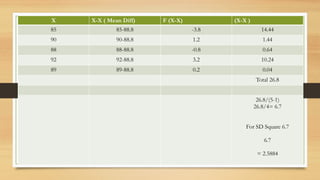
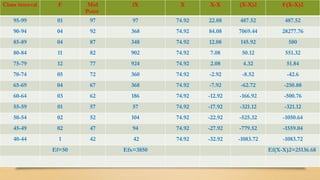
The document explains variance and standard deviation as measures of data dispersion, crucial for risk assessment, quality control, and statistical inference. It highlights their significance, including precision in data understanding, outlier identification, and comparability across datasets, while also noting limitations such as sensitivity to outliers and assumption of normal distribution. Additionally, it provides a step-by-step example of calculating variance and standard deviation using a dataset of exam scores.