Download as PDF, PPTX








![IDS Lab
Jamie Seol
Lemma 1
• Lemma 1: for b1 < x1 < b2 < … < bn < xn, matrix A = [ReLU(xi - bj)]ij has
full rank
• Proof: obvious](https://image.slidesharecdn.com/generalization-170409133615/75/Understanding-deep-learning-requires-rethinking-generalization-13-2048.jpg)








The document discusses the limitations of deep learning's generalization capabilities, arguing that neural networks often memorize data rather than genuinely generalize concepts. It highlights that techniques like regularization do not fundamentally address these issues, and the theoretical boundaries of generalization error remain unclear. Ultimately, it calls for caution in associating optimization directly with generalization in deep learning models.
Deep learning's understanding requires rethinking generalization; overfitting leads to large generalization errors.
CIFAR-10 is an image classification task involving 10 classes. Neural networks can classify easily.
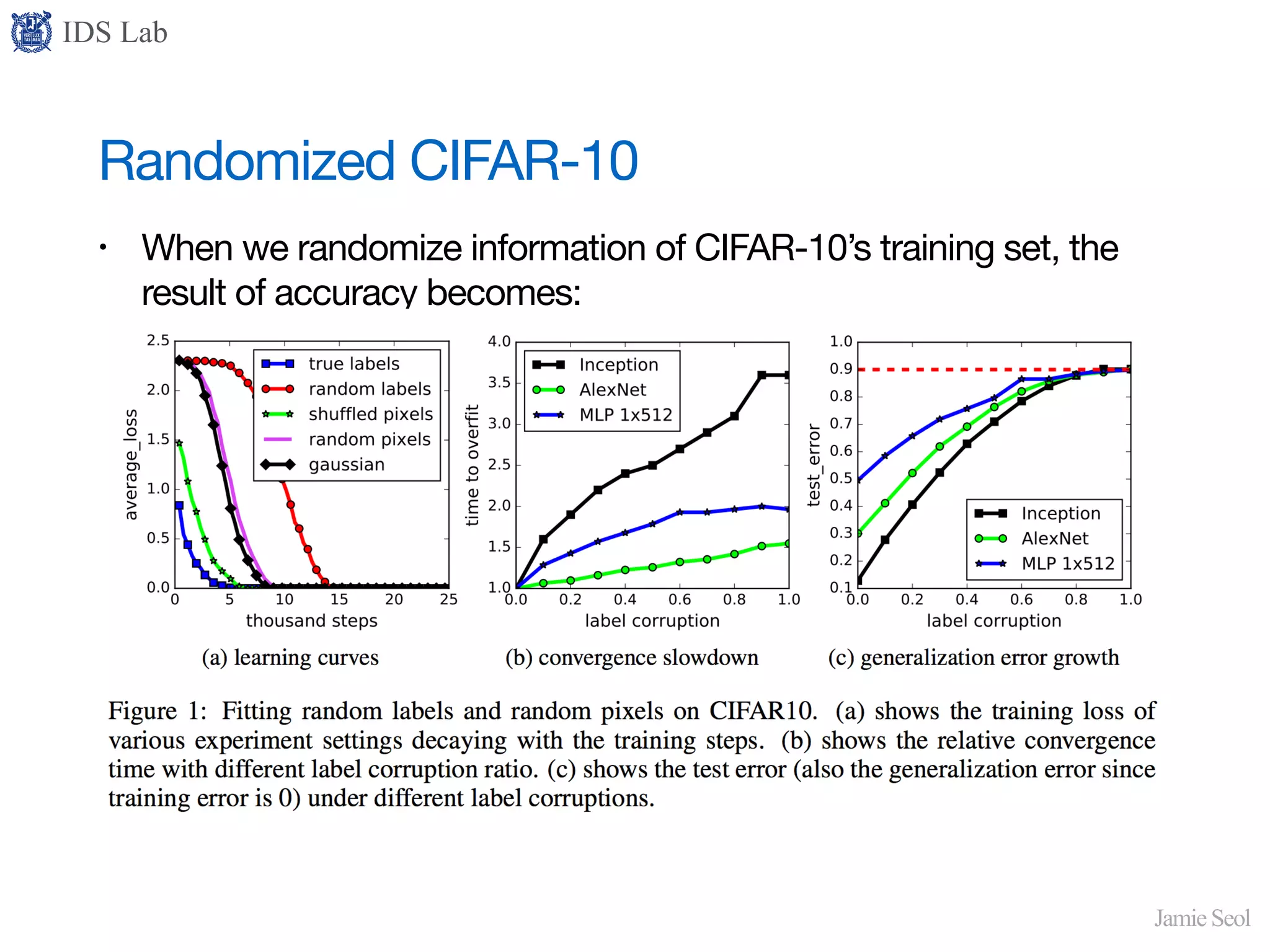
Randomized CIFAR-10 shows neural networks memorizing instead of generalizing. They are fragile to overfitting.
