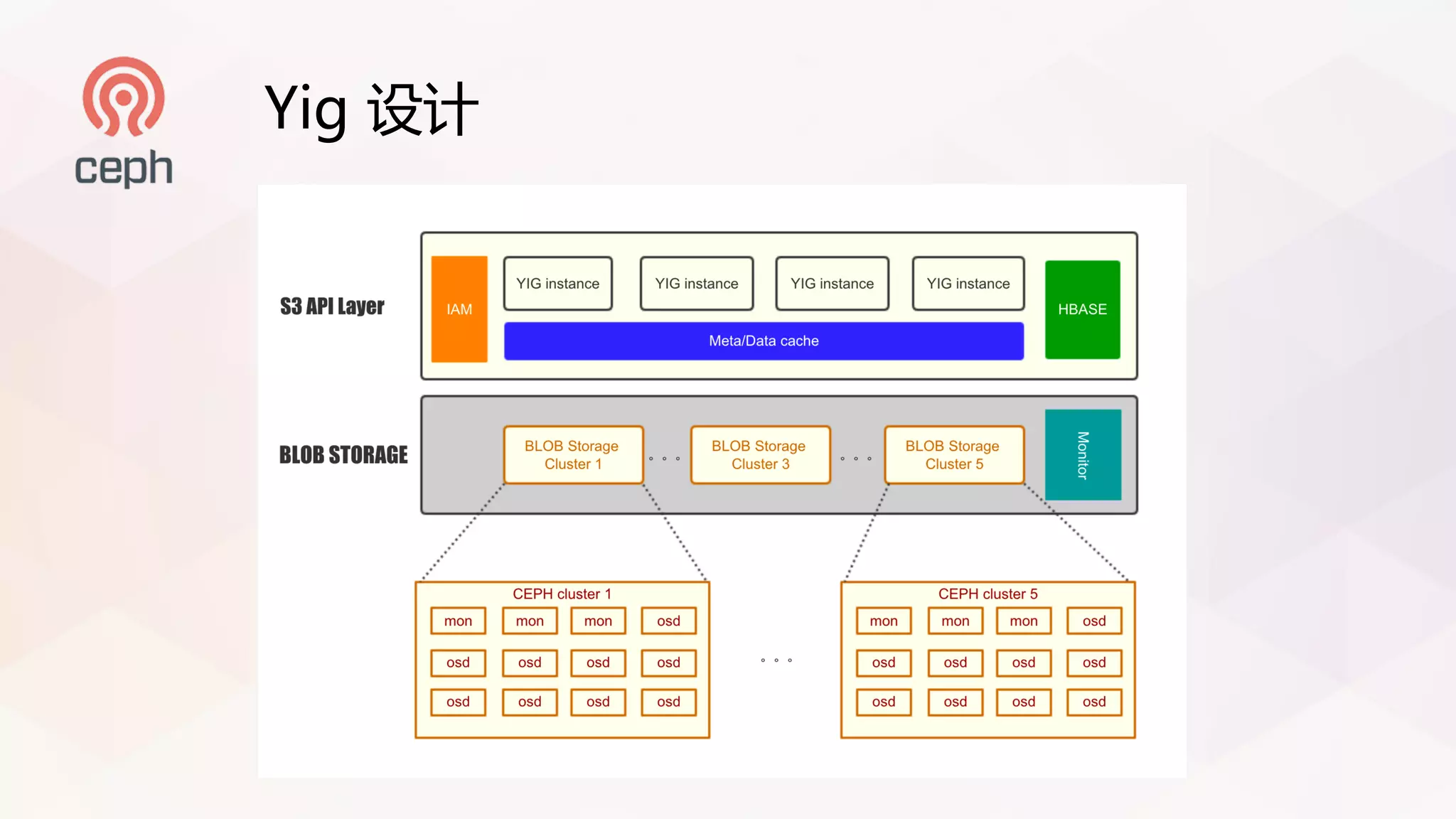
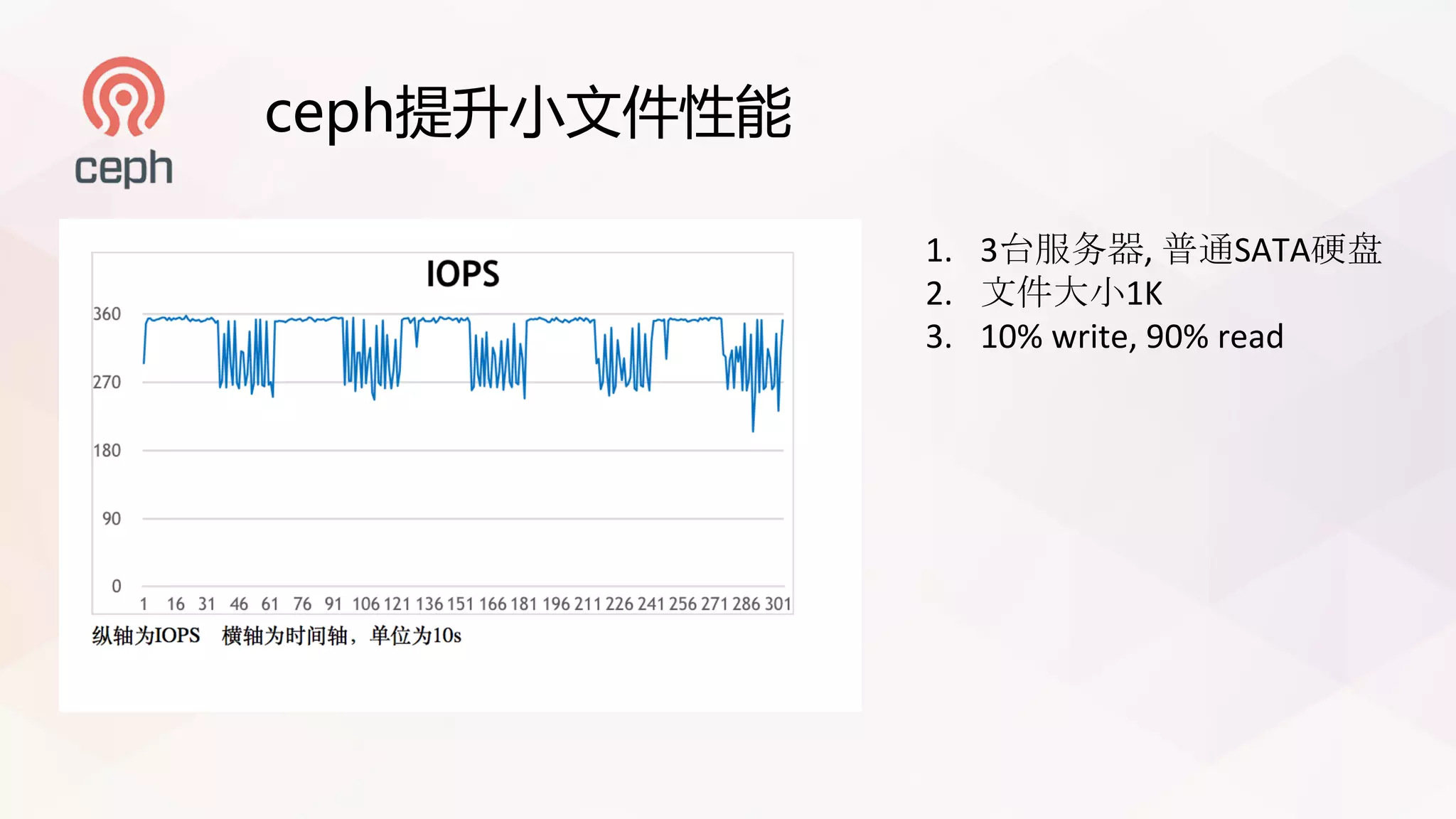
本文讨论了基于Ceph构建EB级对象存储系统的挑战和优化方案,包括RADOSGW的数据处理瓶颈、缓存共享、以及YIG架构的优势。具体提到了一系列性能提升策略,针对大文件和小文件的读写性能提出了相应的解决方案。文章还介绍了未来在存储引擎和数据一致性模型上的考虑。