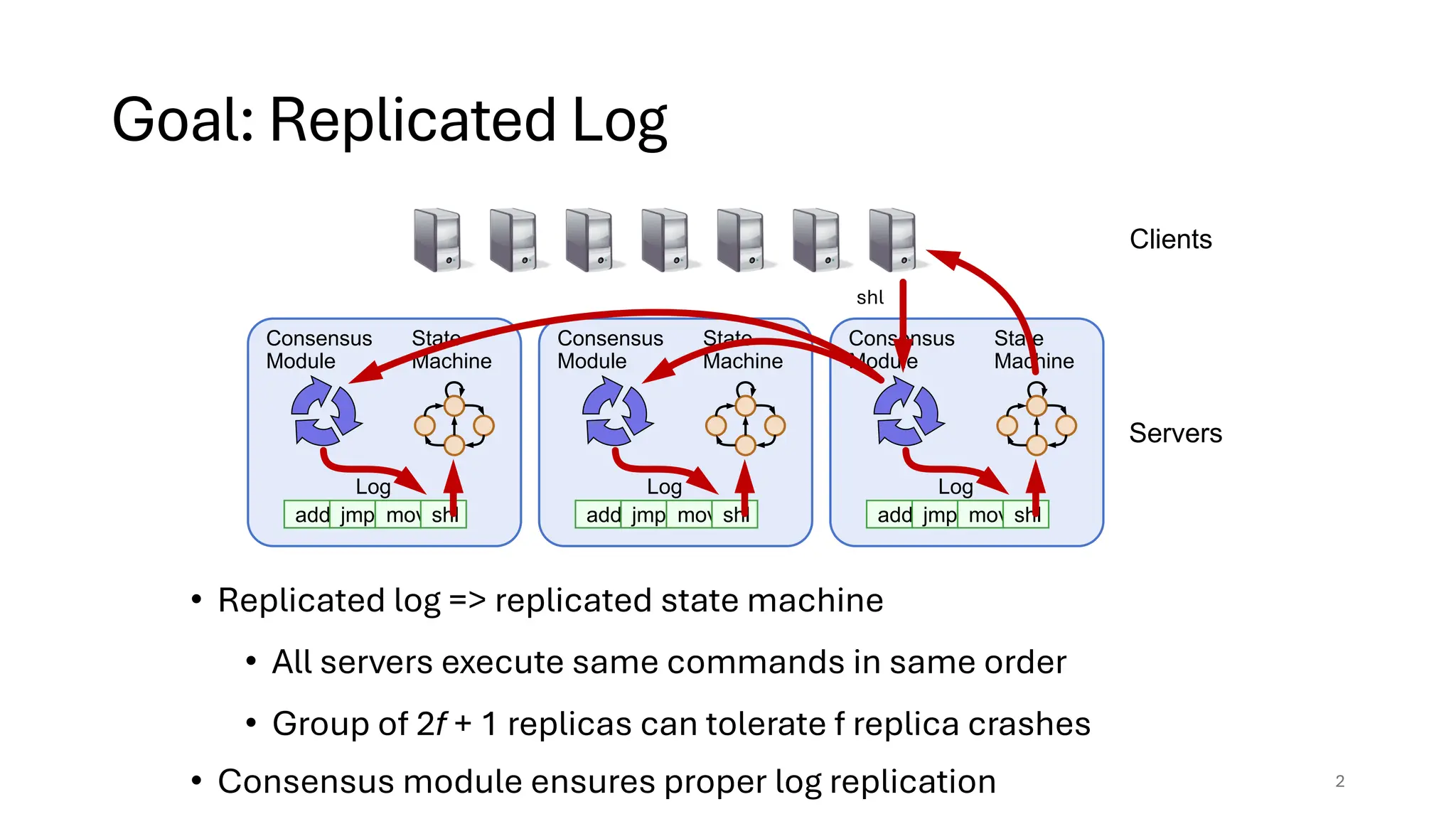
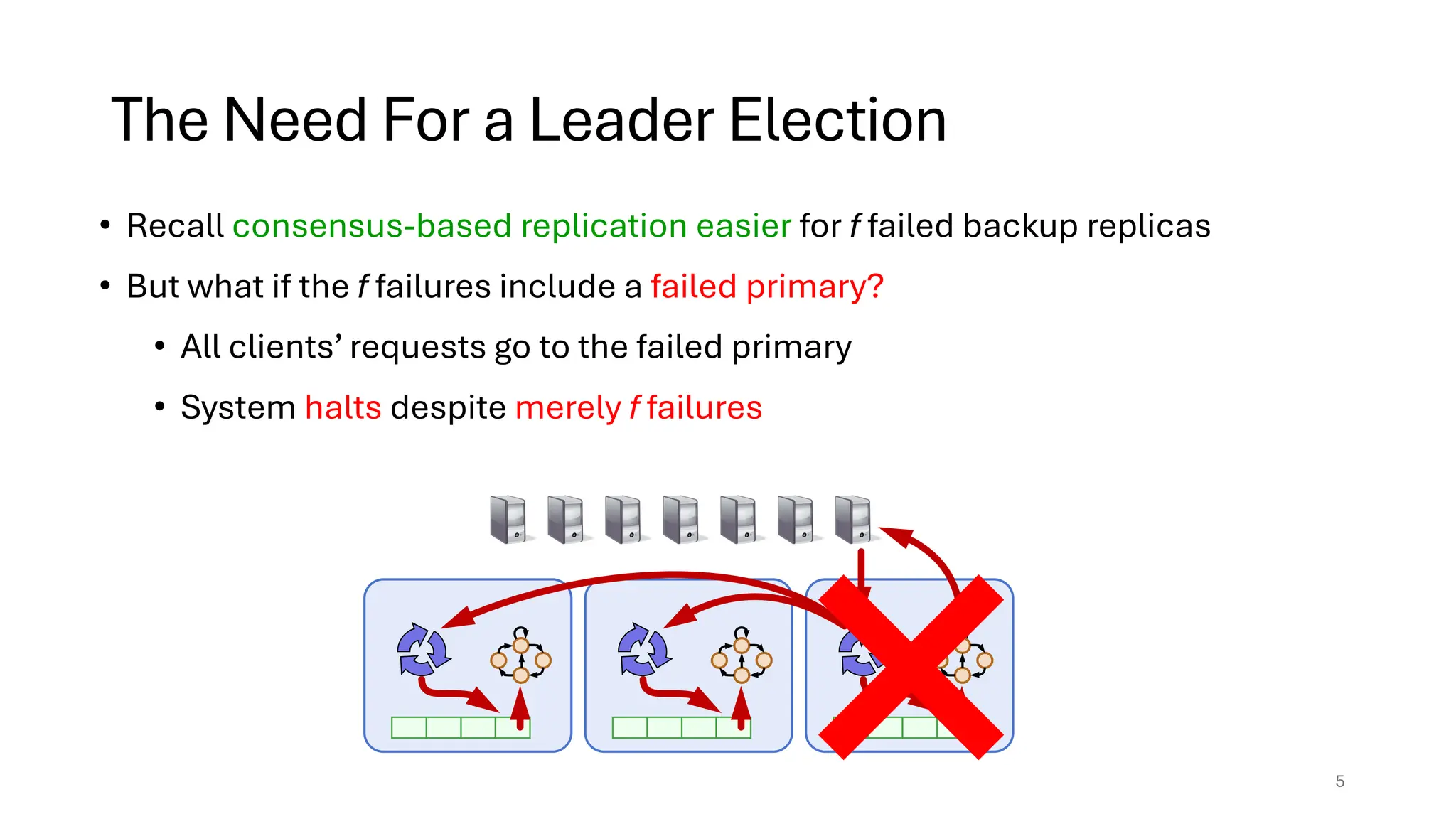
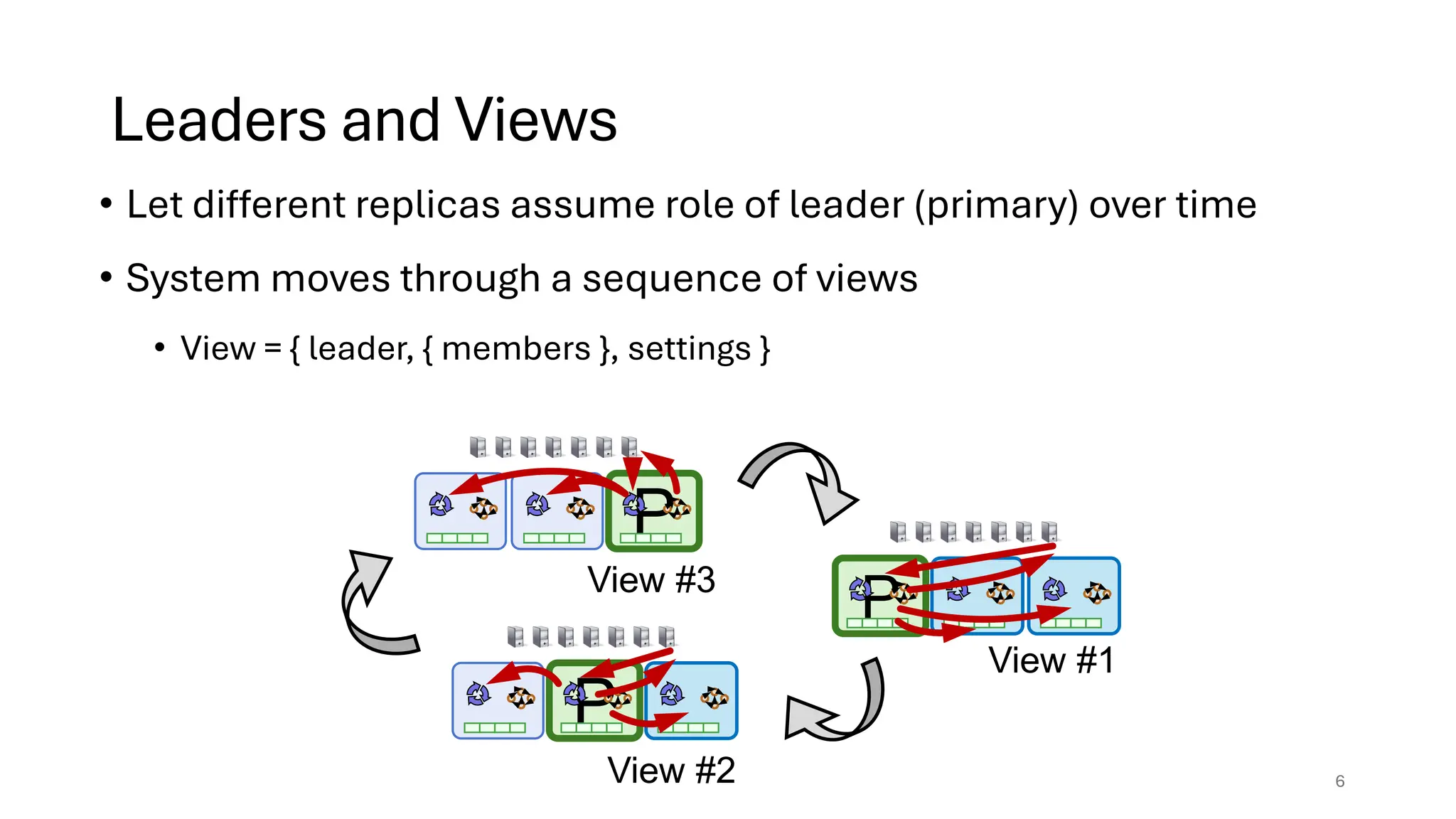
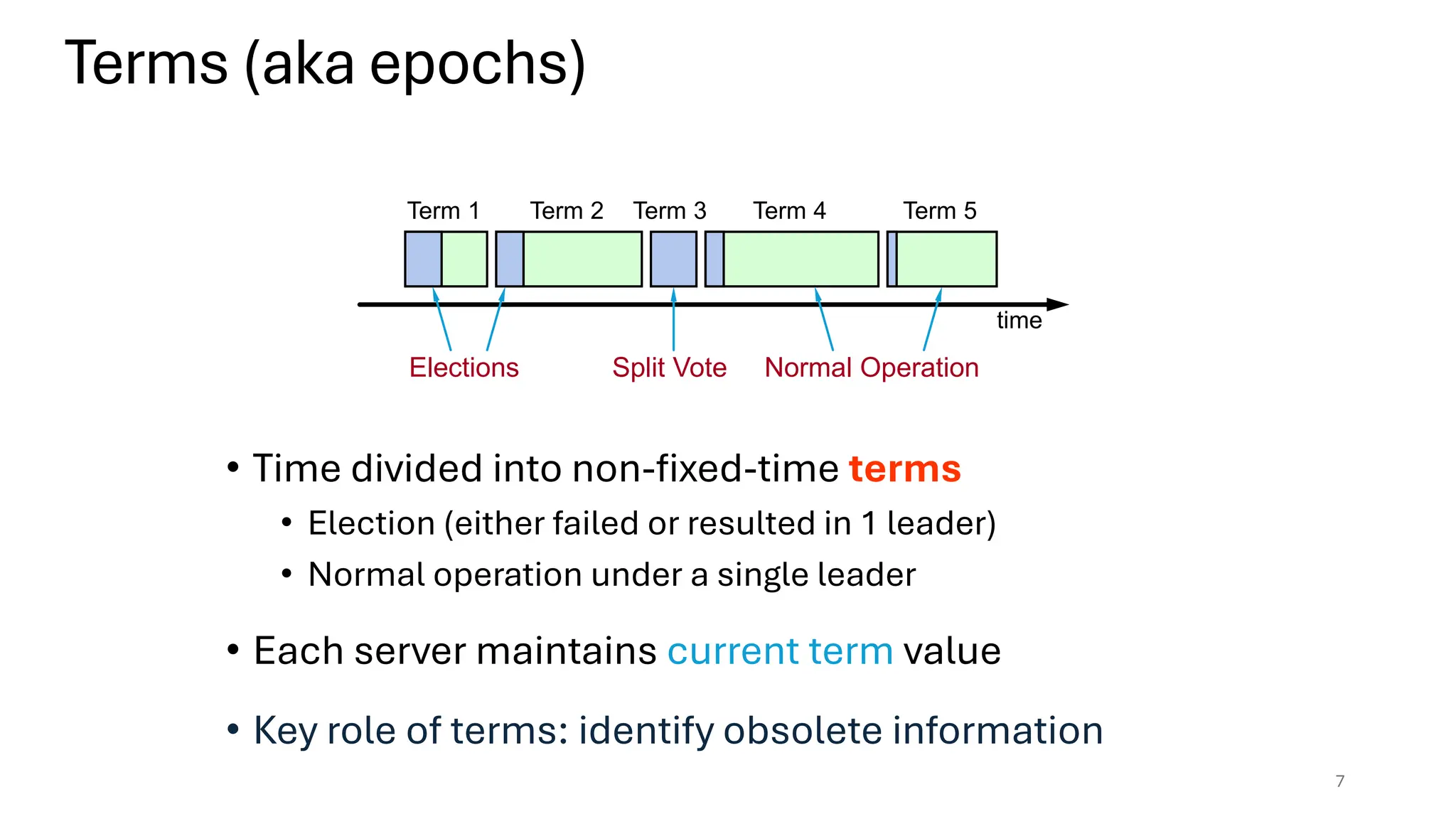
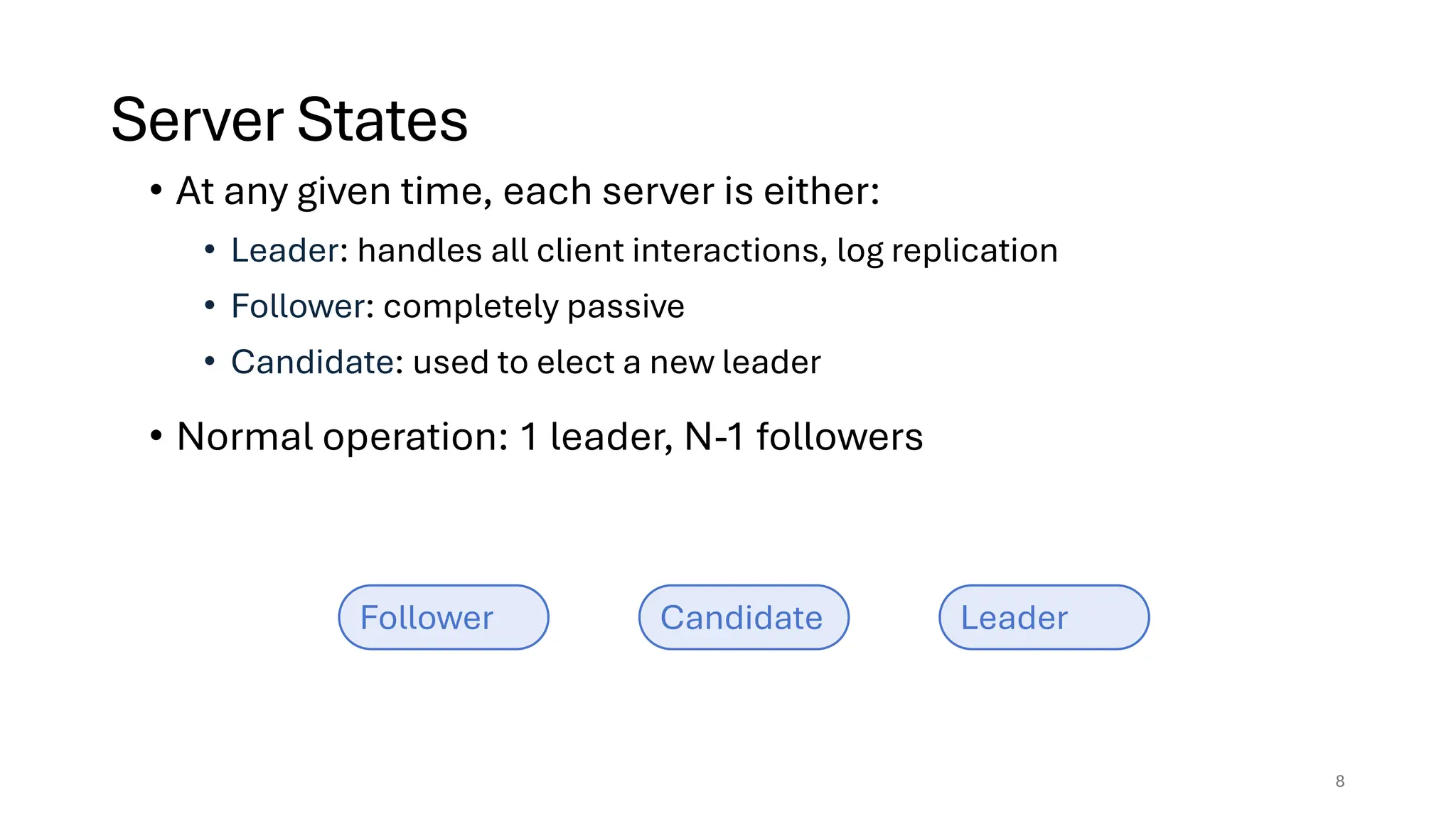
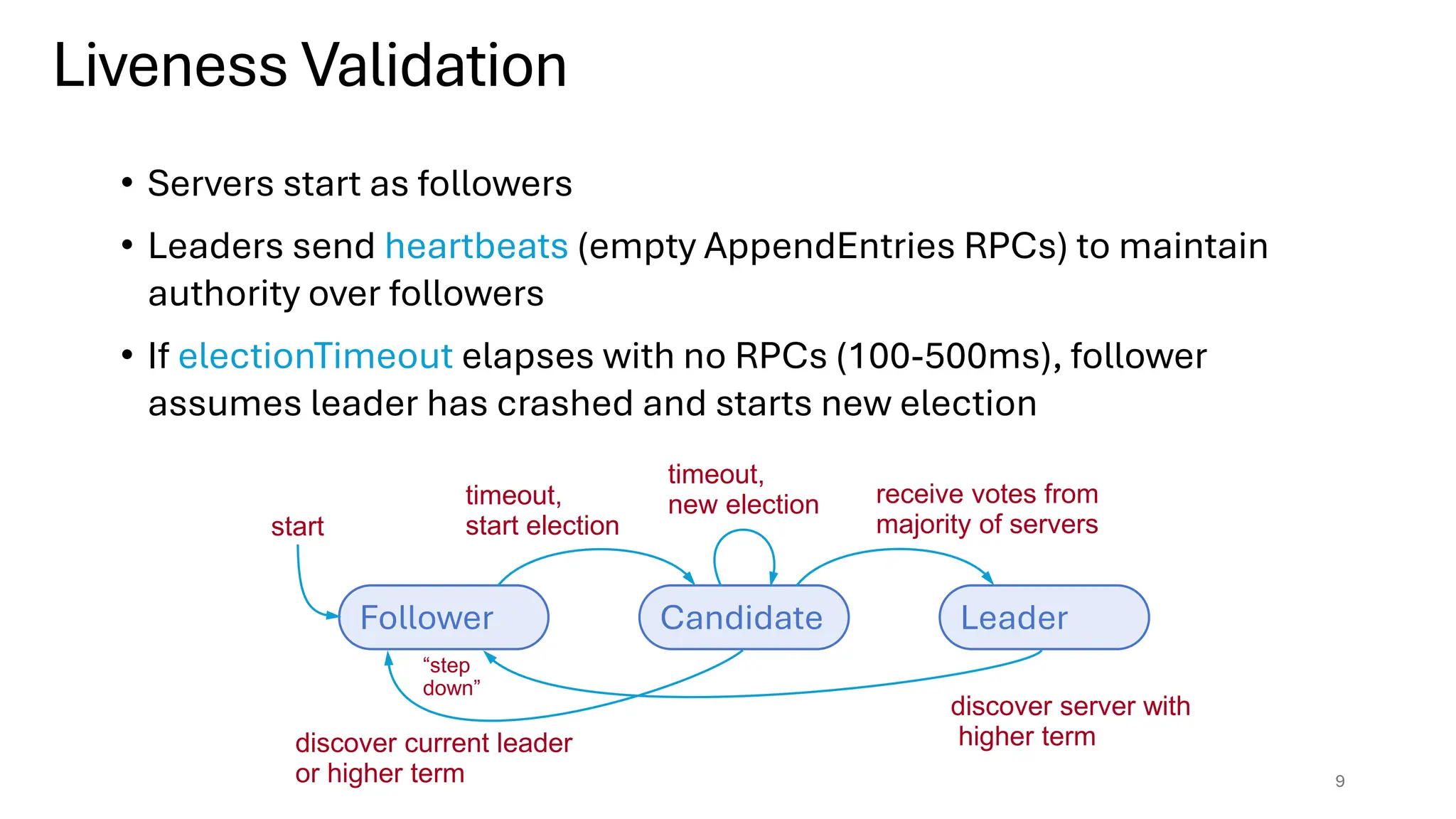