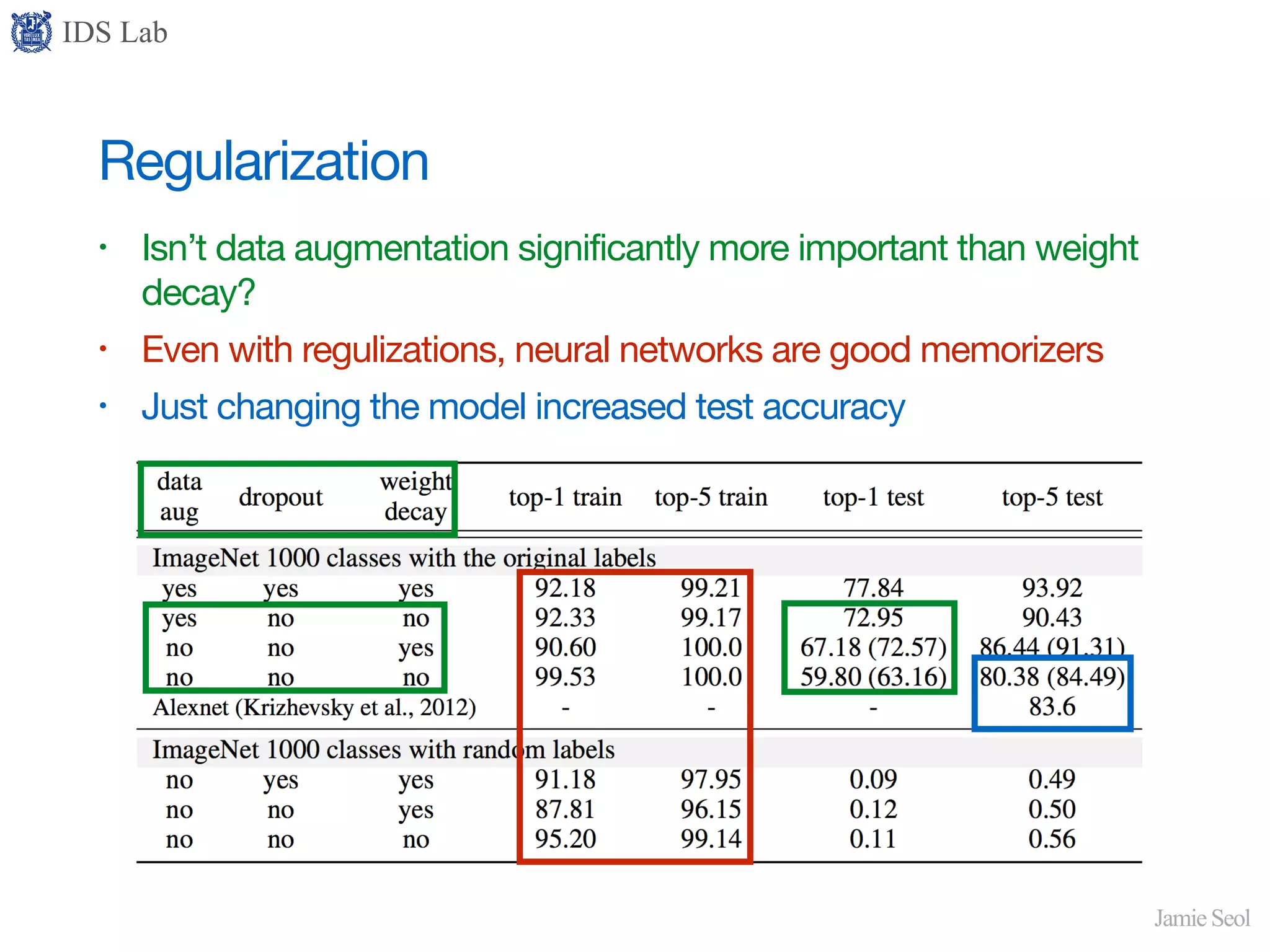
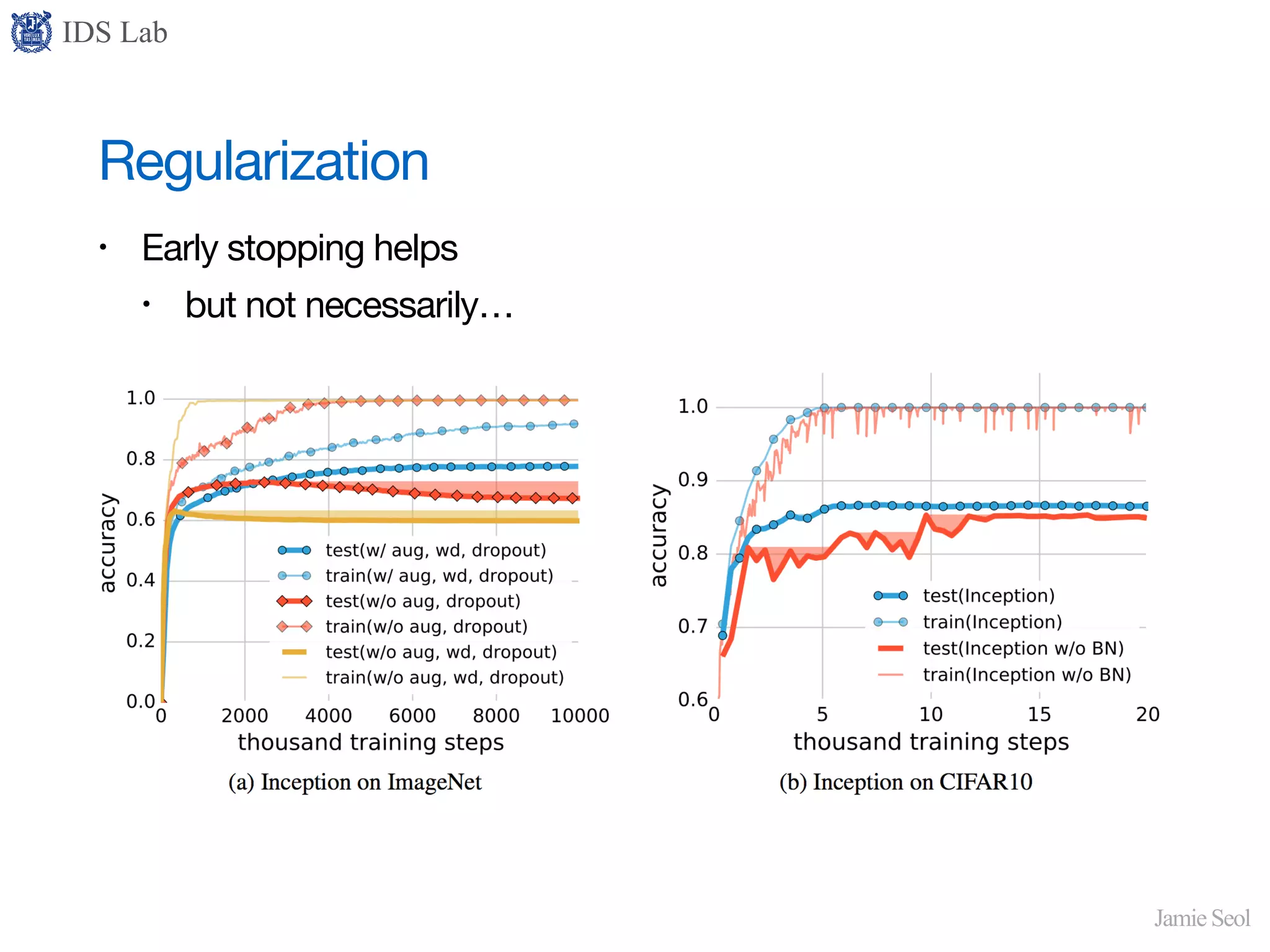
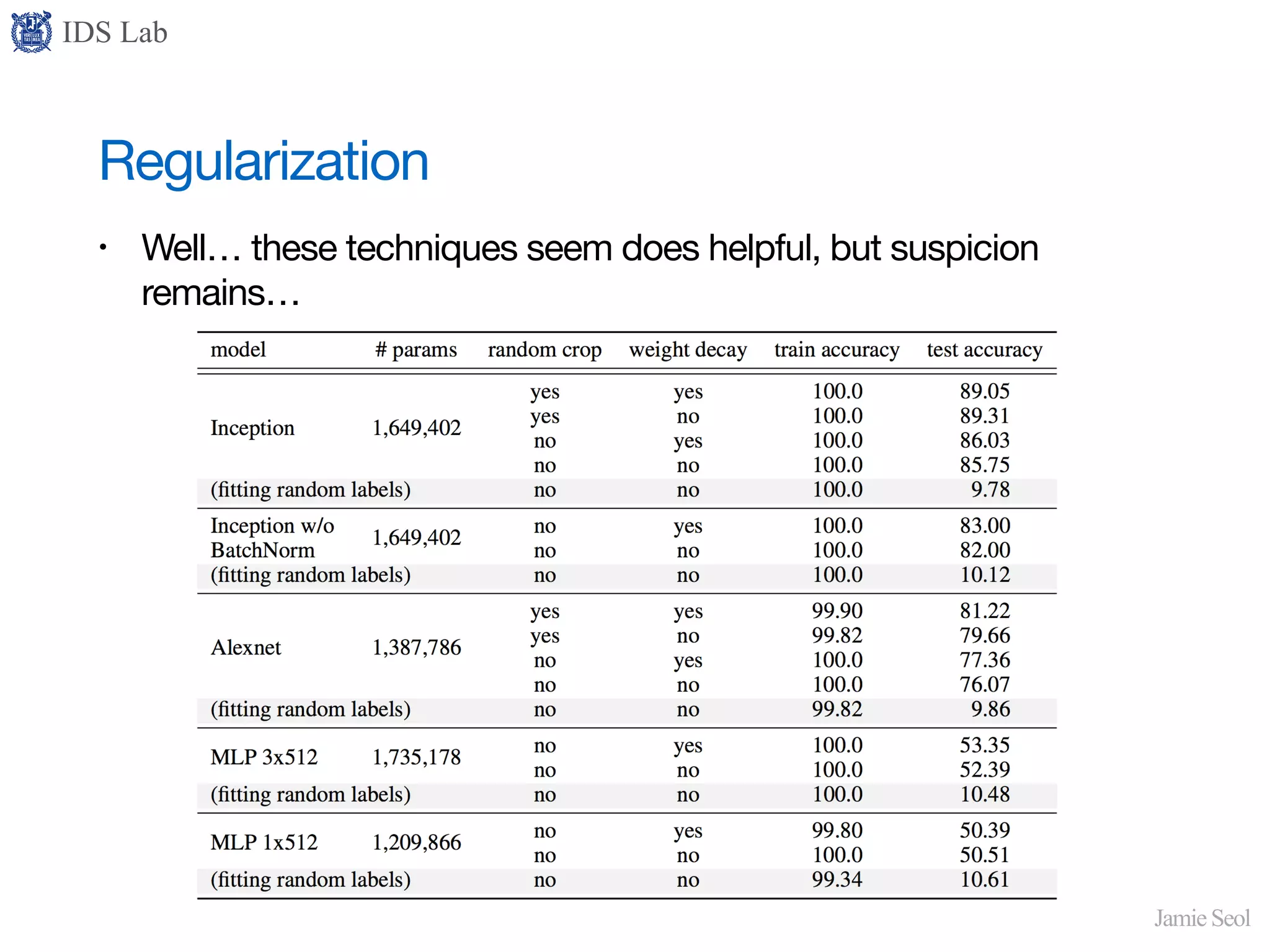
Discusses regularization methods like dropout and early stopping, questioning their effectiveness in improving generalization.
Rademacher complexity reveals memorization limits; models can overfit with many parameters, indicating generalization challenges.
Thinking on linear optimization via SGD uncovers multiple minima and redefines regularization's role in generalization.
Cautions on discussing generalization in deep learning and highlights experimental findings questioning existing techniques.

![[DL輪読会]Understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170217-170217024917-thumbnail.jpg?width=640&height=640&fit=bounds)







![[GAN by Hung-yi Lee]Part 1: General introduction of GAN](https://cdn.slidesharecdn.com/ss_thumbnails/part1-180809095233-thumbnail.jpg?width=640&height=640&fit=bounds)





































