred ~ 283.22
chris ~ 23774.17](https://image.slidesharecdn.com/nosql-111101201856-phpapp01/75/Nosql-19-2048.jpg)