Download to read offline

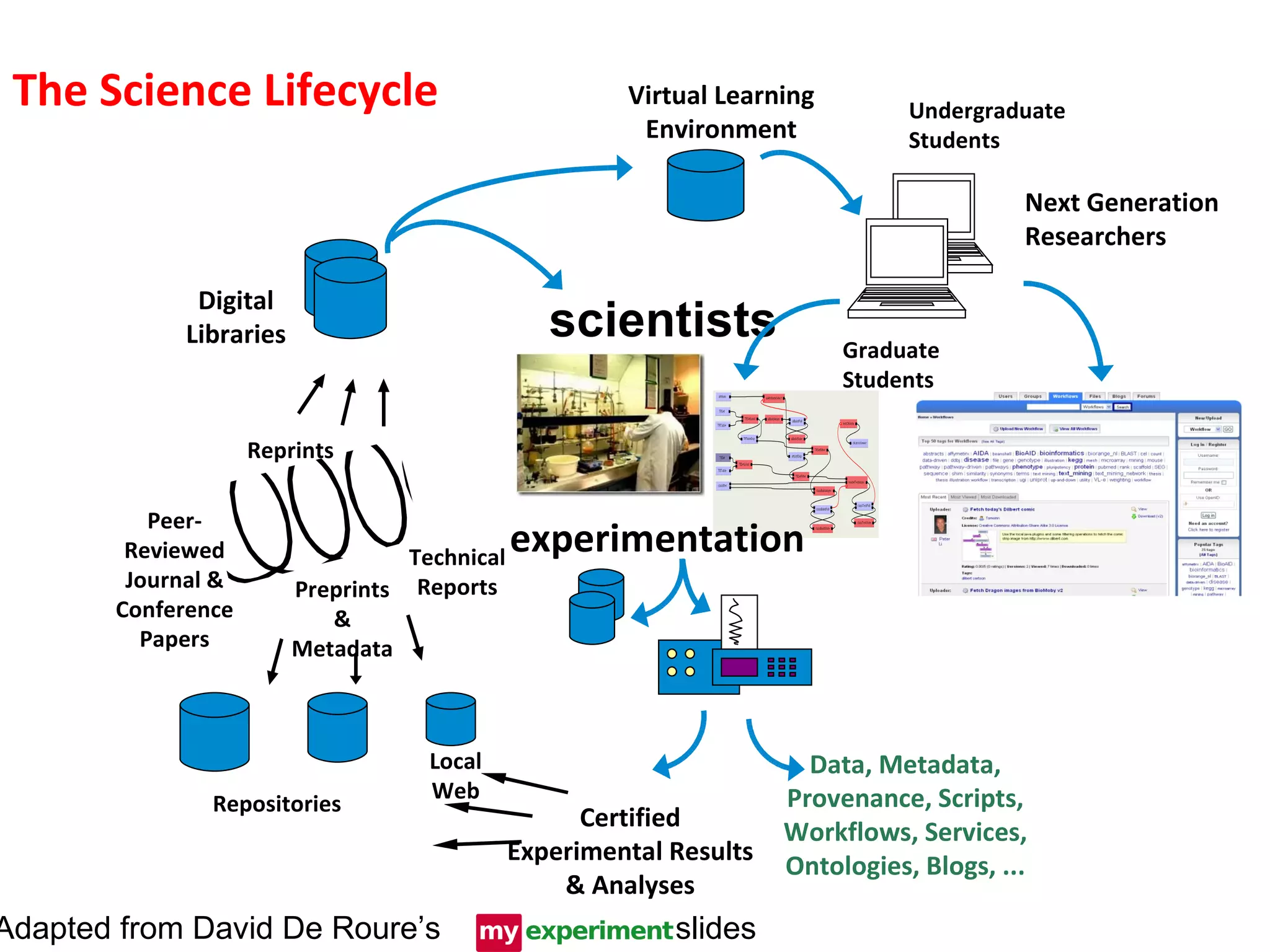


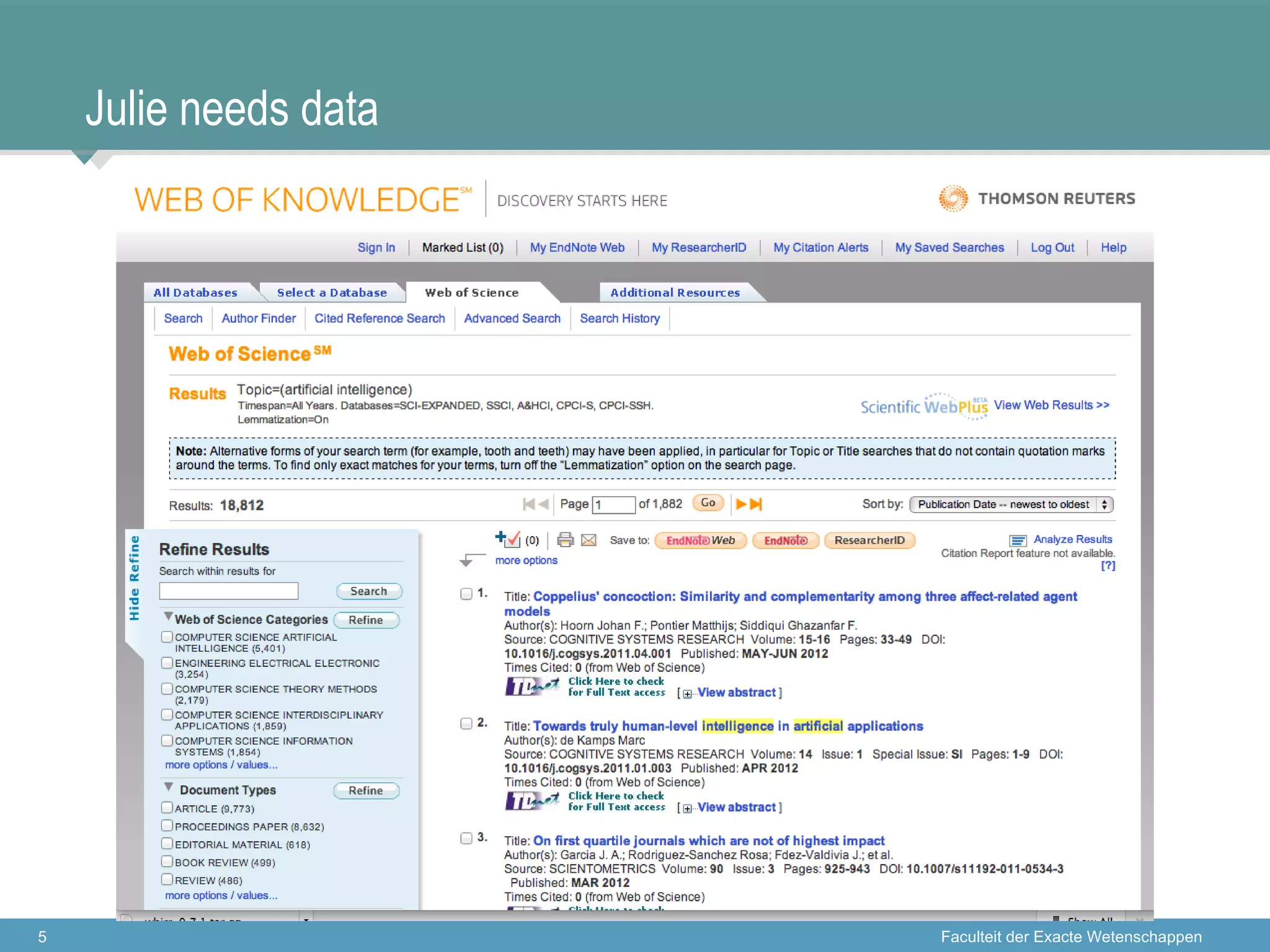

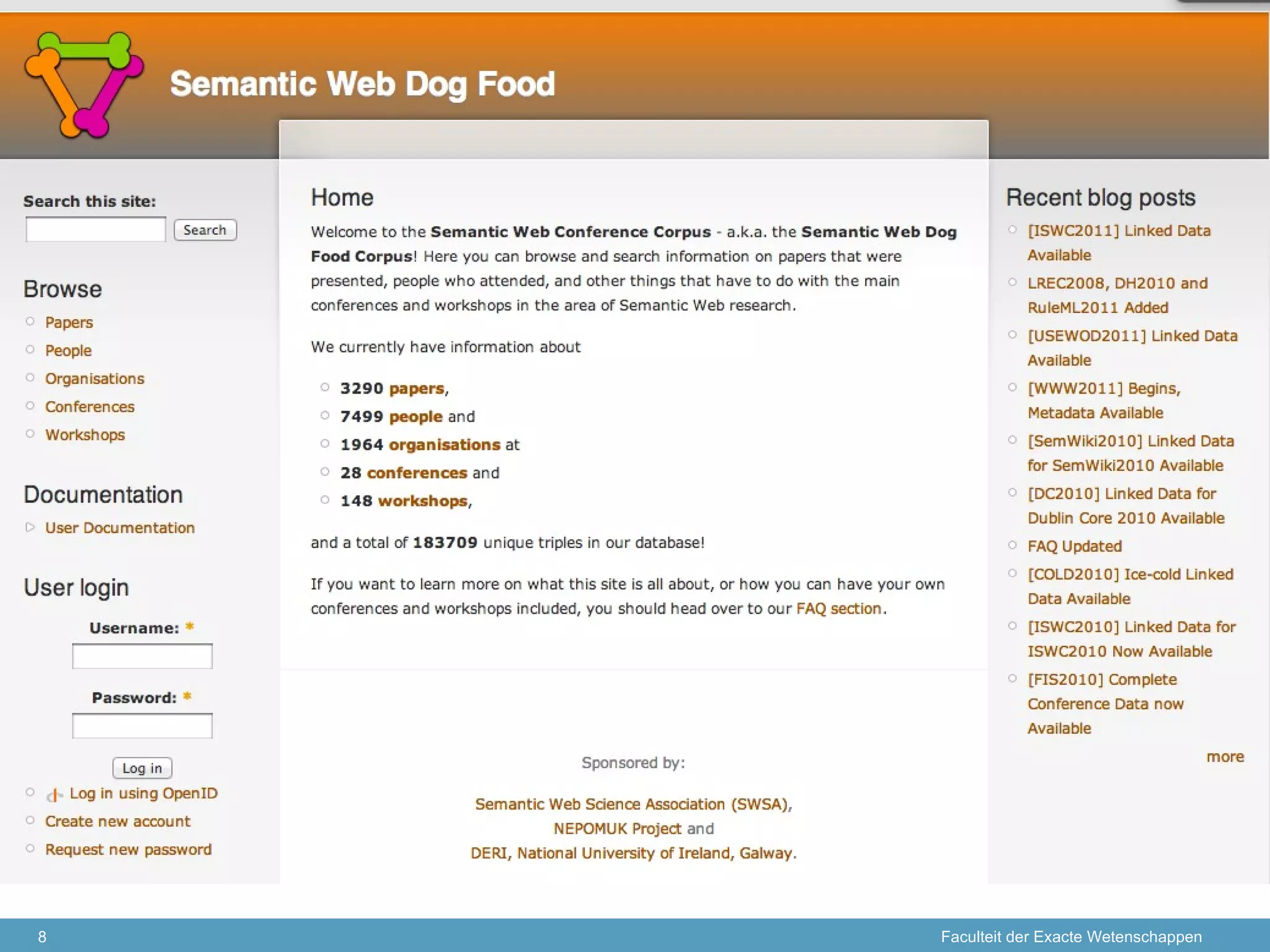





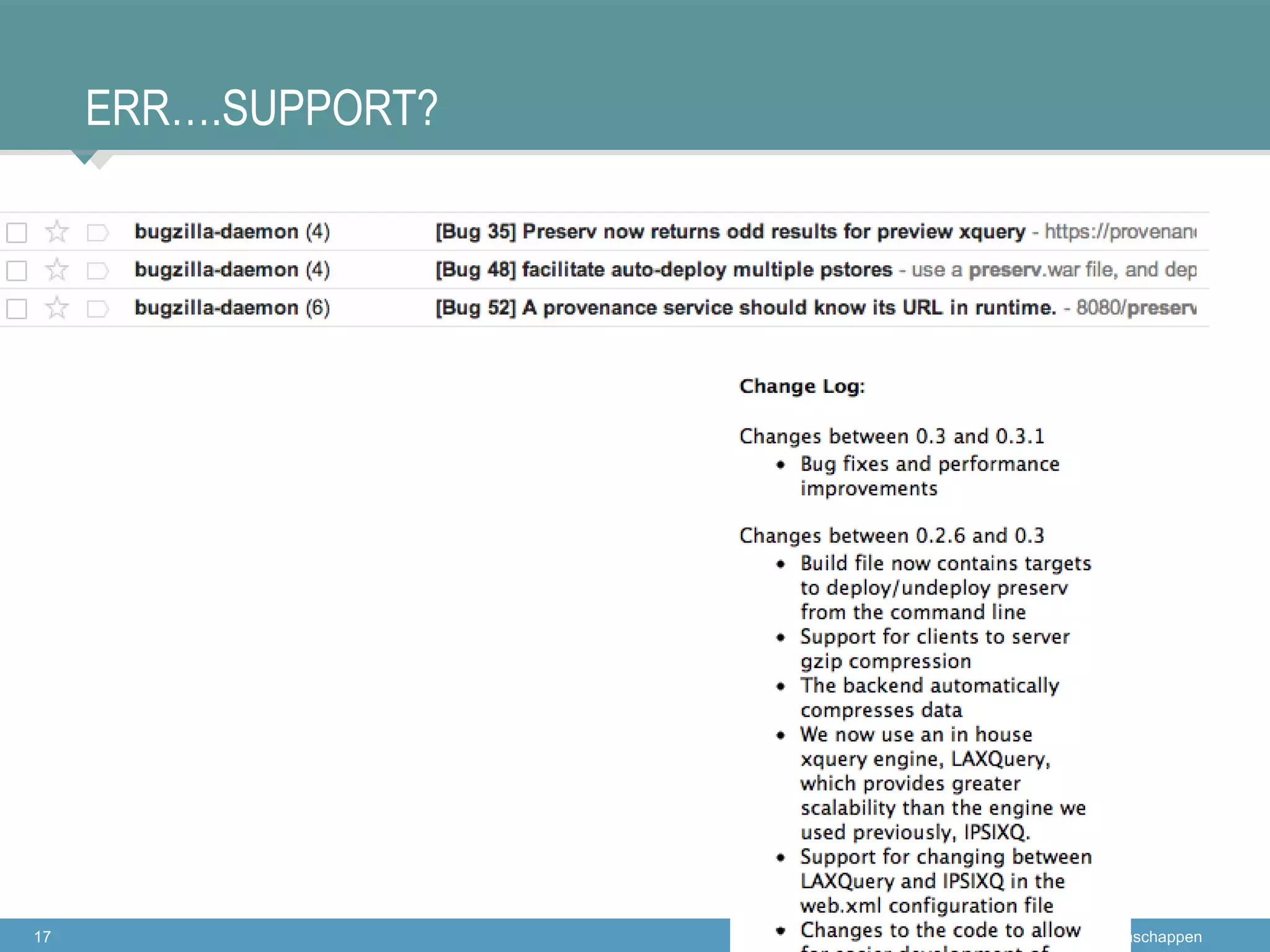


The document discusses the concept of open data and its implications for both producers and consumers, particularly within the context of scientific research. It outlines the benefits of open data for young scientists, emphasizes the need for support for data producers, and highlights the importance of clear guidelines and data citation. The content is based on a presentation regarding the accessibility and management of data in research environments.























































