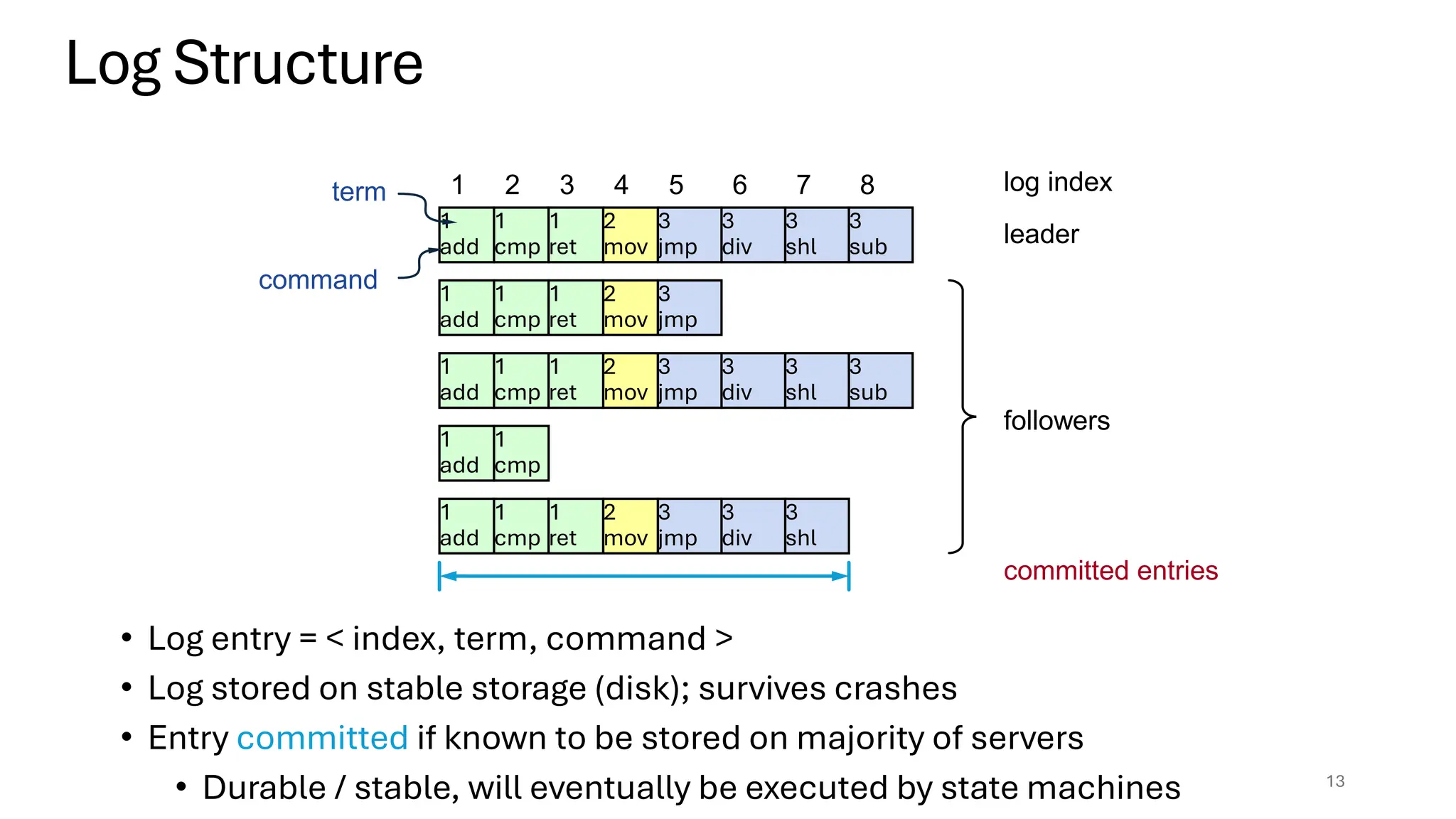
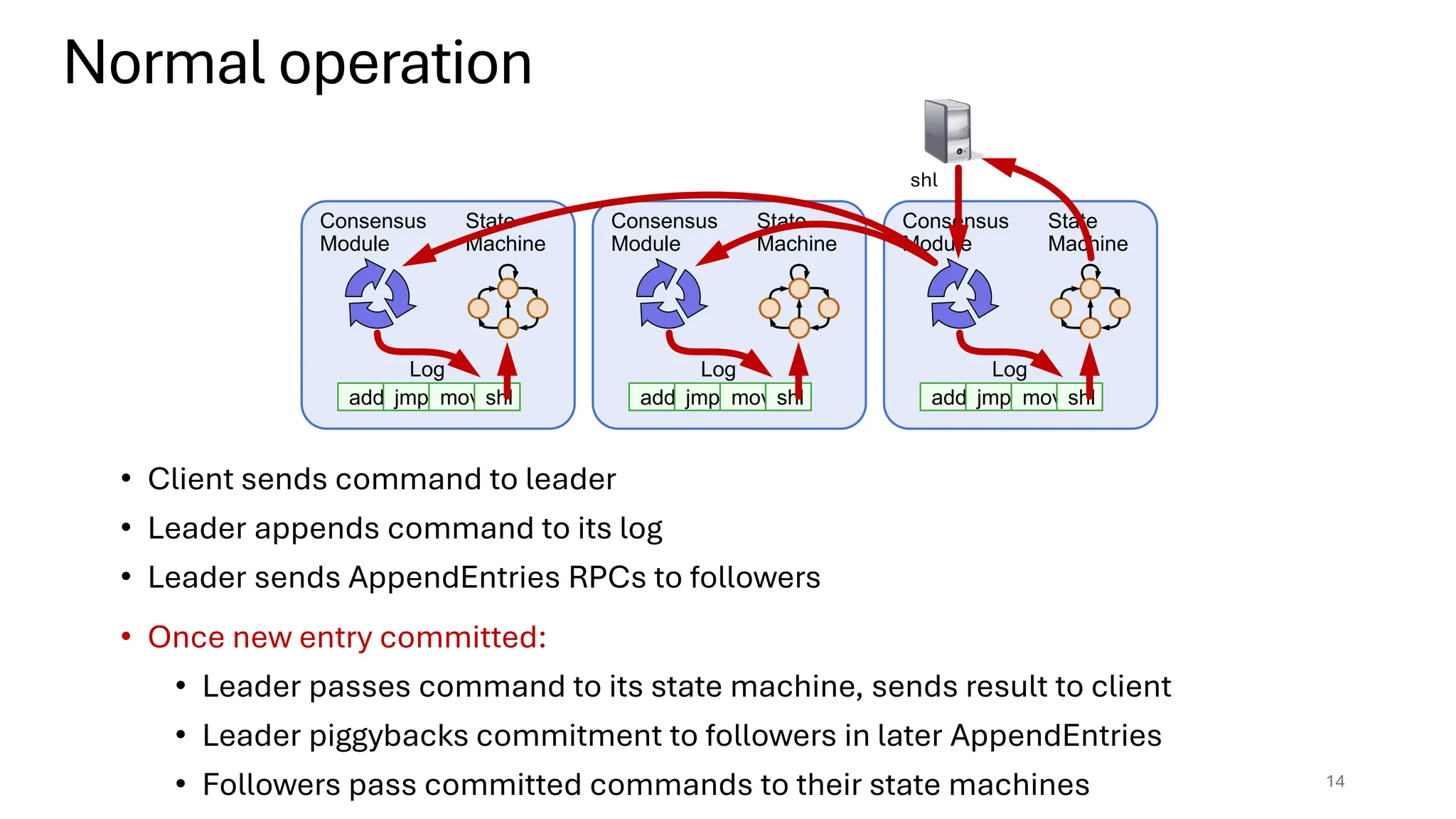
Raft is a consensus algorithm designed for replicated logs, allowing a group of servers to maintain a consistent state despite failures. It operates through