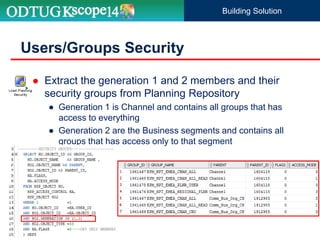
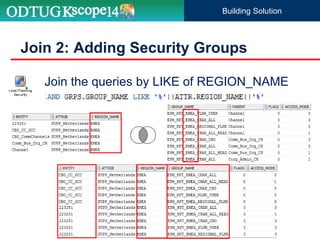
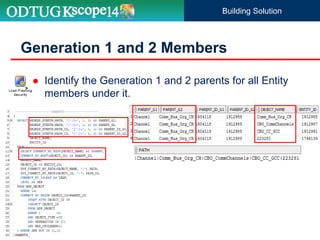
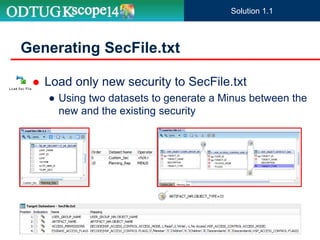
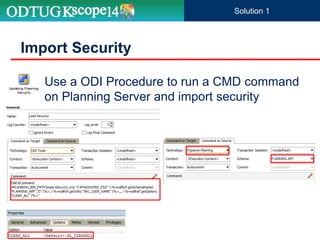
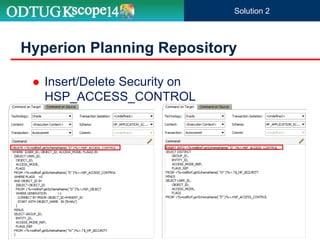
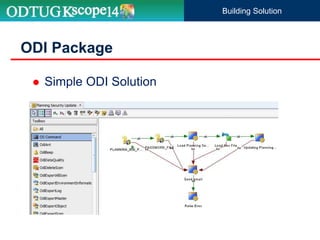
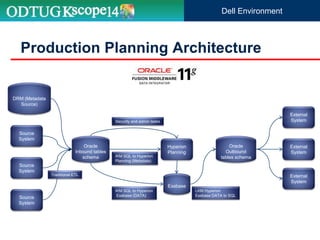
The document discusses the implementation of Hyperion Planning security within Dell's environment, focusing on the complexities of managing access to over 22,000 cost centers globally. It outlines the roles of key speakers and the methodologies for building a robust security framework using Oracle Data Integrator (ODI) to dynamically control user access based on geographical attributes. The use of various repository tables for managing users, groups, and access control is highlighted, along with two main solutions for importing security permissions into the system.





















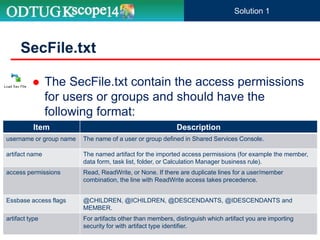
![ ImportSecurity utility loads access permissions for
users or groups from a text file into Planning
ImportSecurity
Parameter Description
[-f:passwordFile] Optional: If an encrypted password file is set up, use as the first parameter in the
command line to read the password from the full file path and name specified in
passwordFile.
appname Name of the Planning application to which you are importing access permissions.
username Planning administrator user name.
delimiter Optional: SL_TAB, SL_COMMA, SL_PIPE, SL_SPACE, SL_COLON, SL_SEMI-COLON. If
no delimiter is specified, comma is the default.
RUN_SILENT Optional: Execute the utility silently (the default) or with progress messages. Specify 0 for
messages, or 1 for no messages.
[SL_CLEARALL] Optional: Clear existing access permissions when importing new access permissions. Must
be in uppercase.
ImportSecurity.cmd [-f:passwordFile] “appname,username,[delimiter],[RUN_SILENT],[SL_CLEARALL]”
Solution 1](https://image.slidesharecdn.com/unleashinghyperionplanningsecurityusingodi-160601140922/85/Unleashing-Hyperion-Planning-Security-Using-ODI-29-320.jpg)





























































![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)