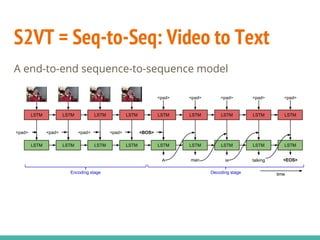
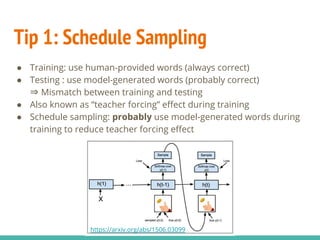
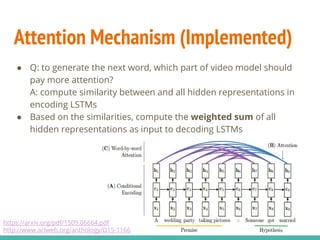
The document describes a project implementing a sequence-to-sequence model for generating video captions using TensorFlow, achieving a BLEU score of 0.275. It details the methodologies employed, including the use of LSTM and attention mechanisms, and highlights challenges faced like the 'teacher forcing' effect. The project aims to improve performance through techniques like schedule sampling and is planning to work on a larger dataset for further analysis.




























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