a leader election process, ensuring that commands are replicated and executed in the same order across servers. The algorithm enhances safety and performance while simplifying the implementation compared to other consensus methods like Paxos.




![• Safety: allow at most one winner per term
• Each server votes only once per term (persists on disk)
• Two different candidates can’t get majorities in same term
• Liveness: some candidate eventually wins
• Each choose election timeouts randomly in [T, 2T]
• One usually initiates and wins election before others start
• Works well if T >> network RTT
Servers
Voted for
candidate A
B can’t also
get majority
Elections
11](https://image.slidesharecdn.com/raft-240531231314-e197a75c/75/Raftconsensusalgorithmforreplication-pdf-11-2048.jpg)
![Elections
12
• Liveness: some candidate eventually wins
– Each choose election timeouts randomly in [T, 2T]
– One usually initiates and wins election before others start
– Works well if T >> network RTT
Technique used throughout
distributed systems:
Desynchronizes behavior
without centralized
coordination!](https://image.slidesharecdn.com/raft-240531231314-e197a75c/75/Raftconsensusalgorithmforreplication-pdf-12-2048.jpg)















![[Yu cheng lin]cloud presentation - Raft](https://cdn.slidesharecdn.com/ss_thumbnails/yu-chenglincloudpresentation-raft-170817043111-thumbnail.jpg?width=640&height=640&fit=bounds)







































