Download as PDF, PPTX



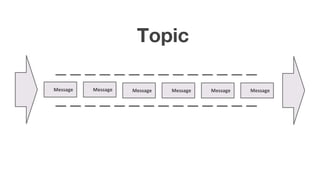
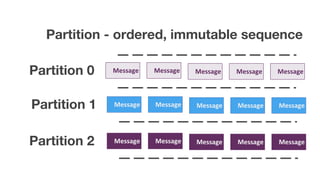
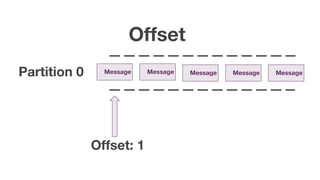
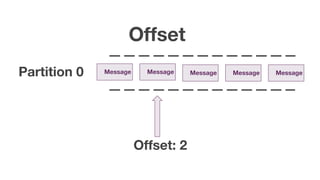
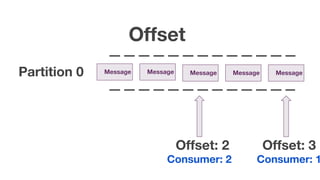
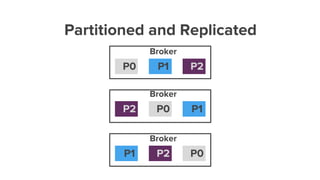
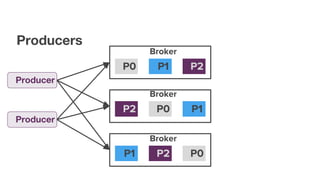
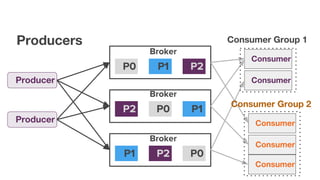






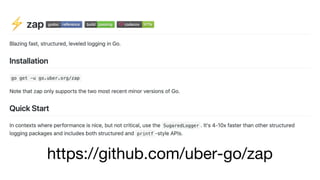



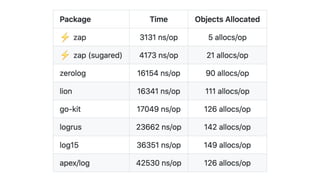





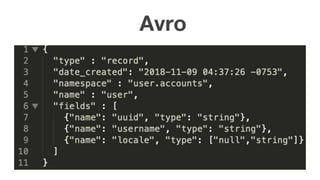













The document discusses using Apache Kafka with Go, detailing message handling, topic partitioning, and consumer groups for efficient data processing. It highlights the differences between at-most-once and at-least-once delivery semantics and provides references to logging frameworks and Kafka libraries in Go. The author, Nikolay Stoitsev, emphasizes performance aspects of message consumption and publishing in a Kafka environment.























































































